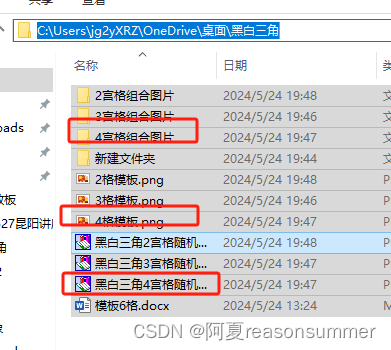
背景需求:
【教学类-58-01】黑白三角拼图01(2*2宫格)256种-CSDN博客文章浏览阅读318次,点赞10次,收藏12次。【教学类-58-01】黑白三角拼图01(2*2宫格)256种https://blog.csdn.net/reasonsummer/article/details/139173885
【教学类-58-02】黑白三角拼图02(3*3宫格)262144种-CSDN博客文章浏览阅读136次,点赞7次,收藏7次。【教学类-58-02】黑白三角拼图02(3*3宫格)262144种 https://blog.csdn.net/reasonsummer/article/details/139176570?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139176570%22%2C%22source%22%3A%22reasonsummer%22%7D
https://blog.csdn.net/reasonsummer/article/details/139176570?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139176570%22%2C%22source%22%3A%22reasonsummer%22%7D
我尝试过2*2是256,3*3是262114, 想制作 4*4。
4*4的的排列方式太多了,程序内存不够计算。出现MomeryError,只能放弃。
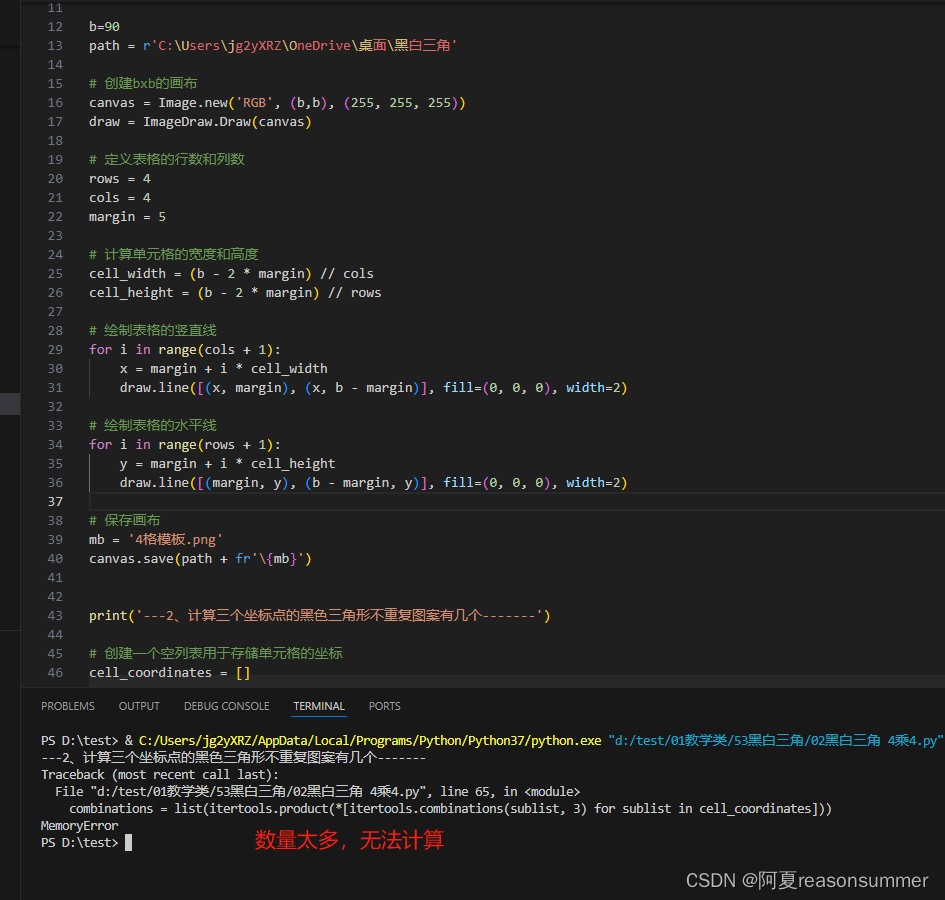
代码(内存不够计算)
'''
黑白三角(4*4), 16个单元格每个有四个坐标,四个坐标随机抽取3个,进行组合,共有262144种不重复排序,带边距
因为有26万种,所以把图片做的90,但是太多了,无法计算
像素小一点 生成时间15:34-16:02
AI对话大师,阿夏
2024年5月24日
'''
from PIL import Image, ImageDraw
b=90
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\黑白三角'
# 创建bxb的画布
canvas = Image.new('RGB', (b,b), (255, 255, 255))
draw = ImageDraw.Draw(canvas)
# 定义表格的行数和列数
rows = 4
cols = 4
margin = 5
# 计算单元格的宽度和高度
cell_width = (b - 2 * margin) // cols
cell_height = (b - 2 * margin) // rows
# 绘制表格的竖直线
for i in range(cols + 1):
x = margin + i * cell_width
draw.line([(x, margin), (x, b - margin)], fill=(0, 0, 0), width=2)
# 绘制表格的水平线
for i in range(rows + 1):
y = margin + i * cell_height
draw.line([(margin, y), (b - margin, y)], fill=(0, 0, 0), width=2)
# 保存画布
mb = '4格模板.png'
canvas.save(path + fr'\{mb}')
print('---2、计算三个坐标点的黑色三角形不重复图案有几个-------')
# 创建一个空列表用于存储单元格的坐标
cell_coordinates = []
# 计算每个单元格的四个顶点坐标
for row in range(rows):
for col in range(cols):
top_left = (margin + col * cell_width, margin + row * cell_height)
top_right = (margin + (col + 1) * cell_width, margin + row * cell_height)
bottom_left = (margin + col * cell_width, margin + (row + 1) * cell_height)
bottom_right = (margin + (col + 1) * cell_width, margin + (row + 1) * cell_height)
# 将四个顶点坐标添加到列表中
cell_coordinates.append([top_left, top_right, bottom_left, bottom_right])
# print(cell_coordinates)
# [[(0, 0), (400, 0), (0, 400), (400, 400)], [(400, 0), (b, 0), (400, 400), (b, 400)], [(0, 400), (400, 400), (0, b), (400, b)], [(400, 400), (b, 400), (400, b), (b, b)]]
import itertools,os
# 生成所有组合方式
combinations = list(itertools.product(*[itertools.combinations(sublist, 3) for sublist in cell_coordinates]))
# print(combinations)
print(len(combinations))
# 262144
print('---3、制作三个坐标点的黑色三角形(4个)-------')
from PIL import Image, ImageDraw
new=path+r'\四宫格组合图片'
os.makedirs(new,exist_ok=True)
m=1
# 定义要绘制的坐标点组合
for point_combination in combinations:
# 读取图像文件
image = Image.open(path+fr'\{mb}')
# 创建绘图对象
draw = ImageDraw.Draw(image)
# 遍历每个坐标点组合
for combination in point_combination:
# 绘制填充为黑色的多边形
draw.polygon(combination, fill="black")
# 保存结果图像
image.save(new+fr"\{m:06d}.png")
m+=1
# print('---4合并打印-26万张就不生成卡片了------')
# # 第3步,读取图片写入docx,合并PDF
# import os,time
# from docx import Document
# from reportlab.lib.pagesizes import letter
# from reportlab.pdfgen import canvas
# from PyPDF2 import PdfMerger
# from docx.shared import Cm
# # 读取123文件夹中的所有图片地址
# image_folder = new
# new_folder = path+r'\零时文件夹'
# os.makedirs(new_folder, exist_ok=True)
# image_files = [os.path.join(image_folder, file) for file in os.listdir(image_folder) if file.endswith('.png')]
# # 每8个图片一组进行处理
# grouped_files = [image_files[i:i+6] for i in range(0, len(image_files), 6)]
# print(grouped_files)
# # 处理每一组图片
# for group_index, group in enumerate(grouped_files):
# # 创建新的Word文档
# doc = Document(path+r'\模板6格.docx')
# print(group)
# # 遍历每个单元格,并插入图片
# for cell_index, image_file in enumerate(group):
# # 计算图片长宽(单位:厘米)
# # 插入图片到单元格
# table = doc.tables[0]
# cell = table.cell(int(cell_index / 2), cell_index % 2)
# # 6列两个都是6
# cell_paragraph = cell.paragraphs[0]
# cell_paragraph.clear()
# run = cell_paragraph.add_run()
# run.add_picture(image_file, width=Cm(9.4), height=Cm(9.4))
# # 保存Word文档
# doc.save(os.path.join(new_folder, f'{group_index + 1}.docx'))
# # 所有docx合并成PDF
# # 将10个docx转为PDF
# import os
# from docx2pdf import convert
# from PyPDF2 import PdfFileMerger
# # from PyPDF4 import PdfMerger
# # output_folder = output_folder
# pdf_output_path = path+fr'\黑白三角三宫格26万(6张一页).pdf'
# # 将所有DOCX文件转换为PDF
# for docx_file in os.listdir(new_folder):
# if docx_file.endswith('.docx'):
# docx_path = os.path.join(new_folder, docx_file)
# convert(docx_path, docx_path.replace('.docx', '.pdf'))
# # 合并零时文件里所有PDF文件
# merger = PdfFileMerger()
# for pdf_file in os.listdir(new_folder):
# if pdf_file.endswith('.pdf'):
# pdf_path = os.path.join(new_folder, pdf_file)
# merger.append(pdf_path)
# time.sleep(2)
# # 保存合并后的PDF文件
# merger.write(pdf_output_path)
# merger.close()
# import shutil
# # 删除输出文件夹
# shutil.rmtree(new_folder)
因此需要我想随机抽取10张4*4的图片,但要保证随机抽的图案不能相同)
'''
黑白三角(4*4), 16个单元格每个有四个坐标,四个坐标随机抽取3个,进行组合,自动抽取10张,带边距
随机图片
AI对话大师,阿夏
2024年5月24日
'''
from PIL import Image, ImageDraw
f=10 # 需要10份
b=800 # 画布大小
g=4 # 宫格数
by=50 # 边距
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\黑白三角'
# 创建bxb的画布
canvas = Image.new('RGB', (b,b), (255, 255, 255))
draw = ImageDraw.Draw(canvas)
# 定义表格的行数和列数、边距
rows = g
cols = g
margin = by
# 计算单元格的宽度和高度
cell_width = (b - 2 * margin) // cols
cell_height = (b - 2 * margin) // rows
# 绘制表格的竖直线
for i in range(cols + 1):
x = margin + i * cell_width
draw.line([(x, margin), (x, b - margin)], fill=(0, 0, 0), width=2)
# 绘制表格的水平线
for i in range(rows + 1):
y = margin + i * cell_height
draw.line([(margin, y), (b - margin, y)], fill=(0, 0, 0), width=2)
# 保存画布
mb =f'{g}格模板.png'
canvas.save(path + fr'\{mb}')
print('---2、计算三个坐标点的黑色三角形不重复图案有几个-------')
# 创建一个空列表用于存储单元格的坐标
cell_coordinates = []
# 计算每个单元格的四个顶点坐标
for row in range(rows):
for col in range(cols):
top_left = (margin + col * cell_width, margin + row * cell_height)
top_right = (margin + (col + 1) * cell_width, margin + row * cell_height)
bottom_left = (margin + col * cell_width, margin + (row + 1) * cell_height)
bottom_right = (margin + (col + 1) * cell_width, margin + (row + 1) * cell_height)
# 将四个顶点坐标添加到列表中
cell_coordinates.append([top_left, top_right, bottom_left, bottom_right])
# print(cell_coordinates)
# print(len(cell_coordinates))
# 16
# [[(0, 0), (400, 0), (0, 400), (400, 400)], [(400, 0), (b, 0), (400, 400), (b, 400)], [(0, 400), (400, 400), (0, b), (400, b)], [(400, 400), (b, 400), (400, b), (b, b)]]
import random
import os
combinations=[]
# 存储选取的点,随机生成坐标(样式)排除重复,生成10份样式不同的模版
while len(combinations) < f:
selected_points = []
for points in cell_coordinates:
selected_points.append(tuple(random.sample(points, 3)))
combinations.append(tuple(selected_points))
print(combinations)
print(len(combinations))
# 10
# # 生成所有组合方式,太多了,生成不出来
# combinations = lisitertools.product(*[itertools.combinations(sublist, 3) for sublist in cell_coordinates]))
# # print(combinations)
# print(len(combinations))
# # 262144
print('---3、制作三个坐标点的黑色三角形(4个)-------')
from PIL import Image, ImageDraw
new = path + fr'\{g}宫格组合图片'
os.makedirs(new, exist_ok=True)
m = 1
# 定义要绘制的坐标点组合
for point_combination in combinations:
print(point_combination)
# 清空selected_points列表
selected_points = []
# 遍历每个坐标点组合
for combination in point_combination:
# 从每个列表中随机选取三个点,并加入到selected_points中
selected_points.append(tuple(random.sample(combination, 3)))
# 读取图像文件
image = Image.open(path + fr'\{mb}')
# 创建绘图对象
draw = ImageDraw.Draw(image)
# 遍历每个坐标点组合
for combination in selected_points:
# 绘制填充为黑色的多边形
draw.polygon(combination, fill="black")
# 保存结果图像
image.save(new + fr"\{m:03d}.png")
image.close() # 关闭图像文件
m += 1
print('---4合并打印------')
# 第3步,读取图片写入docx,合并PDF
import os,time
from docx import Document
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from PyPDF2 import PdfMerger
from docx.shared import Cm
# 读取123文件夹中的所有图片地址
image_folder = new
new_folder = path+r'\零时文件夹'
os.makedirs(new_folder, exist_ok=True)
image_files = [os.path.join(image_folder, file) for file in os.listdir(image_folder) if file.endswith('.png')]
# 每8个图片一组进行处理
grouped_files = [image_files[i:i+6] for i in range(0, len(image_files), 6)]
print(grouped_files)
# 处理每一组图片
for group_index, group in enumerate(grouped_files):
# 创建新的Word文档
doc = Document(path+r'\模板6格.docx')
print(group)
# 遍历每个单元格,并插入图片
for cell_index, image_file in enumerate(group):
# 计算图片长宽(单位:厘米)
# 插入图片到单元格
table = doc.tables[0]
cell = table.cell(int(cell_index / 2), cell_index % 2)
# 6列两个都是6
cell_paragraph = cell.paragraphs[0]
cell_paragraph.clear()
run = cell_paragraph.add_run()
run.add_picture(image_file, width=Cm(9.4), height=Cm(9.4))
# 保存Word文档
doc.save(os.path.join(new_folder, f'{group_index + 1}.docx'))
# 所有docx合并成PDF
# 将10个docx转为PDF
import os
from docx2pdf import convert
from PyPDF2 import PdfFileMerger
# from PyPDF4 import PdfMerger
# output_folder = output_folder
pdf_output_path = path+fr'\黑白三角{g}宫格随机{f}张(6张一页).pdf'
# 将所有DOCX文件转换为PDF
for docx_file in os.listdir(new_folder):
if docx_file.endswith('.docx'):
docx_path = os.path.join(new_folder, docx_file)
convert(docx_path, docx_path.replace('.docx', '.pdf'))
# 合并零时文件里所有PDF文件
merger = PdfFileMerger()
for pdf_file in os.listdir(new_folder):
if pdf_file.endswith('.pdf'):
pdf_path = os.path.join(new_folder, pdf_file)
merger.append(pdf_path)
time.sleep(2)
# 保存合并后的PDF文件
merger.write(pdf_output_path)
merger.close()
import shutil
# 删除输出文件夹
shutil.rmtree(new_folder)