本文来源公众号“DeepDriving”,仅用于学术分享,侵权删,干货满满。
原文链接:CUDA编程-03:线程层级
DeepDriving | CUDA编程-01: 搭建CUDA编程环境-CSDN博客
DeepDriving | CUDA编程-02: 初识CUDA编程-CSDN博客
1 GPU架构概述
英伟达GPU的架构是围绕一个流式多处理器(Streaming Multiprocessors,SM)的可扩展阵列构建的,通过复制这种架构的构建来实现GPU的硬件并行。一个典型的SM包括以下几个组件:
-
核心
-
共享内存/一级缓存
-
寄存器文件
-
加载/存储单元
-
特殊功能单元
-
线程束调度器

一个GPU中通常有多个SM,每个SM上支持许多个线程并发地执行,CUDA采用单指令多线程(Single-Instruction Multiple-Thread,SIMT)来管理和执行GPU上的众多线程,并提出一个两级的线程层级结构的概念以便组织线程。由一个内核启动所产生的所有线程统称为一个线程网格,同一网格中的所有线程共享全局内存空间,一个网格由多个线程块组成,一个线程块包含一组线程,同一线程块内的线程通过同步和共享内存的方式实现协作,不同块内的线程不能协作。当host通过内核函数启动一个内核网格时,这个内核网格的线程块就被分配到可用的SM上来执行,一个线程块内的多个线程在SM上并发执行,多个线程块可以并发地在一个SM上执行,当线程块终止时,新的线程块又可以在腾出的SM上启动执行。
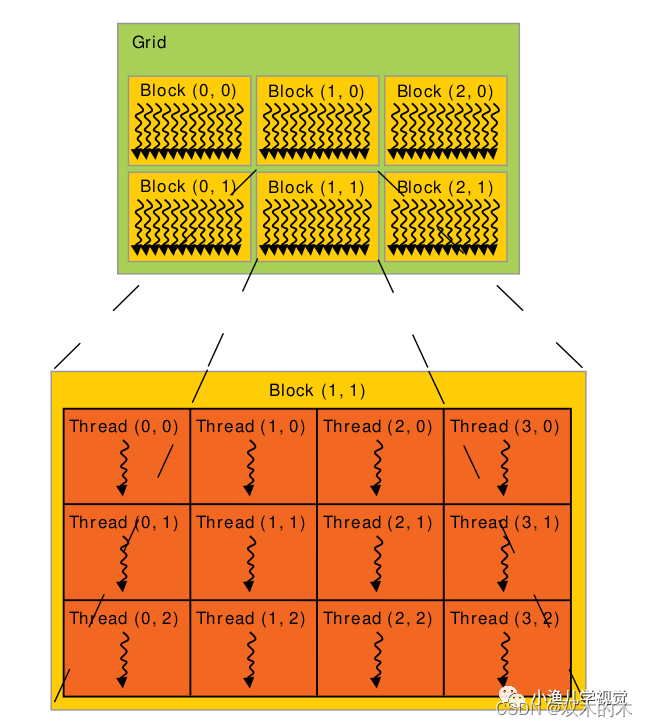
2 线程
线程是并行程序的基础,并行化的方式一般有两种:任务并行和数据并行。任务并行是将一个计算任务分解为几个子任务,通过不同的线程分别执行各个子任务,最后汇总结果;数据并行是将一个总任务在数据粒度上进行划分,然后每个线程处理一份数据,每个线程上执行的计算任务是一样的。
举个搬砖的例子:
假设我们的任务是将100个砖从A点搬到B点,搬砖的任务分为3个子任务:把砖从A点装车、从A点运送到B点、在B点把砖从车上卸下来。如果采用任务并行方式,那么可以请多个工人,然后把他们分为3个组,每个组负责一个子任务 ;如果是采用数据并行,那么可以请100个工人,每个人负责1个砖,每个人的任务都是把砖从A点搬到B点。
GPU采用数据并行的模式,它可以运行成千上万的线程用于运行大量逻辑比较简单的计算任务以实现高效的并行化计算。在上一篇文章中,我介绍了一个数组相加的例子,本文继续以这个例子来介绍GPU中以多线程实现并行化的方式。
先来看一下CPU实现数组相加的方式:
void VectorAddCPU(const float *const a, const float *const b, float *const c,
const int n) {
for (int i = 0; i < n; ++i) {
c[i] = a[i] + b[i];
}
}
CPU的代码默认是单线程执行模式,要想实现含多个数据的数组相加任务,就必须以循环的方式实现(相当于一个人要把所有的砖搬完)。
再来看GPU的实现方式:
__global__ void VectorAddGPU(const float *const a, const float *const b,
float *const c, const int n) {
int i = blockDim.x * blockIdx.x + threadIdx.x; // 线程ID
if (i < n) {
c[i] = a[i] + b[i]; //每个线程需要做的事情
}
}
可以看到,GPU代码中并不需要循环,只是需要一个线程ID来进行索引,并告诉每个线程需要做的事情。线程依靠两个内置变量来进行区分:
-
blockIdx: 线程块在线程网格中的索引 -
threadIdx: 线程块内的线程索引
这两个CUDA内置变量是基于uint3定义的向量类型,是一个包含x,y,z三个无符号整数字段的结构。
在调用内核函数的时候,会在<<< >>>内设置两个参数,分别代表线程网格的维度和线程块的维度。CUDA可以组织三维的线程网格和线程块,它们的维度由下列两个内置变量来决定:
-
blockDim: 线程块的维度,用每个线程块中的线程数量来表示 -
gridDim: 线程网格的维度,用每个线程网格中的线程块数量来表示
它们是基于uint3定义的dim3结构类型的变量,用于表示维度,每个维度可通过x,y,z字段获得,未被初始化的字段会被初始化为1且忽略不计。通常情况下,一个线程网格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。
const size_t size = 1024;
dim3 thread_per_block(256);
dim3 block_per_grid((size + thread_per_block.x - 1) / thread_per_block.x);
printf("thread_per_block: %d, block_per_grid: %d \n", thread_per_block.x,
block_per_grid.x);
VectorAddGPU<<<block_per_grid, thread_per_block>>>(da, db, dc, size);
在上面的例子中,我只初始化了线程网格和线程块的第一维x,相当于设定线程网格中的线程块是以一维的形式排列,每个线程块中的线程也是以一维的形式排列,在内核函数中每个线程的ID可以这样得到:
const unsigned int id = blockDim.x * blockIdx.x + threadIdx.x;
我们可以在内核函数中打印gridDim,blockDim,blockIdx,threadIdx这些信息看一下:
......
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(29 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(30 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(31 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(0 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(1 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(2 0 0)
......
把thread_per_block设置为512再看一下:
......
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(93 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(94 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(95 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(416 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(417 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(418 0 0)
......
可以看到,启动内核函数的时候在<<< >>>内设置不同的执行参数,内核中线程的布局是不一样的。
3 线程束
CUDA采用SIMT架构来管理和执行线程,将线程块中的线程每32个(记住这个神奇的数字)为一组进行划分,每一组被称为一个线程束(warp)。线程束的大小warpSize是CUDA中的一个内部属性,可以通过以下方式获得:
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("warpSize: %d\n", prop.warpSize);
线程束是GPU的基本执行单元,当线程网格启动后,网格中的线程块被分配到SM中执行,一旦线程块被调度到一个SM上,线程块中的线程就会被进一步划分为线程束,每个线程束中的所有线程执行相同的命令,每个线程拥有自己的指令地址计数器和寄存器状态,利用自己的私有数据执行当前的指令。线程块的逻辑视图和硬件视图之间的关系如下:
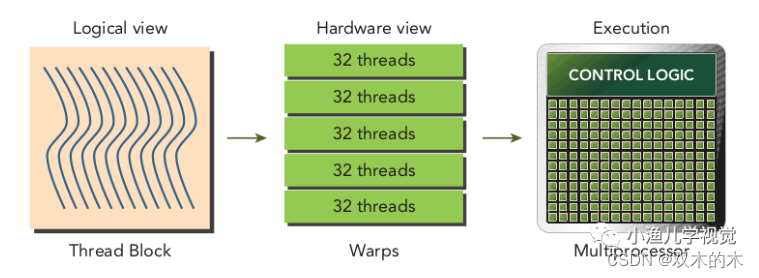
从逻辑角度看,线程块是线程的集合,它们可以被组织成一维、二维或者三维的布局形式;从硬件角度来看,线程块是一维线程束的集合,线程块中的线程被组织成一维布局,每32个连续的线程组成了一个线程束。
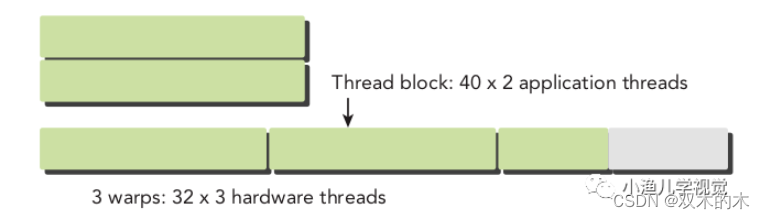
由于在硬件上线程块中的线程会被划分为线程束,而线程束不会在不同线程块之间分离,也就是说同一个线程束中的线程不会同属于两个线程块。如果线程块的大小不是线程束大小的偶数倍,那么最后一个线程束里就会有些线程没有用,但是它们依然会消耗SM的资源,所以在设置线程块大小的时候,最好设置为32的倍数。下图展示了一个线程块中包含80个线程时的情况,硬件为这些线程分配了3个线程束,最后一个线程束中有些线程是没有用的。
4 线程块
对于一份给定的数据,确定网格和块的维度的一般步骤为:
-
确定块的维度大小;
-
在已知数据大小和块大小的基础上计算网格的维度。
如何确定一个块的维度大小,通常需要考虑内核的性能特性和GPU的资源限制,比如寄存器和共享内存的大小,使用合适的网格和块大小来组织线程可以对内核性能产生较大的影响。在程序中,应该尽量避免使用小的线程块,因为这样无法充分利用硬件资源。为了防止不合理的内存合并,我们需要尽量做到数据内存的分布与线程的分布达到一一映射的关系。CUDA的设计思想是将数据分解到并行的线程和线程块中,使得程序结构与内存数据的分布能够建立一一映射的关系。假如我们需要计算二维数组的相加,那么可以将线程网格和线程块划分为二维:

这种情况下计算线程的ID会稍微复杂一点,首先计算当前的行索引,然后乘以每一行的线程总数,最后加上X轴方向上的偏移,这样就能计算出线程相对于整个线程网格的绝对线程索引:
const unsigned int idx = blockDim.x * blockIdx.x + threadIdx.x;
const unsigned int idy = blockDim.y * blockIdx.y + threadIdx.y;
const unsigned int thread_id = (gridDim.x * blockDim.x) * idy + idx;
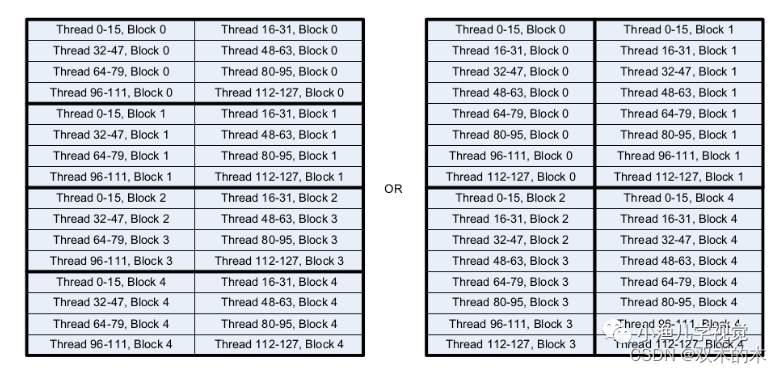
当然,二维线程块的布局方式也有多种,比如下面这两种,它们的线程总数是一样的,但左图的布局要比右图的更高效。因为无论是在CPU还是在GPU中都是以行的方式进行内存访问,以右图的布局方式,同一行的数据需要被2个线程块访问2次,而左图的布局同一行的数据只需要访问1次即可。
5 参考资料
-
《
Professional CUDA C Programming》 -
《
CUDA C Programming Guide》 -
《
CUDA Programming:A Developer's Guide to Parallel Computing with GPUs》
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。