📢📢📢📣📣📣
哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝
一位上进心十足的【Java ToB端大厂领域博主】!😜😜😜
喜欢java和python,平时比较懒,能用程序解决的坚决不手动解决😜😜😜✨ 如果有对【java】感兴趣的【小可爱】,欢迎关注我
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
————————————————如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。
全球AI新闻速递
1.百川智能:发布Baichuan 4及首款AI智能助手百小应。
2.讯飞星火API能力正式免费开放。
3.科技巨头承诺安全开发AI模型:极端风险启动“紧急停止开关”。
4.腾讯云 AI 代码助手限时免费公测。
5.欧盟:首部《人工智能法案》批准。
6.LVMH宣布和阿里巴巴深度合作,AI模型优化高端零售体验。
7.微软:发布最新语言模型系列Phi-3。
8.好莱坞CAA 与Veritone合作推出数字化名人形象库CAAvault,保护名人形象权。
9.微软:PowerToys 新增“高级粘贴”功能。
10.谷歌:开始测试AI答案中广告功能。
11.国内大模型接连降价,李开复表态技术为先:宁走国外市场,也不参与“价格战”
12.北京:推进数字疗法、AI 辅助治疗等产品研发应用,支持医疗大模型开发、落地
13.编写脚本、生成和优化视频广告,TikTok 推出 Symphony AI 套件
14.亚马逊与 AI 公司 Hugging Face 合作:定制芯片低成本运行 AI 模型
15.OpenAI 和新闻集团签署多年协议,ChatGPT 可引用《华尔街日报》等媒体内容
16.百度文心一言上线新功能「智能配图」 会员用户可无限次使用。
人工智能的未来
AI 的内心深处

我们仍在尝试了解我们大脑的内部运作方式。但研究人工智能如何“思考”就像窥探外星物种的思维一样。人工智能开发人员知道他们的模型是有效的,但如果问他们它们是如何工作的,你只能得到有根据的猜测。
Anthropic 的研究人员相信他们距离找到确切答案又近了一步:他们着手解决多年来困扰计算机科学家的一个谜团。神经网络为何能够将原始信息拼凑在一起,从而理解我们世界中更复杂的模式?
工作原理:研究人员试图通过分析模型的神经元簇(有时称为特征)来绘制模型的“大脑”。首先,他们为人工智能创造了一种方法,告诉我们当我们提出某些问题时哪些功能会被激活——有点像在核磁共振成像过程中大脑的不同部分是如何发光的。
然后,他们试验了如果放大某些特征会发生什么。这导致了一些奇怪的行为:当他们增强金门大桥的某个特征时,克劳德感到困惑,并认为这是“标志性大桥本身”。但真正的目标是做相反的事情——找出一种方法来安静神经网络中我们不想激活的某些部分。
为什么这很重要:现在,像克劳德这样的模型很容易说出有偏见、不正确甚至危险的信息。但是,如果你可以配制一种数字药丸来抑制产生有毒物质的途径呢?通过屏蔽网络的这些区域,Anthropic 能够阻止 Claude 生成欺骗性和危险的内容——这是构建更安全模型的重大突破。
LLM 是 ERP 技术的未来吗?

大型语言模型 (LLM) 和 ERP 技术——这两个系统的结合被视为 ERP 领域的未来,目前仍处于初始开发的早期阶段。
将法学硕士 (LLM) 整合到企业技术平台中似乎是显而易见的;法学硕士 (LLM) 可以处理大量数据,从本质上为自动化解决方案奠定了基础。安永似乎意识到了其潜在价值,于 2023 年 9 月推出了其人工智能平台 EY.ai,并与我们分享了新的协作努力带来的好处。安永英国和爱尔兰的首席信息官 Catriona Campbell 分享了成功开发 EY.ai 所需进行的内部变革程度,其中包括向其员工推出法学硕士 (LLM)。
“我们对EY.ai投资的一部分是向我们整个 400,000 名员工推出 EYQ(一种大型语言模型)。这是世界上第一个也是最大的私人 GenAI 实施之一。初步证据显示,EYQ 正在推动 EY 的生产力提高 40%,预计在未来 12 个月内将提高到 100%。”
安永在 18 个月内向 EY.ai 投资了 14 亿美元,目标是创建一个统一平台,将安永自身的业务经验与人工智能技术相结合,帮助企业采用人工智能解决方案。
通过在 EY.ai 内部培育商业联盟生态系统,安永可以将其合作伙伴的集体业务和技术知识与自己的 AI 能力相结合,通过采用 AI 为业务转型提供更有效、更全面的方法。商业联盟包括戴尔科技、IBM、微软、SAP、ServiceNow、汤森路透和 UiPath,以及其他一些挥舞 AI 旗帜的公司。
Campbell 继续说道:“该平台将安永团队在战略、转型、风险、保证和税务方面的丰富业务经验与安永技术平台和 AI 功能相结合,帮助客户自信地采用 AI,同时应对其挑战。安永团队使用该平台为客户提供差异化的 AI 服务和解决方案。”
最终,EY.ai 的能力可以证明利用 ERP 技术开发法学硕士的潜力。与 GenAI 功能协同工作时生产力的提升可以成为企业拥抱创新所需的推动力。
欧盟签署人工智能法
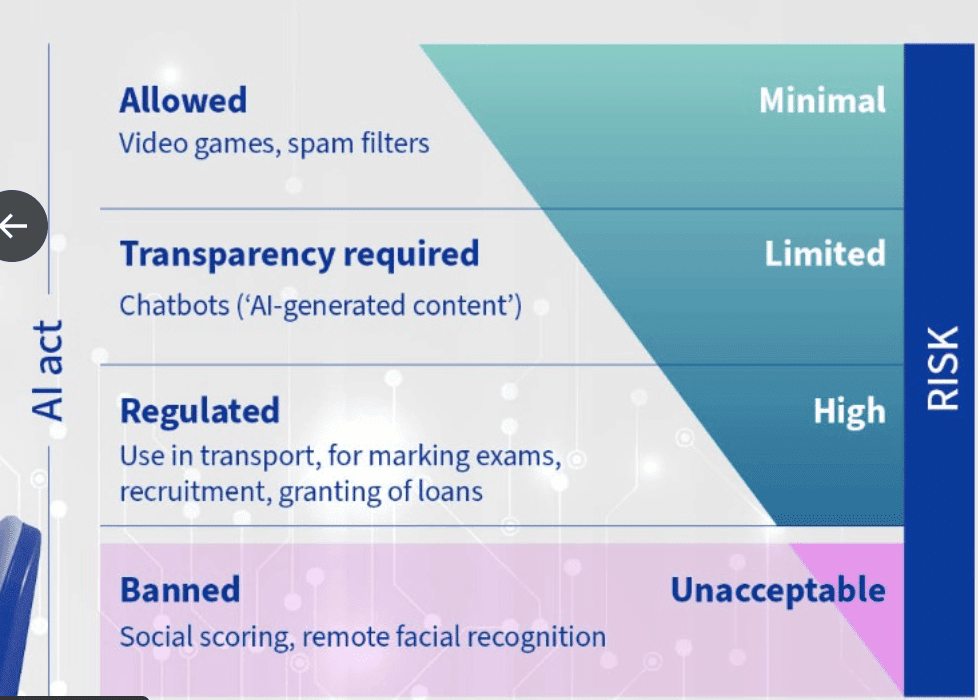
欧盟部长批准一项具有开创性的欧盟法律,为敏感领域的人工智能使用制定了规则。执法和就业等领域的人工智能系统必须透明、准确、安全并使用高质量数据。高风险的人工智能系统在欧盟使用前需要获得认证,而某些系统(如中国的社会信用评分)是被禁止的。实时人脸识别一般是被禁止的,但在特定的执法案件中是允许的。
低风险的人工智能系统必须披露其内容是由人工智能生成的。欧盟委员会下属的“人工智能办公室”将负责执行该法律,该法律将在发布后 20 天生效,大多数规则将在两年内生效。
人工智能与生产力
互联网上最值得讨论的问题之一是节省时间
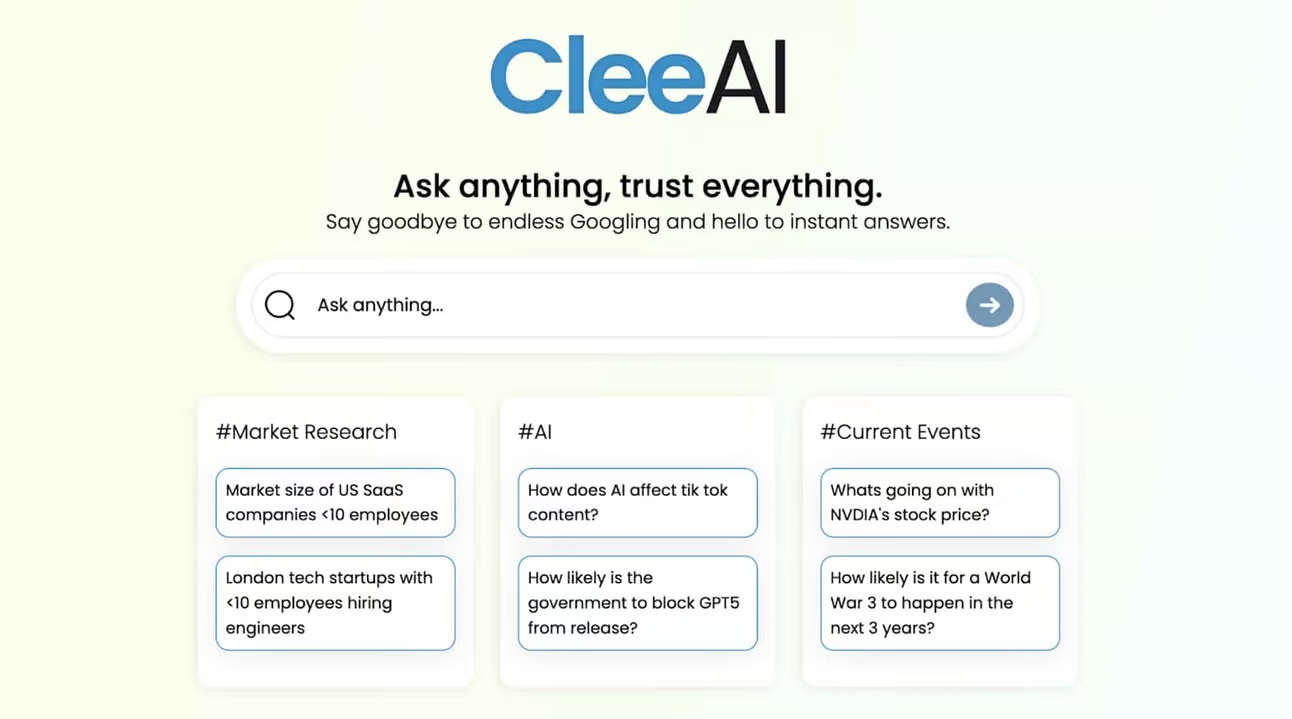
CleeAI 凭借其先进的情境感知和对准确性的承诺,重新定义了您在数字时代查找可靠信息的方式。您可以跳过滚动和事实核查,在几秒钟内直接获得准确且有来源的信息。
您可以通过以下方式使用 CleeAI 获取更好的信息:
1.注册:前往 CleeAI网站并注册;
2.生成准确的响应:使用搜索栏查找您正在寻找的信息;
3.实时检索: CleeAI 将从实时来源生成事实和信息列表;
4.来源优先:点击来源即可获取引用的来源链接;
5.分享:与您的团队分享答案。
CleeAI 消除了不断搜索和事实核查的需要,帮助您找到更好的答案,同时节省大量时间。
Salesforce 如何利用自己的技术在一个季度内节省 50,000 小时的工作时间

人工智能正在改变我们的工作方式——当我们有效地将人工智能融入我们的劳动力战略时,员工和公司都将受益匪浅。在 Salesforce,创新是一项核心价值,我们已经看到员工对利用人工智能的兴趣体现了这一点。
我们现在已经部署了 50 多种人工智能工具来帮助我们的员工提高工作效率。根据员工反馈,并与我们的人工智能委员会和首席信息官 Juan Perez 合作,我们优先考虑了四种企业范围的解决方案,旨在帮助增强目标设定、自动化日常任务、更快地查找信息和简化支持,同时让我们的员工成功 (ES) 和 IT 团队能够专注于更复杂的任务。
我们推出了一款名为 Einstein 的人工智能 Slack 应用,帮助 Salesforce 员工完成日常任务。例如安排和总结会议、回答一般问题以及规划外出活动。
根据 Slack 劳动力实验室的最新研究,办公室工作人员表示,他们 41% 的时间都花在了“低价值、重复性或对核心工作职能没有意义”的任务上。这款直接内置于 Slack 中的应用可以帮助我们的员工将精力集中在更有价值的工作上。
在一个季度内,该应用程序处理了近 370,000 个查询,在短短三个月的时间内为员工用户节省了约 50,000 小时的时间。
Project BaseCamp 在网络上创建单一、无缝的数字工作场所
Gartner最近的一项调查发现,“47% 的数字工作者很难找到有效完成工作所需的信息或数据。”在 Salesforce,我们希望确保这不会成为生产力的障碍 — 因此我们创建了 Project Basecamp。
Project BaseCamp 将成为 Salesforce 员工搜索和获取支持、新闻、活动、任务和培训的唯一目的地——所有这些都根据他们的工作地点和身份进行个性化设置。
BaseCamp由Experience Cloud和Unified Knowledge 提供支持,并由 Einstein 生成答案,它使用 AI 搜索多个信息存储库并生成员工问题的答案,例如“如何更换丢失的徽章?”如果员工需要支持,他们可以从同一界面记录工单 — 减少上下文切换并更快地获得答案。
BaseCamp 以我们从人工智能驱动的Ask Concierge 应用程序中看到的生产力提升为基础 - 该应用程序已解决超过 88,000 个请求,并将问题解决时间从平均 48 小时缩短至仅 30 分钟 - 生产力大幅提高。
由 Einstein 提供支持的 V2MOM 可实现更深入的业务目标协调
Einstein 还在改变 Salesforce 最关键的流程之一:V2MOM。V2MOM(愿景、价值观、方法、障碍和衡量标准)是我们今年的业务计划。它让员工知道对他们的期望是什么、他们的表现如何,以及他们因取得成果而获得奖励。
现在,有了 Einstein 和我们增强的 V2MOM 工具,员工可以拥有一个数字助理来帮助制定清晰且可衡量的目标。当员工登录我们基于 Salesforce 构建的 V2MOM 工具时,他们可以向 Einstein 提出他们独特的愿景和目标,这将帮助制定基于其管理链 V2MOM 的计划。
结果是整个组织实现了更深层次的协调,这有助于我们更快地实现业务目标。自推出以来,85% 的员工已经使用新的 Einstein V2MOM 功能来增强他们的目标。
通过内置 Einstein,我们对技术代理和电子邮件的依赖减少了 50%,自助服务率达到 93%——其中 Einstein Chatbot 解决了 88% 的问题。
Experience Cloud 帮助新员工更高效地入职
我们希望新员工能够尽快感受到支持并提高工作效率,因此我们在 Experience Cloud 上建立了一个网站,让新员工可以访问福利信息、任务和快速链接,帮助他们开始 Salesforce 之旅。借助内置的 Einstein,我们对技术代理和电子邮件的依赖减少了 50%,自助服务率达到 93%——其中 Einstein Chatbot 解决了 88% 的问题。
Cohere 推出开放权重 AI 模型 Aya23,支持近二十种语言

加拿大企业人工智能初创公司Cohere的非营利研究机构Cohere for AI (C4AI)宣布发布 Aya 23 的开放权重,Aya 23 是一组全新的最先进的多语言语言模型。
有8B和35B参数变体(参数指的是AI 模型中人工神经元之间的连接强度,一般表示更强大、更有能力的模型)。Aya 23 是 C4AI 的 Aya 计划下的最新成果,旨在提供强大的多语言能力。
值得注意的是,C4AI 已开源 Aya 23 的权重。这些是 LLM 中的一种参数,最终是AI 模型底层神经网络中的数字,使其能够确定如何处理数据输入和输出什么。通过在这样的开放版本中访问它们,第三方研究人员可以对模型进行微调以满足他们的个人需求。同时,它还未达到完全开源的水平——其中训练数据和底层架构也会被发布。但它仍然非常宽容和灵活,与 Meta 的 Llama 模型类似。
Aya 23 以原始型号 Aya 101为基础,支持 23 种语言。其中包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语
与 Aya 一起打破语言障碍
尽管大型语言模型(LLM)在过去几年蓬勃发展,但该领域的大部分工作都是以英语为中心的。
因此,尽管大多数模型能力很强,但除了少数几种语言之外,其表现往往很差——尤其是在处理资源匮乏的语言时。
C4AI 研究人员表示,问题有两个方面。首先,缺乏强大的多语言预训练模型。其次,没有足够的涵盖多种语言的教学式训练数据。
为了解决这一问题,该非营利组织与来自 119 个国家的 3,000 多名独立研究人员共同发起了Aya 计划。该组织最初创建了 Aya Collection,这是一个庞大的多语言教学风格数据集,包含 5.13 亿个提示和完成实例,然后利用它开发了涵盖 101 种语言的教学微调法学硕士 (LLM)。
该模型 Aya 101于 2024 年 2 月作为开源 LLM 发布,标志着大规模多语言语言建模向前迈出重要一步,支持 101 种不同的语言。
但它是基于 mT5 构建的,而 mT5 在知识和性能方面现已过时。
其次,它的设计重点是覆盖范围——或者说覆盖尽可能多的语言。这使得模型的容量共享范围过广,以至于其在特定语言上的表现落后。
现在,随着 Aya 23 的发布,Cohere for AI 正在努力实现广度和深度的平衡。本质上,这些基于Cohere 的 Command 系列模型和 Aya Collection 的模型专注于为更少的语言(23 种)分配更多容量,从而改善跨语言的生成。
经评估,这些模型在涵盖的语言方面的表现优于 Aya 101,并且在广泛的判别和生成任务上优于 Gemma、Mistral 和 Mixtral 等广泛使用的模型。
通过这项工作,Cohere for AI 向高性能多语言模型又迈进了一步。
为了提供这项研究的访问权限,该公司根据知识共享署名-非商业性使用 4.0 国际公共许可证在 Hugging Face 上发布了8B和35B 型号的开放权重。
研究人员补充道:“通过发布 Aya 23 模型系列的权重,我们希望能够帮助研究人员和从业者推进多语言模型和应用。”值得注意的是,用户甚至可以在 Cohere Playground 上免费试用新模型。






![BUUCTF---web---[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/2ba7118cdddd4d90b3e3bca0611d8bec.png)