分词处理
- 1、token(词汇单元)
- 2、Tokenizer(分词)
- 3、ElasticSearch 分词器(Analyzer)
- 4、分词工具
- 停用词(Stop words)
1、token(词汇单元)
“token”主要用于文本数据的预处理阶段,将文本拆分为基本的词汇单元;“embedding”主要用于将离散的词汇单元连续向量化表示,以便在复杂的机器学习模型中进行处理;“encoding”则主要用于将文本数据转换为神经网络等深度学习模型可处理的向量表示。在自然语言处理(NLP)中,token是指文本中最小的语义单元。比如,一个句子可以被分割成若干个单词,每个单词就是一个token。例如,“I love you”这个句子可以被分割成三个token:“I”,“love”和“you”。token可以帮助我们把文本分解成更容易处理和分析的部分。
- token:模型输入基本单元。比如中文BERT中,token可以是一个字,也可以是等标识符。
- embedding:一个用来表示token的稠密的向量。token本身不可计算,需要将其映射到一个连续向量空间,才可以进行后续运算,这个映射的结果就是该token对应的embedding。
- encoding:表示编码的过程。将一个句子,浓缩成为一个稠密向量,也称为表征,(representation),这个向量可以用于后续计算,用来表示该句子在连续向量空间中的一个点。理想的encoding能使语义相似的句子被映射到相近的空间。
2、Tokenizer(分词)
参考:https://zhuanlan.zhihu.com/p/649543347
通常情况下,Tokenizer有三种粒度:word/char/subword
word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .]
character:按照单字符进行分词,就是以char为最小粒度。 如:Today is sunday. 则会分割成[t, o, d,a,y, … ,s,u,n,d,a,y, .]
subword:按照词的subword进行分词。如:Today is sunday. 则会分割成[to, day,is , s,un,day, .]
可以看到这三种粒度分词截然不同,各有利弊。常见的子词算法有Bye-Pair Encoding (BPE) / Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece等。
SentencePiece:SentencePiece它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece除了集成了BPE、ULM子词算法之外,SentencePiece还能支持字符和词级别的分词。
Tokenizer包括训练和推理两个环节。训练阶段指得是从语料中获取一个分词器模型。推理阶段指的是给定一个句子,基于分词模型切分成一连串的token。
概括:
1.分词粒度: 根据不同的切分粒度可以把tokenizer分为,基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。
2. subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。
3. 完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后处理。
4. SentencePiece是一个分词工具,内置BEP等多种分词方法,基于Unicode编码并且将空格视为特殊的token。这是当前大模型的主流分词方案。

作用:
1.分词。tokenizer将字符串分为一些sub-word token string,再将token string映射到id,并保留来回映射的mapping。从string映射到id为tokenizer encode过程,从id映射回token为tokenizer decode过程。映射方法有多种,例如BERT用的是WordPiece,GPT-2和RoBERTa用的是BPE等等,后面会详细介绍。
2.扩展词汇表。部分tokenizer会用一种统一的方法将训练语料出现的且词汇表中本来没有的token加入词汇表。对于不支持的tokenizer,用户也可以手动添加。
3.识别并处理特殊token。特殊token包括[MASK], <|im_start|>, <sos>, <s>等等。tokenizer会将它们加入词汇表中,并且保证它们在模型中不被切成sub-word,而是完整保留。
子词分词:
-
Byte Pair Encoding (BPE)
Byte-Pair Encoding(BPE)是最广泛采用的subword分词器。
训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
编码方法:将文本切分成字符,再应用训练阶段获得的合并规则
经典模型:GPT, GPT-2, RoBERTa, BART, LLaMA, ChatGLM等 -
WordPiece
Google的Bert模型在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
bert用的是wordpiece, wordpiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频字节对。WordPiece算法也是每次从词表中选出两个子词合并成新的子词。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。 总结来说,WordPiece每次选择合并的两个子词,通常在语料中以相邻方式同时出现。 比如说 P(ed) 的概率比P(e) + P(d)单独出现的概率更大,可能比他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性。 -
Unigram Language Model (ULM)
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。

如何使用上述子词算法?一种简便的方法是使用SentencePiece,它是谷歌推出的子词开源工具包,其中集成了BPE、ULM子词算法。除此之外,SentencePiece还能支持字符和词级别的分词。更进一步,为了能够处理多语言问题,sentencePiece将句子视为Unicode编码序列,从而子词算法不用依赖于语言的表示。https://zhuanlan.zhihu.com/p/191648421
3、ElasticSearch 分词器(Analyzer)
ES内置了多种分词器,standard分词器是默认分词器,按词拆分、小写;simple分词器:按非字母拆分,小写,过滤非字母;wihtespace分词器:按空格分词。IK分词器是推荐较多的中文分词器,支持粗力度和细粒度分词,需要安装插件使用。
分词器的组成
分词器是专门处理分词的组件,分词器由以下三部分组成:
Character Filters:针对原始文本处理,比如去除 html 标签
Tokenizer:按照规则切分为单词,比如按照空格切分
Token Filters:将切分的单词进行加工,比如大写转小写,删除 stopwords,增加同义语
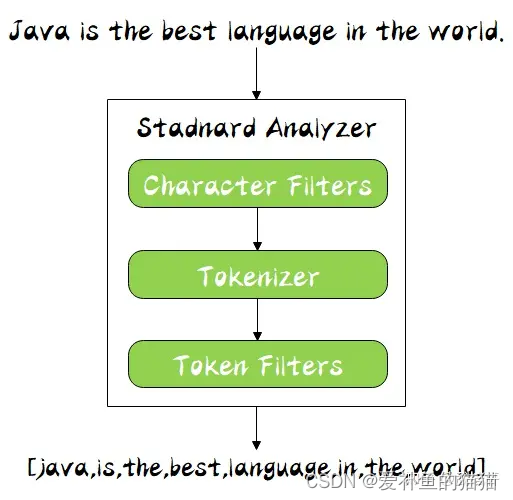
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
其中,ES 内置了许多分词器:
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Pattern Analyzer - 正则表达式,默认 \W+
Language - 提供了 30 多种常见语言的分词器
Customer Analyzer - 自定义分词器
4、分词工具
分词器简单而言就是将字符序列转化为数字序列,对应模型的输入。
分词器是用来实现分词的,分词器由三部分组成:字符过滤器、分词器和Token过滤器,字符过滤器:对原始文本进行过滤;分词器:按照一定规则进行分词;Token过滤器:对分词进行处理,转小写,移除停用词,添加同义词。
分词器由Character Filter、Tokenizer和Token Filter三部分组成,其工作流程依次为Character Filter、Tokenizer和Token Filter,其中Character Filter和Token Filter可以为空。

一、中文分词工具
https://cloud.tencent.com/developer/article/1747734
(1)Jieba
(2)snowNLP分词工具
(3)thulac分词工具
(4)pynlpir 分词工具
(5)StanfordCoreNLP分词工具
(6)Hanlp分词工具
哈工大LTP、中科院计算所NLPIR、清华大学THULAC、jieba
二、英文分词工具
- NLTK:
- SpaCy:
- StanfordCoreNLP
在目前的分词技术中,有几个比较流行和广泛应用的分词工具。下面介绍一些比较常用的分词工具,以供参考。
- 结巴分词(jieba):结巴分词是基于Python的中文分词工具,具有功能强大、速度快、准确度高等特点。它支持三种分词模式:精确模式、全模式和搜索引擎模式,并且可以通过调用不同的AI实现不同的分词功能。
- LTP(Language Technology Platform):LTP是一种基于深度学习的中文自然语言处理工具包,其中包括了分词、词性标注、命名实体识别等多个功能模块。LTP的分词模块采用了深度学习方法,具有较高的准确度和鲁棒性。
- NLTK(Natural Language Toolkit):NLTK是一个Python库,提供了丰富的自然语言处理功能。其中包括了中文分词的功能,可以通过调用NLTK的分词模块实现中文分词。
- HanLP:HanLP是由人民日报社自然语言处理与社会人文计算实验室开发的一套自然语言处理工具。其中包括了中文分词功能,并且支持多种分词算法,如基于最大熵模型和条件随机场等。
- THULAC:THULAC(THU Lexical Analyzer for Chinese)是由清华大学自然语言处理与社会人文计算实验室开发的一套中文词法分析工具。它具有较高的准确度和速度,适用于大规模中文文本的分词任务。
以上仅是介绍了一些常用的中文分词工具,每个工具都有其优势和适用的场景。在选择使用哪个分词工具时,可以根据具体的需求和任务来进行选择。建议可以对比不同工具的分词效果、效率和易用性等方面,并结合自己的需求来做出选择。
比较 :
准确率、社区活跃度、适应范围、速度等。北京大学PKUse和清华大学THULAC可供参考。
可根据个人不同的需求去选择不同的分词工具。将自己的语料实际放进去看一下最后的结果。
这样会给你一些参考价值。综合速度、社区活跃度、更新频率和语料结果,
个人更倾向于jieba分词,专业的领域交给专业的团队去做。
只有Thulac的结果比较特别,StanfordCoreNLP的运行占用大量内存和CPU,
尝试另一句话‘这本书很不错’,jieba无法分出‘本’,其他都可以完整分词,
不过StanfordCoreNLP依然占用大量内存和CPU。
https://github.com/ysc/cws_evaluation
1、一个好的分词工具不应该只能在一个数据集上得到不错的指标,而应该在各个数据集都有很不错的表现。从这一点来看,thulac和ltp都表现非常不错。
2、因为分词是个基础部件,分词速度对于一个分词工具来说也至关重要。从这一点来看,thulac和jieba表现的不错。
3、大家都知道,基本的分词依赖模型,但真正想用分词工具来解决应用层面上的问题,都需要借助于词库,本文测试的4个工具均支持用户自定义词库。
4、特别需要强调的一点是,哈工大的ltp支持分词模型的在线训练,即在系统自带模型的基础上可以不断地增加训练数据,来得到更加丰富、更加个性化的分词模型。https://www.sohu.com/a/120375125_465975
停用词(Stop words)
停用词(Stop words)是指在文本处理过程中被忽略或删除的常见词汇。这些词汇通常是频繁出现的功能词或无实际意义的词语,例如介词、连词、冠词、代词等。停用词通常对于文本的含义分析没有太大贡献,且会占据大量的存储空间和计算资源。因此,在文本处理任务(如文本分类、信息检索等)中,常常会预先定义一组停用词,并在处理过程中将它们从文本中移除。停用词的具体内容可以根据任务的特定需求而定,通常包括例如:“a”, “an”, “the”, “is”, “are”, “and”, "of"等常见词汇。选择停用词列表时,需要综合考虑语言的特点、任务的领域和目标等因素。
大语言模型的词表扩充
LLaMA词表中的中文token比较少(只有几百个)。为了解决这些问题,我们可能就需要进行中文词表扩展。比如:在中文语料库上训练一个中文tokenizer模型,然后将中文 tokenizer 与 LLaMA 原生的 tokenizer 进行合并,通过组合它们的词汇表,最终获得一个合并后的 tokenizer 模型。







![BUUCTF---web---[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/2ba7118cdddd4d90b3e3bca0611d8bec.png)