24年5月,北京大学、国防创新研究院无人系统技术研究中心、中国电信人工智能研究院联合发布了DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving。
DriveWorld在UniAD的基础上又有所成长,提升了自动驾驶目标检测、目标追踪、3D占用、运动预测及规划的性能,后期扩大数据集和调整骨干网络大小应该会收益不少。
DriveWorld集成了BEV、Occupancy、World Model、LLM、Probabilistic Generative Model等核心技术,个人认为质量很高,改善精进的空间也蛮高。
总之,都在为开发出安全、舒适的自动驾驶基础模型努力着。
Abstract
以视觉为中心的自动驾驶由于其成本较低,最近引起了广泛的关注。预训练对于提取通用表示至关重要。然而当前以视觉为中心的预训练通常依赖于2D或3D前置Pre-text任务,忽略了自动驾驶作为4D场景理解任务的时间特征。在本文中,引入一个基于世界模型的自动驾驶 4D 表示学习框架(称为 DriveWorld)来解决这一挑战,该框架能够以时空方式从多摄像头驾驶视频进行预训练。具体而言,提出了一个用于时空建模的记忆状态空间模型,该模型由动态记忆库模块和静态场景传播模块组成。动态记忆库模块用于学习时间-觉察潜在动态以预测未来变化,静态场景传播模块用于学习空间-觉察潜在静态以提供全面的场景上下文。我们还引入了一个任务提示,将任务-觉察特征解耦为各种下游任务。实验结果表明,DriveWorld 在各种自动驾驶任务上取得了可喜的成果。当使用 OpenScene 数据集进行预训练时,DriveWorld 在 3D 对象检测的 mAP 增加了 7.5%,在线构图的 IoU 增加了 3.0%,多目标跟踪的 AMOTA 增加了 5.0%,运动预测的minADE 降低了 0.1m,占用预测的 IoU 增加了 3.0%,规划的平均 L2 误差减少了 0.34m。
1.Introduction
自动驾驶是一项复杂的工作,它依赖于对4D场景的全面理解。
- Implicit Occupancy Flow Fields for Perception and Prediction in Self-Driving
- Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multimodal Foundation Models
这需要获得一个强大的时空表征,处理涉及感知、预测和计划任务。
- Planning-oriented Autonomous Driving
由于自然场景的随机性、环境可观测性以及下游任务多样性,学习时空表征是极具挑战性。
- Temporal Consistent 3D LiDAR Representation Learning for Semantic Perception in Autonomous Driving
- Spatiotemporal Self-supervised Learning for Point Clouds in the Wild
预训练在从海量数据中获取通用表示方面起着至关重要的作用,从而能够构建一个丰富了共同知识的基础模型。
- PiMAE: Point Cloud and lmage Interactive Masked Autoencoders for3D Object Detection
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learning multiple visual domains with residual adapters
- MVContrast: Unsupervised Pretraining for Multi-view 3D Object Recognition
- PonderV2: Pave the Way for 3D Foundataion Model with A Universa Pre-training Paradigm
然而,针对自动驾驶中时空表征学习的预训练研究相对有限。以视觉为中心的自动驾驶因其成本较低而受到越来越多关注。
### BEVDet、BEVDepth、BEVFormer、PETR、DETR3D、BEVerse
如图 1 所示,现有的以视觉为中心的预训练算法仍然主要依赖于2D或3D前置任务。
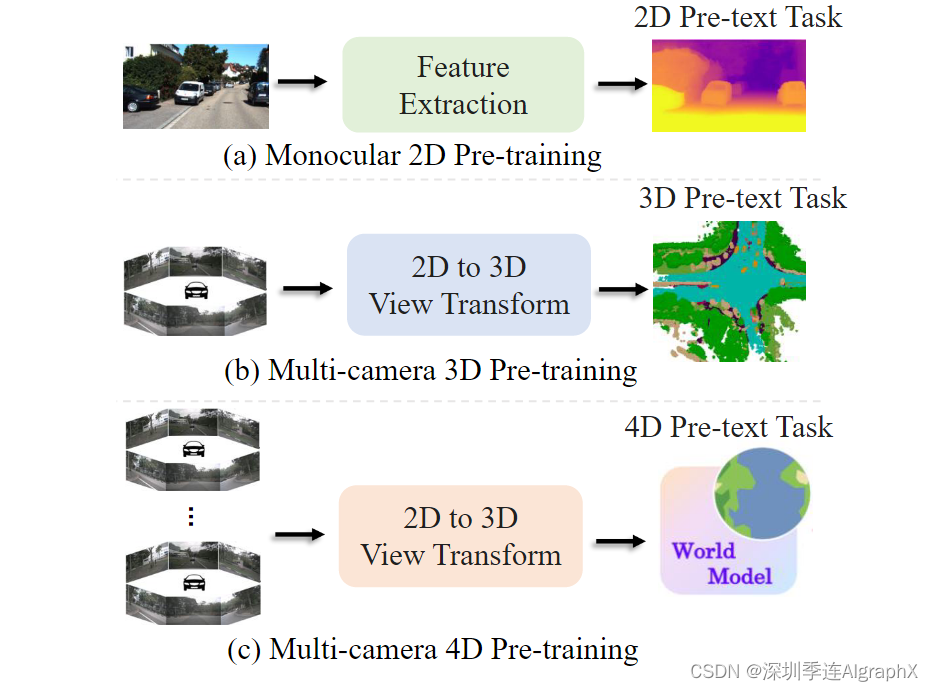
图 1. 视觉中心自动驾驶的不同预训练方法的比较。(a) 具有 2D 前置任务的单目 2D 预训练(例如,2D 分类和深度估计)。(b) 基于 3D 场景重建或 3D 对象检测的多摄像头 3D 预训练。(c) 基于世界模型的学习统一时空表示的 4D 预训练。
###Pre-text task也叫Surrogate Task,也有人译成代理任务。Pre-text可以理解为是一种为达到特定训练任务而设计的间接任务。
- Deep Residual Learning for lmage Recognition
- Is Pseudo-Lidar needed for Monocular 3D Object detection? (DD3D)
- Multi-Camera Unified Pre-training via 3D Scene Reconstruction
- Scene as Occupancy (OccNet)
- UNIPAD: A UNIVERSAL PRE-TRAINING PARADIGM FOR AUTONOMOUS DRIVING
DD3D已经证明了深度估计用于预训练的有效性。OccNet、UniScene和UniPAD进一步将预训练扩展到3D场景重建。然而,这些算法忽略了4D表示对于理解自动驾驶场景的重要性。
我们的目标是使用世界模型来解决以视觉为中心的自动驾驶预训练的4D表示。世界模型擅长于表示智能体对其环境的时空知识。在强化学习中,DreamerV1、DreamerV2和DreamerV3使用世界模型将智能体的经验封装在预测模型中,从而促进了通用行为的获取。MILE利用三维几何作为归纳偏置,直接从专家演示视频中学习一个紧凑的潜在空间,在CARLA模拟器中构建世界模型。ContextWM和SWIM使用丰富的野外视频预训练世界模型,以提高下游视觉任务的高效学习。最近,GAIA-1和DriveDream构建了生成世界模型,利用视频、文本和动作输入来使用扩散模型创建逼真的驾驶场景。与前面提到的关于世界模型的工作不同,我们的方法主要侧重于利用世界模型来学习用于自动驾驶预训练的4D表示。
驾驶本身就需要应对不确定性。在模糊的自动驾驶场景中有两种类型的不确定性:任意不确定性Aleatoric uncertainty,源于世界的随机性;认知不确定性Epistemic uncertainty,源于不完善的知识或信息。如何利用过去的经验来预测可能的未来状态,并估计关于自动驾驶世界状态的缺失信息,仍然是一个悬而未决的问题。在这项工作中,我们通过世界模型探索了4D预训练,以处理任意和认知不确定性。具体来说,我们从两个方面设计记忆状态空间模型来减少自动驾驶中的不确定性。首先,为了解决任意不确定性,我们提出了动态记忆库模块,用于学习时间感知的潜在动态以预测未来状态。其次,为了减少认知的不确定性,我们提出了静态场景传播模块,用于学习空间感知的潜在静态,以提供全面的场景上下文。此外,我们引入了任务提示,它利用语义线索作为提示,自适应地针对不同的驾驶下游任务调整特征提取网络。
为了验证我们提出的4D预训练方法的性能,我们对nuScenes训练集和最近发布的大规模3D占用数据集OpenScene进行了预训练,然后利用nuScenes训练集进行了微调。实验结果表明,与2D ImageNet预训练、3D占用预训练和知识蒸馏算法相比,我们的4D预训练方法具有优越性。它在以视觉为中心的自动驾驶任务中表现出了实质性的改进,包括3D物体检测、多物体跟踪、在线构图、运动预测、占用预测和规划。本工作的主要贡献如下:
- 提出了第一个基于世界模型的4D预训练方法,用于以视觉为中心的现实世界自动驾驶,该方法从多摄像头驾驶视频中学习紧凑的时空表示。
- 设计了记忆状态空间模型Memory State-Space Model,其中包括用于学习时间-觉察潜在动态的动态记忆库模块Dynamic Memory Bank module,用于学习空间-觉察潜在静态的静态场景传播模块Static Scene Propagation module,以及用于自适应各种任务条件特征提取的任务提示Task Prompt。
- 广泛的实验表明,DriveWorld的预训练有助于在以视觉为中心的感知、预测和规划任务中达到SOTA性能。
2. Related Work
2.1. Pre-training for Autonomous Driving
根据输入模态,自动驾驶预训练算法主要分为:大规模LiDAR点云预训练和图像预训练。大规模LiDAR点云的预训练算法可进一步分为对比学习方法、掩码自编码器方法和基于占用的方法。为了将3D空间结构融入以视觉为中心的自动驾驶,涉及深度估计的预训练方法已被广泛采用。
- Is Pseudo-Lidar needed for Monocular 3D Object detection? (DD3D)
- Policy Pre-training for End-to-end Autonomous Driving via Self-supervised Geometric Modeling
OccNet、UniScene、UniPAD和PonderV2已经通过3D场景重建引入了预训练。BEVDistill、DistillBEV、GeoMIM利用知识蒸馏从预训练的LiDAR点云检测模型中传递几何信息。然而,自动驾驶对4D场景的理解提出了挑战。我们提出了第一个基于世界模型的以视觉为中心的自动驾驶的4D预训练方法。
2.2. Spatial-Temporal Modeling for Autonomous Driving
在自动驾驶领域,时空建模一直是研究的热点。BEVFormer利用时空变换从多相机图像中学习BEV表示。BEVDet4D将BEVDet从纯空间三维扩展到时空四维空间。BEVStereo、STS和SOLOFusion通过利用时间多视图立体(MVS)解决了基于相机的3D任务中的深度感知挑战。PETRv2和StreamPETR利用稀疏对象查询对运动对象建模,实现长时间信息的高效传输。ST-P3和UniAD致力于通过时空特征学习构建端到端的基于视觉的自动驾驶系统。
2.3. World Models
世界模型使智能体能够从过去的经验和当前的观察中学习状态表示,从而预测未来的结果。世界模型在强化学习和自动驾驶中有广泛的应用。
- Exploring the Potential of World Models for Anomaly Detection in Autonomous Driving
- Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
- GAlA-1:A Generative World Model for Autonomous Driving
- Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
在强化学习中,2018年,Ha和Schmidhuber提出World Models,认为可以以无监督的方式快速训练世界模型,以学习环境的压缩时空表示。一些方法以获得奖励和与环境在线互动为前提,从世界模型紧致潜在空间中预测。
- Recurrent World Models Facilitate Policy Evolution
- Dream to Control: Learning Behaviors by Latent lmagination
- MASTERING ATARI WITH DISCRETE WORLD MODELS
- Mastering Diverse Domains through World Models
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion为自动驾驶中的点云预测任务建立无监督的世界模型。
在本文中,我们通过世界模型向机器人灌输预训练的时空表征,以感知周围环境并预测其他参与者的未来行为。
3. DriveWorld
考虑由多视角摄像机捕获的一系列观察到的T视频帧,表示 ,以及它们相应的专家动作
和3D占用标签
,这些可以借助LiDAR点云和姿态数据获得,我们的目标是通过世界模型学习紧凑的时空BEV表示,该模型可以根据过去的多摄像机图像和动作,预测当前和未来的3D占用。如图 2 所示,所设计的DriveWorld模型包括:
- 一个图像编码器Image Encoder
- 一个2D到3D视图变换View Transform,例如Transformers、LSS技术
- 一个记忆状态空间模型Memory State-Space Model,MSSM
- 动态记忆库模块Dynamic Memory Bank module学习时间感知的潜在动态
- 静态场景传播模块Static Scene Propagation module学习空间感知的潜在静态
- 一个解码器Decoder预测动作和3D占用
- 一个任务提示Task Prompt来调整不同任务的特征提取。

图 2. DriveWorld整体架构。由于自动驾驶严重依赖于对4D场景的理解,因此我们的方法首先涉及将多摄像头图像转换为4D空间。在提出的用于时空建模记忆状态-空间模型Memory State-Space Model中,我们有两个基本组成部分:动态记忆库(Dynamic Memory Bank)和静态场景传播(Static Scene Propagation),前者学习时间-觉察的潜在动态以预测未来状态,后者学习空间-觉察的潜在静态以提供全面的场景上下文。该配置促进了解码器的任务,即为当前和未来的时间步骤重建3D占用和动作。此外,我们设计了基于预训练文本编码器的任务提示,以自适应解耦各种任务-觉察特征。
3.1. Memory State-Space Model
随着自动驾驶汽车的移动,在其观察范围内依次传递两种类型的信息:与物体移动引起的场景变化相关的时间-觉察信息,以及与场景上下文相关的空间-觉察信息。如图 3 所示,为了分别处理这些动态智能体与空间场景进行4D预训练,我们提出了用于时间-觉察潜在动态的动态记忆库模块和用于空间-觉察潜在静态的静态场景传播模块。接下来,我们将首先介绍时间建模的概率模型,然后是动态记忆库模块和静态场景传播模块的详细介绍。

图 3. 记忆状态空间模型MSSM总体结构。MSSM将传输的信息分为两类:时间感知-觉察和空间-觉察信息。动态记忆库模块利用运动感知层归一化(MLN)对时间-觉察属性进行编码,并与动态更新的记忆库进行信息交互。同时,静态场景传播模块利用BEV特征来表示空间-觉察的潜在静态,直接传递给解码器。
##### 下面是模型实现的总结内容,由于没有代码验证,不对的地方,请各位帮忙斧正,谢谢!

如下图 6、MSSM另外一种表示方式:图模型。确定性状态 h 用正方形表示,而随机状态 s 用圆形表示。为了清晰起见,观测的状态以灰色突出显示。实线表示生成模型,而虚线表示变分推理variational inference。

Probabilistic Modelling
为了使模型具有时间建模的能力,我们首先引入两个潜在变量 ,其中
表示历史状态,
表示随机状态。
用过去历史
和随机状态
更新。
在观察图像时,可以利用过去和当前图像获得当前场景感知。然而,在预测未来时,在没有输入图像的情况下,我们仅依靠过去的历史和状态 来预测未来的状态。这种预测过程类似于概率生成模型。
为了预测未来,我们遵循循环状态空间PLAS模型,
- 构建后验状态分布
- 构建先验状态分布
目标是将先验分布(基于过去历史和状态的预期结果)与后验分布(由观察到的多摄像机图像和动作得出的结果)相匹配。

Dynamic Memory Bank

Static Scene Propagation
随着车辆的移动,场景的连续帧通常描绘最小的变化,突出的静态对象,如道路,树木和交通标志构成了场景的主要内容。将输入图像转换成一维矢量会导致关键信息的丢失。除了传递时间感知信息外,世界模型还应该能够对空间感知信息进行建模。(aware看成感知,感觉顺口一些)
如图 3 所示,我们从帧 1 到帧 T 中随机选择一帧 o',并使用其 BEV 特征 b' 构建描述空间感知结构的潜在静态表示 。我们以逐通道的方式将空间感知的潜在静态
和时间感知的潜在动态
结合起来。我们选择不使用warping操作,允许模型学习整个场景的鲁棒全局表示,并
专注于捕获运动信息。由于
是从BEV特征
中学习来的,所以在模型训练过程中,BEV特征同时获取静态场景和运动信息的表示。这种整体表示在随后的解码器网络中使用。
3.2. 3D Occupancy Prediction
为了全面了解自动驾驶中周围的场景,我们将物理世界建模为三维占位结构,利用占位的几何形式来描绘车辆周围的环境。
- Using occupancy grids for mobile robot perception and navigation
- Dfferentiable Raycasting for Self-supervised Occupancy Forecasting
- LiDAR-based 4D Occupancy Completion and Forecasting
- Occupancy Flow Fields for Motion Forecasting in Autonomous Driving
- Scene as occupancy
与其他重建输入2D图像的世界模型不同,3D占用解码器可以通过对基于视觉的模型进行预训练来引入周围世界的几何先验。与深度估计预训练不同,深度估计预训练主要代表物体表面,3D占用可以代表整个结构。此外,与MILE的BEV分割目标不同,它忽略了关键的高度信息,而3D占用提供了更全面的物体描述。三维占位解码器设为
![]()
其中mθ为将一维特征扩展到BEV维度的网络,lθ为预测占位的三维卷积网络。通过OccNet和UniScene等预训练算法,重建三维占位作为前置任务pre-text task已经被证明是有效的。与OccNet和UniScene相比,我们进一步扩展到4D占用预训练,通过时空建模引入额外的先验知识。
3.3. Task Prompt
虽然通过世界模型设计的前置任务能够学习时空表征,但不同的下游任务关注不同的信息。例如,3D目标检测任务强调当前的空间感知信息,而未来预测任务优先考虑时间感知信息。过度关注未来信息,例如车辆的未来位置,可能会对3D目标检测任务造成不利影响。
为了缓解这一问题,受少样本图像识别语义提示和多任务学习视觉范例驱动提示的启发,我们引入了“任务提示”的概念,为不同的大脑提供特定的线索,指导他们提取任务感知特征。考虑到不同任务之间存在的语义联系,我们利用大语言模型 (例如BERT, CLIP)来构建这些任务提示。例如,专注于当前场景的3D占用重建任务的任务提示符
设置为“该任务是预测当前场景的3D占用”。我们将提示符
输入到
中,得到提示符编码
。随后,我们使用AdaptiveInstanceNorm和CNN将其扩展到BEV的维度,记为
,将其与学习到的时空特征进行整合。
### 基于4D预训练的BEV特征图从当前和未来场景中都捕获了丰富的信息。然而,对于特定的下游任务,一些信息可能是多余的,甚至是有害的。可以利用任务提示来减轻冗余信息的影响。在在线地图构建任务中,特征地图以任务提示为导向,强调当前的空间感知信息。目标在特征图中具有更准确的位置信息,以达到更高的精度。对于运动预测任务,特征映射在任务提示的引导下,同时保存了空间和时间信息。目标在特征映射中覆盖更广的区域,从而实现更强的鲁棒性预测。
3.4. Pre-training Objective
DriveWorld的预训练目标包括:
- 最小化先验、后验状态分布之间的差异(即Kullback-Leibler,KL差异)
- 最小化过去和未来3D占用(即交叉熵损失CE)
- 以及动作相关损失(即L1损失)。
我们描述了在 T 个时间步上观察输入的模型,然后设想 L 步的未来 3D 占用率和动作。DriveWorld的整体损失函数为

对于OpenScene数据集,我们还利用L2损失进行占用流量预测。DriveWorld基于概率生成模型Probabilistic Generative Model。损失函数的详细推导请参见补充资料第6节。
### DriveWorld包括以下五个组成部分:

在这个贝叶斯概率模型中,推断随机潜在变量 ,通过深度变分推理而非蒙特卡洛来实现。参数化、KL散度、变分下界等技术及推导和验证与DDPM、LDM内容类似。请参见:
Probabilistic Diffusion Model概率扩散模型理论代码详细解读_哔哩哔哩_bilibili
51-33 LDM 潜在扩散模型论文精读 + DDPM 扩散模型代码实现-CSDN博客
3.5. Fine-tuning on Downstream Tasks
通过DriveWorld,我们获得了BEV的时空表征。具体来说,图像特征提取和生成BEV特征(即编码器)之间的网络是预训练的。在微调过程中,同时训练具有任务提示的编码器和解码器(即不同任务的头部网络)。
4. Experiments
4.1. Experimental Setup
Dataset
我们在自动驾驶数据集nuScenes和最大规模的3D占用数据集OpenScene上进行预训练,并在nuScenes上进行微调。评估设置与UniAD相同。
### 三维占用地面真值是通过融合多帧LiDAR点云得到。与单帧点云相比,这种方法提供了更全面的对象表示,包括遮挡区域的细节。随着3D重建技术的发展,使用NeRF、3D Gaussian Splatting和MVS(AA-RMVSNet、MVSnet)等技术,直接从自动驾驶视频中重建三维占用地面真值逐渐变得可行。
Pre-training
为了与BEVFormer和UniAD一致,我们采用ResNet101-DCN作为基础主干。对于3D占用率预测,我们建立了16 × 200 × 200的体素大小。学习率设置为2×10−4。默认情况下,预训练阶段包含24个epoch。模型在T = 4步上观察输入,未来预测被设置为L = 4步。
Fine-tuning
在微调阶段,我们保留了生成BEV特征和微调下游任务的预训练编码器。对于3D检测任务,我们采用BEVFormer框架,在不冻结编码器的情况下对其参数进行微调,并进行了24次epoch的训练。对于其他自动驾驶任务,我们使用了UniAD框架,并将我们微调的BEVFormer权重加载到UniAD中,所有任务都遵循标准的20 epoch训练协议。对于UniAD,我们遵循了它的实验设置,即在第1阶段进行6次训练,在第2阶段进行20次训练。实验采用8颗NVIDIA Tesla A100 gpu进行。
4.2. Ablation Studies
我们首先使用UniAD进行了彻底的消融研究(仅对第一阶段进行微调,队列长度为3以提高效率),并在nuScenes训练集上进行了预训练,以验证DriveWorld每个组件的有效性。
Component Analysis
我们首先验证了所提出的记忆状态空间模型(MSSM)模块的有效性。如表 1 所示,使用循环状态空间模型(Recurrent State-Space Model, RSSM)进行预训练导致3D检测性能明显变差。这是由于RSSM具有潜在动力学的 1D 张量,不能有效地保留上下文信息,从而在预训练期间导致模型中断。然而,当静态场景传播(SSP)集成到MSSM中时,使用BEV特征直接重建导致性能提高约1%。引入动态内存库(DMB)后,3D检测和在线构图性能下降,但跟踪性能有所提高。在运动预测任务中,广泛的感知场可能是模型有效执行所必需的。然而,在检测任务中,精确的定位是至关重要的,而广泛的感知场可能会在检测过程中引入额外的噪声。随后引入的运动感知层归一化(MLN)在所有感知任务中都得到了改进。这说明了在传递动态信息时结合运动属性的重要性。最后,所提出的任务提示将不同任务的不同信息解耦,从而进一步提高感知性能。

Dataset Scale
我们还研究了预训练和微调数据量的影响。表 2 表明,增加预训练中使用的数据量可以提高下游任务的性能。重要的是,仅使用75%的数据进行微调仍然可以获得相当的性能。这一发现强调了我们的4D预训练方法在将数据需求减少25%方面的有效性。这意味着在标注方面节省了相当大的成本,代表了巨大的实用和经济优势。

4.3. Main Results
在本节中,我们验证了基于世界模型的4D预训练方法在各种自动驾驶任务中的有效性。除了将其与最先进的自动驾驶算法进行比较外,我们还将其与各种预训练算法进行对比,包括2D ImageNet预训练、单目3D检测算法FCOS3D、知识蒸馏算法BEVDistill、3D占位预训练算法OccNet和UniScene,以提供一个全面的评估。符号†表示使用nuScenes的训练集进行预训练,符号‡表示使用OpenScene的训练集进行预训练。对于微调,我们使用与UniAD相同的解码器头。“+X”表示使用不同预训练模型 X 对UniAD进行微调后得到的实验结果。
3D Object Detection
我们首先评估了多摄像头3D目标检测任务的性能。表 3 的结果显示,基于世界模型的4D预训练方法,与单纯依赖2D ImageNet预训练的BEVFormer相比,mAP和NDS分别大幅提高了7.5%和6.8%。BEVFormer与FCOS3D预训练,专门为单目3D对象检测量身定制,优于仅依赖于2D预训练的模型,导致性能提高4%。OccNet、UniScene和BEVDistill利用3D占用重建和知识蒸馏作为预训练目标,使性能额外提高了2%。这些发现强调了3D预训练与传统2D预训练模式相比的有效性。我们创新的DriveWorld引入了4D时空预训练,在nuScenes数据集上,与OccNet、UniScene和BEVDistill相比,表现出适度的性能改进。当扩展到大规模占用数据集OpenScene进行预训练时,额外提高1%的性能。

Online Mapping
我们验证了在线构图任务的性能。如表 4 所示,与UniAD相比,OccNet和UniScene中3D占用的预训练使IoU提高了约1%,知识蒸馏算法BEVDistill也使性能提高了1%。在nuScenes进行4D预训练后有2%的改进,在OpenScene上进行预训练后有3%的改进。

Multi-object Tracking
我们进一步评估了多目标跟踪任务的性能,这需要更深入地考虑时间信息。表 5 显示了本次评估的结果。很明显,利用DriveWorld的4D预训练结果在AMOTA方面显著提高了2.6%。令人印象深刻的是,在OpenScene上进行预训练后,这种性能提升变得更加显著,在AMOTA上达到了5.3%的大幅增长。相比之下,OccNet、UniScene和BEVDistill预训练在AMOTA上只提供了1.0%的适度改进。此外,DriveWorld显示出最低的ID切换分数,这表明DriveWorld使模型能够始终如一地展示每个tracklet的时间一致性。

Motion Forecasting
在运动预测任务中,如表 6 所示,通过3D预训练(如OccNet、UniScene和BEVDistill)获得的改进明显有限。相比之下,我们的4D预训练方法包含了预测未来状态的能力,显著提高了运动预测任务性能。在nuScenes上进行预训练,minADE降低了0.04m,而在OpenScene上进行预训练,minADE显著降低了0.1m。这种显著的改进归功于OpenScene更大的数据规模和该数据集中有价值的流量信息。

Occupancy Prediction
UniAD的占位预测任务是在二维BEV视图中进行的。如表 7 所示,在OpenScene上进行4D占用率预训练后,模型显示出令人印象深刻的增强:IoU-near增加2.8%,IoU-far增加5%,VPQ-near增加3.4%,VPQ-far增加3.4%。这一结果强调了预训练方法在实现更全面4D场景重建方面的有效性。

Planning
最后验证了4D预训练算法在规划任务上的有效性。如表 8 所示,DriveWorld通过实现新的最先进的规划结果脱颖而出,减少了0.34m的平均L2误差和0.12的平均碰撞率。这些结果超过了先前的最佳模型UniAD。UniAD以顺序的方式集成了感知、预测和计划。我们的4D预训练方法全面重建了3D场景,增强了当前场景的检测和分割等任务。并预测未来情景,提升了跟踪和预测能力。结合这些优势,进一步提高了最终规划步骤的性能。
因此,我们已经开发了一个强大的自动驾驶基础模型。

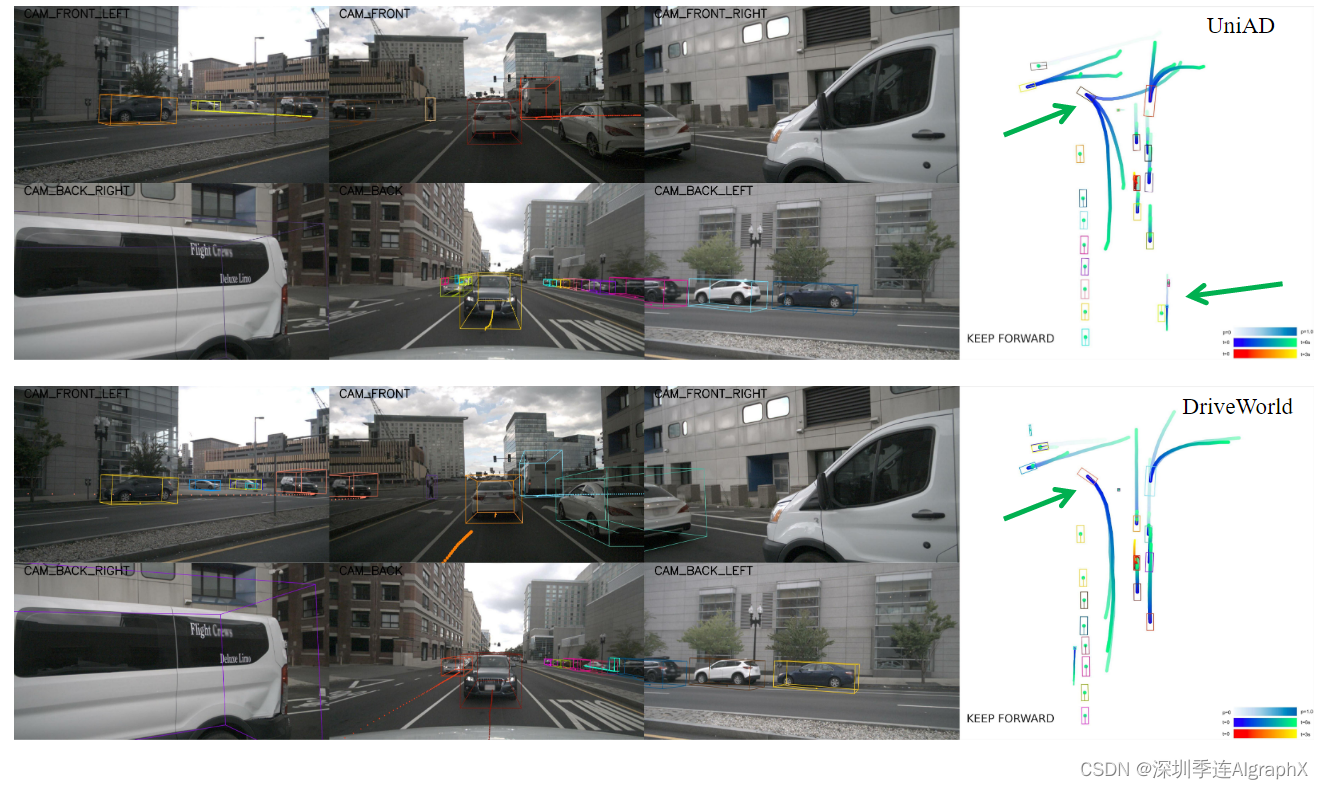
4.4. Qualitative Results
UniAD和DriveWorld的定性比较如图 4 所示。UniAD在检测远处物体时出现误报,DriveWorld提高了检测精度。此外,UniAD对转弯车辆的轨迹预测存在误差,DriveWorld通过4D预训练解决了这一问题,从而可以准确预测未来的变化。
5. Conclusion
针对以视觉为中心的自动驾驶,我们提出了一种基于世界模型的4D预训练方法DriveWorld。DriveWorld通过一个世界模型来学习紧凑的时空BEV表示,该模型基于过去的多摄像头图像和动作来预测3D占用。我们设计了一个用于时空建模的记忆状态空间模型,使用动态记忆库模块学习时间感知表征,使用静态场景传播模块学习空间感知表征。此外,还引入了一个任务提示来引导模型自适应地获取特定于任务的表示。大量实验表明,DriveWorld显著提高了各种自动驾驶任务的性能。DriveWorld代表4D世界知识的力量为自动驾驶的创新开辟了新途径。
局限性和未来的工作。目前,DriveWorld的标注仍然是基于LiDAR点云。探索以视觉为中心的预训练自监督学习是必要的。此外,DriveWorld的有效性仅在轻量级ResNet101骨干网上得到了验证;考虑扩大数据集和主干的大小是值得的。我们希望提出的4D预训练方法能够为自动驾驶基础模型的开发做出贡献。
DriveWorld-https://arxiv.org/abs/2405.04390
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。






![BUUCTF---web---[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/2ba7118cdddd4d90b3e3bca0611d8bec.png)