源码基于:Android U
1. prop
| 名称 | 选项名称 | heap 变量名称 | 功能 |
|---|---|---|---|
| dalvik.vm.heapstartsize | MemoryInitialSize | initial_heap_size_ | 虚拟机在启动时,向系统申请的起始内存 |
| dalvik.vm.heapgrowthlimit | HeapGrowthLimit | growth_limit_ | 应用可使用的 max heap,超过这个值就会产生 OOM |
| dalvik.vm.heapsize | MemoryMaximumSize | capacity_ | 特殊应用的内存最大值,需要在应用manifest.xml 中设定: android:largeHeap="true" 此时,变量growth_limit_ 被重置为capacity_ 另外,对于CC 收集器RegionSpace 的内存是 capacity_ * 2 |
| dalvik.vm.foreground-heap-growth-multiplier | ForegroundHeapGrowthMultiplier | foreground_heap_growth_multiplier_ | low memry模式下,且没有定义该prop 时,该值为 1.0f 如果定义了该prop,最终在prop值的基础上 +1.0f |
| dalvik.vm.heapminfree | HeapMinFree | min_free_ | 单次堆内存调整的最小值,也是管理内存需要的最小空闲内存 |
| dalvik.vm.heapmaxfree | HeapMaxFree | max_free_ | 单次堆内存调整的最大值,也是管理内存需要的最大空闲内存 |
| dalvik.vm.heaptargetutilization | HeapTargetUtilization | target_utilization_ | 堆目标利用率 |
首先,对比 dalvik.vm.heapsize 和 dalvik.vm.heapgrowthlimit 两个属性,在 ActivityThread.java 中handleBindApplication() 函数中会根据 android:largeHeap 属性确定使用哪个值为 heap 最大值:
if ((data.appInfo.flags&ApplicationInfo.FLAG_LARGE_HEAP) != 0) {
dalvik.system.VMRuntime.getRuntime().clearGrowthLimit();
} else {
// Small heap, clamp to the current growth limit and let the heap release
// pages after the growth limit to the non growth limit capacity. b/18387825
dalvik.system.VMRuntime.getRuntime().clampGrowthLimit();
}后面四个值用来确保每次GC 之后,java 堆已经使用和空闲的内存有一个合适的比例,这样可以尽量地减少GC 的次数。
调整的方式按照如下的规则:
art/runtime/gc/heap.cc
void Heap::GrowForUtilization(collector::GarbageCollector* collector_ran,
size_t bytes_allocated_before_gc) {
...
if (gc_type != collector::kGcTypeSticky) {
// Grow the heap for non sticky GC.
uint64_t delta = bytes_allocated * (1.0 / GetTargetHeapUtilization() - 1.0);
DCHECK_LE(delta, std::numeric_limits<size_t>::max()) << "bytes_allocated=" << bytes_allocated
<< " target_utilization_=" << target_utilization_;
grow_bytes = std::min(delta, static_cast<uint64_t>(max_free_));
grow_bytes = std::max(grow_bytes, static_cast<uint64_t>(min_free_));
target_size = bytes_allocated + static_cast<uint64_t>(grow_bytes * multiplier);
next_gc_type_ = collector::kGcTypeSticky;
}
if (!ignore_target_footprint_) {
SetIdealFootprint(target_size);
...
}按照上面公式,假设 live_size=120M,target_utilization=0.75,max_free=8M,min_free=2M,那么:
delta =120M * (1/0.75 - 1)=40M
delta(40M) > max_free(8M)
target_size=120M + 8M = 128M,即堆的尺寸在此次 GC 之后调整到128M。
这个target_size 对应下文第 2.4 节中的 total_memory 值。对应的log 如下:
system_server: NativeAlloc concurrent copying GC freed 405107(20MB) AllocSpace objects, 238(4760KB) LOS objects, 33% free, 46MB/70MB, paused 83us,119us total 245.909ms
system_server: NativeAlloc concurrent copying GC freed 330013(15MB) AllocSpace objects, 67(1340KB) LOS objects, 33% free, 47MB/71MB, paused 94us,276us total 214.045ms
system_server: Background concurrent copying GC freed 302867(18MB) AllocSpace objects, 565(11MB) LOS objects, 32% free, 48MB/72MB, paused 588us,176us total 346.099ms
system_server: NativeAlloc concurrent copying GC freed 365830(18MB) AllocSpace objects, 254(5080KB) LOS objects, 33% free, 48MB/72MB, paused 143us,133us total 306.945ms
system_server: Background concurrent copying GC freed 235782(15MB) AllocSpace objects, 666(13MB) LOS objects, 33% free, 47MB/71MB, paused 83us,127us total 160.238ms上面计算的 target_size 是下次申请内存时是否需要 GC 的一个重要指标,下面结合场景理解。
场景一:
target_size=128M,live_size=120M,如果此时需要分配一个1M 内存对象?
管理的内存最大为8M,当请求分配 1M 内存是,可用内存 8 - 1 = 7M > min_free,所以此次申请无需GC,也不用调整 target_size。
场景二:
target_size=128M,live_size=120M,如果此时需要分配一个7M 内存对象?
管理的内存最大为8M,当请求分配 7M 内存是,可用内存 8 - 7 = 1M < min_free,所以此次申请需要GC,且调整 target_size。
场景三:
target_size=128M,live_size=120M,如果此时需要分配一个10M 内存对象?
管理的内存最大为8M,当请求分配 10M 内存是,已经超过了 8M 空间,先GC 并调整target_size,再次请求分配,如果还是失败,将 target_size 调整为最大,再次请求分配,失败就再 GC一次软引用,再次请求,还是失败那就是OOM,成功后要调整 target_size。
所以,Android在申请内存的时候,可能先分配,也可能先GC,也可能不GC,这里面最关键的点就是内存利用率跟Free内存的上下限。
2. GC log
system_server: Background concurrent copying GC freed 82590(11MB) AllocSpace objects, 1139(22MB) LOS objects, 31% free, 52MB/76MB, paused 326us,284us total 302.779ms
.mobile.service: Background young concurrent copying GC freed 185026(5214KB) AllocSpace objects, 60(7396KB) LOS objects, 59% free, 7072KB/17MB, paused 26.144ms,21us total 40.78这里以 system_server 的 GC log 为例。
2.1 字段Background
这里展示是触发 GC 的原因,所有 GC 的原因都被记录在 gc_cause.h 中:
art/runtime/gc/gc_cause.h
enum GcCause {
kGcCauseNone,
kGcCauseForAlloc,
kGcCauseBackground,
kGcCauseExplicit,
kGcCauseForNativeAlloc,
...
};| index | name | 备注 |
|---|---|---|
| kGcCauseNone | None | 无效类型,用于占位 |
| kGcCauseForAlloc | Alloc | 分配失败时触发GC,分配会被block,直到GC 完成 通过new 分配新对象时,如果heap size 超过max,需要先GC |
| kGcCauseBackground | Background | 后台GC 这里的“后台”并不是指应用切到后台才会执行的GC,而是GC在运行时基本不会影响其他线程的执行,所以也可以理解为并发GC。在每一次成功分配Java对象后,都会去检测是否需要进行下一次GC,这就是GcCauseBackground GC的触发时机。触发的条件需要满足一个判断,如果new_num_bytes_allocated(所有已分配的字节数,包括此次新分配的对象) >= concurrent_start_bytes_(下一次GC触发的阈值),那么就请求一次新的GC。 |
| kGcCauseExplicit | Explicit | 显示调用 System.gc() 触发的 GC |
| kGcCauseForNativeAlloc | NativeAlloc | 当native 分配,出现内存紧张时触发GC 需要确认 native + java 的权重是否超过了总的heap size |
2.2 字段 concurrent
这里展示的是 GC 的收集器名称,代表不同 GC 算法。所有GC 收集器定义在 collector_type.h 中:
art/runtime/gc/collector_type.h
enum CollectorType {
kCollectorTypeNone,
kCollectorTypeMS,
kCollectorTypeCMS,
kCollectorTypeCMC,
kCollectorTypeSS,
kCollectorTypeHeapTrim,
kCollectorTypeCC,
...
};| index | 收集器名称 | 功能 |
|---|---|---|
| kCollectorTypeMS | mark sweep | 标记清除算法由标记阶段和清除阶段构成。 mark 阶段是把所有活动对象都做上标记,sweep 阶段是把那些没有标记的对象也就是非活动的对象进行回收的过程。通过这两个阶段,可以使用不用利用的内存空间重新得到利用。 |
| kCollectorTypeCMS | concurrent mark sweep | 并发的MS |
| kCollectorTypeCMC | concurrent mark compact | 标记整理算法是将标记清除算法和复制算法相结合的产物。标记整理算法由标记阶段和压缩阶段构成。 mark 阶段是把所有活动对象都做上标记,compact 阶段通过数次搜索堆来重新装填活动对象。因 compact 而产生的优点是不用牺牲半个堆。 |
| kCollectorTypeSS | semispace | 综合了semi-space和mark-sweep,同时还支持compact |
| kCollectorTypeCC | concurrent copying | 是对mark sweep 而导致内存碎片化的一个解决方案。 算法利用From 空间进行分配。当From 空间被完全占满时,GC 会将活动对象全部复制到To 空间。当复制完成后,该算法会把From 空间和To 空间互换,GC 也就结束了。From 空间和To 空间大小必须一致。这是为了保证能把From 空间中的所有活动对象都收纳到To 空间里。 |
2.3 GC freed 字段
GC freed 会统计两个数据:
-
AllocSpace objects,这里展示的是此次 GC 回收的非 LOS 的字节数;
-
LOS objects,这里展示的是此次 GC 回收的 LOS 的字节数;
2.4 31% free, 52MB/76MB 字段
这里展示当前进程在此次 GC 之后的内存情况。
这里记录已经分配的总内存(记作 current_heap_size) 和已经分配内存的最大值 (记作 total_memory,这个值不会超过最大值)。
52 M 就是 current_heap_size,76M 就是total_memory。
free 百分比 = (total_memory - current_heap_size) / total_memory
2.5 paused 字段
这里展示当前进程在此次GC 中应用挂起的时间以及次数。
每次挂起的时间都会打印出来,中间用逗号分隔。
2.6 total 字段
这里展示当前进程在此次 GC 中完成所需要的时间,其中包括 paused 时间。
2.7 源码
源码于 art/runtime/gc/heap.cc
art/runtime/gc/heap.cc
void Heap::LogGC(GcCause gc_cause, collector::GarbageCollector* collector) {
...
LOG(INFO) << gc_cause << " " << collector->GetName()
<< (is_sampled ? " (sampled)" : "")
<< " GC freed " << current_gc_iteration_.GetFreedObjects() << "("
<< PrettySize(current_gc_iteration_.GetFreedBytes()) << ") AllocSpace objects, "
<< current_gc_iteration_.GetFreedLargeObjects() << "("
<< PrettySize(current_gc_iteration_.GetFreedLargeObjectBytes()) << ") LOS objects, "
<< percent_free << "% free, " << PrettySize(current_heap_size) << "/"
<< PrettySize(total_memory) << ", " << "paused " << pause_string.str()
<< " total " << PrettyDuration((duration / 1000) * 1000);
...
}3. 收集机制简介
Heap 类提供了三种GC 接口:
-
CollectGarbage(),用来执行显示GC,例如 system.gc() 接口;
-
ConcurrentGC(),用来执行并行GC,只能被 ART 运行时内部的GC 守护线程调用;
-
CollectGarbageInternal(),ART运行时内部调用的GC 接口,可以执行各种类型的GC;
ART runtime 将空间划分:Image Space、Malloc Space、Zygote Space、Bump Pointer Space、Region Space、Large Object Space。
art/runtime/gc/space/space.h
enum SpaceType {
kSpaceTypeImageSpace,
kSpaceTypeMallocSpace,
kSpaceTypeZygoteSpace,
kSpaceTypeBumpPointerSpace,
kSpaceTypeLargeObjectSpace,
kSpaceTypeRegionSpace,
};其中前面都是在地址空间上连续的,即 Continuous Space,而 Large Object Space 是一些离散地址的集合,用来分配一些大对象,称为Discontinuous Space。
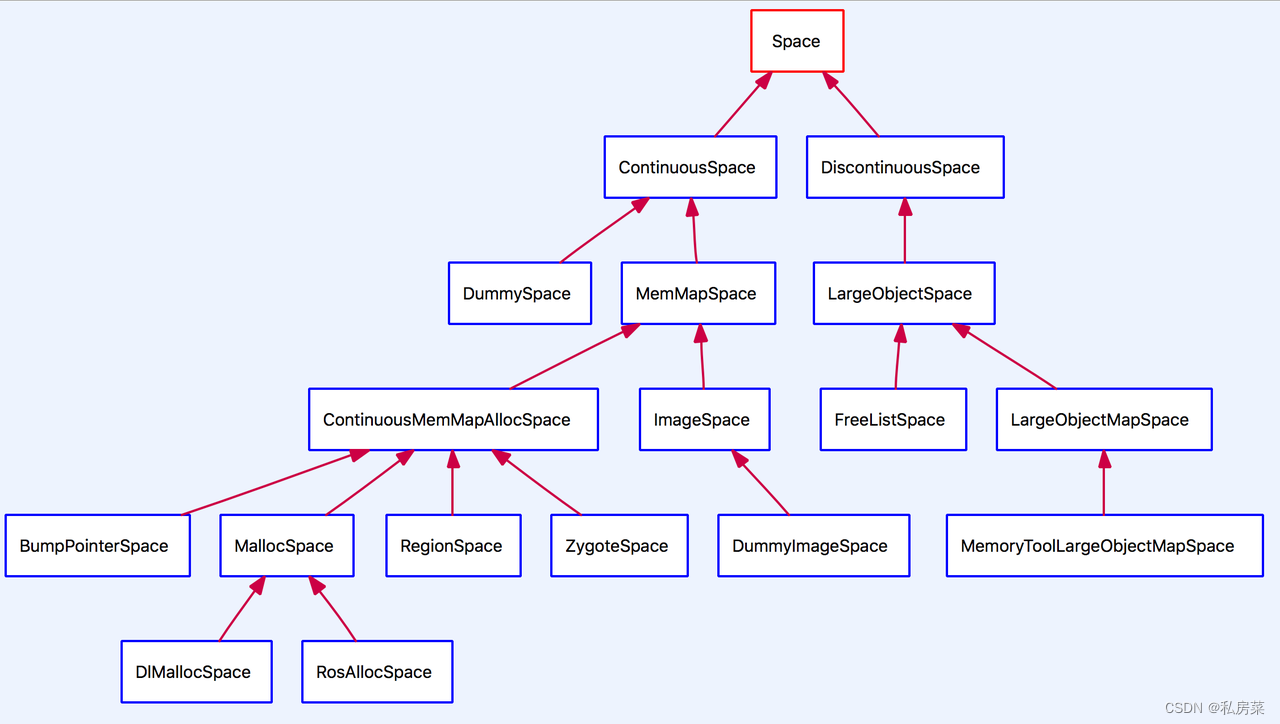
原先Davlik虚拟机使用的是传统的 dlmalloc 内存分配器进行内存分配。这个内存分配器是Linux上很常用的,但是它没有为多线程环境做过优化,因此Google为ART虚拟机开发了一个新的内存分配器:RoSalloc,它的全称是Rows of Slots allocator。RoSalloc相较于dlmalloc来说,在多线程环境下有更好的支持:在dlmalloc中,分配内存时使用了全局的内存锁,这就很容易造成性能不佳。而在RoSalloc中,允许在线程本地区域存储小对象,这就是避免了全局锁的等待时间。ART虚拟机中,这两种内存分配器都有使用。
Heap 类的 Heap::AllocObject是为对象分配内存的入口,如下:
art/runtime/gc/heap.h
template <bool kInstrumented = true, typename PreFenceVisitor>
mirror::Object* AllocObject(Thread* self,
ObjPtr<mirror::Class> klass,
size_t num_bytes,
const PreFenceVisitor& pre_fence_visitor)
REQUIRES_SHARED(Locks::mutator_lock_)
REQUIRES(!*gc_complete_lock_,
!*pending_task_lock_,
!*backtrace_lock_,
!process_state_update_lock_,
!Roles::uninterruptible_) {
//AllocObjectWithAllocator() 实现在 heap-inl.h 中
return AllocObjectWithAllocator<kInstrumented>(self,
klass,
num_bytes,
GetCurrentAllocator(),
pre_fence_visitor);
}会首先通过 Heap::TryToAllocate尝试进行内存的分配。在 Heap::TryToAllocate方法,会根据AllocatorType,选择不同的Space进行内存的分配。在 Heap::TryToAllocate 方法失败时,会调用 Heap::AllocateInternalWithGc 进行 GC,然后在尝试内存的分配。
参考:
https://developer.aliyun.com/article/652546#slide-5