目录
1. 主从模式
为什么需要主从?
搭建主从架构
2. Sentinel(哨兵)模式
为什么需要哨兵模式?
搭建哨兵集群
哨兵集群
Go语言编程redis哨兵模式
有了哨兵,客户端连接谁?
test1:redis节点主从切换
test2:sentinel实例全部挂掉后,redis的读写操作
3. 分片集群(Cluster 模式)
为什么需要Cluster模式?
搭建分片集群
启动所有集群节点
创建集群
搭载集群中出现的问题
测试
插槽原理
为什么数据key不是与节点绑定,而是与插槽绑定?
插槽值计算规则
对一个key的操作流程
集群伸缩
添加节点
删除节点
自动故障转移
手动故障转移(新旧服务器升级交替,数据转移)
Go语言编程Redis集群
该文章的主要内容:
- 搭建主从模式、哨兵模式、分片集群模式,及过程中需要注意的细节
- 用Go语言go-redis来编码哨兵模式和分片集群模式
1. 主从模式
为什么需要主从?
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
客户端需要写的就往主Redis实例写,要读的就往从Redis实例读,这样就可以提高Redis的并发能力。
Redis主从集群为什么要采用读写分离,而不是传统的负载均衡呢?
因为根据以往经验,对Redis的操作大部分都是读,写操作占少数。所以在集群中采用读写分离,同时以少量主节点和大量从节点搭配,大大提升Redis的读取性能。主节点需要注意的就是数据同步如何同步给从节点。
搭建主从架构

使用两个云服务器,所以会在每个服务器启动一个Redis服务。服务器A和服务器B。
现在两台服务器都开启了Redis服务,但是这两个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前,效果一样)命令。
临时和永久 两种模式:
- 修改配置文件(永久生效)
- 在redis.conf 中添加一行配置:replicaof <主机ip> <端口>
- 若是集群中主机有密码的,需要再添加一行配置: masterauth <密码>
- 使用redis-cli客户端连接到redis服务,执行replicaof 命令 (重启后失效):
replicaof <masterip>(Redis实例ip) <masterport>(Redis实例端口)这里使用修改redis.conf配置文件的方式来展示。
在作为从节点的服务器上修改其redis.conf文件,即是修改slave实例的redis.conf。主节点的redis.conf不需要做过多改动。
#redis.conf 从节点的配置文件
#--------找到如下内容并修改--------
bind 0.0.0.0 -::1 #对所有ip开放连接
daemonize yes #允许后台启动
logfile "/usr/local/redis/redis.log" #日志路径(自己设置自己想要的位置)
dir /data/redis/data/ #数据库备份文件存放目录
replicaof 192.168.1.29 6379 #master的ip和port
masterauth 123456 #slave连接master的密码,master没有设置连接密码则无需配置
requirepass 123456 #Redis连接登录密码

另一服务器的redis.conf文件不需要改动。
分别在两个服务器的redis-cli登录查看。
- 查看主从状态

- 数据显示
主设置了数据后,在从机中可以看到该数据。而且在 slave 节点是无法写入数据的。

2. Sentinel(哨兵)模式
为什么需要哨兵模式?
主从模式是提高了Redis的并发能力。但是,要是主Redis实例宕机了,那就需要人工来重启或者切换主实例,这是很麻烦的。而这时候就可以使用哨兵模式了。
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。在master实例宕机时候,哨兵会自动把slave实例提升为master实例,并会告知其他从实例,有新的master了。
搭建哨兵集群
在redis.conf同目录中有文件sentinel.conf,这个就是哨兵的配置文件。
因为哨兵模式,一般是使用多个哨兵的,即是会有多个哨兵进程。我们把该配置文件存放到某位置。创建目录,sentinel/s1,在把sentinel.conf拷贝到s1中,并修改sentinel.conf。
Sentinel 模式是基于主从模式搭建的,所以直接使用上边已经搭建好的主从模式环境,修改 sentinel 配置文件。
#sentinel.conf
port 26379 #sentinel进程的端口
daemonize yes #yes是后台运行,no是前台运行
logfile "/usr/local/redis/sentinel_26379.log" //日志存储位置
dir /data/redis/sentinel/ #sentinel工作目录
sentinel monitor mymaster 192.168.1.129 6379 1
#1 表示判断master失效至少需要1个sentinel同意, 因为当前是用单哨兵,所以设置为1
#设置为2就表示判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel auth-pass mymaster 123456 //主的密码,就最好主从的密码是一样的,这样就不出错
sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s
- 启动哨兵
执行命令
redis-server ./sentinel.conf在后台运行的,所以我们从日志来查看,可以看到哨兵会获取到Redis主和从的ip和端口。

- 测试主机挂掉(手动停掉主机Redis服务)
查看sentinel日志
- +sdown master, 即是主观认为39服务器实例下线
- +odown master .... #quorum ... ,即是quorum达标,客观认为39服务器下线
- +try_failover master, 即是尝试等待39服务器实例上线
- +vote-for_leader ,即是sentinel内部选一个leader,被选中的sentinel实例去执行故障切换
- +failover_state-select-slave master,即是准备选一个slave,作为新的master
- +selected-slave slave,即是选中了43服务器实例
- +failover-state-send-slaveof-noone slave,即是让43服务器实例执行slaveof noone,成为新的mater
- +failover-state-wait-promotion salve ,即是43服务器实例等待提升,其就是让其他salve执行slaveof 43服务器实例
- +promoted-slave slave ,即是43服务器实例正式提升为master
- +failover-state-reconf-slvaes master,即是修改下线的39服务器实例,让它标记为新master的slave
- +switch-master ,即是主从切换完成

查看原先是slave的实例,info replication,可以看到其提升为master了。
而之后启动原先为master的实例,再查看,可以看到其作为了slave。
哨兵集群
单个哨兵进程对Redis服务器进行监控时可能会出现一些问题(比如说哨兵挂掉),为此我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。由于一个哨兵就需要一个进程,哨兵集群至少要三个哨兵才能保证健壮性,因此要配置多哨兵,这里使用一主二从,所以需要6个进程。
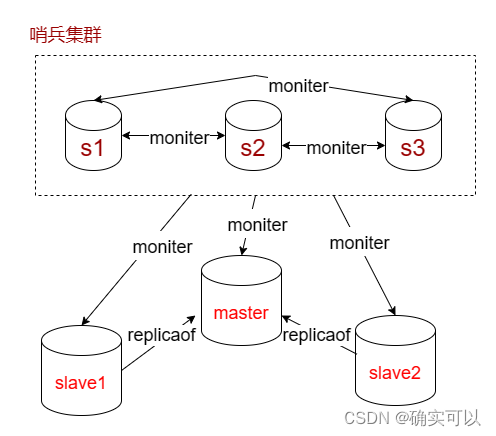
和前面的sentinel/s1类似,在sentinel目录中创建目录s3和s3,之后分别拷贝s1中的sentinel.conf到s2,s3。修改s2,s3的sentinel.conf。
下面是3个哨兵的配置文件:
这里要注意的是:port端口不同,还有sentinel monitor <master-name> <ip> <redis-port> <quorum>中的quorum值,该值表示判断master失效至少需要sentinel同意的个数,所以现在三个sentinel,就设置为3/2+1=2。
#s1
port 20000 #sentinel进程的端口
daemonize yes #yes是后台运行,no是前台运行
logfile "/usr/local/redis/sentinel_26379.log" //日志存储位置
dir /data/redis/sentinel/ #sentinel工作目录
sentinel monitor mymaster 192.168.1.129 6379 2
#1 表示判断master失效至少需要1个sentinel同意, 因为当前是用单哨兵,所以设置为1
#设置为2就表示判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel auth-pass mymaster 123456 //主的密码,就最好主从的密码是一样的,这样就不出错
sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s
#s2
port 20001 #sentinel进程的端口
daemonize yes #yes是后台运行,no是前台运行
logfile "/usr/local/redis/sentinel_26379.log" //日志存储位置
dir /data/redis/sentinel/ #sentinel工作目录
sentinel monitor mymaster 192.168.1.129 6379 2
#1 表示判断master失效至少需要1个sentinel同意, 因为当前是用单哨兵,所以设置为1
#设置为2就表示判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel auth-pass mymaster 123456 //主的密码,就最好主从的密码是一样的,这样就不出错
sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s
#s3
port 20002 #sentinel进程的端口
daemonize yes #yes是后台运行,no是前台运行
logfile "/usr/local/redis/sentinel_26379.log" //日志存储位置
dir /data/redis/sentinel/ #sentinel工作目录
sentinel monitor mymaster 192.168.1.129 6379 2
#1 表示判断master失效至少需要1个sentinel同意, 因为当前是用单哨兵,所以设置为1
#设置为2就表示判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel auth-pass mymaster 123456 //主的密码,就最好主从的密码是一样的,这样就不出错
sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30sGo语言编程redis哨兵模式
有了哨兵,客户端连接谁?
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。
哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过 sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis 主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
import "github.com/go-redis/redis/v8"
func SentinelClient() *redis.Client {
return redis.NewFailoverClient(&redis.FailoverOptions{
MasterName: "mymaster",
SentinelAddrs: []string{"127.0.0.1:26379", "127.0.0.1:27379", "127.0.0.1:28379"},
Password: "wook1847",
})
//从 go-redis v8 版本开始,你可以尝试使用 NewFailoverClusterClient 把只读命令路由到从节点,
//注意,NewFailoverClusterClient 借助了 Cluster Client 实现,不支持 DB 选项(只能操作DB 0)
//返回值是*redis.ClusterClient
// return redis.NewFailoverClusterClient(&redis.FailoverOptions{
// MasterName: "mymaster",
// SentinelAddrs: []string{"127.0.0.1:26379", "127.0.0.1:27379", "127.0.0.1:28379"},
// Password: "123456",
// RouteByLatency: true, //把只读命令路由到最近的节点
// })
}
func main() {
//哨兵模式
sentinel := db.SentinelClient()
k := "testage"
sentinel.Set(context.Background(), k, "111", 10*time.Minute)
val, err := sentinel.Get(context.Background(), k).Result()
if err != nil {
fmt.Println("err: ", err)
}
fmt.Println("result:", val)
}使用go-redis编程sentinel模式,来看看个别情况。
测试代码:
func main() {
//哨兵模式
sentinel := db.SentinelClient()
for {
reply, err := sentinel.Incr(context.Background(), "test").Result()
fmt.Printf("reply= %v,err= %v\n", reply, err)
time.Sleep(3 * time.Second)
}
}test1:redis节点主从切换
在运行过程中,shutdown redis主节点,可以看到在reply等于6和7之间,客户端监测到了主从切换,并重新连接到新的主节点,这段时间大致等于sentinel配置down-after-milliseconds的时长。

test2:sentinel实例全部挂掉后,redis的读写操作
把3个sentinel实例全部 kill掉,则go-redis会记录一条日志,而对redis的读写操作仍然正常。

3. 分片集群(Cluster 模式)
为什么需要Cluster模式?
主从和哨兵模式可以解决高并发读、高可用问题。哨兵模式是在主从模式上添加的,一般企业使用Sentinel 模式就可以满足一般生产的需求,具备高可用性。
但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
那么使用分片集群可以解决以上问题。
分片集群:
- 集群中是有多个master,每个master存储不同的数据(分片存储),比如一共60G的数据,分别分配到3台20G内存的服务器
- 每个master都可以有多个slave节点
- master之间通过ping检测彼此健康状况(替代哨兵。分片集群自身具备故障转移等功能,可以不需要哨兵)
- 客户端请求可以访问集群中的任意节点,最终都会被转发到正确节点

搭建分片集群
从上图可知,分片集群需要的节点是比较多,(上图的也可以有4个master,或者5个或者更多master)。这里我们就搭建最小的分片集群,包含3个master节点,每个master包含一个slave节点。
启动所有集群节点
一共6个节点,那每个服务器启动3个节点,只有一台服务器的话,就只在一台服务器启动6个节点即可。我这里就按照一个服务器启动3个节点为例。
自己找个合适的位置,创建cluster目录,并在cluster目录下创建c1,c2,c3目录。
每个集群节点的配置文件就是使用redis.conf。那就修改redis.conf文件。之后再修改配置文件的路径位置,拷贝到对应的c1,c2,c3目录中。
port 26379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /workspace/cluster/c1/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /workspace/cluster/c1/
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 日志
logfile /workspace/cluster/c1/run.log
requirepass "wook1847" #设置登录访问密码
之后通过命令启动实例
redis-server cluster/c1/redis.conf
redis-server cluster/c2/redis.conf
redis-server cluster/c3/redis.conf创建集群
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。
这里我们使用Redis5之后的命令来搭建。
redis-cli --cluster create --cluster-replicas 1 43.139.27.107:20001 43.139.27.107:20002 43.139.27.107:20003 39.108.70.103:20001 39.108.70.103:20002 39.108.70.103:20003 -a 密码命令说明:
- redis-cli --cluster: 代表集群操作命令
- create:代表创建集群
- --cluster-replicas 1 或者 --replicas 1:指定集群中每个master的副本个数,设置为1,即是从机有1个。然后Redis会自动计算master数量。此时节点总数 ÷ (replicas +1)=n,n就是maseter的数量。注意:是不能指定哪个节点是主节点的。
- -a :表示输入密码,每个Redis实例要是有密码的话,需要输入密码,每个实例密码都要一致。
执行上述命令(在哪个服务器执行该命令都行的):

这里输入yes,则集群开始创建:

通过命令可以查看集群状态:(通过任一节点查看都可以的)
redis-cli -a 密码 -p 20001 cluster nodes 搭载集群中出现的问题
搭载集群中出现的问题
1.没有输入密码
Redis设置密码的话,就需要输入密码

2.Redis实例内有数据
这是不行的,需要实例数据为空才行。

主要两步骤:
- 删除appendonly.aof和dump.rdb。因为Redis启动是从这两个文件中恢复数据重启的。而该文件的位置根据你自己的redis.conf配置而定。
- 第一步还不行的话,就需要删除所有节点的
cluster-config-file,也就是节点配置文件,自动生成的node.conf文件,路径也配置在redis.conf文件中。
3.阻塞等待很长时间

遇到这种情况大部分是因为集群总线的端口没有开放。
集群总线:
每个Redis集群中的节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如6379,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口。比如:redis实例的端口为6379,那么另外一个需要开通的端口是:6379 + 10000, 即需要开启 16379。16379端口用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。
所以开放每个集群节点的客户端端口和集群总线端口才能成功创建集群。要是云服务器的话,还需要到云服务器的安全组去开启。
测试

上述出现了问题,其出错的原因:
因为分片集群采用key和插槽绑定的模式,就是对一个key进行操作(get/set)之前,都会先计算其插槽值(hash slot),然后根据插槽值去查找对应的插槽位(即是Redis节点,每个Redis节点对应一个插槽区间)。
比如:假设存在两个节点a、b。a的插槽区间为[0,9191],b的插槽区间为[9191,16383],查找的key的插槽值是7777。
使用redis-cli命令登录a节点,操作该key,而该key的插槽值刚好位于a节点的插槽区间,所以不会报错。要是登录在b节点操作该key,就会报错。
这是因为在分布式集群模式下,该Key对应的插槽区间在a节点上(先找插槽区间,再找对应的节点),在b节点上无法操作,需要在a节点上才可以操作。
使用正常的redis-cli命令无法进行切换节点的操作,使用redis-cli -c命令就可以根据Key对应的插槽区间,重定向到对应的节点(先找插槽区间,再找对应的节点),然后再对该Key进行操作。
所以,集群操作时候,需要给redis-cli加上 -c 参数。
redis-cli -c -p 7001
参数:
-c Enable cluster mode (follow -ASK and -MOVED redirections). 启用集群模式(按照 -ASK 和 -MOVED 重定向进行操作)。

我们发现,当我们试图添加key时,有可能会跳到其他节点,为什么会这样呢?这就涉及到我们即将讲解的插槽原理
插槽原理
一个Redis分片集群有0~16383共16384个插槽(hash slot),这些插槽会被平均分给每一个master节点,一个master节点映射着一部分插槽,这一点在集群创建时的信息中可以看到,也可以从redis-cli -p 端口 -a 密码 cluster nodes 得到。

为什么数据key不是与节点绑定,而是与插槽绑定?
当要操作一个key时,都是先计算器插槽值(hash slot), 然后去寻找插槽区间,再根据插槽区间找到对应的节点,然后会重定向到该节点,再对key进行操作。
那为什么不直接与Redis节点绑定,为什么要在中间加了一层插槽呢?
因为Redis节点可能会出现宕机,Redis集群后期可能需要进行伸缩等情况。当节点删除或者发生宕机时,节点上保存的数据也就丢失,但如果数据绑定的是插槽,那么当出现该情况时候,就可以将故障接的插槽转移到存活节点上。这样,数据绑定插槽,就永远能操作数据所在的位置。
使用哈希槽的好处:可以方便的添加或移除节点。
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
插槽值计算规则
数据key与插槽是多对一的关系,redis会根据key的有效部分计算插槽值,然后将key放入对应插槽,key的有效部分分两种情况:
- 当key中包含"{}“时,且”{}“中至少包含1个字符,”{}"中的部分是有效部分
- key中不包含"{}",整个key都是有效部分
对一个key的操作流程
将16384个插槽分配到不同的Redis实例中。
- 根据key的有效部分(全部 或 {})计算哈希值,对16384取余
- 余数作为插槽值,寻找所在插槽区间对应的Redis节点,然后重定向到目标实例
- 执行命令
集群伸缩
其就是分片集群动态地添加或移除Redis节点。
在命令行展示的话,可以通过redis-cli --cluster展示。redis-cli --cluster提供了很多操作集群的命令。

添加节点
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
redis-cli --cluster add-node 新Redis节点的ip: 新Redis节点的端口 想要添加的集群中的某个节点ip:端口 [可选参数]具体说明:
- new_host:new_port 就是新增的节点,这个是必须指定的。
- 而后面的existing_host:existing_port就可以从目标集群中随便取一个节点地址即可,因为这个节点起的作用就是,把新增节点的消息通知给集群中每一个节点。
可选参数: --cluster-slave:指定新增节点为从节点; --cluster-master-id:指定新增节点的主节点。
注意:
- 要是不指定上面两个可选参数(--cluster-slave、--cluster-master-id),那么新增节点默认就是作为集群的一个主节点。但是,要是existing_host:existing_port是集群中的从节点,那么不指定上面两个参数,其也是会作为从节点。
- 默认情况下,新增节点作为主节点添加以后,不会自动重新分配插槽区间给新增节点的,需要我们手动从别的主节点那里去获取。
这里以一个案例来展示说明:向集群中添加一个新的master节点,并向其中存储num=10
步骤分解:
- 启动一个新的Redis实例,端口为20004
- 添加该实例到之前的集群,并且是作为maseter节点
- 给该节点手动分配插槽,使得num这个key可以存储到该节点
这个就是展示两个功能:1.添加一个节点到集群中,2.将部分插槽分配到新节点中 。
1.创建redis实例
创建文件夹cluster/c4,拷贝前面的redis.conf到c4文件夹中。修改该redis.conf。把port值改为20004,日志文件位置logfile和cluster-config-file,appendfilename,dbfilename都修改好对应的位置。appendfilename,dbfilename是redis启动获取数据的文件,要改好名字,不然新节点启动就会去获取已存在节点的数据文件了。
执行命令,启动该节点。
redis-server redis.conf2.添加新节点到redis
执行命令:
redis-cli --cluster add-node 39.108.70.103:20004 39.108.70.103:20001 -a 密码
通过命令查看集群状态:
redis-cli -p 20001 -a 密码 cluster nodes 
可以看到,端口为20004的节点插槽数量是0,所以不会有数据存储到该节点上。
3.转移插槽
我们要将num存储到20004节点,因此需要先看下num的插槽是多少。

如上图所示,num的插槽是2764。
端口为20001的节点对应的插槽区间是[0,5460]。那我们可以将0~3000的插槽转移到20004实例上。
命令格式:reshard
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.执行命令
redis-cli -a 密码 --cluster reshard 43.139.27.107:20001 --cluster-from 493e21da88c3694debbac7d22411ec2528bdbc2d --cluster-to 171b7f79ac17debf22424c4b8e115c8766ef54af --cluster-slots 3000- reshard 43.139.27.107:20001 ,表示从这个节点所在的集群中进行迁移插槽,可以是该集群的任一主节点
- --cluster-from 493e21da88c3694debbac7d22411ec2528bdbc2d,插槽的来源节点,这个是要写node-id
- --cluster-to 171b7f79ac17debf22424c4b8e115c8766ef54af,插槽迁移的目的接地,是要写node-id
- --cluster-slots 3000,表示迁移3000个插槽,注意:是从来源节点的卡槽最小值开始计算的。
迁移过程之中会让输入yes,即可。
注意:这个过程消耗的时间是比较长的。
然后,通过命令查看结果:
redis-cli -p 20001 -a 密码 cluster nodes 
直接在20004节点查看数据,发现num的数据已迁移到该节点

删除节点
删除从节点
这个就很简单。
通过cluster nodes查看节点,端口为20002的是从节点,就以删除该节点为例子。

执行del-node host:port node_id命令
redis-cli --cluster del-node 39.108.70.103:20001 54d42af7758a414d073c5a5bb1badcea3f53dd30 -a 密码- del-node后面的host:port是 集群主节点的ip和port(任意一个主节点都行)
- node_id就是被删除的从节点id。
效果如下:

虽然该节点从集群中移除.但该节点服务没停止,角色变成了master。

删除主节点
这个就会复杂。因为主节点中存放着数据,所以在删除之前,我们要把数据迁移走,并且把该节点的插槽分配到其他主节点上。
1.迁移主节点插槽
把主节点43.139.27.107:20002全部迁移到39.108.70.103:20004。

20002节点的数据,迁移过后,其数据会转移到20004节点上。
20002节点原先的数据:

使用--cluster rehard。之前的是使用一行代码的,这里展示逐步的。

选择完这几项以后,回车继续:

查看集群节点插槽和数据
20002上已经没有插槽了,都是迁移到20004节点了,数据也是迁移到20004节点。
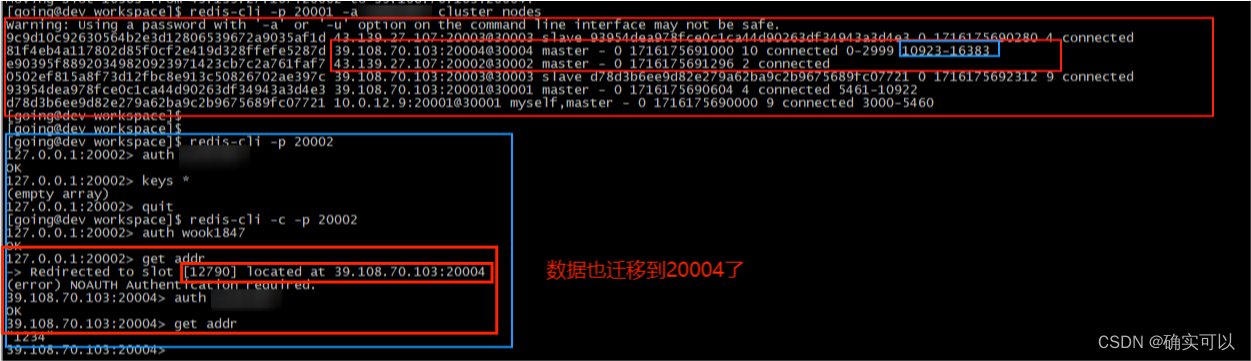
2.自动平衡集群各主节点哈希槽
这样做就很容易导致插槽数据量不均衡,有些节点多,有些节点少,这是不妥的。所以我们需要平衡插槽。使用redis-cli --cluster rebalance命令。
执行命令
redis-cli --cluster rebalance 39.108.70.103:20004 -a 密码效果如下 
3.删除主节点
找到对应节点的node-id,执行命令
redis-cli --cluster del-node 39.108.70.103:20001 e90395f88920349820923971423cb7c2a761faf7 -a 密码
自动故障转移
案例:让maseter节点20001宕机,使其从节点上位。
直接停止端口为20001的master实例,再查看集群节点。
可以看到: 20001主节点连接失败了,让其从节点成为master。

当20001再次启动,就会变为一个slave节点了。
手动故障转移(新旧服务器升级交替,数据转移)
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。

注意:因为一些原因,我把之前的集群删掉了,重新创建了,所以现在每个节点对应的node-id和是否是master就可能和之前不一样的。
案例:在20001这个slave节点执行手动故障转移,20001重新夺回master地位
步骤如下:
- 利用redis-cli连接20001这个节点
- 执行cluster failover命令

Go语言编程Redis集群
import "github.com/go-redis/redis/v8"
func CluterClient() *redis.ClusterClient {
cluster := redis.NewClusterClient(&redis.ClusterOptions{
//master的ip地址
Addrs: []string{
"127.0.0.1:20001",
"127.0.0.1:20002",
"127.0.0.1:20003",
},
Password: "123456",
DialTimeout: 10 * time.Second,
ReadTimeout: 10 * time.Second,
WriteTimeout: 10 * time.Second,
})
fmt.Println(cluster.Options().Addrs)
//遍历每个节点
err := cluster.ForEachShard(context.Background(), func(ctx context.Context, shard *redis.Client) error {
return shard.Ping(ctx).Err()
})
if err != nil {
panic(err)
}
return cluster
}
func main() {
Cluter := db.CluterClient()
key := "home"
Cluter.Set(context.Background(), key, "666", 10*time.Minute)
result, err := Cluter.Get(context.Background(), key).Result()
if err != nil {
fmt.Println(err)
}
fmt.Println("result: ", result)
}想要公网访问Redis集群,那在写Addr时候就需要写maseter的公网ip。但是这样还是不能访问。会出现下图问题:连接超时。我们写的是公网的,显示连接的却是内网。

这个问题也困扰了我很久。原来是集群中给每个节点生成的node.conf文件导致的。redis实例启动,创建了集群后,每个节点生成的node.conf中的myself节点是内网ip。就是这个问题导致的。
 所以需要修改node.conf,把内网ip改成公网ip,那才能访问。把集群所有节点生成的node.conf文件中的内网ip改成对应实例的公网ip,之后再重启集群所有Redis服务器即可。
所以需要修改node.conf,把内网ip改成公网ip,那才能访问。把集群所有节点生成的node.conf文件中的内网ip改成对应实例的公网ip,之后再重启集群所有Redis服务器即可。