文章目录
- 前言
- Redis实现数据的持久化
- Redis实现持久化的策略
- RDB
- 手动触发RDB持久化操作
- 自动触发RDB持久化操作
- AOF
- AOF重写机制
前言
众所周知,Redis 操作数据都是在内存上操作的,而我们都知道内存是易失的,服务器重启或者主机掉电都会导致内存中的数据丢失,那么这样的话,我们重启服务器之后,Redis 上的数据就消失了,那么这样就会很麻烦。所以为了解决这个问题,Redis 也实现了数据的持久化,虽然不像 MySQL 那样至始至终数据都是在硬盘上存储的,但是对于操作数据速度快的 Redis 来说,这种持久化也是可以的。
Redis实现数据的持久化
Redis 实现数据持久化是即在内存中存储数据,也会将内存中的数据存在硬盘上,当 Redis 服务重启的时候,虽然此时内存中的数据丢失了,但是 Redis 可以将硬盘中的数据再读入内存中。那么这是有人就会问了:将同一份数据存储两份是不是浪费空间呢?为了实现 Redis 的持久化,这些空间的使用是非常有必要的,并且相对于速度来说,硬盘空间的价格相对更低一些。
Redis实现持久化的策略
那么 Redis 实现持久化的时候,具体是按照哪些策略来进行的呢?这里主要用到了两种策略:RDB 和 AOF
- RDB(Redis Database):定期将内存中的数据存储到硬盘中
- AOF(Append Only File):实时将内存中的数据存储到硬盘中
RDB
RDB 持久化策略是将内存中的数据定期存放在硬盘中,生成一个“快照”,到后面 Redis 服务重启的时候,首先就会根据这个“快照”进行数据的恢复。而这个定期持久化的方式又有两种:一种是手动触发,另一种就是自动触发。
在学习 RDB 持久化之前,我们还需要知道 redis.conf 中的一些配置选项:
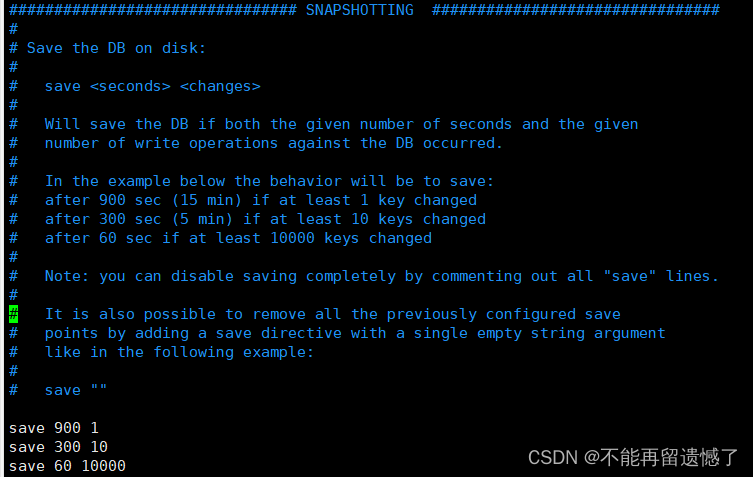
这个选项是自动触发 RDB 持久化操作的条件,前面第一个数字代表着多少秒之内,第二个数字表示操作的次数,也就是说在多少秒之内操作了至少多少次才会自动触发 RDB 持久化操作,默认的自动触发的条件就是在 15 分钟内操作了至少 1 次、在 5 分钟之内操作了至少 10 次、在一分钟之内操作至少 10000 次,我们可以通过修改这个配置的值来符合我们的实际情况。
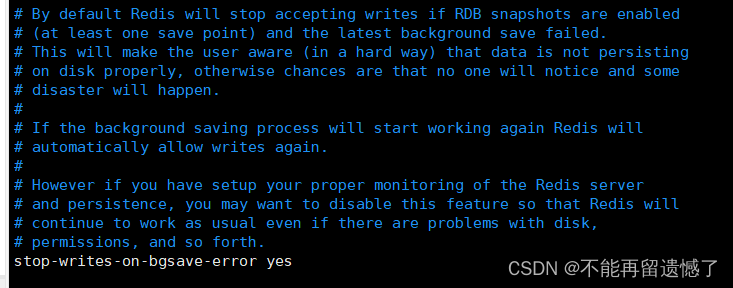
stop-writes-on-bgsave-error yes,用于控制当RDB持久化过程中出现错误时,Redis是否应停止接受写入操作。
如果设置为yes,当RDB持久化(如执行bgsave命令)出错时,Redis会停止接受新的写入请求。这通常是因为操作系统内存不足或其他与持久化相关的错误。这种设置可以确保数据的一致性,但也可能导致客户端请求被拒绝,影响服务的可用性。

这个选项是配置 RDB 持久化操作生成的文件的名称,默认是 dump.rdb
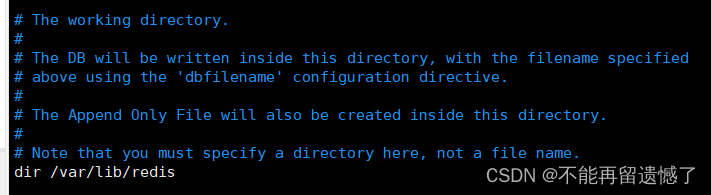
这个选项是指定持久化生成的文件将会被放在哪个目录下,我们可以在这个目录下找打我们 RDB 操作生成的“快照”。
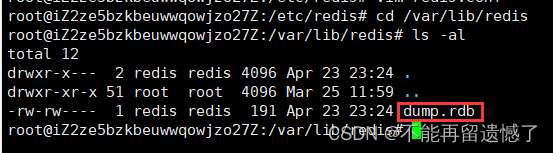
可以看看这个文件中已经存储了哪些数据:
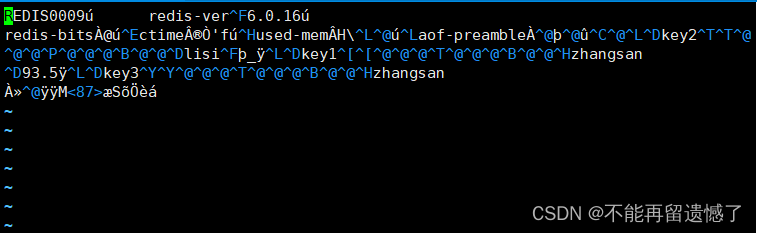
可以看到 rdb 文件中存储的数据都是二进制数据,以二进制的形式存储数据一是可以节省空间,二是 Redis 服务在启动的时候,读取二进制数据相较于读取文本数据速度更快,虽然我们看不到这些二进制数据,但是可以大致看出来当前存在哪些 key。
注意:rdb 文件不可以随意修改,如果随意修改的话,可能会导致 redis 服务重启的时候出现一些错误的数据,也可能导致 redis 服务根本无法正常启动。
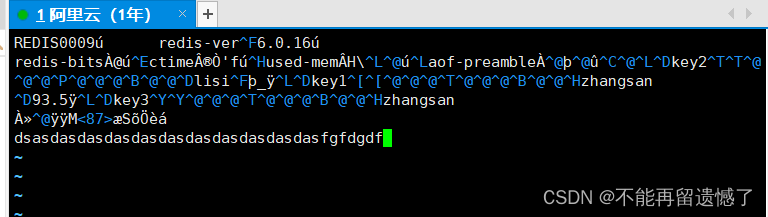
我这里对 rdb 文件进行随意的修改,然后启动 redis 服务看是否能启动成功:
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# redis-cli
127.0.0.1:6379> keys *
1) "key2"
2) "key1"
3) "key3"
127.0.0.1:6379> type key1
zset
127.0.0.1:6379> zrange key1 0 -1
1) "zhangsan"
127.0.0.1:6379> type key2
zset
127.0.0.1:6379> zrange key2 0 -1
1) "lisi"
127.0.0.1:6379> zrange key3 0 -1
1) "zhangsan"
当我们在 rdb 的末尾添加错误数据的时候 redis 可以正常启动,但是可能会存在错误的数据。而我们如果在 rdb 文件的中间添加错误的数据的时候就会出现 redis 服务无法正常启动的情况。
退一步讲,如果我们的 rdb 文件被修改了之后,那么该如何做呢?首先我们可以使用redis-check-rdb dump.rdb命令检查 rbd 文件是否存在错误:
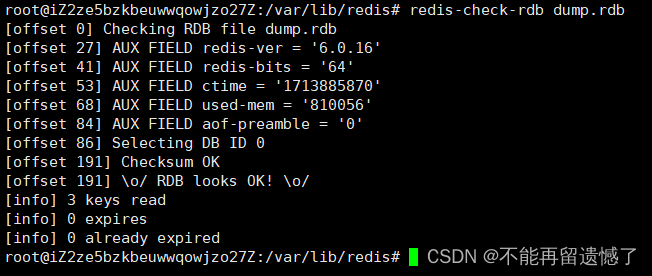
上面是检查 rdb 文件没有问题的时候。
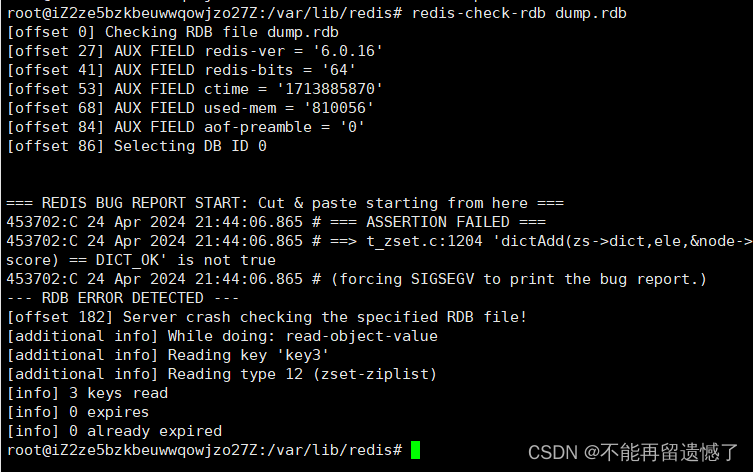
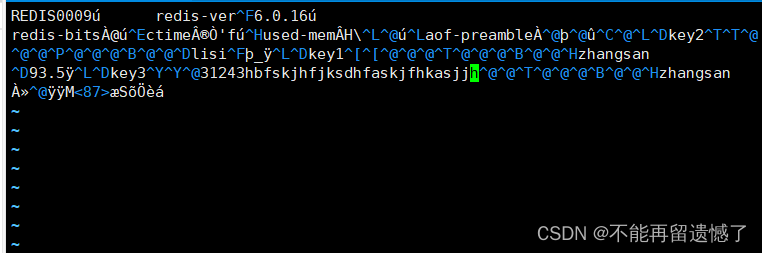
而这里则是检查 rdb 文件出现错误的情况。
那么既然检查出了 rdb 文件存在问题之后,我们可以手动修改错误(如如果能够看懂二进制数据并且找到错误在哪里当然是可以的),或者就是暴力方法,直接将这个文件删了。
当了解了这些跟 rdb 持久化操作相关的配置之后,我们来了解一下如何手动和自动实现 RDB 持久化操作:
手动触发RDB持久化操作
手动触发 RDB 持久化操作依赖于两个命令 save 和 bgsave。
当使用 save 命令的时候 redis 会全力以赴的进行“快照”生成的操作,此时就会阻塞其他 redis 命令的执行,也就类似于 keys * 这样的操作,所以不建议大家使用这个命令实现 RDB 持久化操作,而是建议大家使用另一个 RDB 持久化操作 bgsave。
bgsave 和 save 的最终效果是一样的,只不过过程不同,bgsave 会创建出来一个子进程,然后将此时 redis 内存中存储的数据拷贝到一个临时文件中,等内存中的所有数据都快拷贝完成之后,才会将之前的 rdb 文件删除掉,然后再将这个临时文件的文件名改为对应的 rdb 文件。
在添加数据之前,先来看看 dump.rdb 文件中有什么数据:
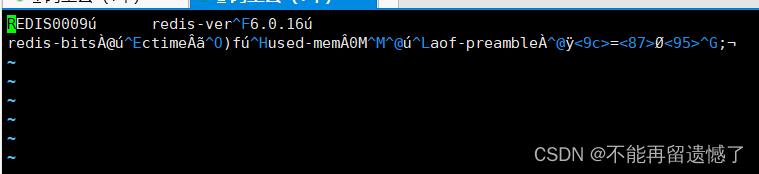
然后向 redis 中添加一些数据并且手动触发 RDB 持久化操作:
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> set key2 222
OK
127.0.0.1:6379> set key3 333
OK
127.0.0.1:6379> BGSAVE
Background saving started
再来看看 dump.rdb 文件中有哪些数据:

可以大致看到我们新添加进去的 key1、key2和key3 数据,然后我们再重新启动一下 redis 服务,看看这些数据是否还存在:
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# ps -aux | grep redis
redis 453884 0.5 0.6 67212 11140 ? Ssl 22:03 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 453891 0.0 0.1 6480 2460 pts/0 S+ 22:03 0:00 grep --color=auto redis
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# service redis-server restart
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# ps -aux | grep redis
redis 453898 2.0 0.6 67212 11016 ? Ssl 22:03 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 453904 0.0 0.1 6480 2332 pts/0 S+ 22:03 0:00 grep --color=auto redis
127.0.0.1:6379> keys *
1) "key1"
2) "key3"
3) "key2"
127.0.0.1:6379> get key1
"111"
127.0.0.1:6379> get key2
"222"
127.0.0.1:6379> get key3
"333"
可以看到这些数据是存在的,所以通过 save 或者 bgsave 命令手动触发 RDB 持久化操作是可行的。
自动触发RDB持久化操作
为了更轻松的达到自动触发 RDB 持久化的操作,我们修改一下自动触发的条件:

127.0.0.1:6379> set key3 333
OK
127.0.0.1:6379> set key4 444
OK
127.0.0.1:6379> set key5 555
OK
可以看到,新添加的key3,key4和key5都被写入了 rdb 文件中。
通过配置文件中时间和次数限制,可以自动触发 redis 的 RDB 持久化操作,不仅如此,当我们进行 flushall 操作和退出 redis 的时候也会自动触发 RDB 持久化操作:
127.0.0.1:6379> set key6 666
OK
127.0.0.1:6379> set key7 777
OK
127.0.0.1:6379> SHUTDOWN
127.0.0.1:6379> SHUTDOWN
not connected> exit
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis#
127.0.0.1:6379> set key8 888
OK
127.0.0.1:6379> set key9 999
OK
127.0.0.1:6379> FLUSHALL
下面是 bgsave 执行的大致流程:
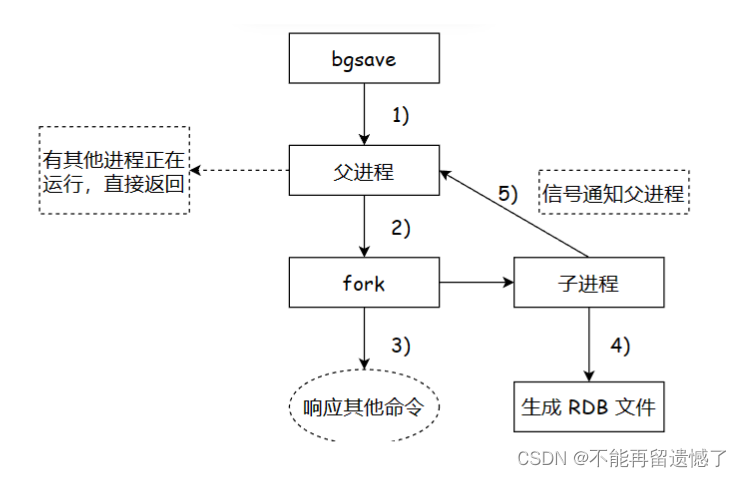
当父进程执行 bgsave 的时候如果发现有其他进程也在执行 bgsave 命令,那么该父进程就会直接返回,因为有其他进程执行了,拷贝的数据是差不多的,不需要做出额外的操作。如果此时没有其他的进程进行 bgsave 操作,那么当前父进程就会使用 fork() 命令创建出来一个子进程,让这个子进程将此时内存中存储的数据拷贝到临时生成的 rdb 文件中,当拷贝完成之后在发送信号告诉父进程我这里拷贝完成了。
在进行 RDB 操作的时候,是需要消耗一点时间的,bgsave 操作拷贝的是此时内存中存在的数据,如果在拷贝的过程中,数据库中的数据又发生了变化,那么也就意味着生成的 RDB 文件中的数据和内存中的实时数据是存在差别的,但是其实这个问题是不用很担心的,因为 RDB 持久化操作的目的就是定时拷贝,即使拷贝完成的 RDB 文件和实时内存数据存在一些差距也是没有很大问题的。但是还有一个问题就是,当未达到 RDB 自动存储的条件的时候,如果在这期间 redis 服务器发生了重启或者断电的时候,那么在上一次存储的数据到此时的数据由于没来得及进行持久化操作,所以这部分的数据就会丢失。
向 redis 中添加一些数,但是不达到自动持久化的条件,也不手动持久化,然后直接关闭 redis 服务的进程:
127.0.0.1:6379> set key4 444
OK
127.0.0.1:6379> set key5 555
OK
127.0.0.1:6379>
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# ps -aux | grep redis
redis 453965 0.1 0.6 67212 11268 ? Ssl Apr24 1:03 /usr/bin/redis-server 0.0.0.0:6379
root 455967 0.0 0.1 6480 2292 pts/0 S+ 14:20 0:00 grep --color=auto redis
root@iZ2ze5bzkbeuwwqowjzo27Z:/var/lib/redis# kill -9 453965

可以看到,在上一次持久化操作到此时内存中的数据就没有存储在硬盘中,这部分的数据就丢失了。
所以如果我就想要拷贝的硬盘上的数据和实时内存中的数据一样该怎么办呢?这个也是有办法的,这里就需要使用到我们的第二种持久化操作——AOF持久化操作了。
AOF
Redis AOF(append only file)每次会将用户的操作记录在文件中,当 redis 重启的时候就会读取这个文件中的内容来恢复数据。aof 默认是关闭的,如果需要使用 AOF 持久化操作而不是 RDB 的话,就需要我们在配置文件中配置:

这个配置 no 表示不使用 AOF 作为持久化操作,yes 表示使用,我们把它改为 yes。

这个选项是 AOF 持久化操作生成的文件的名称,默认是 appendonly.aof ,该文件还是和 RDB 操作生成的文件在同一个目录中。
这两个配置后面为大家介绍。
当修改完成配置文件之后,重启 redis 服务使配置文件生效,然后使用一些 redis 命令:
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> set key2 222
OK
127.0.0.1:6379> set key3 333
OK
再看看 appendonly.aof 文件中的内容:

可以发现使用 AOF 实现持久化操作生成的 aof 文件中存储的都是我们用户输入的命令,并且是以文本的形式存储的,只不过中间加入了一些分隔符而已。
这时候可能会有人问了:既然 AOF 持久化操作是实时进行持久化的操作,那么我们每次敲下一个命令,既要向内存中写入数据,也要向硬盘中写入数据,那么这样的话,I/O 的次数不就会很多了嘛?redis 执行命令的速度是否会很慢呢?按道理来说是这样的,但是 redis 也做了一些优化,AOF 并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区中,当缓冲区中有一些数据之后,才会将缓冲区中的命令都写入硬盘中,这样就减少了 I/O 次数,不仅如此,写入硬盘的顺序也是依次将缓冲区中的内容写入文件的末尾,也就是顺序写入,在硬盘上读写数据,顺序读写的速度也是比较快的(虽然没有内存快),但是这个速度我们人的感知也不是很大的。
但是这时候又会出现新的问题:当内存中的缓冲区的数据还没有写入硬盘之前,如果这时候计算机掉电重启了之后,那么我们内存缓冲区中的数据是否也会丢失呢?答案是是的,但是如果真的遇到了这种情况也是没有办法的。但是有一些措施可以减少损失,就是 redis 给出了一些选项,让我们根据实际情况来决定缓冲区的刷新策略。通过刷新缓冲区,我们可以手动控制缓冲区中的数据写入硬盘的时间,这样就可以减少因掉电造成的数据丢失。
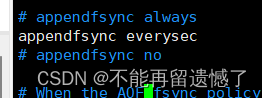
appendfsync选项:
| 可配置值 | 说明 |
|---|---|
| always | 命令写入 aof_buf 之后调用fsync同步,完成后返回 |
| everysec | 命令写入 aof_buf 之后只执行 write 操作,不进行fsync,每秒由同步线程进行fsync |
| no | 命令写入 aof_buf 之后,只进行 write 操作,由 OS 控制 fsync 频率 |
刷新频率越高,性能影响就越大,但是数据的可靠性就越高
刷新频率越低,性能影响越小,但是数据的可靠性就越低
AOF 命令会将用户输入的所有命令都存入硬盘文件中,那么随着我们输入的命令越来越多,该文件的大小就会越来越多,那么就会占用越来越多的硬盘资源,并且 redis 服务器启动时扫描的文件内容就越来越多,redis 启动的速度就会越来越慢,所以为了解决这个问题,就出现了 重写机制。
什么是重写机制呢?
AOF重写机制通过创建一个新的AOF文件来解决这个问题。新文件只包含当前有效和存在的数据的写入命令,而不是历史上所有的写入命令。这样可以大大减少AOF文件的体积,提高数据恢复的效率。AOF重写也是通过fork子进程来完成的,子进程会扫描Redis的数据库,将键值对转换为相应的写入命令,并写入到临时文件中。完成重写后,临时文件会替换旧的AOF文件。
例如,下面的命令就可以进行重写:
lpush key 111
lpush key 222
lpush key 333
set key1 111
set key1 222
set key1 333
set key2 111
del key2
set key2 222
del key2
上面的命令就可以重写为 lpush 111 222 333,set key1 333和空,就类似这样的重写机制,就可以大大减少 AOF 持久化操作生成的文件的大小。
AOF 重写机制的触发也分为两种情况:手动触发和自动触发。
手动触发就是依靠 bgrewriteaof 命令:
在测试 AOF 的重写机制之前,我们需要更改配置文件中的选项的值:
这个选项表示是否使用 rdb 和 aof 两种机制,后面为大家继续介绍。
127.0.0.1:6379> keys *
1) "key2"
2) "key3"
3) "key1"
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> set key1 222
OK
127.0.0.1:6379> set key1 333
OK
在使用 bgrewriteaof 之前查看 appendonly.aof 文件中的内容:
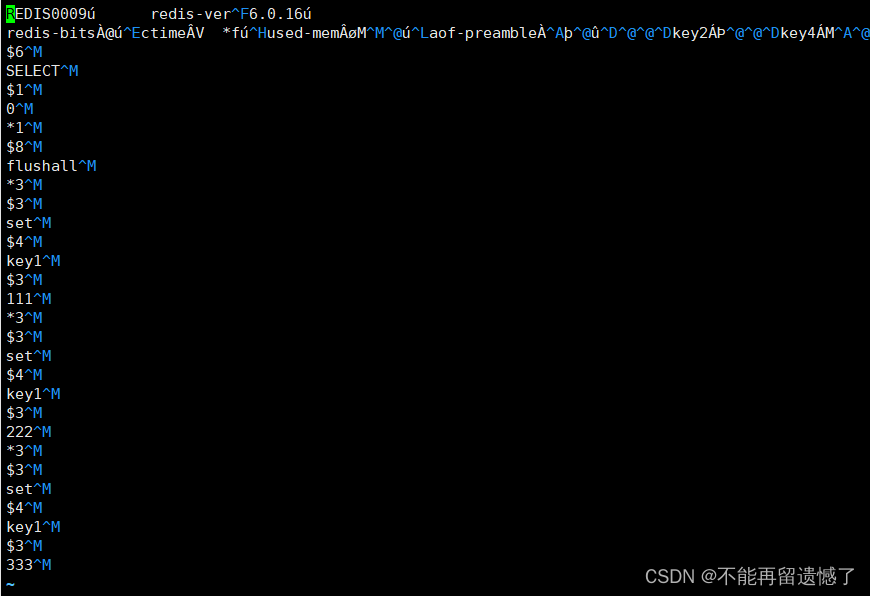
然后使用复写命令:
127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started
再查看 appendonly.aof 文件中的内容:
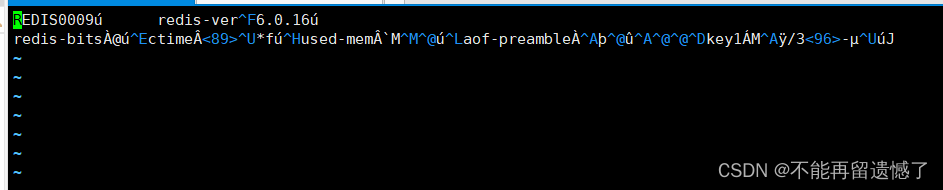
可以看到 appendonly.aof 文件中的内容的数据格式变成了二进制的形式,前面不是说 AOF 持久化操作生成的文件的数据格式是文本格式嘛,这里为什么是二进制格式呢?这里后面为大家介绍。
虽然此时 aof 中文件的数据是二进制数据,但是我们可以大致看出来,此文件中存储的命令只有 set key1 333,也就是使用 bgrewriteaof 实现了重写。
这里自动触发 AOF 持久化操作也是需要满足条件的:
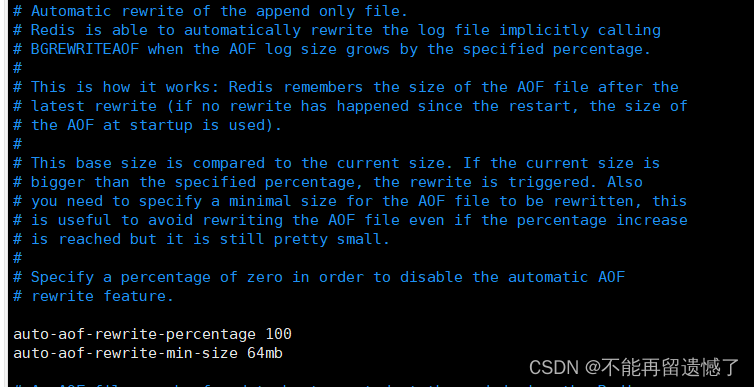
如果当前 AOF 文件的大小是上次重写后大小的 auto-aof-rewrite-percentage 的百分比加上指定的大小(由 auto-aof-rewrite-min-size 控制),那么 Redis 就会触发一次 AOF 重写。
这里自动触发 AOF 持久化机制的操作就不为大家展示了。
AOF重写机制
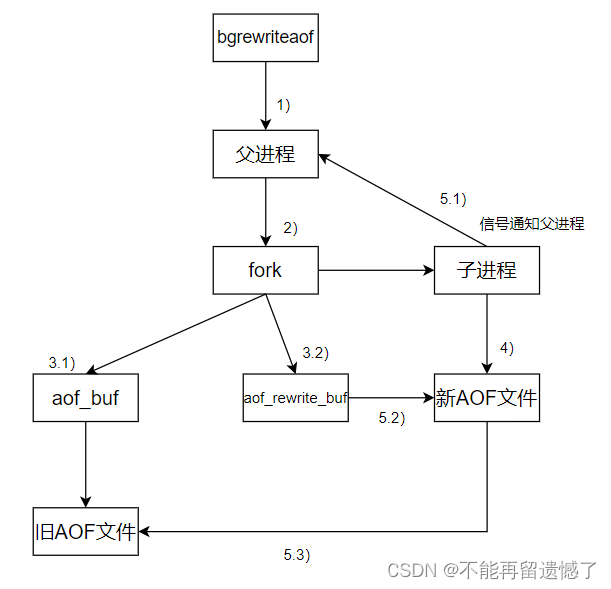
当父进程触发了重写机制时,跟 bgsave 一样,不是父进程来进行重写操作,而是创建出一个子进程来进行重写操作,这个创建的子进程会继承当前父进程的内存状态,那么子进程进行重写的时候就会从这个继承的内存中读取数据进行重写。在这个过程中,父进程仍然会接收请求,并且会将接收到的请求的数据放进 aof_buf 和 aof_rewrite_buf 两个缓冲区中,当子进程将内存中的数据重写完成之后,子进程就会向父进程发送一个信号,当父进程接收到这个信号之后,就会将 aof_rewrite_buf 缓冲区中的数据也写入到新创建的含有重写的数据的 AOF 文件的后面,然后就可以用新的 AOF 文件替代掉原来的 AOF 文件了。
为什么重写的过程中会有两个缓冲区呢?aof_rewrite_buf 缓冲区的作用我们知道,但是 aof_buf 缓冲区的作用是什么呢?aof_buf 缓冲区的作用还是重写之前的缓冲区,在重写的时候,父进程还会将缓冲区中的数据持久化存储到旧 AOF 文件中。这时就会有人问了:不是有了新的 AOF 文件了吗?那么继续向旧的 AOF 文件中写入数据不会多此一举吗?肯定不是的,这样做是为了防止子进程在重写结束之前进程异常中断或者 redis 服务器重启等特殊情况,如果没有这一步操作,遇到了这个问题,那么在调用重写命令到重写结束时候的数据机会因为内存数据的丢失而丢失,而有了这一步操作则可以避免这种情况的发生。
如果在执行 bsrewriteaof 的时候,发现当前 redis 正在进行重写操作的时候,当前进程会直接返回,不会进行重写;但是如果在执行 bsrewriteaof 的时候,发现当前 redis 正在生成 RDB 快照的时候,当前进程不会返回,而是会等 RDB 快照生成完成之后,再进行重写。
RDB 持久化操作是定期生成快照,最终以二进制的形式存储,而 AOF 持久化操作则是实时存储用户输入的命令,然后对命令进行重写,最终以文本的形式进行存储。我们都知道机器读取文本数据的速度是比较慢的,这两种持久化的方式各有优点但也各有缺点,而我们的 redis 则是使用了混合持久化的方式:按照 AOF 的方式,用户输入的每个命令都会先存储在内存缓冲区中,等缓冲区到达一定大小之后,就会将缓冲区中的数据存储进硬盘文件中,并且当这个文件的大小到达一定大小之后,会进行重写操作,混合持久化的方式不是以文本的形式存储数据了,而是会将数据以二进制的形式存储,这样的操作既保证了数据的实时性,也不至于 redis 服务在启动的时候花费过多的时间。
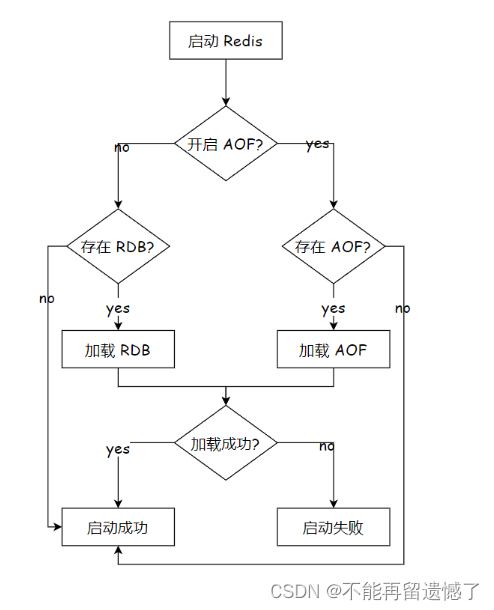
如果我们的 redis 工作目录中同时存在 rdb 文件和 aof 文件的时候,redis 启动的时候回忆哪个文件中的内容为准来恢复数据呢?其实这个问题大家仔细想想是能理解的,因为 aof 文件中的数据是实时存储的,所以 aof 文件中的数据比 rdb 文件中的数据更加可靠,所以当 aof 文件和 rdb 文件同时存在的时候,redis 恢复数据是以 aof 文件为准的。