1.1、流程剖析
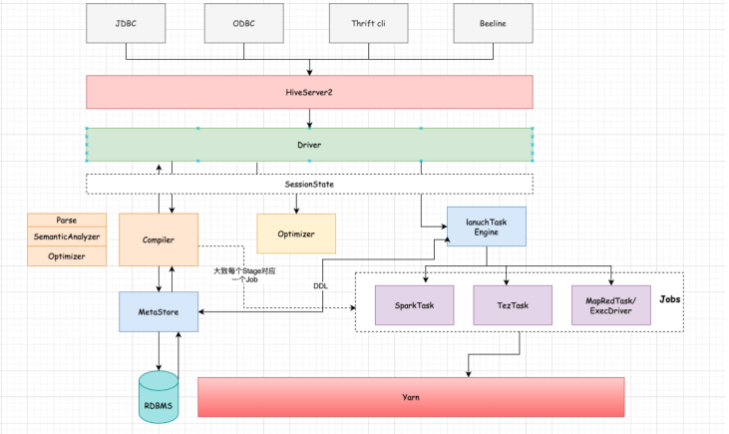
大致流程:
1、客户端连接到HS2(HiveServer2,目前大多数通过beeline形式连接,Hive Cli模式相对较重,且直接略过授权访问元数据),建立会话
2、提交sql,通过Driver进行编译、解析、优化逻辑计划,生成物理计划
3、对物理计划进行优化,并提交到执行引擎进行计算
4、返回结果
细节流程:
1、客户端和HiveServer2建立连接,创建会话
2、提交查询或者DDL,转交到Driver进行处理
3、Driver内部会通过Parser对语句进行解析,校验语法是否正确
4、然后通过Compiler编译器对语句进行编译,生成AST Tree
5、SemanticAnalyzer会遍历AST Tree,进一步进行语义分析,这个时候会和Hive MetaStore进行通信获取Schema信息,抽象成QueryBlock,逻辑计划生成器会遍历QueryBlock,翻译成Operator(计算抽象出来的算子)生成OperatorTree,这个时候是未优化的逻辑计划
6、Optimizer会对逻辑计划进行优化,如进行谓词下推、常量值替换、列裁剪等操作,得到优化后的逻辑计划。
7、SemanticAnalyzer会对逻辑计划进行处理,通过TaskCompiler生成物理执行计划TaskTree。
8、TaskCompiler会对物理计划进行优化,然后根据底层不同的引擎进行提交执行。

1.1.1、Analyze Sql
语法:
EXPLAIN [EXTENDED|CBO AST|DEPENDENCYAUTHORIZATION LOCKS VECTORIZATION ANALYZE] query版本支持:
Hive0.14.0支持AUTHORIZATION;[HIVE-5961]
Hive2.3.0支持VECTORIZATION;[HIVE-11394]
Hive3.2.0支持LOCKS;[HIVE-17683]
Explain结果总共分为三个部分:
1、对应查询的抽象语法树 AST
2、每个计划阶段Stage之间的依赖关系
3、每个计划阶段的描述(可能是map/reduce,也可能是操作元数据或者文件操作)
聚合操作分析示例:
EXPLAIN FROM SrC INSERT OVERMRITE TABLE dest g1 SELECT src.key, sum(substr(src.value,4)) GROUP BY src.key;聚合操作分析输出信息:
STAGE DEPENDENCIES: --每个stage之间的依赖关系
stage-1 is a root stage --Stage1是根阶段
stage-2 depends on stages: stage-1 --当Stage1执行完成后才会执行stage2
stage-0 depends on stages: stage-2 --当stage2执行完成后才会执行stage0
STAGE PLANS: --具体stage信息
stage: stage-1
Map Reduce--MapReduce阶段
Alias ->Map Operator Tree: --map阶段从一个特定表或者上一个map/reduce阶段结果中读取
src --表名
Reduce Output Operator
key expressions:
expr: key
type: string
sort order: +
Map-reduce partition columns:
expr: rand()
type: double
tag: -1
value expressions:
expr: substr(value, 4)
type: string
Reduce Operator Tree: --执行部分聚合
Group By Operator
aggregations:
expr: sum(UDFToDouble(VALUE.0))
keys:
expr: KEY.0
type: string
mode: partial1
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.mapred.SequenceFileOutputFormat
name: binary table
......依赖分析示例:
EXPLAIN DEPENDENCY SELECT key, count(1) FROM srcpart WHERE dS IS NOT NULL GROUP BY key依赖分析结果:
{
"input_partitions": [
{
"partitionName": "default<at:var at:name=\"srcpart\"/>ds=2008-04-08/hr=11"
},
{
"partitionName": "default<at:varat;name=\"srcpart\"/>ds=2008-04-08/hr=12"
},
{
"partitionName": "default<at:varat;name=\"srcpart\"/>ds=2008-04-09/hr=11"
},
{
"pantitionName": "default<at:var at:name= \"srcpart\"/>ds=2008-04-09/hr=12"
}
],
"input_tables": [
{
"tablename": "default@srcpart",
"tabletype": "MANAGED_TABLE"
}
]
}分析实际数据量示例:
explain analyze select t1.user id,t2.visit url from wedw_tmp.tmp_url info t1 full join wedw_tmp.tmp_url info t2 on t1.user_id = t2.user_id;分析实际数量结果:







![[BJDCTF2020]Easy MD5(浅谈PHP弱类型hash比较缺陷)](https://img-blog.csdnimg.cn/44a98362352b4eaa8996fc10d4c26504.png)