一、if的条件判断
1-1 if elif else
-
判断年龄属于哪个年龄段
# 判断学生
core = input('请输入成绩')
if int(core) >=90 :
print('优秀')
elif int(core) >=70 and int(core) <90:
print('中等')
elif int(core) >=60 and int(core) <70:
print('及格')
else:
print('不及格')
时间段, 成绩的划分,星座判断
1-2 if 嵌套
if 判断条件1: if 判断条件2: if 判断条件3: else: 第3个条件不成时执行 else: 第2个条件不成时执行 else: 第1个条件不成时执行
可以控制判断的执行顺序,进行多次判断
# if嵌套使用
name = input('请输入用户名:')
password = input('请输入密码:')
# 先判断用户名是否正确
if name == '张三':
# 在判断密码是否正确
if password=='123456':
print('登录成功')
else:
print('密码不正确')
else:
print('用户名不正确')
二、While循环
保证Python程序根据要求能持续运行
可以使用循环语句的语法实现循环运行,可以执行循环条件,当不满足条件后退出循环
-
语法格式
-
循环的代码逻辑要在下一行开始,开头空四格
-
条件成立,循环中代码逻辑会一直执行
-
while 数据判断条件: 编写循环执行的业务逻辑 修改退出条件数据
# while 一般用在需要程序持续运行时使用
a = 1
while a == 1:
# 条件成立,会一直运行while内的代码逻辑
name = input('请输入用户名:')
password = input('请输入密码:')
# 先判断用户名是否正确
if name == '张三':
# 在判断密码是否正确
if password == '123456':
print('登录成功')
# 通过修改变量值,改变判断条件不成立,此时就可以退出循环
a = 2
else:
print('密码不正确')
else:
print('用户名不正确')
-
控制循环输入次数不能超过三次
a = 1
while a <= 3:
# 条件成立,会一直运行while内的代码逻辑
name = input('请输入用户名:')
password = input('请输入密码:')
# 先判断用户名是否正确
if name == '张三':
# 在判断密码是否正确
if password == '123456':
print('登录成功')
# 通过修改变量值,改变判断条件不成立,此时就可以退出循环
a = 6
else:
print('密码不正确')
else:
print('用户名不正确')
三、For循环
while 主要控制数据处理的次数
for 遍历获取数据(容器形式的数据)中每个元素数据,字符串,列表,字典,元祖,集合,range方法
for循环的次数是有容器内的元素个数决定
-
语法格式
for i(临时变量,接收循环的元素数据) in 容器数据: 对临时变量中的数据进行操作
-
range的使用,可以根据指定数值生成范围内的容器数据
-
range(10) 生成0-10范围内的数据 起始从0开始
-
range(2,10) 生成的范围是 2-10
-
生成的范围数据是左闭右开 [0,10) 0可以取到值,10取不到值
-
# for循环 [0,5) for i in range(5): print(i) for i in range(2,5): # [2,5) print(i)
四、Break和Continue
break 跳出循环或结束循环
continue 跳过当前这一次循环,执行下次循环
可以对循环的数据进行判断,如果符合条件可以进行跳出循环或跳过循环
-
break退出for循环
for num in range(3): # [0,3) 0,1,2
name = input('请输入用户名:')
password = input('请输入密码:')
# 先判断用户名是否正确
if name == '张三':
# 在判断密码是否正确
if password == '123456':
print('登录成功')
# 使用break关键,会结束循环,不再进行取值
break
else:
print('密码不正确')
else:
print('用户名不正确')
-
遍历1-10数据,只对偶数数据输出
for data in range(1,11): # 对data数据进行奇数判断 if data % 2 !=0: # 跳过 continue # continue被执行,continue后面逻辑就不会被执行 print(data)
五、容器类型介绍
容器就是存放数据的
python 中的容器数据有多种形式,每种形式有自己的存储格式, 数据存储特性不一样
字符串 str 就是容器 存放一个一个字母 格式 : 单引号 '数据' ,双引号 "数据" ,三个引号 """ 数据 """
列表 list 格式: [数据1,数据2,数据3.....]
元祖 tuple 格式: (数据1,数据2,数据3,)
集合 set 格式: {数据1,数据2,数据3,}
字典 dict 格式: {key1:value1,key2:value....}
数据存储的特性
有序和无序
有序: 字符串,列表,元祖,字典
无序: 集合
数据重复性
允许数据重复 字符串,列表,元祖,字典的value部分可以重复
不允许重复 集合,字典的key值
数据是否允许修改
允许修改 列表,字典value数据可以修改,
不允许修改 字符串 ,元祖
常用的字符串,列表和字典
六、字符串
字符串就是有一个一个字母构成,使用引号包裹数据
data_str1 = '数据' data_str2 = "数据" data_str3 = '''数据'''
6-1 下标取值
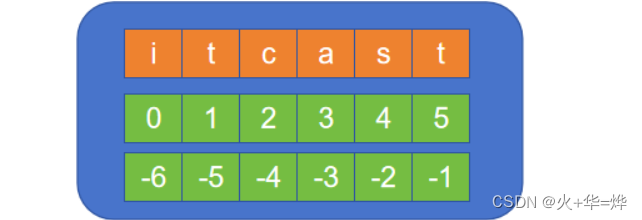
在有序的容器中,会对数据的顺序进行编号,该编号就称为数据下标。可以通过下标取出对应位置中的数据
下标编号是从0开始
数据:i t c a s t
下标:0 1 2 3 4 5
-
字符串的下标取值
-
一次取出一个下标对应的数据
-
# 有序容器的下标取值 data_str = 'itcast' # 下标取一个值 print(data_str[2])
-
切片
-
指定下标范围进行取值
-
[起始下标:结束下标] 下标的范围是左闭右开的,结束下标的值取不到
-
# 有序容器的下标取值 data_str = 'itcast' # 下标取一个值 print(data_str[2]) # 下标取多个值 使用切片 [起始下标:结束下标] 取值范围也是左闭右开 结束下标的数据无法取到 print(data_str[1:4])
-
间隔步长取值
# 有序容器的下标取值 data_str = 'itcast' # 下标取一个值 print(data_str[2]) # 下标取多个值 使用切片 [起始下标:结束下标] 取值范围也是左闭右开 结束下标的数据无法取到 print(data_str[1:4]) # 间隔取多个值 使用切片 [起始下标:结束下标:步长] print(data_str[1:6:2]) # 起始从1开始 下一个值是 1+2=3 1+2+2=5
-
下标的其他操作
# 单个取值时超过下标值或报错 print(data_str[6])
![]()
# 切片进行多个数据取值超出下标,不会报错,将后面的数据全部取出 print(data_str[1:1000])
# 取值的下标可以是负数 print(data_str[-4:-2])
# 如果需要改变起始位置从右边开始,则需要将步长设置为-1 # 可以实现字符串的反转 print(data_str[-1:-7:-1]) # 需要获取所有的的字符可以省略起始和结束下标 print(data_str[::-1])
6-2 for循环取值
依次从字符串中取出每一个字母,该过程叫做数据遍历
# 遍历字符串数据 data = 'itcast' for i in data: print(i)
6-3 函数方法
-
find 找字符在字符串中位置,返回对应的首字母的下标,数据不存在返回-1
# 字符串的函数操作方法
# 查找字符在字符串中的下标位置
data = 'itcast'
# num接收查找到的下标 如果存在返回对应位置下标,不存在返回-1
num = data.find('w')
print(num)
-
index 找字符在字符串中位置,返回对应的首字母的下标,数据不存在报错
num2 = data.index('w')
print(num2)
-
split 字符串的切割
-
切割后的数据会放入列表中返回
-
data_str = 'python,hadoop,spark,flink'
# split的切割字符串
res = data_str.split(',')
print(res)
-
replace 字符串的替换,替换字符串中的数据
-
除了可以替换数据,还可以清洗数据
-
data_str2 = '2024-10-11'
# 字符串替换
res2 = data_str2.replace('-','/')
print(res2)
data_str3 = '机器哦@我觉得#千库网'
# 通过replace的替换去除特殊字符
res3 = data_str3.replace('@','').replace('#','')
print(res3)
七、列表
7-1 列表定义
语法格式
[数据1,数据2.....]
# 列表的定义及取值 # 在列表中可以定义指定多个数据内容,尽量保证数据类型一致 data_list = [1, 20, 33, 15, 18, 21] data_list2 = ['spark', 'hadoop', 'flink', 'python'] data_list3 = [1, '张三', 20]
7-2 列表取值
可以通过下标和切片取值
for循环遍历取值
# 列表的定义及取值 # 在列表中可以定义指定多个数据内容,尽量保证数据类型一致 data_list = [1, 20, 33, 15, 18, 21] data_list2 = ['spark', 'hadoop', 'flink', 'python'] data_list3 = [1, '张三', 20] # 列表也是有序容器,所以支持下标取值 # 单个取值 print(data_list[1]) print(data_list2[2]) # 切片取多个值 print(data_list[1:5]) # 步长间隔取值 print(data_list[1:5:2]) # 循环遍历取值 for i in data_list3: print(i) # 列表嵌套列表 data_list4 =[[1,2,3],['a','b','c']] print(data_list4[1][0])
7-3 列表的增删改查方法
增加
-
append
-
常用来增加一个元素数据
-
-
extend
-
将另一个列表的数据合并当前列表
-
-
insert
-
指定下标位置增加数据
-
# 添加列表数据
data_book = [] # 定义一个空列表
# append添加数据,将数据添加到列表末尾
data_book.append('昆仑')
data_book.append('沧海')
data_book.append('五大贼王')
# 查看原始数据
print(data_book)
# insert 可以指定下标位置添加
data_book.insert(1, '青盲')
# 查看数据
print(data_book)
# extend将一个列表数据合并另一个列表中
data_book_new = ['大魔术师', '冒死记录']
data_book.extend(data_book_new)
print(data_book)
# 使用运算符 + 将列表合并
data_book_new2 = ['死亡通知单', '暗黑者', '摄魂谷', '凶画']
res = data_book + data_book_new2
print(res)
删除
-
del 数据[下标] 删除指定下标的数据
-
remove 删除列中指定的数据
-
pop() 弹出列表中的数据,数据弹出后会从列表中删除
-
默认从最后一个数据弹出
-
-
clear() 清除所有列表中的数据,变成空列表
# 删除列表中的数据
data_book = ['诛仙','斗破苍穹','盗墓笔记','年少荒唐','极品家丁','坏蛋是怎么练成的']
# 通过指定下标删除
del data_book[3]
print(data_book)
# 指定数据删除
data_book.remove('极品家丁')
print(data_book)
# 弹出数据删除 将末尾数据弹出 可以定义接收变量,接收弹出的数据
res = data_book.pop()
print(data_book)
# 清空列表数据
data_book.clear()
print(data_book)
修改
-
指定下标对应的数据进行修改
-
列表[下标] = 修改的值
-
-
列表数据的反转 修改顺序
-
排序
# 修改列表数据 data_book = ['紫川', '三重门', '从你的全世界路过', '梦里花落知多少'] # 通过下标修改数据 data_book[1] = '善恶的彼岸' print(data_book) # 列表反转 data_book.reverse() print(data_book) # 列表排序 data_list = [1,7,2,4,3] data_list.sort(reverse=False) print(data_list) data_list.sort(reverse=True) print(data_list)
查询
-
index 查询数据在列表中的下标位置
-
count 查询数据出现的次数
-
in 查找数据是否在列表中
-
not in 不在列表中
-
-
len 获取列表的元素个数
# 查询列表数据
data_book = ['道德的谱系','反基督','瞧,这个人','飞鸟集']
# index查询数据
num = data_book.index('反基督')
print(num)
# num = data_book.index('aa')
# print(num)
# count 统计数据出现次数
num2 = data_book.count('飞鸟集')
print(num2)
# 查询元素个数
num3 = len(data_book)
print(num3)
# 判断元素是否在列表中
if '道德的谱系' in data_book:
print('数据在列表中')
# not in 是判断不在列表中