文章目录
- 0、准备
- 1、缓存穿透:不存在的key
- 2、缓存击穿:热点key过期
- 3、缓存雪崩:大批key同时过期
- 4、双写一致性
- 4.1 要求高一致性
- 4.2 允许一定的一致延迟
- 5、面试
0、准备
Redis相关概览:
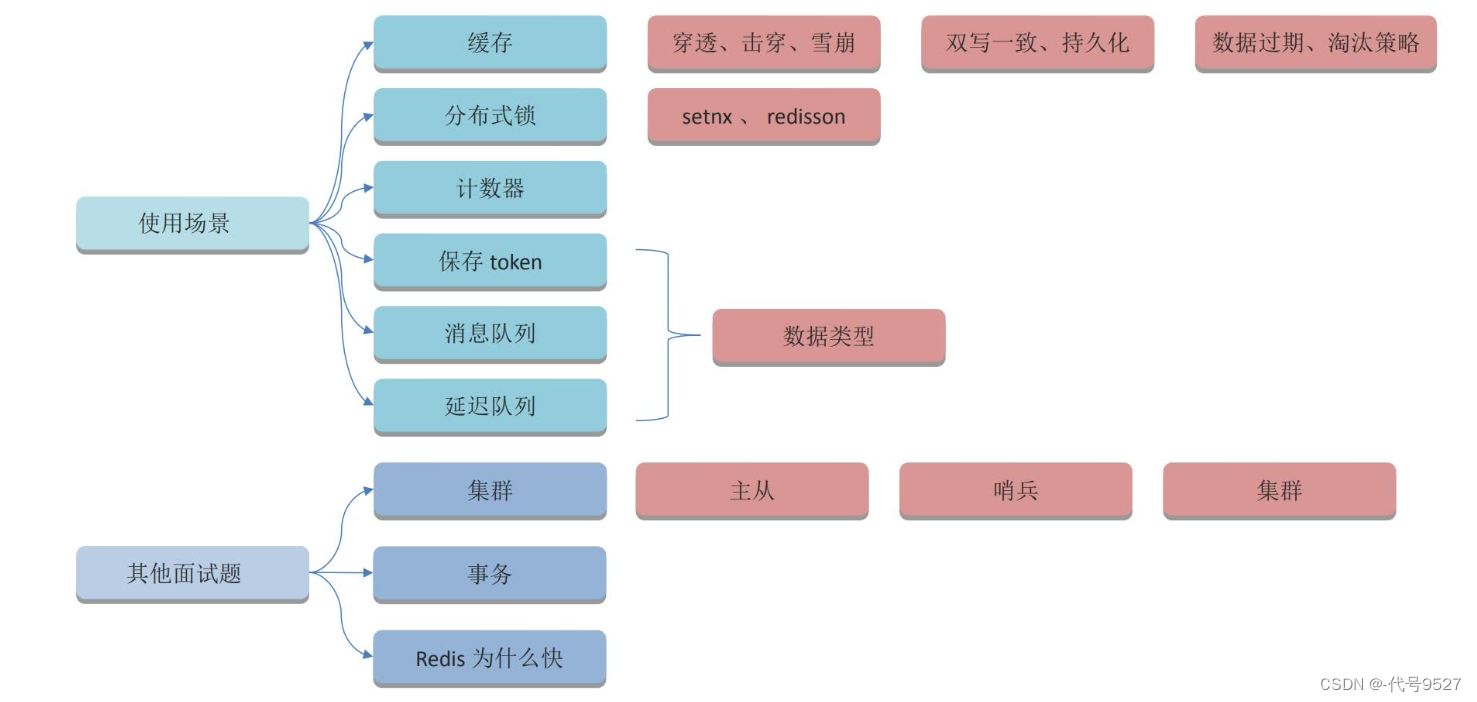
以简历上所列的项目为切入点,展开Redis相关的问题:

1、缓存穿透:不存在的key
Client ⇒ Redis ⇒ MySQL,缓存穿透,即中间的Redis形同虚设,请求每次过来都查库。一般是网站被攻击时,疯狂造不存在数据,然后发起请求,冲击数据库,消耗数据库连接池资源,直到服务不可用。
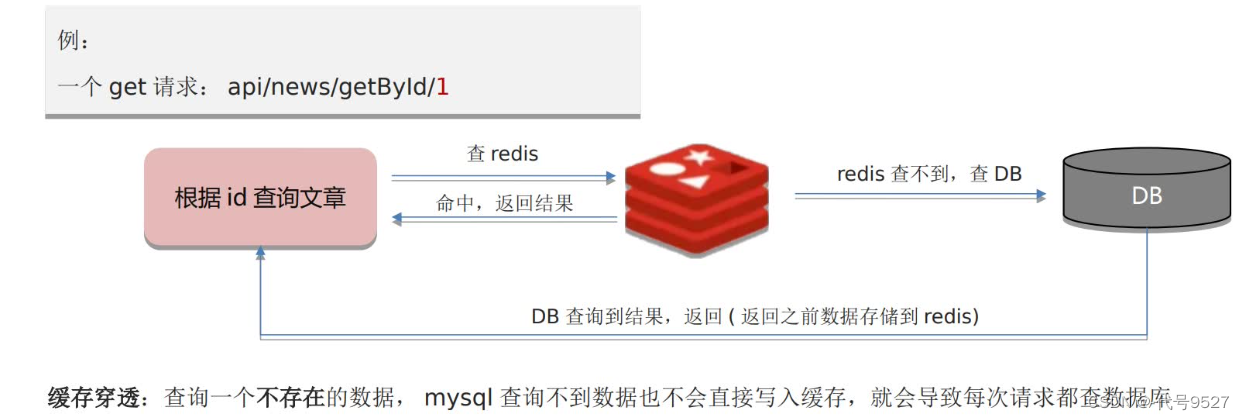
解决方案一:缓存空数据

查到的结果为空也写进Redis。实现简单但消耗内存,可能会发生不一致的问题(即库里有数据了,但缓存里依旧是null,导致查不到最新数据)
解决方案二:布隆过滤器
缓存预热的时候,往布隆过滤器中添加数据。后面请求过来时,先经过布隆过滤器,判断ID不存在的话,直接返回,都走不到Redis。
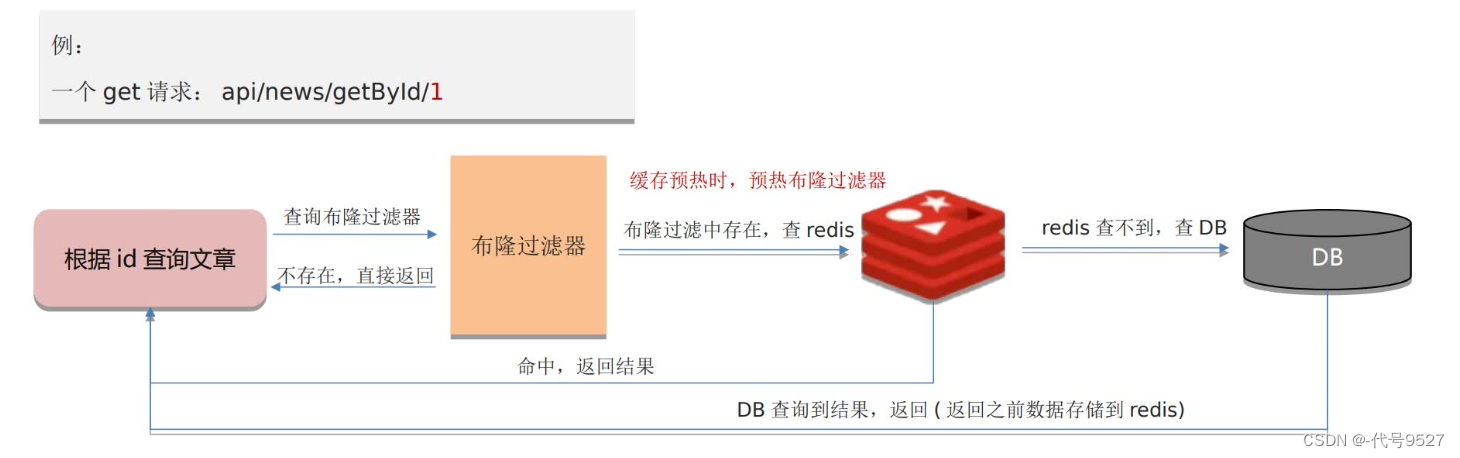
如此,内存占用少,但实现复杂,且存在误判(即有的ID不存在,但布隆过滤器会判断为存在)

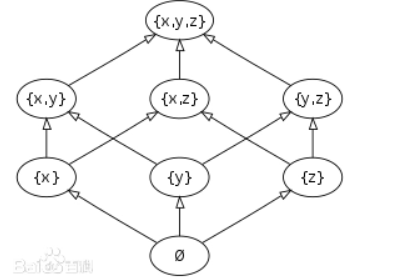
bitmap(位图):一个bit数组,每个单元非0即1。预热ID的时候,用多个hash函数获取该ID的hash值,并把bitmap对应位置改为1。后面查数据是否存在时,就用相同的hash函数获取hash值,查看对应的位置是否都为1。由此,布隆过滤器实现了检索一个元素是否在一个集合中。
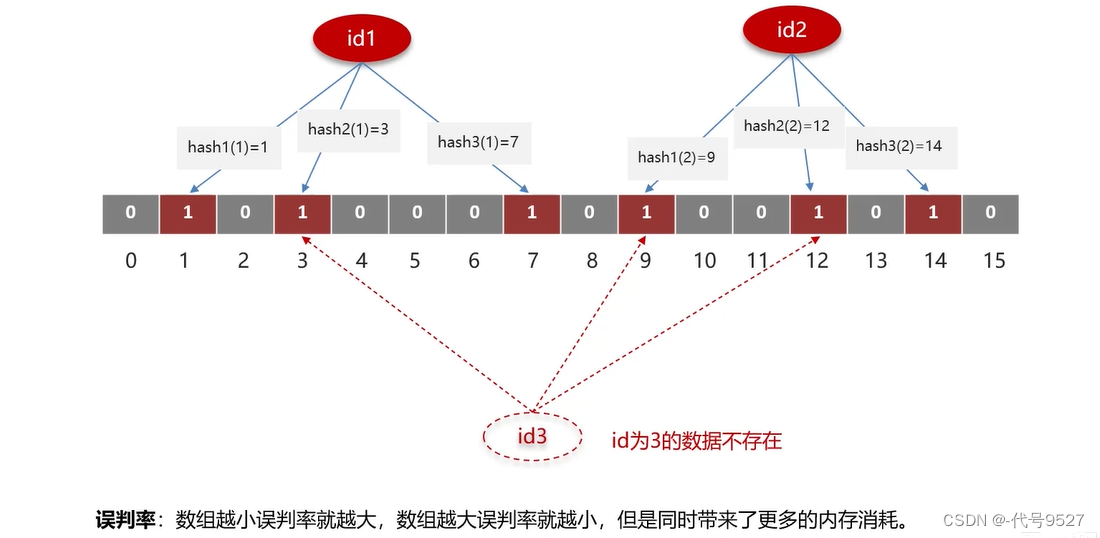
如上,id1和id2点亮了1、3、7和9、12、15的位置为1,id3虽然不存在,但其hash值所在位置都为1,判定为是存在的ID,即误判。数组越大,误判率越低。
2、缓存击穿:热点key过期
给一个热点key设置了过期时间,当这个key过期的时候,恰好有大量请求查这个key,这些请求自然都走到了数据库,可能导致DB服务不可用。如下图,比如查询一次MySQL再写到Redis需要50ms,热点数据过期后,这50ms内的大量请求都会冲到数据库

解决方案一:添加互斥锁
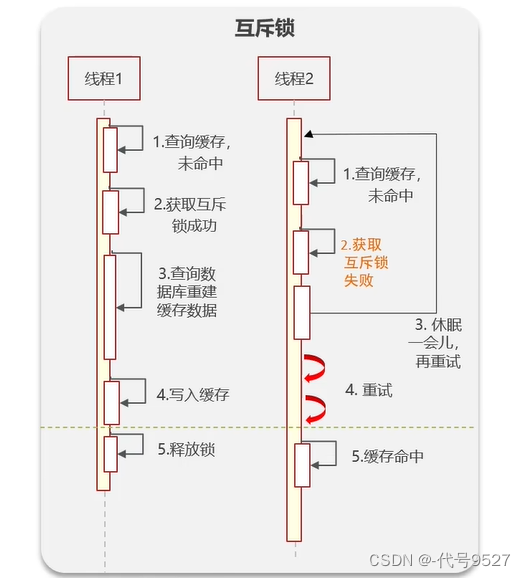
缓存未命中,查库前,获取一个互斥锁,获取不到则一直重试,如此,后面的线程走不到查库这一步,直到线程1完成查库+写入Redis,其余线程就会命中缓存。如此,保护了数据库服务且保证了数据强一致性,但性能不好
解决方案二:逻辑过期
Redis层面,不设置过期时间,但业务层面加一个过期时间,如
| key | value |
|---|---|
| 001 | {“id”:“123”,“title”:“标题1”,"expire":1716368322} |

即明天16:58的时候,这条数据逻辑过期,但你在Redis中还能查到,不过是查到了过期数据,不是最新的。具体流程:
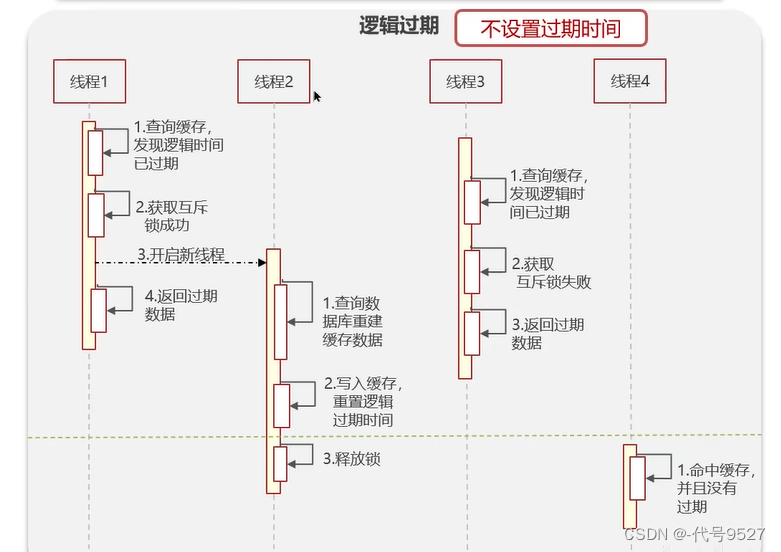
线程1过来查缓存,发现当前时间超过了缓存的逻辑过期时间,于是线程1获取一个互斥锁,再开启一个线程2去查库 + 更新缓存,自己则先把过期数据返回。此过程中,即使有线程3进来,并发现了已超过逻辑过期时间,它也不会重复去查库重建缓存,因为它获取不到互斥锁,此时线程3会先返回过期数据。 因此,这种方式性能好,但数据一致性不保证。
3、缓存雪崩:大批key同时过期
同一时间段,大量缓存的key过期,或者Redis服务宕机,导致大量请求冲到数据库

解决思路是:给不同的key添加随机的TTL(过期时间),如此,大量的key不会同时过期。至于Redis宕机,则可以用Redis哨兵模式或者集群模式、给业务添加多级缓存等方式解决。
最后,降级限流,可用于解决缓存穿透、击穿、雪崩的解决。即服务请求失败次数到一定阈值,直接走降级策略(比如不查库,直接返回空)
//Tips:
穿透无中生有key,布隆过滤null隔离
缓存击穿过期key,锁与非期解难题
雪崩大量过期key,过期时间要随机
面试必考三兄弟,可用限流来保底
4、双写一致性
相关问题:MySQL和Redis的数据如何进行同步。两种追求:
- 一致性高
- 允许一定的一致延迟
4.1 要求高一致性

读操作:命中直接返回。未命中缓存则 查库 + 写入缓存
写操作:数据库更新时,进行延时双删

有数据库的写操作时,为了数据一致性,如果不双删,只删一次缓存 + 改库,则实现方式可以是:
- 先删缓存,再改库
- 先改库,再删缓存
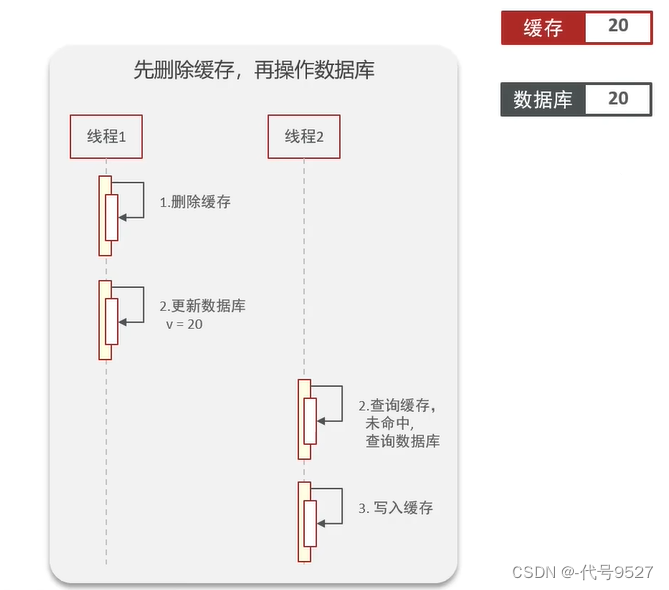
1)若先删缓存,再改库:
理想状态为:线程1删缓存,再更新数据库,后面请求过来(对应线程2),先查缓存,未命中,去查库 + 写入缓存,一切正常
再看非理想状况:线程1删除缓存后挂起,此时缓存为null,库中为10。然后新的请求进来(对应线程2),CPU切到线程2执行,查缓存未命中,线程2去查库 + 写入缓存,线程2执行结束,此时缓存为10,库中为10。最后线程1解除挂起,继续执行,线程1去更新了数据库,此时缓存为10,库中为20 ,数据不一致!
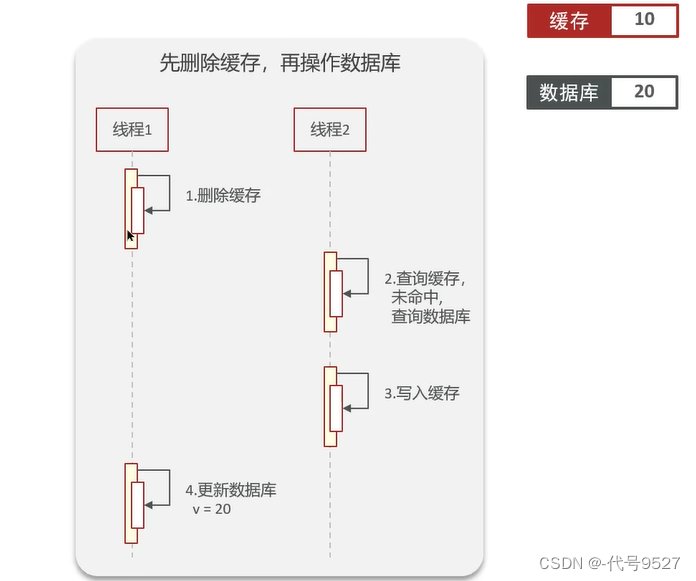
总之,高并发下,线程交替执行,这样实现会出现数据不一致问题。
2)若先改库,再删缓存
理想状态为:线程2更新数据库,再删缓存,此时缓存为null,库中为20。后面请求过来(对应线程1),先查缓存,未命中,去查库 + 写入缓存,一切正常
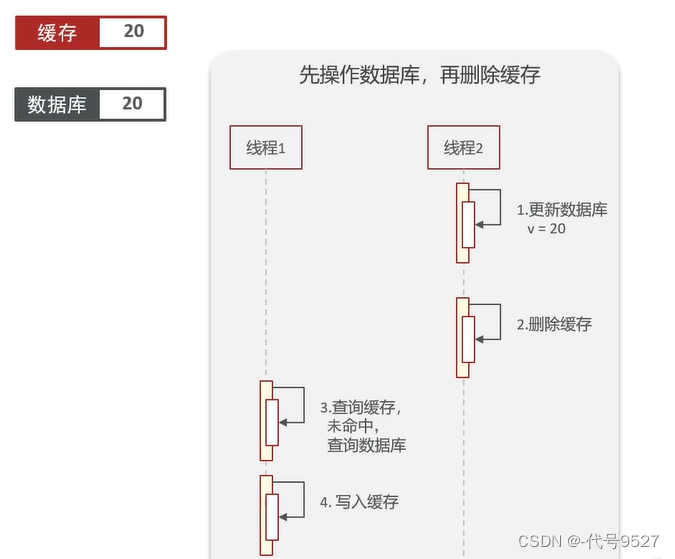
非理想状态下:比如一开始缓存过期,即缓存中为null,库中为10,线程1进来未命中缓存,查库得到10,然后挂起。请求2进来(对应线程2),其进行了update,改库,并删缓存,此时,库中为20,缓存中为null。线程2执行结束,线程1解除挂起继续执行,将查到的数据,写入缓存。此时缓存中为10,库中为20,数据不一致。
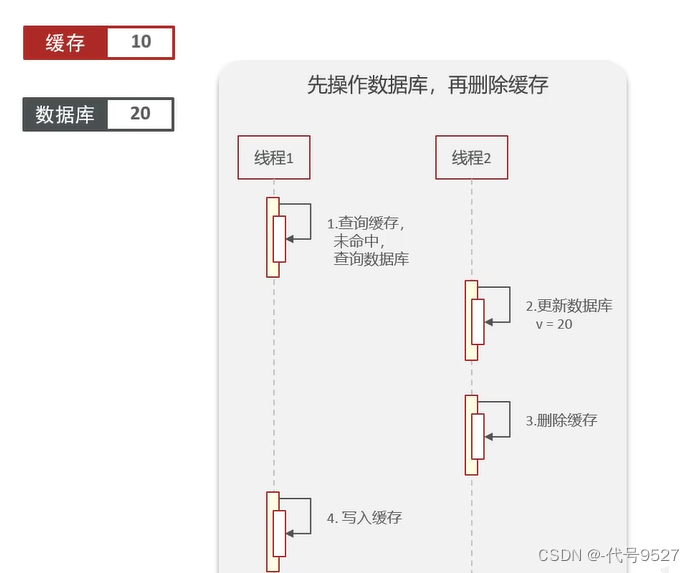
因此,不管先删缓存还是先改库,都可能出现数据不一致
==> 延时双删:先删缓存,数据库更新完后,再删一次缓存。至于为什么要延时后第二次删,是因为如果数据库是主从模式,读写分离,那就需要等主节点把数据同步到从节点。但这个延时的大小不好控制,还是可能出现脏数据。想强一致,可用分布式锁。
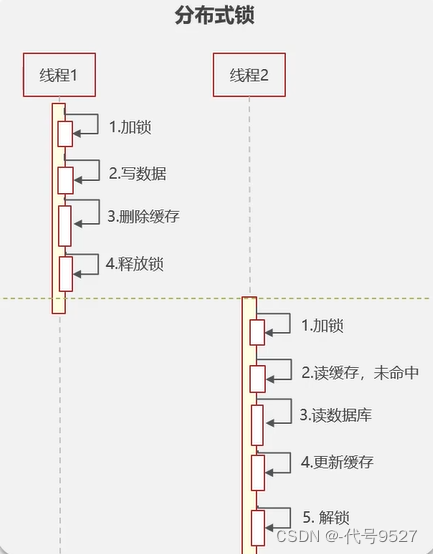
一个线程在更新数据前,加锁,update库 + 删缓存后,释放锁。期间,其余线程不能读写。以上可优化为:读数据的时候,添加共享锁,读读共享,读写互斥。写数据的时候,加排他锁,阻塞其他线程的读和写。如此,实现数据强一致性,但性能低。
4.2 允许一定的一致延迟
异步通知,保证数据的最终一致性。业务服务更新库后,发消息到MQ,缓存服务监听MQ,去更新缓存

以上实现对业务代码有一定的侵入性,需要添加发消息的代码。可把MQ替换为Canal:
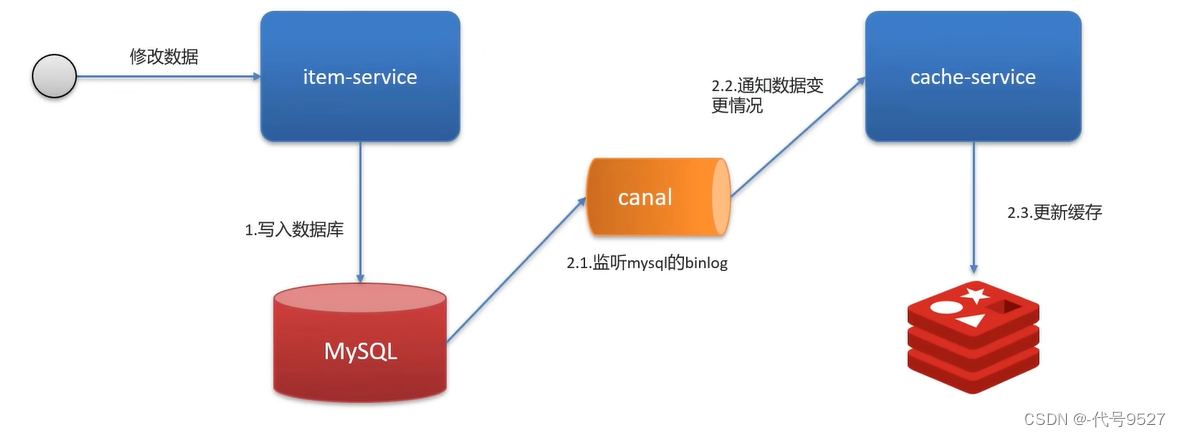
阿里的Canal基于MySQL的主从同步实现。数据库一旦发生改变,二进制的binlog记录DDL语句和DML语句,Canal伪装成MySQL的一个从节点,监听读取MySQL的binlog去更新缓存。此方式不用改业务代码,无侵入性。
最后,如果不要求实时性和强一致性,如热点文章数据,可用异步方案同步数据。如果要求数据强一致性,如抢券的库存,则采用redisson提供的读写锁保证数据同步。
5、面试