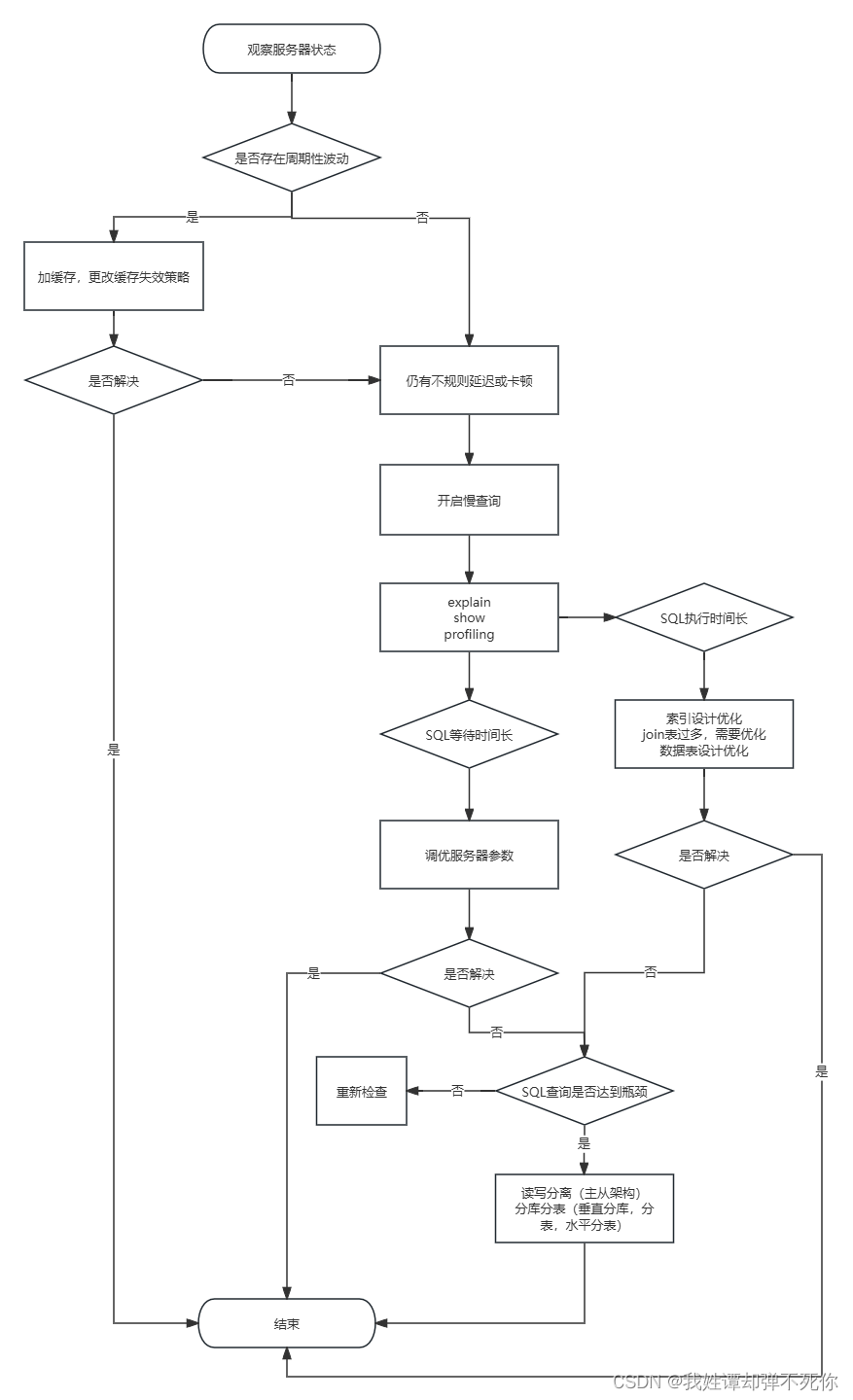
1、数据库服务器的优化步骤
2、查看系统性能参数
- 可以使用
show status语句查询一些MySQL数据库服务器的性能参数执行频率 - 语法格式:
show [ global | session ] status like '参数'; - 常用性能参数如下所示
| 参数名 | 说明 |
|---|---|
| connection | 连接MySQL服务器的次数 |
| uptime | MySQL服务器上线时间 |
| slow_queries | 慢查询的次数 |
| innodb_rows_read | select 查询返回行数 |
| innodb_rows_inserted | 执行insert操作插入的行数 |
| innodb_rows_updated | 执行update操作更新的行数 |
| innodb_rows_delete | 执行delete操作删除的行数 |
| com_select | 查询操作的次数 |
| com_insert | 插入操作的次数。对于批量插入的insert操作,只累加一次 |
| com_update | 更新操作的次数 |
| com_delete | 删除操作的次数 |
| last_query_cost | SQL查询成本 |
3、慢查询日志(定位执行慢的SQL)
-
MySQL慢查询日志用来记录MySQL中
响应时间超过设定阈值的语句,具体运行时间超过long_query_time值的SQL将会被记录到慢查询日志中。long_query_time的默认值为 10。 -
默认情况下,MySQL数据库
没有开启慢查询日志,需要手动设置参数。 -
不
是调优需要一般不建议启动该参数,因为开启慢查询日志或多或少会对性能造成一定影响。 -
查询慢查询日志是否开启
mysql> show variables like 'slow_query_log';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF |
+----------------+-------+
1 row in set (0.01 sec)
- 开启 slow_query_log
mysql> set global slow_query_log = on;
Query OK, 0 rows affected (0.12 sec)
mysql> show variables like 'slow_query_log%';
+---------------------+--------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------+
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/rqtanc-slow.log |
+---------------------+--------------------------------+
2 rows in set (0.00 sec)
- 查询 long_query_time 阈值
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
- 修改long_query_time 阈值
[root@rqtanc ~]# vim /etc/my.cnf
#设置
long_query_time = 5
#重启mysql
[root@rqtanc ~]# systemctl status mysqld.service
- 查看慢查询数目
mysql> show status like 'slow_queries';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 0 |
+---------------+-------+
1 row in set (0.00 sec)
4、慢查询日志分析工具: mysqldumpslow
- 查看 mysqldumpslow 帮助信息
[root@rqtanc ~]# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
- 分析文件源为:
mysql> show variables like 'slow_query_log_file%';
+---------------------+--------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------+
| slow_query_log_file | /var/lib/mysql/rqtanc-slow.log |
+---------------------+--------------------------------+
1 rows in set (0.00 sec)
- 执行以下语句进行分析
[root@rqtanc ~]# mysqldumpslow -a -s t -t 5 /var/lib/mysql/rqtanc-slow.log
Reading mysql slow query log from /var/lib/mysql/rqtanc-slow.log
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hosts
Died at /usr/bin/mysqldumpslow line 162, <> chunk 1.
5、查看SQL执行成本:show profile
- 见 MySQL-SQL执行流程及原理 一文
6、分析查询语句:explain
参考 官方文档
-
定位查询慢的SQL以后,可以使用explain 或 describe 工具做针对性的分析查询语句
-
基本语法(查询执行计划):
explain + SQL 语句如:
mysql> explain select 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
- explain语句输出列的相关说明
| 列名 | 说明 |
|---|---|
| id | 在一个大的查询语句中每个select关键字都对应一个唯一的id |
| select_type | select 关键字对应的哪个查询类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上用到的索引 |
| key_len | 实际上使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外信息 |
6.1、id列
- id 列的值标识了查询执行中的每一步操作,并反映了这些步骤的执行顺序和嵌套关系。
- id如果相同,可以认为是一组从上往下执行
- 在所有组中,id值越大,优先级越高,越先执行
- 每一个id值表示一趟独立的查询,一个SQL的查询趟数越少越好
6.2、select_type 列
- 一个大的查询语句中可以包含若干个select关键字,每个关键字代表一个小的查询语句,而每个select关键字的from子句中可以包含若干张表
- 每一张表对应执行计划输出中的一条记录,对于同一个select关键字中的表来说,他的id值是相同的
| 查询类型 | 说明 |
|---|---|
| SIMPLE | 表示查询是简单的 SELECT 查询,不包含任何子查询或联合查询。 |
| PRIMARY | 表示最外层的 SELECT 查询,也可以称为主查询。 |
| SUBQUERY | 表示查询中的子查询。 |
| DERIVED | 表示派生表,这是一个临时表,通常是在 FROM 子句中的子查询结果。 |
| UNION | 表示联合查询中的第二个或后续的 SELECT。 |
| UNION RESULT | 表示联合查询结果集的合并。 |
| DEPENDENT SUBQUERY | 表示依赖外部查询结果的子查询,每次执行都依赖于外部查询的结果。 |
| UNCACHEABLE SUBQUERY | 表示子查询结果不可缓存,每次执行都重新计算。 |
| MATERIALIZED | 表示使用了物化表(Materialized Table),这是一个存储预先计算结果的临时表。 |
6.3、partitions列
- 出现位置:partitions 列通常出现在执行计划的结果中,用于指示每个操作所涉及的分区信息。
- 分区名称:对于涉及到分区的操作,partitions 列可能会显示涉及的具体分区名称。
- 分区范围:对于涉及到范围分区的操作,partitions 列可能会显示涉及的分区范围。
- 作用
- 显示分区信息:partitions 列提供了有关查询涉及的分区的信息,包括查询在执行过程中访问了哪些分区。
- 性能优化:分析查询涉及的分区信息可以帮助优化查询性能,例如确保查询只访问必要的分区,避免不必要的分区扫描。
6.4、type 列
| 查询类型 | 说明 |
|---|---|
| system | 表示访问系统表,通常只有一行记录。 |
| const | 表示通过常量条件进行访问,通常使用索引直接定位到一行记录。 |
| eq_ref | 表示通过唯一索引进行等值连接,通常用于连接操作。 |
| ref | 表示通过非唯一索引进行等值连接,可能会返回多个匹配行。 |
| range | 表示通过索引范围进行访问,通常用于范围查询。 |
| index | 表示通过索引进行全表扫描,相比于 all 类型,这种访问方法更高效。 |
| all | 表示全表扫描,通常是最低效的访问方法,应尽量避免。 |
- 总结
- type 列提供了关于查询执行时访问表数据的方式的信息。
- 分析 type 列的值可以帮助你了解查询执行的效率,从而进行优化。
- 应该尽量避免使用全表扫描(type 为 all),而更倾向于使用索引来加速查询。
6.5、explain四种输出格式 语法:EXPLAIN FORMAT= [ JSON | TREE | EXTENDED ]
- 传统格式:表格形势
- json格式:
- 将查询执行计划输出为 JSON 格式的数据。这种格式适用于对查询执行计划进行进一步的自动化处理和分析,例如通过脚本进行解析和比较。JSON 格式输出了与标准格式相同的信息,但以 JSON 对象的形式表示,每个属性对应于查询执行计划中的一个字段。
- tree格式:
- 树形格式提供了更具可读性的查询执行计划信息。输出结果以树形结构呈现,每个节点代表查询执行计划中的一个操作。每个节点包含的信息通常与标准格式相同,但以树形结构展示,更直观地显示了查询执行的流程和嵌套关系。
- 拓展格式(EXTENDED)输出:
- 提供了比标准格式更详细的查询执行计划信息。除了标准格式中的列外,还包括了额外的信息,如每个操作的状态、扫描方式、索引长度等。这种格式适用于对查询执行细节进行深入分析和调优,提供了更多的信息用于性能优化。
6.6、SHOW WARNINGS
- 用于显示最近执行的语句产生的警告信息。警告通常是一些执行中的问题或不符合预期的情况的提示。
- SHOW WARNINGS 命令可以帮助你识别并了解这些问题,以便及时采取措施解决。
- 警告信息可能包含以下内容:
- Warning:警告的代码或编号。
- Level:警告的级别,通常是 Note、Warning 或 Error。
- Message:警告的具体消息描述
7、分析优化器执行计划:trace
optimizer_trace可以跟踪优化器做出得各种决策(如:访问表的方法、各种开销计算、各种转换等,并将跟踪结果记录到information_schema.optimizer_trace表中)- 此功能默认关闭,开启trace并将格式设置为json,同时设置trace最大能够使用的内存大小,避免解析过程中因内存过小而不能够完整展示
- 可分析的语句:
- select
- insert
- update
- delete
- replace
- explain
- set
- declare
- case
- if
- return
- call
8、MySQL监控分析视图:sys schema
- 主机相关:以 host_summary开头,主要汇总了IO延迟的信息
- InnoDB相关:以innodb开头,汇总了innodb buffer信息和事务等待innodb锁的信息
- I/O相关:以io开头,汇总了等待I/O及使用量的情况
- 内存使用情况:以memory开头,从主机、线程、事件等角度展示内存使用的情况
- 连接与会话信息: process list和session相关视图,总结了会话相关情况
- 表相关:以schema_table开头的视图,展示了表的统计信息
- 索引信息:统计了索引的使用情况,包含冗余索引和未使用索引的情况
- 语句相关:以statement开头,包含执行全表扫描,使用临时表,排序等的语句信息
- 用户相关:以user开头的视图,统计了用户使用的文件I/O、执行语句统计信息
- 等待事件相关信息:以wait开头,展示等待事件的延迟情况