Yolov8是2023年1月份开源的。与yolov5一样,支持目标检测、分类、分割任务。
Yolov8主要改进之处有以下几个方面:
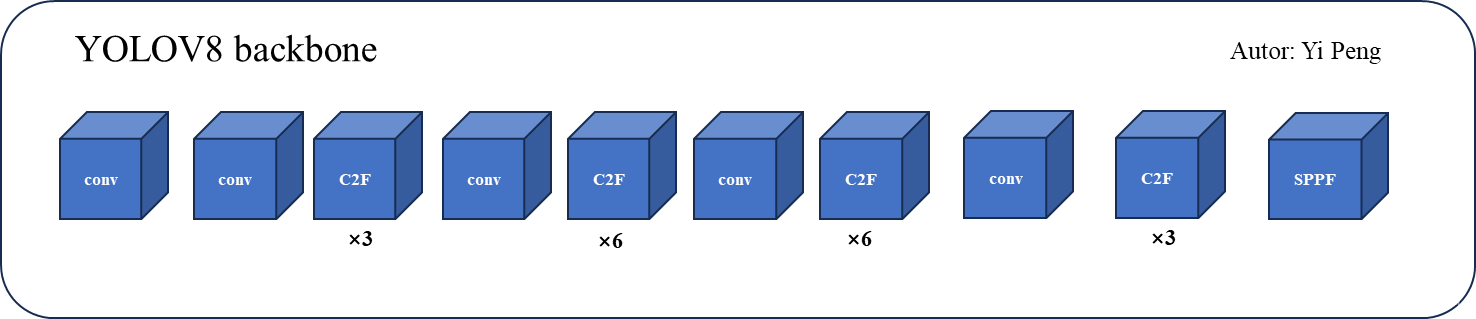
Backbone:依旧采用的CSP的思想,不过将Yolov5中的C3模块替换为C2F模块,进一步降低了参数量,同时yolov8依旧采用了yolov5中的SPPF模块;
PAN-FPN:Yolov8依旧采用了PAN思想,只不过是将PAN中的上采样阶段中的卷积结构删除,将C3模块替换为了C2F模块;
Decoupled-Head:该方法是采用了YOLOX的head部分,分类和回归两个任务的head不再共享参数;
Anchor-Free:YOLOv8使用了Anchor-Free的思想;
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为回归损失;
样本匹配:之前的yolo是用iou,或者anchor与gt的宽高比来匹配样本的,但在yolov8中采用的是Task-Aligned Assigner作为样本匹配(因为没有anchor了,所以就得换个匹配策略)。
同样,yolov8和v5一样,也有yolov8n,yolov8s,yolov8m,yolov8l,yolov8x对应不同的参数量模型。
网络模型解析
要想大致了解yolov8结构可以直接看yaml配置文件,然后再慢慢的解析里面的结构。
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)backbone
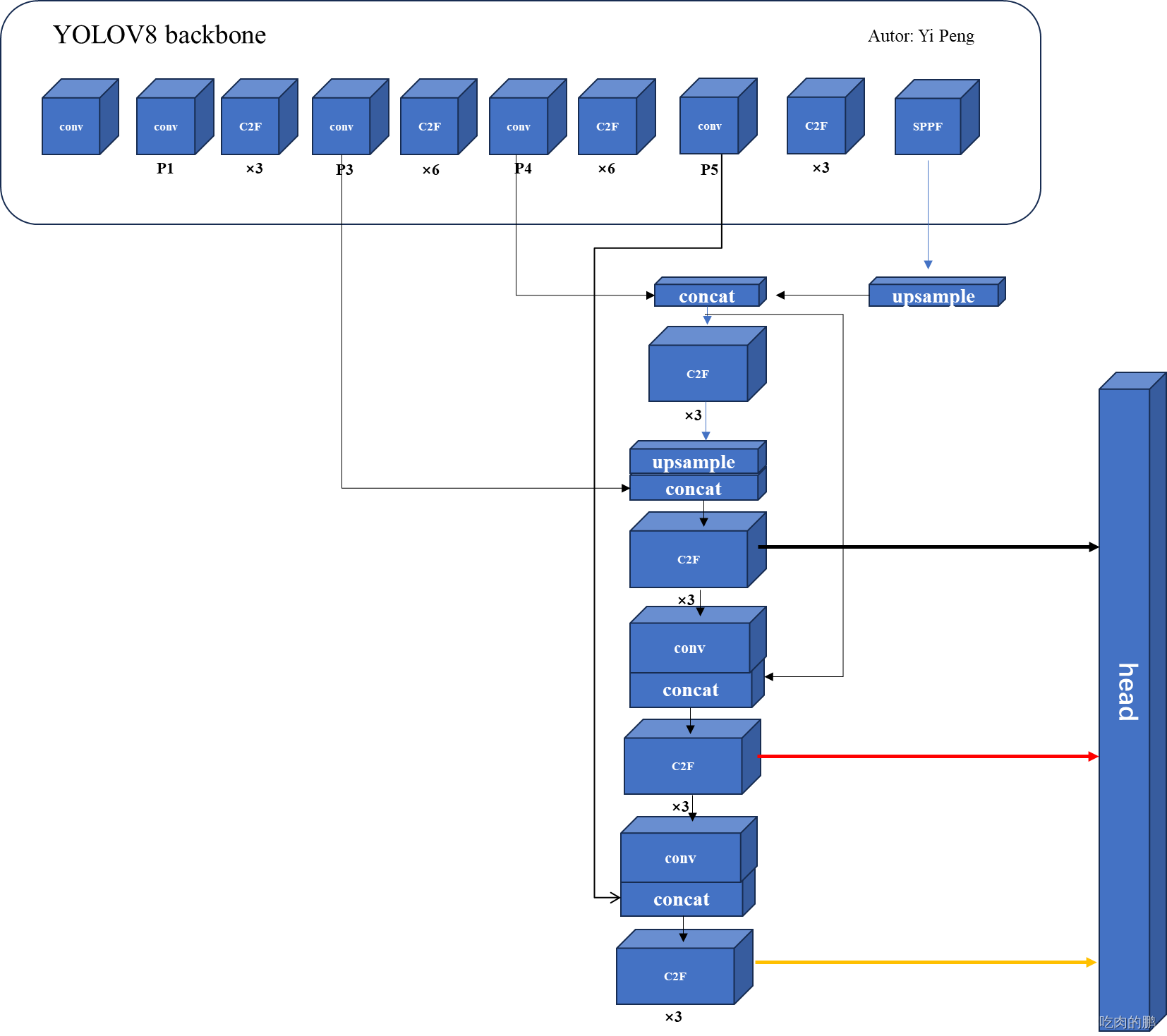
这里先附上完整的yolov8 backbone结构图:
C2F卷积层
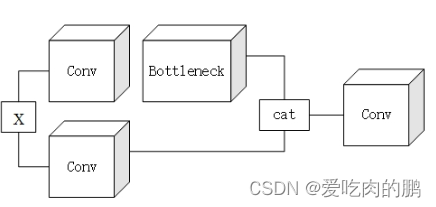
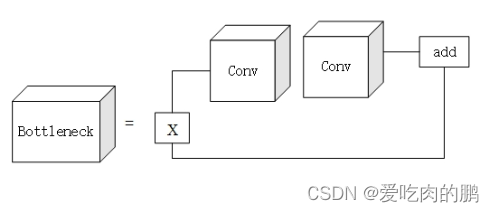
yolov8将yolov5中的C3模块替换为C2F,我们先来看一下C3模块:
|
|
C3网络结构还是借助了CSPNet思想,同时结合了残差网络结构所设计的。
yolov8是将C3替换为C2F网络结构,我们先不要着急看C2F,我们先介绍一下chunk函数,因为在C2F中会用到该函数,如果你对该函数很了解那么可以略去该函数的讲解。chunk函数,就是可以将张量A沿着某个维度dim,分割成指定的张量块。可以看个示例:
假设我的输入张量x的shape为[1,3,640,640],经过一个1x1的卷积后,输出shape为[1,16,640,640],如下:
torch.Size([1, 3, 640, 640])
>>> out = conv1(x)
>>> out.shape
torch.Size([1, 16, 640, 640])然后利用chunk函数在通道维度上分成两块:
>>> out_chunk = torch.chunk(out,2,1)此时我们得到的out_chunk是个tuple类型,那么我们来打印一下这两个输出的shape:
>>> out_chunk[0].shape
torch.Size([1, 8, 640, 640])
>>> out_chunk[1].shape
torch.Size([1, 8, 640, 640])可以看到通过chunk函数将输出通道为16,平均分成了2份后,每个tensor的shape均为[1,8,640,640]。这里只是补充了一下torch.chunk函数的知识~
接下来我们继续看C2F模块。结构图如下:我这里是参考C2F代码来绘制的。
C2F就是由两个卷积层和n个Bottleneck层组成。与yolov5 C3结构很像,只不过C3中的Feat1和Feat2是通过两个卷积实现的,而C2F中通过chunk函数将一个卷积的输出进行分块得到,这样的一个好处就是减少参数和计算量。
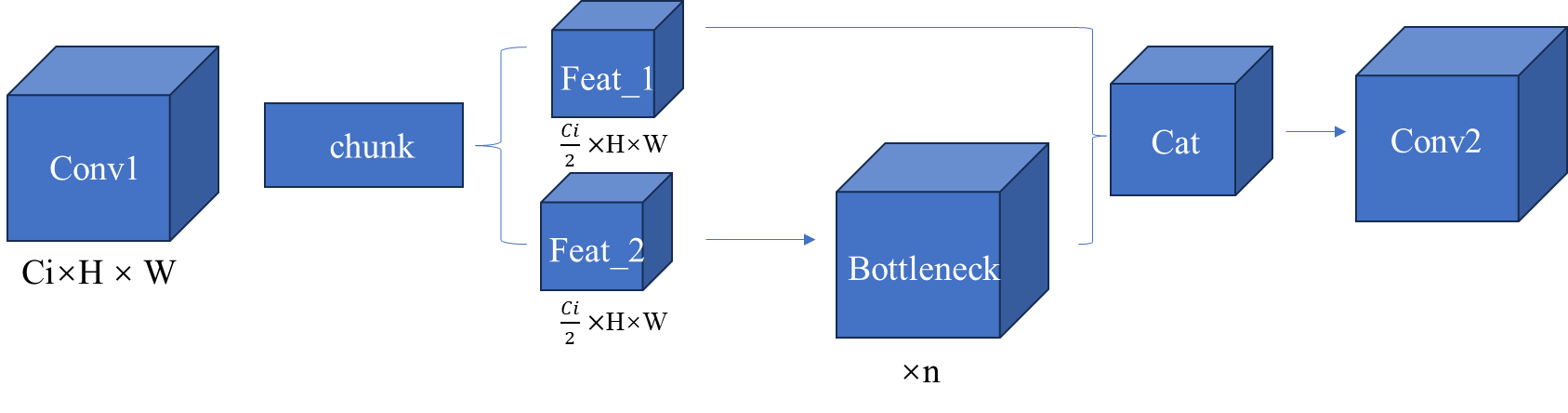
C2F代码如下所示:
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))SPPF结构
SPPF结构如下:
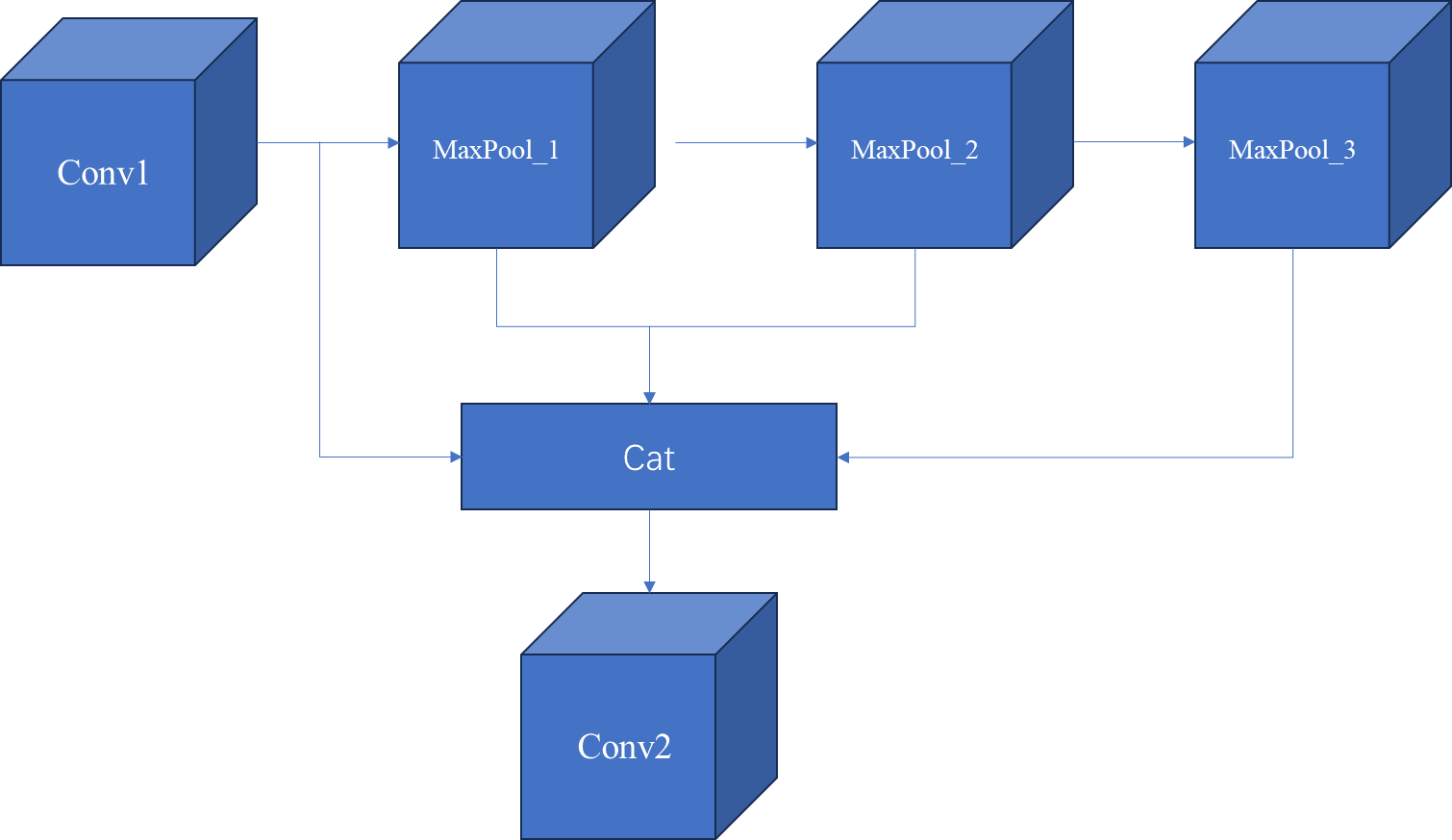
SPPF对应代码:
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))完整的YOLOV8模型结构
完整的YOLOv8结构图如下所示(这里参照yolov8.yaml文件绘制)
head
yolov8的head和yolov5的区别是,v5采用的是耦合头,v8采用的解耦头。什么叫耦合头呢?其实就是在网络最终输出的时候是把bbox、obj、cls三个部分耦合在一起(比如coco数据集,我们知道输出的其中有一个维度是85=5+80,比如有个特征层的shape为【bs,80,80,3,85】,80x80是特征图的高和宽,3是三种anchors,85就是),而v8是将head做了拆分,解耦成了box和cls。
yolov5 head解码部分代码和对应结构图:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,3,20,20,85)
# self.no = nc + 5
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()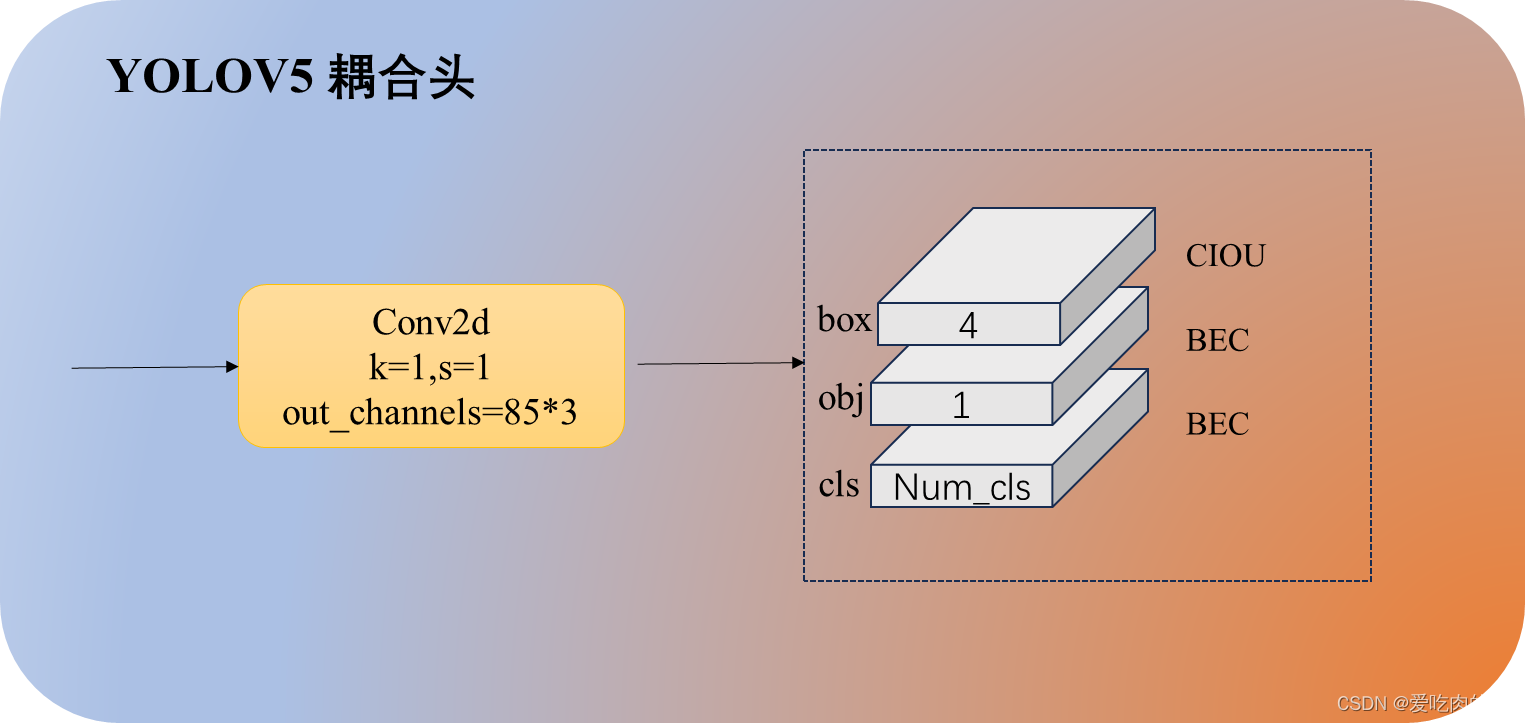
yolov8 head解码部分代码和对应结构图:
不过这里我有个疑问,就是看代码中引入的参数reg_max具体是什么?回归的最大数量?而且为什么设置为16,这样要是有懂的小伙伴可以解答一下。
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
# cv3最后一个卷积out_channels是类别的数量
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl): # self.nl=3
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)

另一方面,v8采用的是anchor-free,而yolov5是用的anchor-base。
训练部分
损失函数
分类回归
这里的分类回归损失函数采用的是VFL。这里的损失其实还是在BCE上面进行的改进,代码如下:
# 分类loss
class VarifocalLoss(nn.Module):
"""
Varifocal loss by Zhang et al.
https://arxiv.org/abs/2008.13367.
"""
def __init__(self):
"""Initialize the VarifocalLoss class."""
super().__init__()
@staticmethod
def forward(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
"""Computes varfocal loss."""
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction='none') *
weight).mean(1).sum()
return loss位置回归
位置回归采用ciou+dfl,代码如下:
# 位置回归loss
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max, use_dfl=False):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl样本匹配
在yolo的样本匹配中,v5之前是用iou进行样本匹配(不是计算loss),而在v5采用的anchor和gt的宽高比,以及样本的中心点落在哪个网络处来判断是否为正样本,以此实现样本匹配,然后才去计算各个loss(可以看我另一篇文章有详细讲解:yolov5损失函数讲解)
而在yolov8中采用TaskAlignedAssigner进行样本匹配。
持续更新。。。
参考资料
Yolov8的详解与实战- - 知乎
yolov8网络解析