文章目录
- 概述
- 原理介绍
- 模型架构
- 核心逻辑
- 嵌入表示层
- 注意力层
- 前馈层
- 残差连接和层归一化
- 编码器和解码器结构
- 数据处理和模型训练
- 环境配置
- 小结
本文涉及的源码可从transforme该文章下方附件获取
概述
Transformer模型是由谷歌在2017年提出并首先应用于机器翻译的神经网络模型结构。为了解决在处理长距离依赖关系时存在一些限制,同时也不易并行化,导致训练速度缓慢的问题,作者提出了全新的Transformer网络结构并引入了自注意力机制(Self-Attention),使得模型能够在每个位置上将输入序列的不同部分进行关联,从而更有效地捕捉长距离的依赖关系。此外,Transformer还采用了残差连接(Residual Connections)和层归一化(Layer Normalization)等技术,以加快训练速度并提高模型性能。
Transformer作为NLP发展史上里程碑的模型,其创造性地抛弃了沿用了几十年的 CNN、RNN 架构,完全使用 Attention 机制来搭建网络并取得了良好的效果,帮助 Attention 机制站上了时代的舞台,当前几乎全部大语言模型都是基于 Transformer 结构。而论及模型本身,Attention 机制的使用使其能够有效捕捉长距离相关性,解决了 NLP 领域棘手的长程依赖问题,同时,抛弃了 RNN 架构使其能够充分实现并行化,提升了模型计算能力。
原理介绍
模型架构
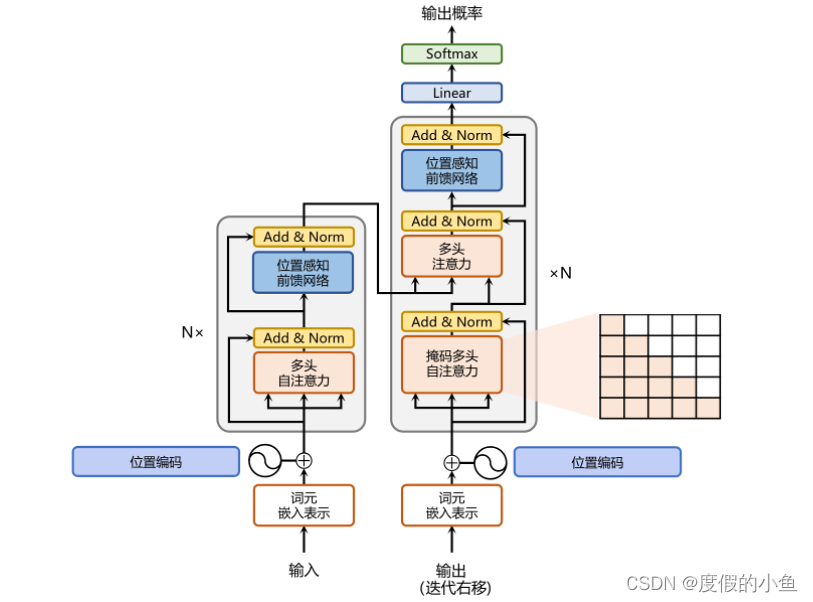
左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的 Transformer 块(Block)组成(对应着图中的灰色框)。这里 N× 表示进行了 N 次堆叠。接下来将逐个介绍 Transformer 的实现细节和原理。
核心逻辑
嵌入表示层
对于输入文本序列,首先通过输入嵌入层(Input Embedding)将每个单词转换为其相对应的向量表示。通常直接对每个单词创建一个向量表示。由于 Transfomer 模型不再使用基于循环的方式建模文本输入,序列中不再有任何信息能够提示模型单词之间的相对位置关系。在送入编码器端建模其上下文语义之前,一个非常重要的操作是在词嵌入中加入位置编码(Positional Encoding)这一特征。具体来说,序列中每一个单词所在的位置都对应一个向量。这一向量会与单词表示对应相加并送入到后续模块中做进一步处理。在训练的过程当中,模型会自动地学习到如何利用这部分位置信息。
为了得到不同位置对应的编码,Transformer 模型使用不同频率的正余弦函数如下所示:
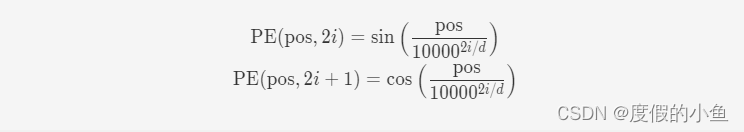
20240524224949272.png&pos_id=img-Z2ZKt0eO-1716562817991)
其中,pos 表示单词所在的位置,2i 和 2i+ 1 表示位置编码向量中的对应维度,d 则对应位置编码的总维度。通过上面这种方式计算位置编码有这样几个好处:首先,正余弦函数的范围是在 [-1,+1],导出的位置编码与原词嵌入相加不会使得结果偏离过远而破坏原有单词的语义信息。其次,依据三角函数的基本性质,可以得知第 pos + k 个位置的编码是第 pos 个位置的编码的线性组合,这就意味着位置编码中蕴含着单词之间的距离信息。pytorch实现代码如下
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
"""
输入
d_model - 输入的隐藏层维度.
max_len - 最大序列长度.
"""
super().__init__()
# 创建矩阵[SeqLen, HiddenDim]来表示输入的位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
# 将一个张量注册为一个缓冲区(buffer),缓冲区通常用于存储模型的状态,但不是模型的参数
# persistent 设置为 False,那么这个缓冲区不会被包括在模型的 state_dict() 中
self.register_buffer('pe', pe, persistent=False)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
注意力层
Attention机制最先源于计算机视觉领域,其核心思想为当我们关注一张图片,我们往往无需看清楚全部内容而仅将注意力集中在重点部分即可。而在自然语言处理领域,我们往往也可以通过将重点注意力集中在一个或几个 token,从而取得更高效高质的计算效果。Attention 机制的特点是通过计算 Query (查询值)与Key(键值)的相关性为真值加权求和,从而拟合序列中每个词同其他词的相关关系。给定由单词语义嵌入及其位置编码叠加得到的输入表示,为了实现对上下文语义依赖的建模,进一步引入在自注意力机制中涉及到的三个元素:查询 q(Query),键 k(Key),值 v(Value)。在编码输入序列中每一个单词的表示的过程中,这三个元素用于计算上下文单词所对应的权重得分。直观地说,这些权重反映了在编码当前单词的表示时,对于上下文不同部分所需要的关注程度。
为了得到编码单词xi时所需要关注的上下文信息,通过位置i查询向量与其他位置的键向量做点积得到匹配分数 qi·k1, qi·k2, …,qi·kt。为了防止过大的匹配分数在后续 Softmax 计算过程中导致的梯度爆炸以及收敛效率差的问题,这些得分会除放缩因子√d以稳定优化。放缩后的得分经过 Softmax 归一化为概率之后,与其他位置的值向量相乘来聚合希望关注的上下文信息,并最小化不相关信息的干扰。计算过程如下图所示
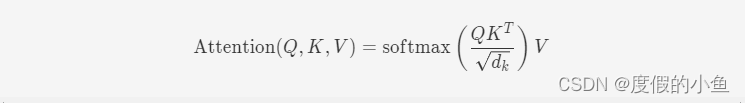
为了进一步增强自注意力机制聚合上下文信息的能力,提出了多头自注意力(Multi-head Attention)的机制,以关注上下文的不同侧面。具体来说,上下文中每一个单词的表示xi经过多组线性矩阵映射到不同的表示子空间中。pytorch 实现代码如下:
def scaled_dot_product(q, k, v, mask=None):
d_k = q.size()[-1]
attn_logits = torch.matmul(q, k.transpose(-2, -1))
attn_logits = attn_logits / math.sqrt(d_k)
if mask is not None:
attn_logits = attn_logits.masked_fill(mask == 0, -9e15)
attention = F.softmax(attn_logits, dim=-1)
values = torch.matmul(attention, v)
return values, attention
class MultiheadAttention(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "embedding 维度必须整除 num_head"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 为了提高效率,将权重矩阵qkv堆叠在一起
self.qkv_proj = nn.Linear(input_dim, 3 * embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
self._reset_parameters()
def _reset_parameters(self):
# 初始化
nn.init.xavier_uniform_(self.qkv_proj.weight)
self.qkv_proj.bias.data.fill_(0)
nn.init.xavier_uniform_(self.o_proj.weight)
self.o_proj.bias.data.fill_(0)
def forward(self, x, mask=None, return_attention=False):
batch_size, seq_length, _ = x.size()
if mask is not None:
mask = expand_mask(mask)
qkv = self.qkv_proj(x)
# 分离出Q, K, V
qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3 * self.head_dim)
qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, Dims]
q, k, v = qkv.chunk(3, dim=-1)
# 计算 value和注意力
values, attention = scaled_dot_product(q, k, v, mask=mask)
values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]
values = values.reshape(batch_size, seq_length, self.embed_dim)
o = self.o_proj(values)
if return_attention:
return o, attention
else:
return o
前馈层
前馈层接受自注意力子层的输出作为输入,并通过一个带有 Relu 激活函数的两层全连接网络对输入进行更加复杂的非线性变换。实验证明,这一非线性变换会对模型最终的性能产生十分重要的影响。计算过程如下图所示:
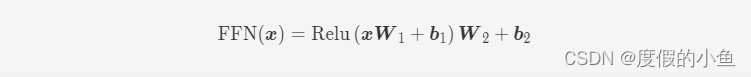
其中 W1, b1,W2, b2 表示前馈子层的参数。实验结果表明,增大前馈子层隐状态的维度有利于提升最终翻译结果的质量,因此,前馈子层隐状态的维度一般比自注意力子层要大。pytorch 实现代码如下:
self.linear_net = nn.Sequential(
nn.Linear(input_dim, dim_feedforward),
nn.Dropout(dropout),
nn.ReLU(inplace=True),
nn.Linear(dim_feedforward, input_dim)
)
残差连接和层归一化
由于Transformer 结构组成的网络结构通常都是非常庞大。编码器和解码器均由很多层基本的Transformer 块组成,每一层当中都包含复杂的非线性映射,这就导致模型的训练比较困难。因此,研究者们在 Transformer 块中进一步引入了残差连接与层归一化技术以进一步提升训练的稳定性。具体来说,残差连接主要是指使用一条直连通道直接将对应子层的输入连接到输出上去,从而避免由于网络过深在优化过程中潜在的梯度消失问题。此外,为了进一步使得每一层的输入输出范围稳定在一个合理的范围内,层归一化技术被进一步引入每个 Transformer 块的当中。层归一化技术可以有效地缓解优化过程中潜在的不稳定、收敛速度慢等问题。
编码器和解码器结构
transformer沿用了Seq2Seq模型的 Encoder-Decoder(编码器-解码器)结构。Encoder由N个(论文中取 N = 6)EncoderLayer 组成,每个 EncoderLayer又由两个sublayer(子层)组成,其中第一个子层为一个多头自注意力层,第二子层为一个全连接神经网络,实际是一个线性层+激活函数+ dropout + 线性层的全连接网络。
相比于编码器端,解码器端要更复杂一些。具体来说,解码器的每个 Transformer 块的第一个自注意力子层额外增加了注意力掩码,对应图中的掩码多头注意力(Masked Multi-Head Attention)部分。这主要是因为在翻译的过程中,编码器端主要用于编码源语言序列的信息,而这个序列是完全已知的,因而编码器仅需要考虑如何融合上下文语义信息即可。而解码端则负责生成目标语言序列,这一生成过程是自回归的,即对于每一个单词的生成过程,仅有当前单词之前的目标语言序列是可以被观测的,因此这一额外增加的掩码是用来掩盖后续的文本信息,以防模型在训练阶段直接看到后续的文本序列进而无法得到有效地训练。此外,解码器端还额外增加了一个多头注意力(Multi-Head Attention)模块,使用交叉注意力(Cross-attention)方法,同时接收来自编码器端的输出以及当前 Transformer 块的前一个掩码注意力层的输出。查询是通过解码器前一层的输出进行投影的,而键和值是使用编码器的输出进行投影的。它的作用是在翻译的过程当中,为了生成合理的目标语言序列需要观测待翻译的源语言序列是什么。基于上述的编码器和解码器结构,待翻译的源语言文本,首先经过编码器端的每个Transformer 块对其上下文语义的层层抽象,最终输出每一个源语言单词上下文相关的表示。解码器端以自回归的方式生成目标语言文本,即在每个时间步t,根据编码器端输出的源语言文本表示,以及前t−1个时刻生成的目标语言文本,生成当前时刻的目标语言单词。pytorch实现的编码器代码如下:
class EncoderBlock(nn.Module):
def __init__(self, input_dim, num_heads, dim_feedforward, dropout=0.0):
"""
输入:
input_dim - 输入的维度
num_heads - 注意力头的数量
dim_feedforward - MLP中隐藏层的维数
dropout - Dropout概率
"""
super().__init__()
# 多头注意力
self.self_attn = MultiheadAttention(input_dim, input_dim, num_heads)
# 两层 MLP
self.linear_net = nn.Sequential(
nn.Linear(input_dim, dim_feedforward),
nn.Dropout(dropout),
nn.ReLU(inplace=True),
nn.Linear(dim_feedforward, input_dim)
)
self.norm1 = nn.LayerNorm(input_dim)
self.norm2 = nn.LayerNorm(input_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 注意力部分
attn_out = self.self_attn(x, mask=mask)
x = x + self.dropout(attn_out)
x = self.norm1(x)
# MLP 部分
linear_out = self.linear_net(x)
x = x + self.dropout(linear_out)
x = self.norm2(x)
return x
class TransformerEncoder(nn.Module):
def __init__(self, num_layers, **block_args):
super().__init__()
self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ in range(num_layers)])
def forward(self, x, mask=None):
for l in self.layers:
x = l(x, mask=mask)
return x
def get_attention_maps(self, x, mask=None):
attention_maps = []
for l in self.layers:
_, attn_map = l.self_attn(x, mask=mask, return_attention=True)
attention_maps.append(attn_map)
x = l(x)
return attention_maps
数据处理和模型训练
获取 cifar100 数据集
from torchvision.datasets import CIFAR100
DATASET_PATH = "./datasets"
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
# ImageNet统计数据
DATA_MEANS = np.array([0.485, 0.456, 0.406])
DATA_STD = np.array([0.229, 0.224, 0.225])
TORCH_DATA_MEANS = torch.from_numpy(DATA_MEANS).view(1, 3, 1, 1)
TORCH_DATA_STD = torch.from_numpy(DATA_STD).view(1, 3, 1, 1)
# Resize to 224x224, and normalize
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(DATA_MEANS, DATA_STD)
])
# 加载训练数据集
train_set = CIFAR100(root=DATASET_PATH, train=True, transform=transform, download=True)
# 加载测试数据集
test_set = CIFAR100(root=DATASET_PATH, train=False, transform=transform, download=True)
使用 resnet 模型提取图片特征
@torch.no_grad()
def extract_features(dataset, save_file):
if not os.path.isfile(save_file):
data_loader = data.DataLoader(dataset, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
extracted_features = []
for imgs, _ in tqdm(data_loader):
imgs = imgs.to(device)
feats = pretrained_model(imgs)
extracted_features.append(feats)
extracted_features = torch.cat(extracted_features, dim=0)
extracted_features = extracted_features.detach().cpu()
torch.save(extracted_features, save_file)
else:
extracted_features = torch.load(save_file)
return extracted_features
CHECKPOINT_PATH = "./saved_models"
train_feat_file = os.path.join(CHECKPOINT_PATH, "train_set_features.tar")
train_set_feats = extract_features(train_set, train_feat_file)
test_feat_file = os.path.join(CHECKPOINT_PATH, "test_set_features.tar")
test_feats = extract_features(test_set, test_feat_file)
自定义数据类,并构建dataloader
class SetAnomalyDataset(data.Dataset):
def __init__(self, img_feats, labels, set_size=10, train=True):
"""
输入:
img_feats - 图片的特征向量,形状为[num_imgs, img_dim]
labels - 每个图片的类别标签
set_size - 集合中图片的数目。从一个类中采样N-1个,从另一个类中采样1个。
train - 是否是训练模式
"""
super().__init__()
self.img_feats = img_feats
self.labels = labels
self.set_size = set_size - 1
self.train = train
# 同个类别图片的下标
self.num_labels = labels.max() + 1
self.img_idx_by_label = torch.argsort(self.labels).reshape(self.num_labels, -1)
if not train:
self.test_sets = self._create_test_sets()
def _create_test_sets(self):
test_sets = []
num_imgs = self.img_feats.shape[0]
np.random.seed(42)
test_sets = [self.sample_img_set(self.labels[idx]) for idx in range(num_imgs)]
test_sets = torch.stack(test_sets, dim=0)
return test_sets
def sample_img_set(self, anomaly_label):
"""
根据异常的标签,对一组新的图像进行采样。采样的图像来自与normaly_label不同的类
"""
set_label = np.random.randint(self.num_labels - 1)
if set_label >= anomaly_label:
set_label += 1
img_indices = np.random.choice(self.img_idx_by_label.shape[1], size=self.set_size, replace=False)
img_indices = self.img_idx_by_label[set_label, img_indices]
return img_indices
def __len__(self):
return self.img_feats.shape[0]
def __getitem__(self, idx):
anomaly = self.img_feats[idx]
if self.train:
img_indices = self.sample_img_set(self.labels[idx])
else:
img_indices = self.test_sets[idx]
# concat图片同时把异常图片放在最后一个
img_set = torch.cat([self.img_feats[img_indices], anomaly[None]], dim=0)
indices = torch.cat([img_indices, torch.LongTensor([idx])], dim=0)
label = img_set.shape[0] - 1
return img_set, indices, label
# 将训练集划分成训练集和验证集
labels = train_set.targets
labels = torch.LongTensor(labels)
num_labels = labels.max() + 1
sorted_indices = torch.argsort(labels).reshape(num_labels, -1)
# 确定每个类的图像数量
num_val_exmps = sorted_indices.shape[1] // 10
# 获取验证和训练的图像索引
val_indices = sorted_indices[:, :num_val_exmps].reshape(-1)
train_indices = sorted_indices[:, num_val_exmps:].reshape(-1)
# 将相应的图像特征和标签分组
train_feats, train_labels = train_set_feats[train_indices], labels[train_indices]
val_feats, val_labels = train_set_feats[val_indices], labels[val_indices]
train_anom_dataset = SetAnomalyDataset(train_feats, train_labels, set_size=SET_SIZE, train=True)
val_anom_dataset = SetAnomalyDataset(val_feats, val_labels, set_size=SET_SIZE, train=False)
test_anom_dataset = SetAnomalyDataset(test_feats, test_labels, set_size=SET_SIZE, train=False)
train_anom_loader = data.DataLoader(train_anom_dataset, batch_size=64, shuffle=True, drop_last=True, num_workers=0,
pin_memory=True)
val_anom_loader = data.DataLoader(val_anom_dataset, batch_size=64, shuffle=False, drop_last=False, num_workers=0)
test_anom_loader = data.DataLoader(test_anom_dataset, batch_size=64, shuffle=False, drop_last=False, num_workers=0)
模型训练和推理
def train_anomaly(**kwargs):
# 创建PyTorch Lightning训练器
root_dir = os.path.join(CHECKPOINT_PATH, "SetAnomalyDetect")
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="cuda" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=100,
gradient_clip_val=2)
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# 检查是否存在预训练模型。如果存在,直接加载并跳过训练
pretrained_filename = os.path.join(CHECKPOINT_PATH, "SetAnomalyDetect.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = AnomalyPredictor.load_from_checkpoint(pretrained_filename)
else:
model = AnomalyPredictor(max_iters=trainer.max_epochs * len(train_anom_loader), **kwargs)
trainer.fit(model, train_anom_loader, val_anom_loader)
model = AnomalyPredictor.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
torch.save(model, pretrained_filename)
# 在验证和测试集上测试最佳模型
train_result = trainer.test(model, train_anom_loader, verbose=False)
val_result = trainer.test(model, val_anom_loader, verbose=False)
test_result = trainer.test(model, test_anom_loader, verbose=False)
result = {"test_acc": test_result[0]["test_acc"], "val_acc": val_result[0]["test_acc"],
"train_acc": train_result[0]["test_acc"]}
model = model.to(device)
return model, result
anomaly_model, anomaly_result = train_anomaly(input_dim=train_anom_dataset.img_feats.shape[-1],
model_dim=256,
num_heads=4,
num_classes=1,
num_layers=4,
dropout=0.1,
input_dropout=0.1,
lr=5e-4,
warmup=100)
环境配置
创建 python 虚拟环境
conda create -n trans python=3.10
安装依赖包
pip install -r requirements.txt
运行程序
python train.py
小结
Transformer 是一种基于自注意力(self-attention)机制的深度学习模型架构,最初由Google的研究团队在2017年的论文《Attention is All You Need》中提出,用于解决自然语言处理(NLP)中的序列到序列(sequence-to-sequence)问题,如机器翻译。由于其强大的性能和广泛的应用范围,Transformer已经成为NLP领域中最重要和最常用的模型之一。
以下是Transformer的主要组成部分和特性:
- 编码器(Encoder)和解码器(Decoder):Transformer由堆叠的编码器和解码器块组成。编码器处理输入序列,生成一个包含输入序列信息的上下文表示。解码器则利用这个上下文表示和之前的输出(在生成任务中)来预测下一个输出。
- 自注意力(Self-Attention)机制:这是Transformer的核心部分。自注意力机制允许模型在处理一个序列中的某个单词时,关注序列中的其他单词。这种能力使得模型能够捕获序列中的长期依赖关系,并理解单词之间的相对位置。
- 位置编码(Positional Encoding):由于Transformer模型不包含递归或卷积结构,它无法像RNN或CNN那样自然地捕获序列中的位置信息。因此,Transformer通过位置编码来向模型提供位置信息。位置编码可以是固定的(如正弦和余弦函数)或可学习的。
- 多头注意力(Multi-Head Attention):在Transformer中,自注意力机制被扩展为多头注意力,即使用多个独立的自注意力层并行处理输入,然后将它们的输出进行拼接。这种设计使得模型能够同时关注输入序列中的不同方面。
- 残差连接(Residual Connections)和层归一化(Layer Normalization):为了缓解深度神经网络中的梯度消失问题,Transformer在每个子层(包括自注意力层和前馈神经网络层)之间使用了残差连接和层归一化。
- 前馈神经网络(Feed-Forward Neural Network):在自注意力层之后,每个编码器和解码器块都包含一个全连接的前馈神经网络,用于对自注意力层的输出进行非线性变换。
由于Transformer的出色性能和广泛的应用范围,它已经扩展到其他领域,如计算机视觉、语音识别和强化学习等。此外,基于Transformer的许多变体模型也被提出,以解决不同的问题和适应不同的任务。