提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 常用命令
- 1.查看CPU使用率
- 1.1 top 命令
- 第一行是任务队列信息: top
- 第二行为进程的信息 Tasks
- 第三行为CPU的信息
- Mem:
- Swap
- 1.2 vmstat命令
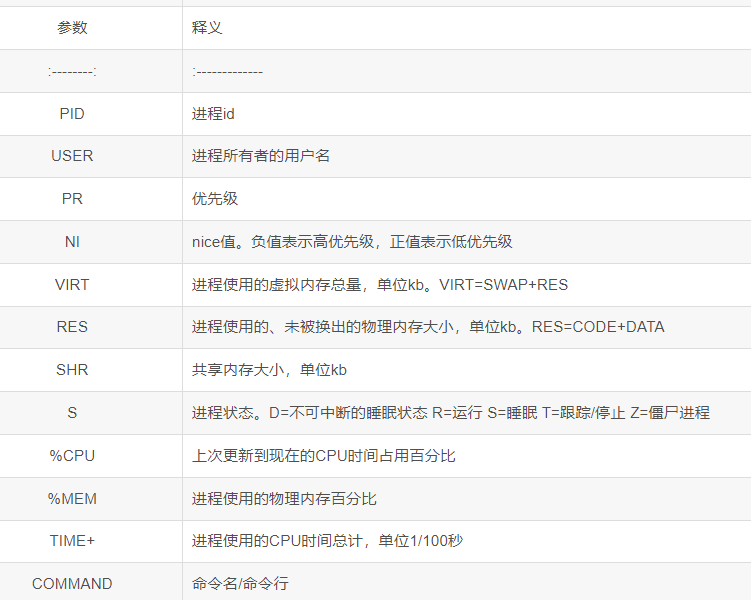
- 参数详解
- 每个参数的具体意思如下:
- 1.3 ps aux命令
- 2.内存使用率
- 2.1 free命令
- 关于 buffer 和 cache:
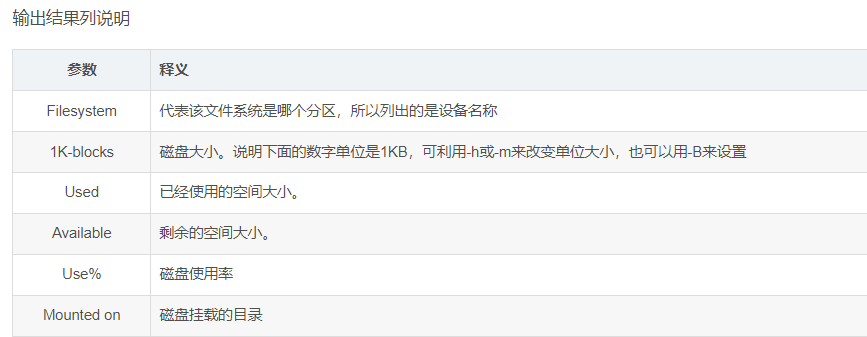
- 3.磁盘使用率
- 3.1 df-h 命令
常用命令


1.查看CPU使用率
1.1 top 命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
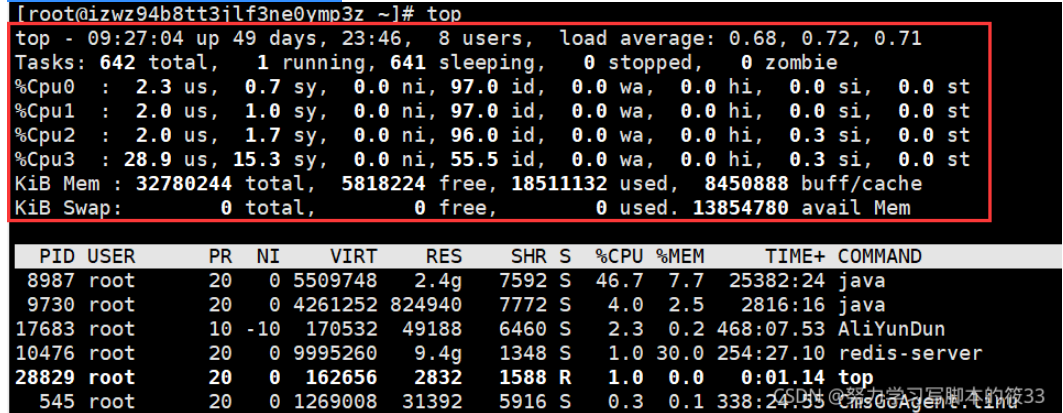
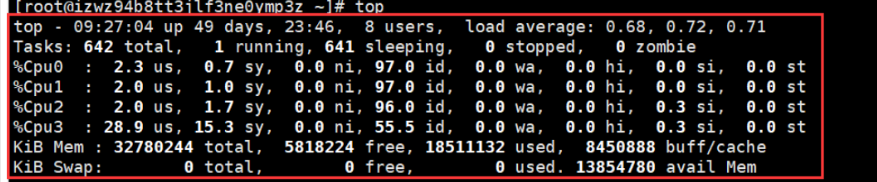
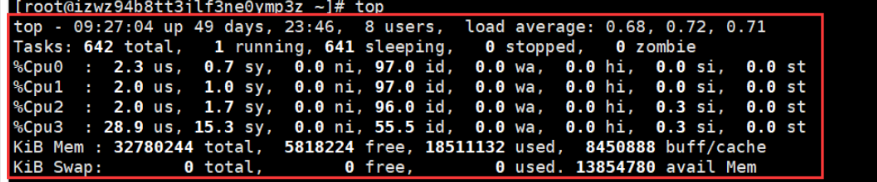
[root@izwz94b8tt3jlf3ne0ymp3z ~]# top
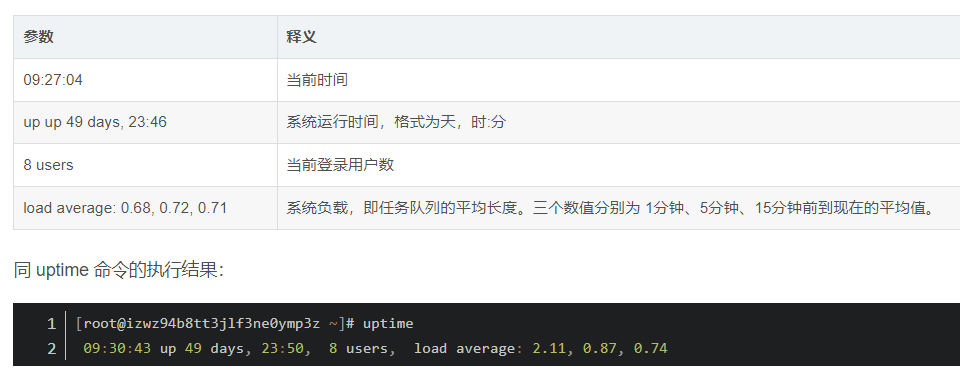
top - 09:27:04 up 49 days, 23:46, 8 users, load average: 0.68, 0.72, 0.71
Tasks: 642 total, 1 running, 641 sleeping, 0 stopped, 0 zombie
%Cpu0 : 2.3 us, 0.7 sy, 0.0 ni, 97.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.0 us, 1.0 sy, 0.0 ni, 97.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 2.0 us, 1.7 sy, 0.0 ni, 96.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu3 : 28.9 us, 15.3 sy, 0.0 ni, 55.5 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 32780244 total, 5818224 free, 18511132 used, 8450888 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 13854780 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8987 root 20 0 5509748 2.4g 7592 S 46.7 7.7 25382:24 java
9730 root 20 0 4261252 824940 7772 S 4.0 2.5 2816:16 java
17683 root 10 -10 170532 49188 6460 S 2.3 0.2 468:07.53 AliYunDun
10476 root 20 0 9995260 9.4g 1348 S 1.0 30.0 254:27.10 redis-server
28829 root 20 0 162656 2832 1588 R 1.0 0.0 0:01.14 top
545 root 20 0 1269008 31392 5916 S 0.3 0.1 338:24.55 CmsGoAgent.linu
546 root 20 0 21672 1088 828 S 0.3 0.0 4:10.99 irqbalance
9333 root 10 -10 436916 2032 1232 S 0.3 0.0 32:12.31 AliSecGuard
27347 root 10 -10 579632 9200 1352 S 0.3 0.0 44:12.52 AliDetect
1 root 20 0 52768 4228 1956 S 0.0 0.0 10:34.76 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.83 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
……………………………………………………………………………………………………………………………………………
top各参数解释:
- 统计信息区前几行是系统整体的统计信息。


第一行是任务队列信息: top
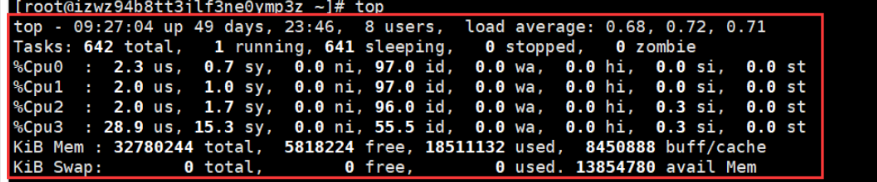
第二行为进程的信息 Tasks
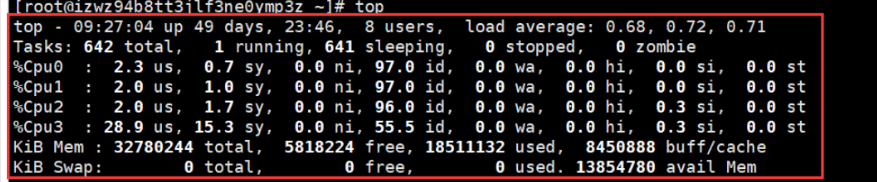
第三行为CPU的信息
- 有几个CPU,就会显示几行。例中有4个,故四行。
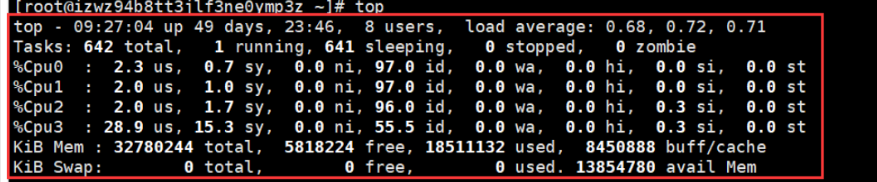
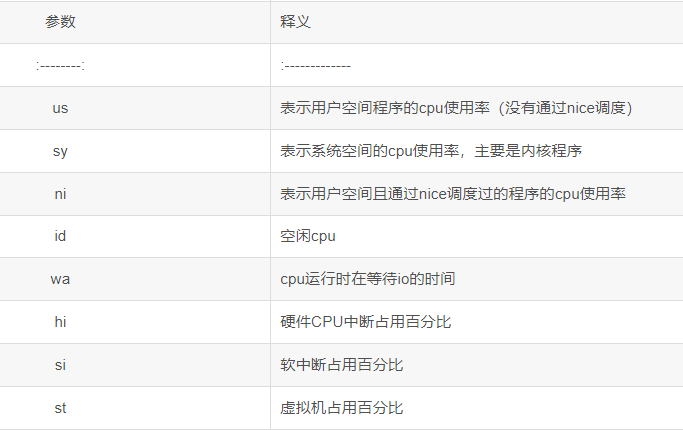
【注意:】97.0id,表示空闲CPU,即CPU未使用率,100%-97.0%=3%,即系统的cpu使用率为3%
Mem:
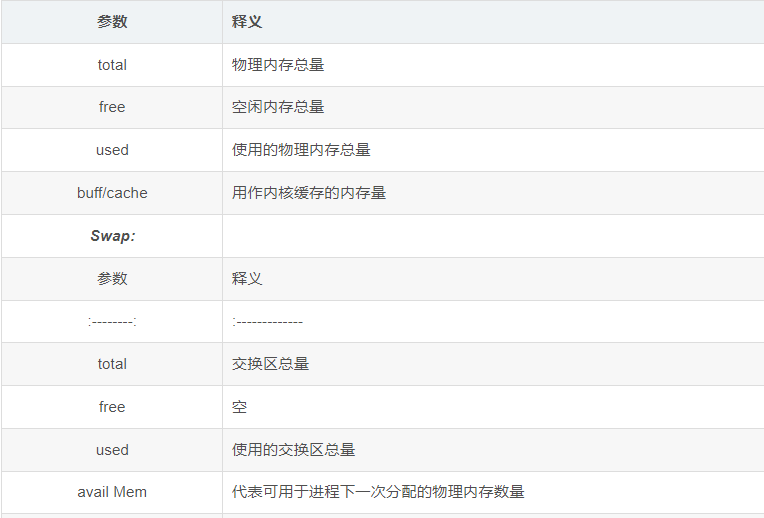
Swap
1.2 vmstat命令
root@vm-199:~# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 97640 53884 192800 578212 0 0 3 20 1 12 1 2 93 3
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了
root@vm-199:~# vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 1 97640 50348 192812 578352 0 0 3 20 1 12 1 2 93 3
0 0 97640 54636 192812 578360 0 0 0 14 126 147 2 4 86 8
0 3 97640 53908 192816 578356 0 0 0 62 96 110 2 4 86 9
0 0 97640 54156 192816 578360 0 0 0 14 113 118 3 5 83 11
0 0 97640 53908 192816 578360 0 0 0 16 107 103 2 3 87 9
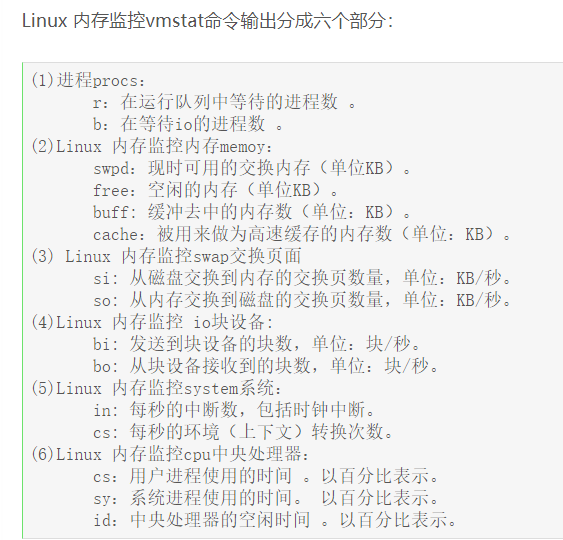
参数详解
常见诊断:
1、假如 r 经常大于4 ,且 id 经常小于40,表示中央处理器的负荷很重。
2、假如 bi,bo 长期不等于0,表示物理内存容量太小。
每个参数的具体意思如下:

r 表示运行队列(就是说多少个进程真的分配到 CPU),我测试的服务器目前 CPU 比较空闲,没什么程序在跑,当这个值超过了 CPU 数目,就会出现 CPU 瓶颈了。这个也和 top 的负载有关系,一般负载超过了 3 就比较高,超过了 5 就高,超过了 10 就不正常了,服务器的状态很危险。top 的负载类似每秒的运行队列。如果运行队列过大,表示你的 CPU 很繁忙,一般会造成 CPU 使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于 0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共 8G,剩余 3415M。
buff Linux/Unix 系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用 300 多 M
cache cache 直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用 300 多 M(这里是 Linux/Unix 的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached 会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于 0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于 0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是 1024byte,我本机上没什么 IO 操作,所以一直是 0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到 140000/s,磁盘写入速度差不多 140M 每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo 就要大于 0。bi 和 bo 一般都要接近 0,不然就是 IO 过于频繁,需要调整。
in 每秒 CPU 的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在 apache 和 nginx 这种 web 服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择 web 服务器的进程可以由进程或者线程的峰值一直下调,压测,直到 cs 到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的 CPU 大部分浪费在上下文切换,导致 CPU 干正经事的时间少了,CPU 没有充分利用,是不可取的。
us 用户 CPU 时间,我曾经在一个做加密解密很频繁的服务器上,可以看到 us 接近 100,r 运行队列达到 80(机器在做压力测试,性能表现不佳)。
sy 系统 CPU 时间,如果太高,表示系统调用时间长,例如是 IO 操作频繁。
id 空闲 CPU 时间,一般来说,id + us + sy = 100,一般我认为 id 是空闲 CPU 使用率,us 是用户 CPU 使用率,sy 是系统 CPU 使用率。
wt等待 IO CPU 时间。
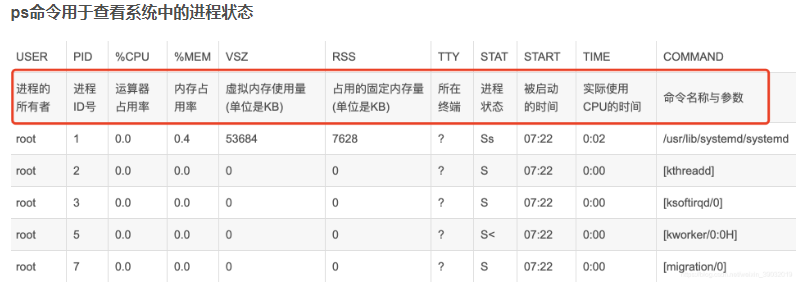
1.3 ps aux命令

2.内存使用率
2.1 free命令

- free ----以KB为单位显示内存使用情况
[root@izwz94b8tt3jlf3ne0ymp3z ~]# free ##以KB为单位显示内存使用情况
total used free shared buff/cache available
Mem: 32780244 18509816 5784948 11504 8485480 13856092
Swap: 0 0 0
- free -m —以MB为单位显示内存使用情况
[root@izwz94b8tt3jlf3ne0ymp3z ~]# free -m ##以MB为单位显示内存使用情况
total used free shared buff/cache available
Mem: 32011 18075 5649 11 8286 13531
Swap: 0 0 0
- free -g —以GB为单位显示内存使用情况
[root@izwz94b8tt3jlf3ne0ymp3z ~]# free -g ##以GB为单位显示内存使用情况
total used free shared buff/cache available
Mem: 31 17 5 0 8 13
Swap: 0 0 0
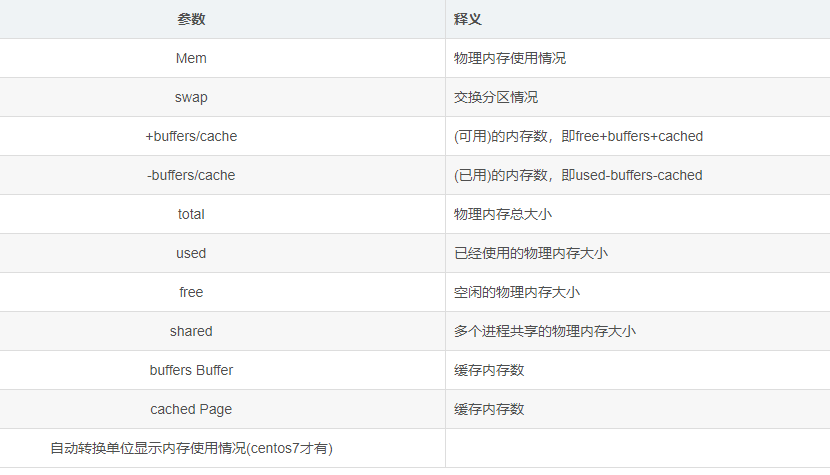
total 总内存 = used + free + buff/cache
available 还能用的内存 = free + buff/cache
如果使用到交换分区,则表明物理内存不够或内存泄漏了
关于 buffer 和 cache:
- 我们的数据是存放在磁盘上的,数据是交给CPU进行处理的,但磁盘的运转速度很慢,CPU的运转速度很快,不可能直接把磁盘的数据直接丢给CPU进行处理,因此要经过一个中间层,即内存,我们把这部分内存称为缓存(cache);
- 相反地CPU把数据处理完了,要存放到磁盘中,也要经过内存这个中间层,这部分内存则称为缓冲(buffer)因此,数据的流向不一样,内存的角色也不一样。系统会优先预留一部分内存给 buff/cache 使用,剩下的内存再留给系统或程序使
3.磁盘使用率
3.1 df-h 命令
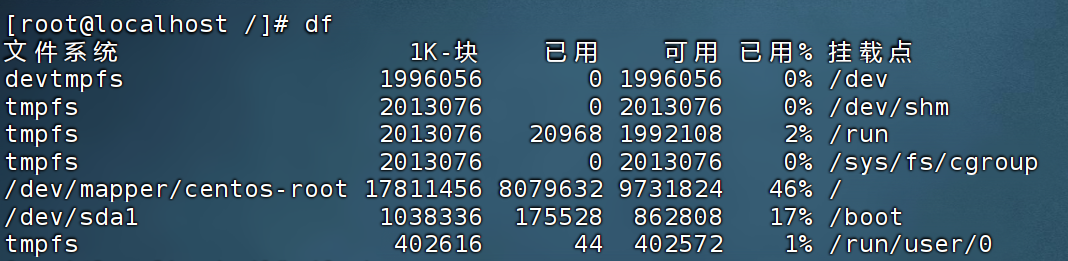
- df-h
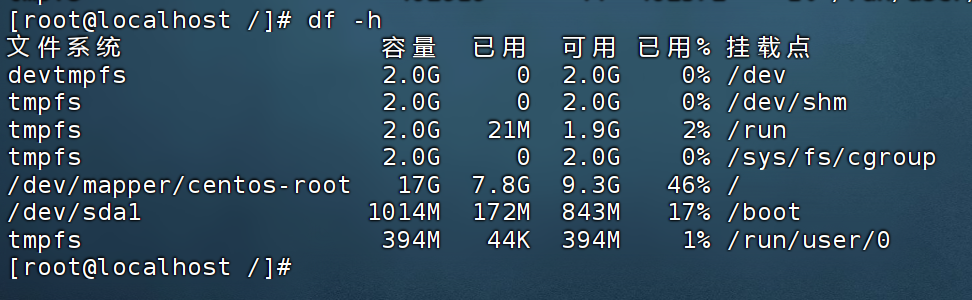
[root@izwz94b8tt3jlf3ne0ymp3z ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 16379668 0 16379668 0% /dev
tmpfs 16390120 0 16390120 0% /dev/shm
tmpfs 16390120 11496 16378624 1% /run
tmpfs 16390120 0 16390120 0% /sys/fs/cgroup
/dev/vda1 309505004 181307880 113500932 62% /
/dev/vdb1 515927276 21636792 471730172 5% /data
25b5d49774-fjs35.cn-shenzhen.nas.aliyuncs.com:/ 1099511627776 34277376 1099477350400 1% /content
tmpfs 3278028 4 3278024 1% /run/user/0