title: PE文件学习篇
tags:
- Windows
- PE
最近在准备面试相的内容,对pe相关的问题有些生疏了,于是就边看博客复习边整理到论坛上希望对大家有帮助。
在《逆向工程核心原理》这本书接触到了PE文件,但是当时学不进去,感觉很晦涩,虽然是一个结构体一个结构体的进行分析,但还是掌握不了。今天在YouTube上找到了一个视频,看了一下有种恍然大明白的感觉。正巧今天看了一期关于国产大飞机C919的视频很有感想,我们的策略是先整体后局部,即不过分死抠细节,不把国产化率排在首位,先造出来一个大飞机,于是我们就有了一张蓝图,知道方向在哪里。学习PE文件这里也是,先整体的过一遍,知道个轮廓,在学起来会容易和有趣不少。
PE基础
PE文件概念
PE文件(Portable Executable file),是一种可执行文件格式,满足此格式的文件都可以在Windows操作系统运行。在Linux系统运行的文件是ELF。
识别PE文件
通过后缀名判断文件格式是不靠谱的,因为后缀名是可以随意更改的,我们用一个十六进制编辑器打开一个文件,如果他的开头是MZ,且0x3c--0x3f所指示的偏移地址处的值是PE那么我们几乎可以肯定这是个PE文件。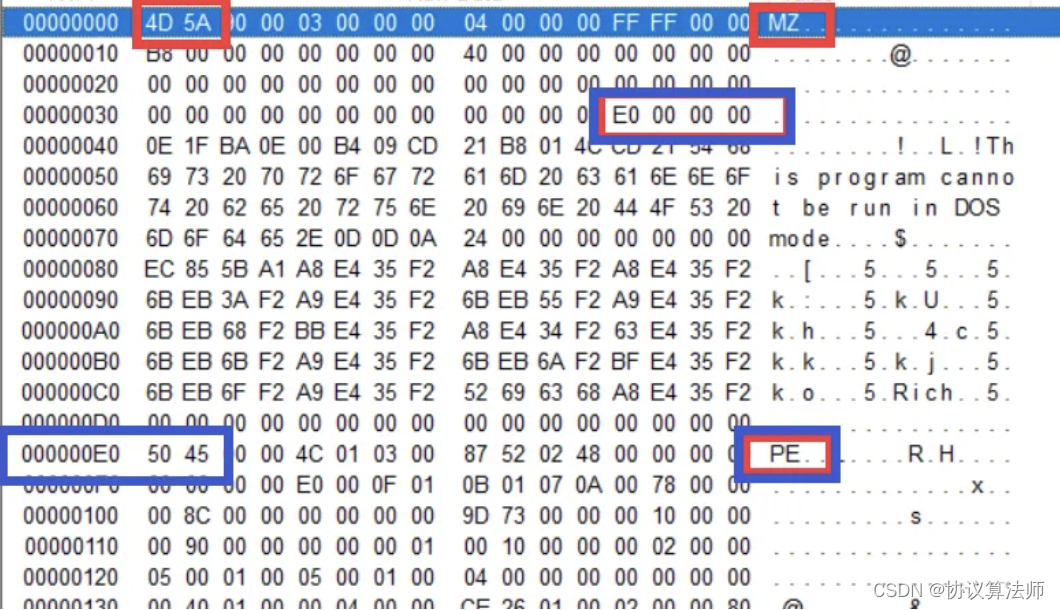
PE文件格式
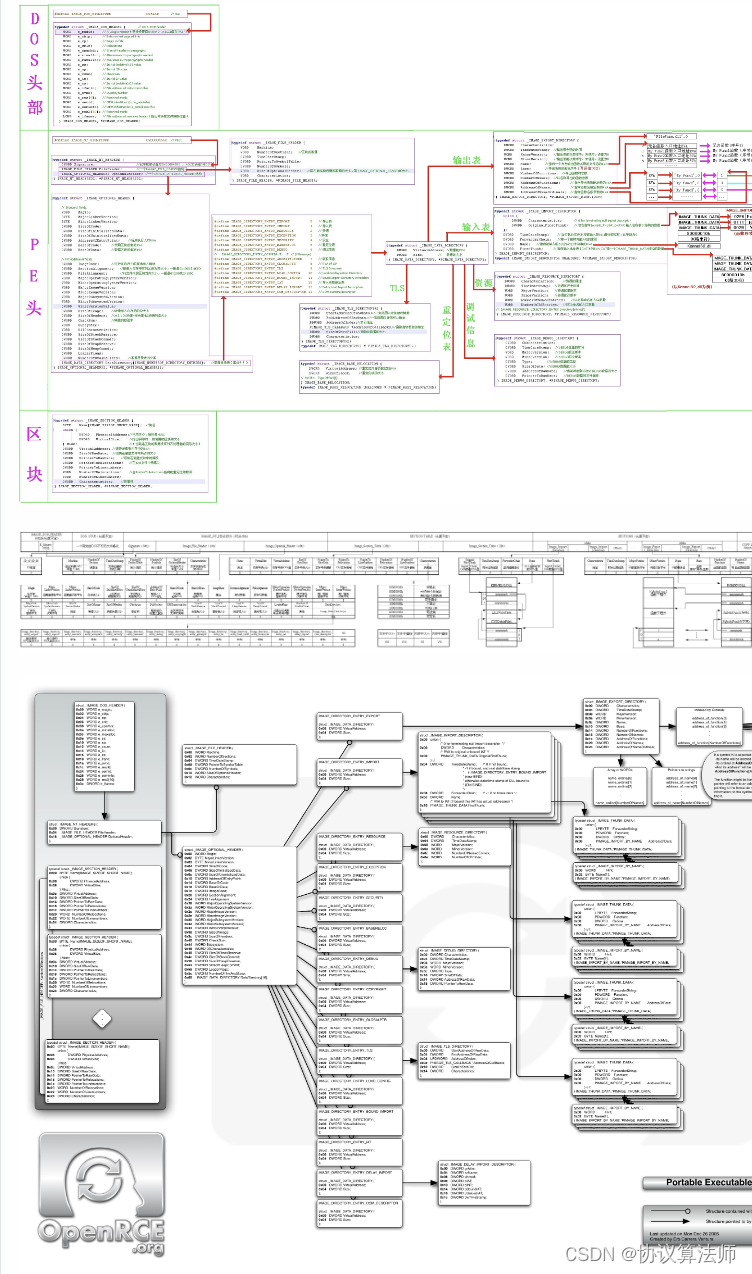
从DOS头到节区头是PE头部分,其下的节区合成PE体。
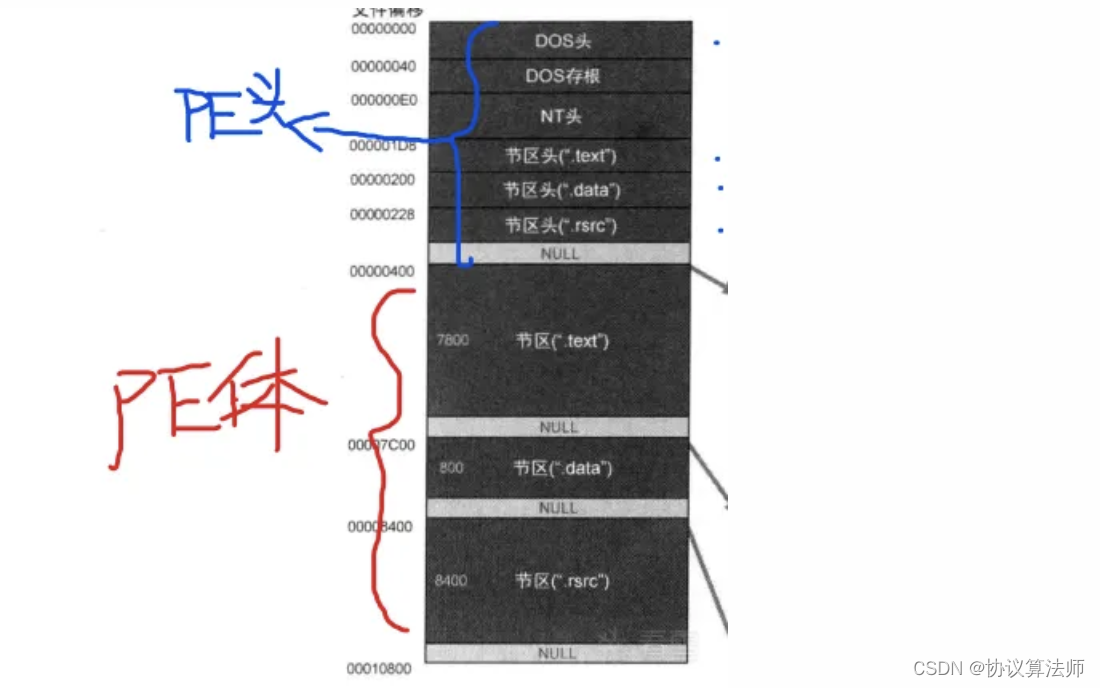

 我们学习PE文件就是学习这些结构体,先对结构体来个介绍。我们可以通过PEView查看pe文件,将notepad.exe拖入。我们先来分析一下存储时的PE文件,没错PE文件运行时和在硬盘中存储时是不同的。
我们学习PE文件就是学习这些结构体,先对结构体来个介绍。我们可以通过PEView查看pe文件,将notepad.exe拖入。我们先来分析一下存储时的PE文件,没错PE文件运行时和在硬盘中存储时是不同的。
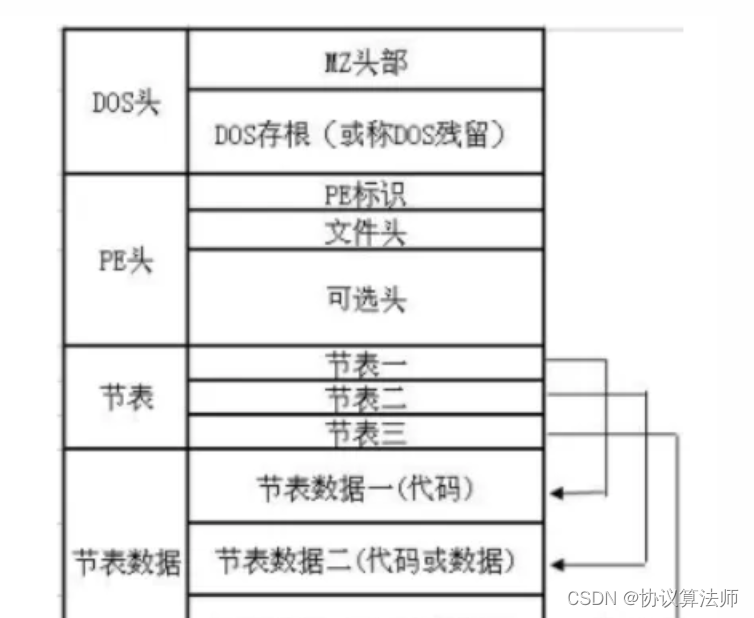
概括
DOS部分(早期为了兼容DOS所设计)
-
IMAGE_DOS_HEADER(64字节)

MS_DOS Stu,DOS存根,大小是不固定的,链接器会在这里插入数据,不影响程序运行,病毒程序可以插入在这里。虽然倒下不固定,但我们可以通过IMAGE_DOS_HEADER结构体的最后一个成员PE头开始的位置,用这个值减去64即DOS存根的大小。 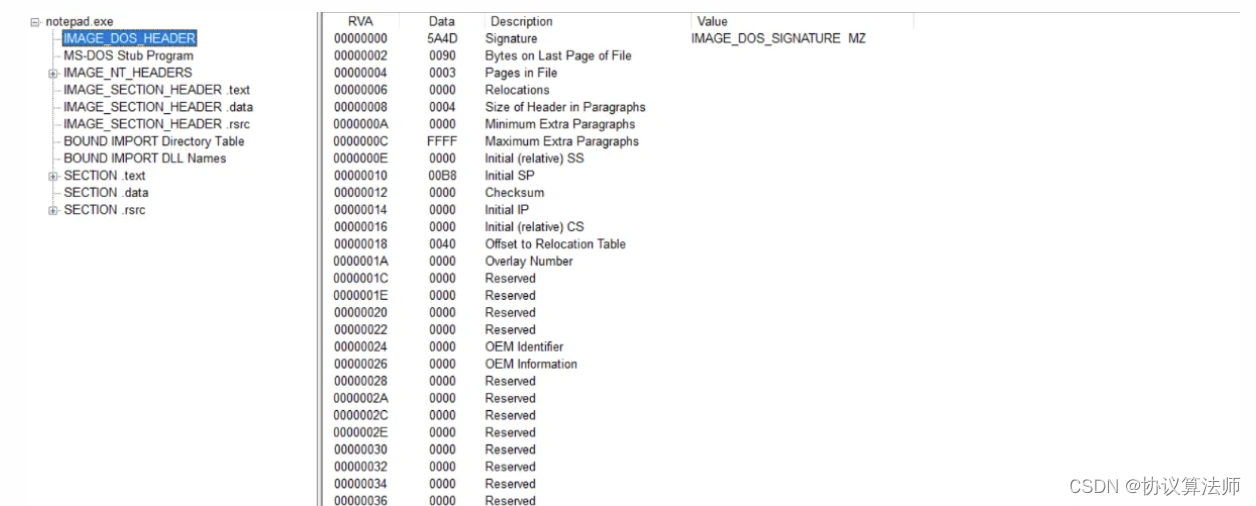
PE文件头
-
IMAGE_NT_HEADERS即PE头结构体,包括三个部分PE标识,标准PE头,扩展PE头


IMAGE_OPTIONAL_HEADER(32位)(224字节)(可扩展),IMAGE_FILE_HEADER结构体的一个成员记录该结构体的大小。 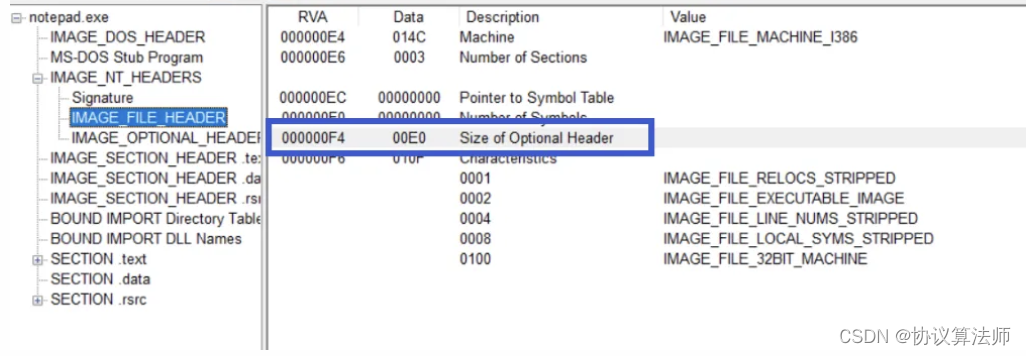

节表 (记录节的信息)
-
IMAGE_SECTION_HEADER (40字节)
有几个节区就有几个这样的结构体

IMAGE_SECTION_HEADER .text

节表后面是一些意义不大的数据,我们可以有效利用这些空间,所以节表和节表数据是不相邻的。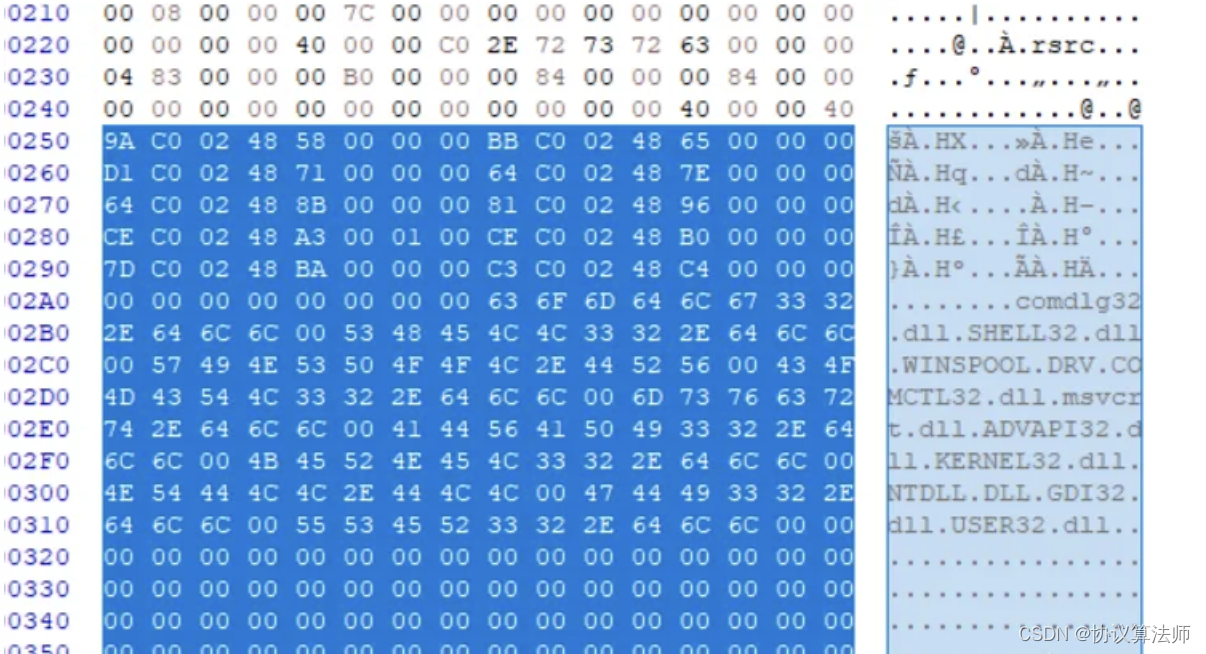 在可选头结构体中有一个成员记录PE头(DOS头+PE文件头+节表)的大小
在可选头结构体中有一个成员记录PE头(DOS头+PE文件头+节表)的大小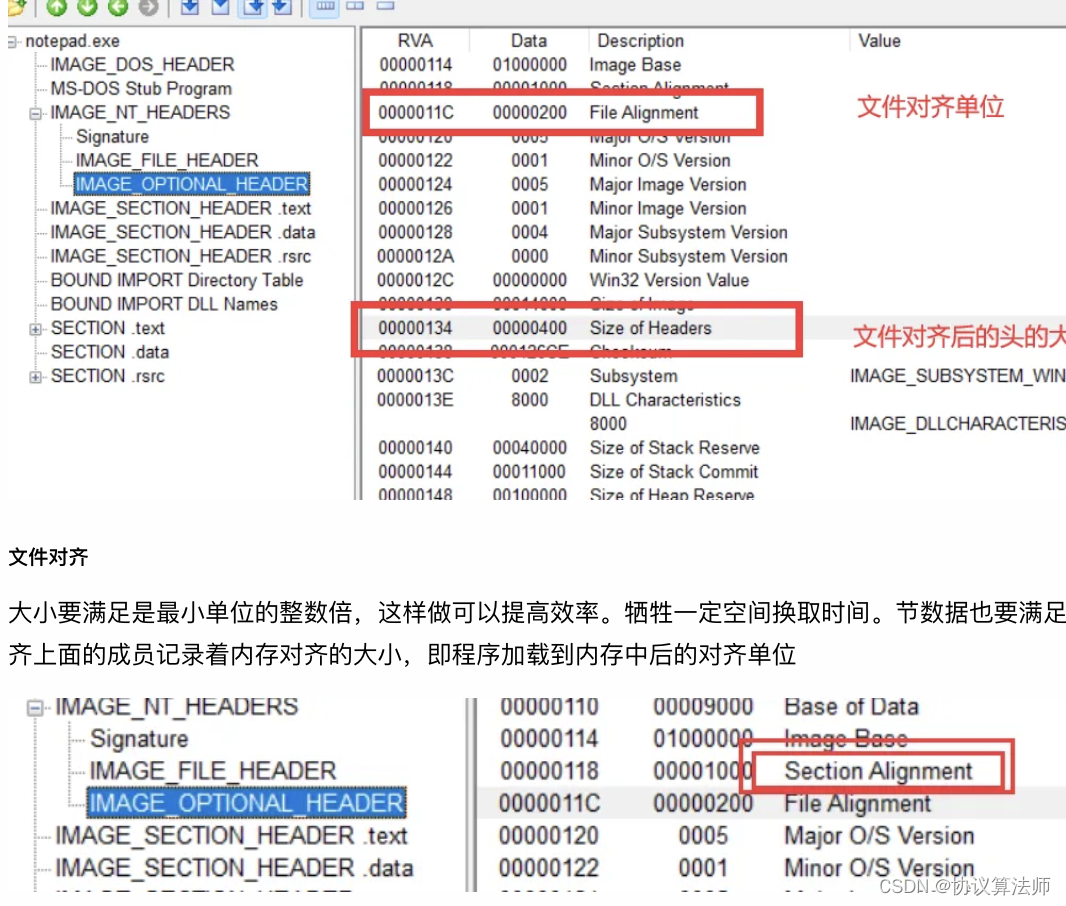
PE文件有两种状态:
磁盘状态(存储)
内存状态(运行)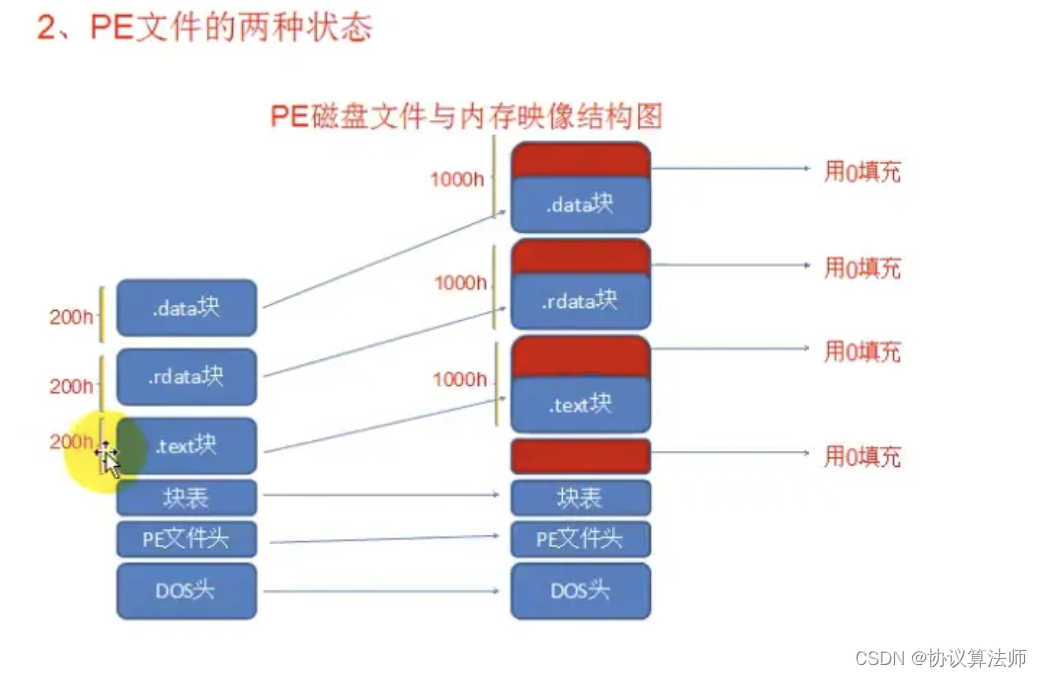
Q & A
Q:为什么文件对齐参数与内存对齐参数不相同?
A:因为它们分别用于优化文件I/O和虚拟内存管理。
DOS头属性说明
IMAGE_DOS_HEADER结构体是为了早期16位程序而准备的,现在已经弃用除了头尾两个成员,其余的都是可以更改的
更改之后不影响程序运行。
PE头属性说明

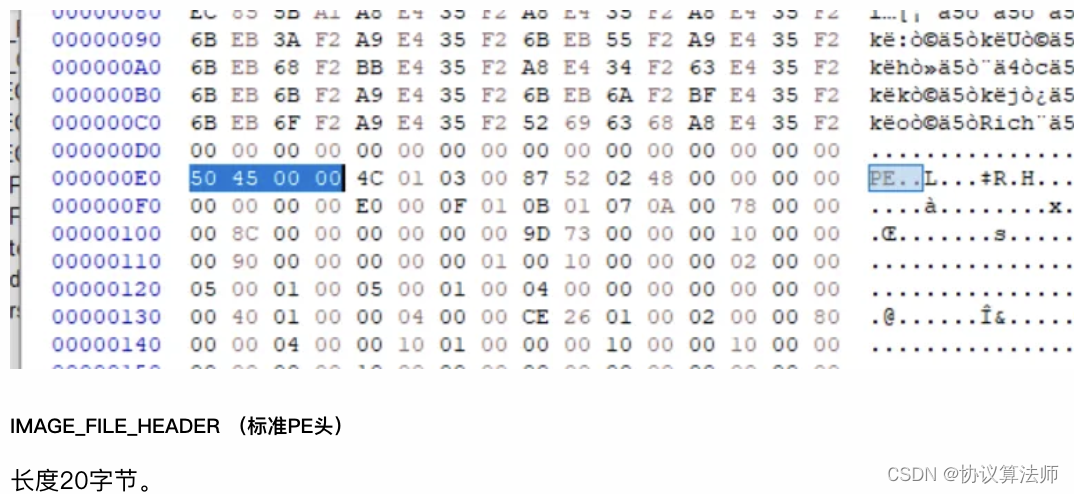
Signature
4个字节的签名。更改之后不可运行。
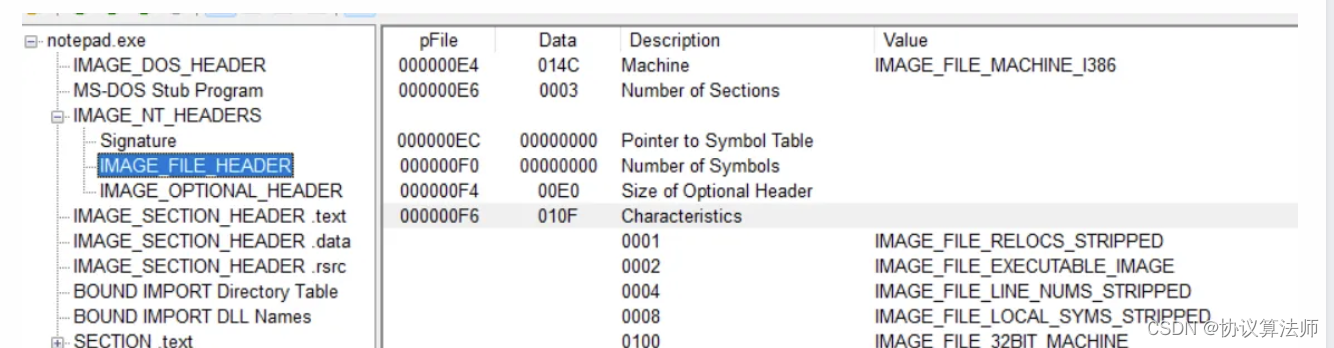

Machine
两个字节,标记可以程序可以运行在什么样的CPU上。 任意:0 ;Intel 386以及后续:14C;x64:8664
Number of Section
两个字节记录节的数目。 

程序的时间戳是指在Windows操作系统上编译或链接可执行文件时,由编译器或链接器自动插入的一个时间戳。它通常存储为32位无符号整数,表示从1970年1月1日00:00:00(格林威治时间)开始的秒数。可以更改。
Pointer to Symbol Table &Number of Symbol
调试相关,不关注,共8个字节
Size of Optional Header
两个字节,因为可选头长度是不固定的,该成员记录MAGE_OPTIONAL_HEADER的大小,32位默认是0xE0,64位默认是0xF0。如果可选头长度更改,也要对应修改这里。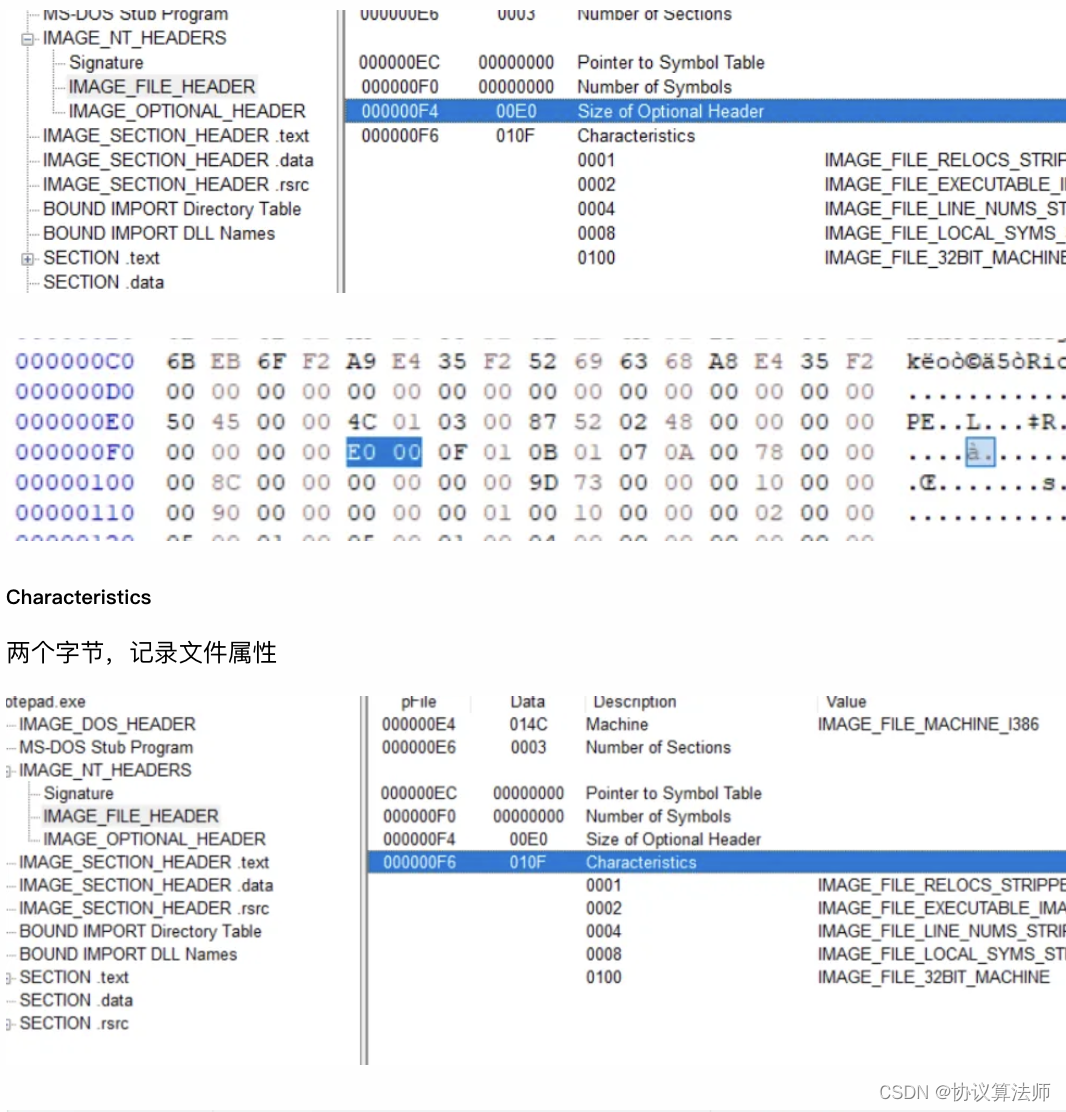
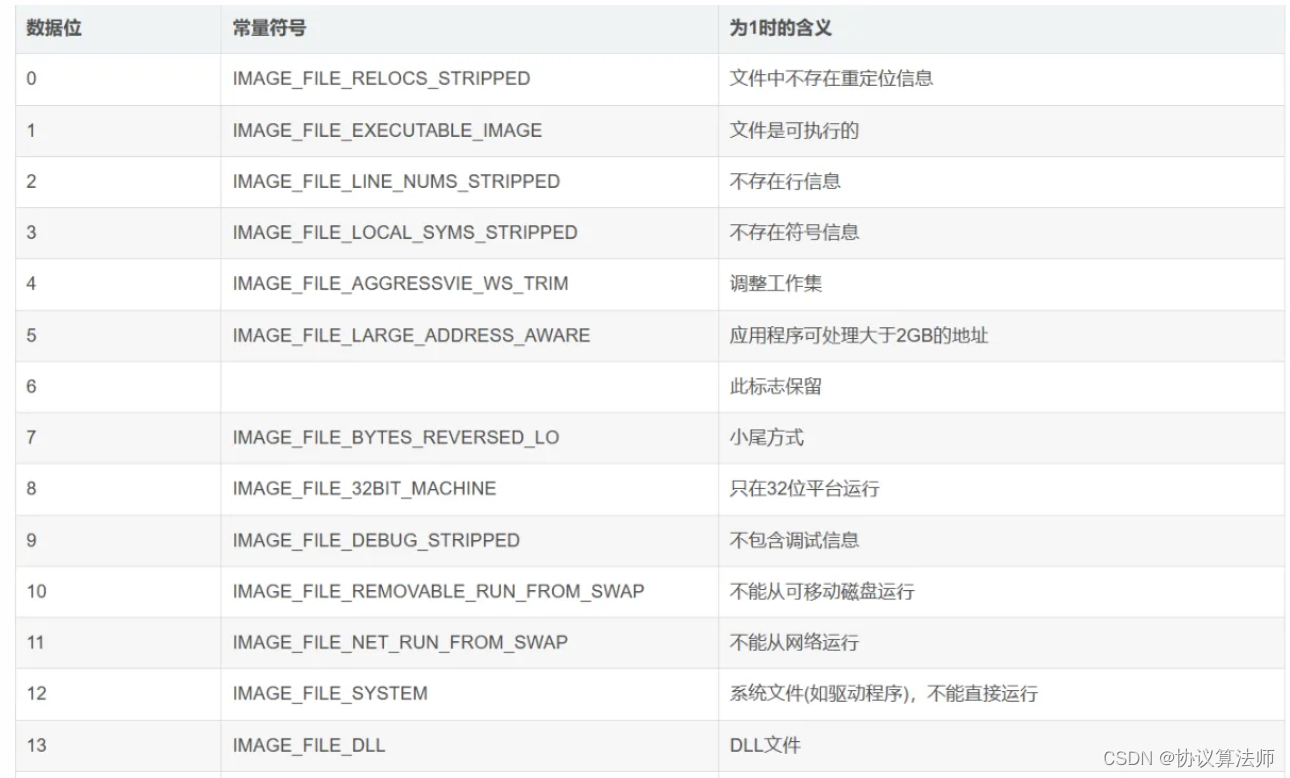
010F -->0000 0001 0000 1111,每一个位都有意义,比如下标为1的地方是1,那么代表该文件是可执行文件。
IMAGE_OPTIONAL_HEADER (扩展PE头)
Magic
两个字节,标志程序是32位还是64位(最准确)。PE32:10B ;PE32+:20B


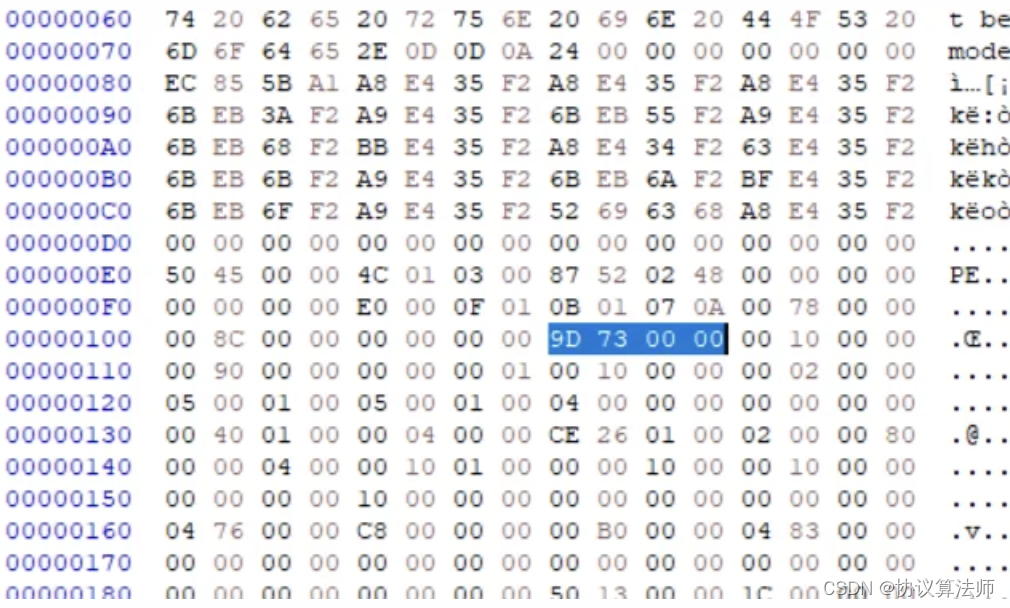
记录代码开始的位置,记录的是相对Image Base的距离。PE文件在内存中展开后最前面都是数据,需要一个值告诉操作系统从哪里开始运行。 那么么该程序就从01000000+0000739D=0100739D, OD会在程序开始设置一个断点,地址就是这里。对这里进行修饰会增加逆向分析的难度,因为调试机器找不到程序入口。
那么么该程序就从01000000+0000739D=0100739D, OD会在程序开始设置一个断点,地址就是这里。对这里进行修饰会增加逆向分析的难度,因为调试机器找不到程序入口。
Image Base
4字节,内存镜像基址。对于32位机器,操作系统会位每个进程分配一个4GB的虚拟地址空间,之所以是4GB,是因为32位操作系统指针长度为4字节32为,所以寻址能力是2的32次方。该成员指明程序在虚拟地址空间的何处展开,即基地址。 
File Alignment
文件对齐大小。
Size of Image
文件在内存中展开时的大小。
Size of Header
四字节,所有头+节表按照文件对齐后的大小。
Checksum
校验和,以两字节为单位,将所有的数据相加。用来判断程序是否受到修改,但是我们可以通过修改其他数值来平衡,所以意义不大。
PE节表
学习节表之前首先要知道PE文件的两种状态
即文件状态和内存状态

Name
8字节,当前节的名字,可以随意更改。
Vitual Size
当前这个节未对齐时的大小,即实际大小。实际大小有可能会比Size of Raw Data大,因为未初始化的全局变量在文件中是不占空间的。在内存中展开时以什么为基准呢?答案是谁大按谁,如果Vitual Size>Size of Raw Data,则按照Vitual Size展开,反之则按照Size of Raw Data。
VirtualAddress
在内存中的偏移地址,加上ImageBase则是内存中的真实地址。
Size of Raw Data
文件对齐后的大小,Vitual Size的值是7748,文件对其大小是100,Size of Raw Data的值为7800。
Pointer to Raw Data
当前节在文件中从何处开始

可以看到下标为5的位是1,代表该节中含有代码。
RVA与FOA的转换
用一个简单的程序开始RVA.c
| 1 2 3 4 5 6 7 8 9 10 11 |
|
我们的任务是通过地址找到该全局变量,然后改变它的值。

我们运行程序,看到其地址是00bca000,这是在内存中的地址,我们知道PE文件在内存中和在文件中展开是不一样的,我们就是要通过内存中的这个地址找到文件中对应的位置。
RVA
相对虚拟地址(Relative virtual address) RVA=内存地址-ImageBase
查看其Image Base得到 RVA=D0A000-400000=90 A000
FOA
文件偏移地址(File offset address) FOA
转换过程
- 判断RVA是否在PE头部,如果在则RVA=FOA,因为头部没有被拉伸
- 如果不在头部,判断RVA位于哪个节中 ,求出 差值=RVA-节.VA,也就是该地址相对节头的距离。为什么要求差值?因为在文件和在内存中差值是相同的。 FOA=节.PointerToData+差值

他的位置是在00CAA000处,这里的位置即内存中的位置,不用想,他肯定不在头中。我们必须将运行中的程序进行分析,因为基地址也是随机化的。




我大为震惊。其实这个过程遇到了很多麻烦,基地址随机是在这个过程中认识到的。这个过程挺美妙的,虽然是个很简单的东西,却体现出了逆向的的思想与魅力。
修改PE文件
在空白区域添加代码
我们要插入这样一个代码
| 1 2 3 4 5 6 |
|

功能呢就是弹出一个这样的错误窗口。这个程序的核心就是调用了一个messagebox函数弹出了一个窗口。由于我们是要对pe文件进行操作,所以肯定不是将代码写入,而是要将机器码插入。就是利于栈传第四个参数0,然后call。
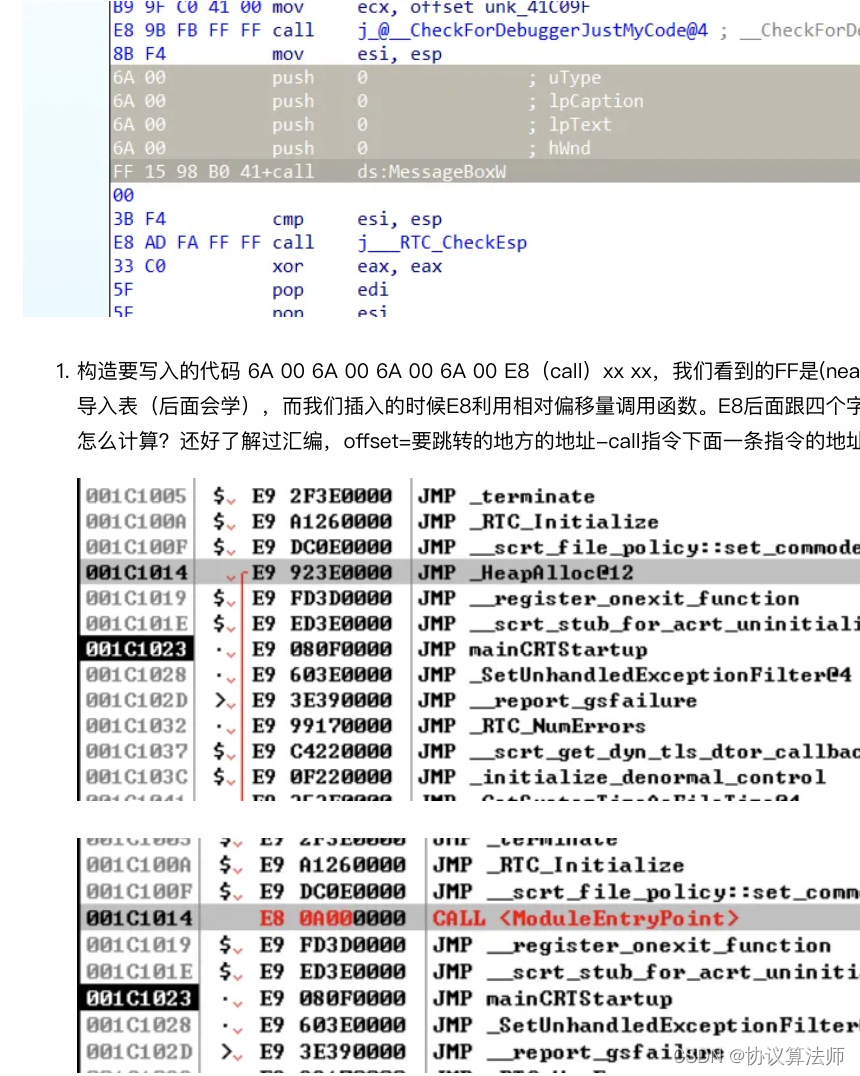
将图一标记位置改为call 1c1023 得到图二,后面的0A=1c1023-1c1019.我们的目标指示让他弹出窗口,不能破坏程序运行,所以弹出之后我们还要跳回到初始位置,让程序正常运行,我们使用JMP(E9)指令来实现该操作,E9后面也是跟偏移量,用法与E8相同。找到messagebox的地址75858A70。根据call指令的位置来计算。
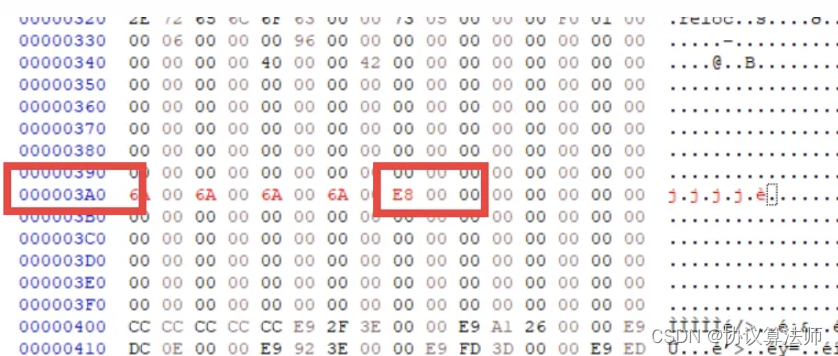
E8所在的位置是3A8,这是文件中的位置,我们要考虑的是运行时的位置,所以要把这个地址加上Image Base =01000000,所以最后得到的 offset=75858A70-010003A8-5=7485 86C3.最后跳转到程序的入口处,查看可选头的成员入口值为739D加上Image Base得到0100739D. offset=0100739D-010003AD-5=6FEB

在108处占4个字节,我们插入的程序起始位置是000003A0.然后,然后就没然后了,程序运行不起,ida和od看到的东西都很奇怪,延误了两天,这里我直接说一下踩的坑,我随意找了一个空白处填充机器码,但后来发现不是所有的位置都能发生跳转,然后就将指令插入在了text段的末尾,然后发现跳转的有些差异,不会跳转在我设置的地方,后知后觉的发现,视频里的老哥演示的的时候拿的是一个文件对齐和内存对齐相同大小的程序,我用的程序是一个不同的,所以就要计算一下 用我们前面学习到的知识。下面理一下步骤
- 首先在文件中确定一段空间,然后运行程序的时候查看 是否为空
- 插入,根据内存中的位置计算
- 改入口,内存中代码的起始位置

第一次尝试的时候成功弹出了窗口,但是关闭之后没有出现记事本,由此我们可以判断执行完我们的代码后,没有成功的返回原入口。此时才想起来补码写错了,插入的位置是87b0,入口点是739d,739d-83b0-5=
然后我就在e9后面填充了E8 EF 00 00,意识到返回出现问题后,想到了有符号数的符号扩展,应该扩展其符号位即1,所以正确的补码形式是FF FF EF E8,填充进去就是E8 EF FF FF.
删除节
删除一个节比较简单,尤其是删除最后一个节,.reloc节区是基址重定位表,删除这个节区对程序的正常运行没有影响,而且删除这个节区可以将文件的大小缩减。下面说一下步骤:
- 将.reloc节区头用0覆盖
- 删除reloc节区
- 修改Image_FILE_HEADER中的numberofsection成员
- 修改IMAGE_OPTIONAL_HEADER中的SizeofImage
覆盖.reloc节区头
28个字节

因为是最后一个节区,所以我们只要将C000即后面的东西删除即可
修改Image_FILE_HEADER
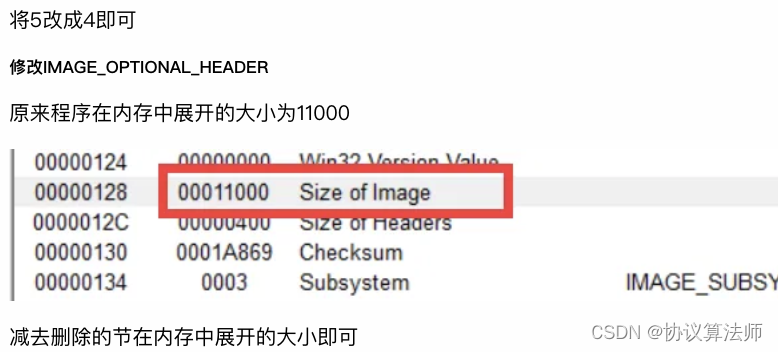


扩大节
为什么要扩大节?
前面演示插入的代码很短,如果要插入一段比较长的代码,可能找不到合适的空间。常见的解决方案就是扩大节,那么扩大哪一个节呢?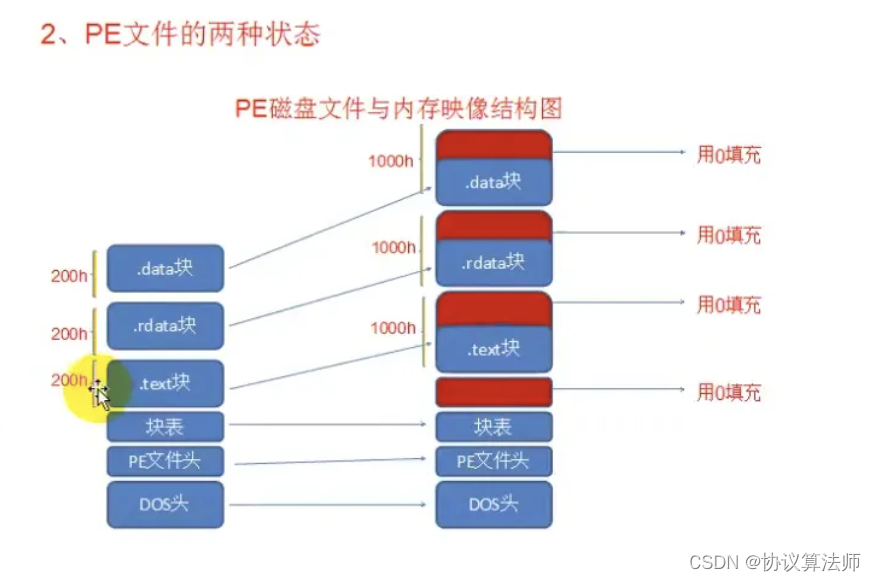
根据这个图不难看出,最好是扩大最后一个节,因为扩大前面的节如果想不影响程序的正常运行,还要去修改节表里的属性。
扩大节的步骤
- 分配空间
- 修改SizeofRawData和VirtualSize
- 修改SizeofImage(内存对齐大小)
- 如果扩展的节没有可执行属性,我们可以在节表结构体更改其属性。
1.分配一块新的空间,大小为S,这里我们选择在最后一个节后面分配0x1000byte的空间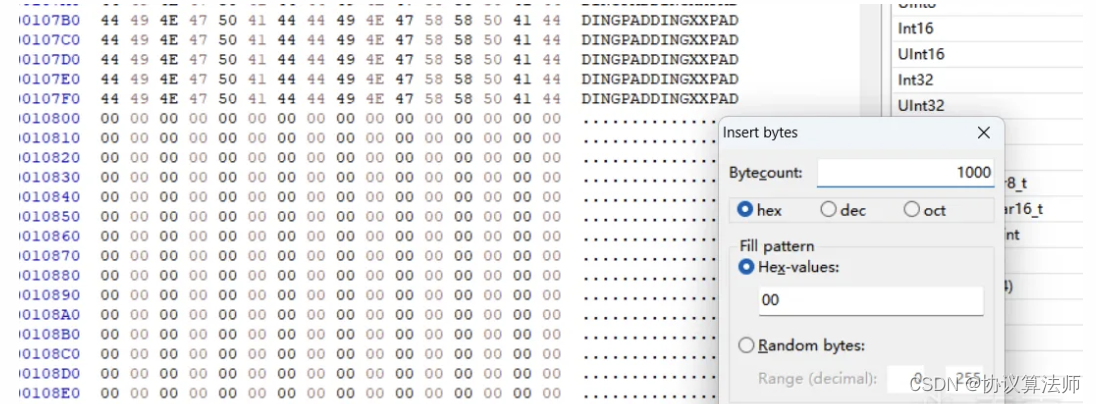
2.修改该节节表信息。要修改Size of Raw Data(实际大小)和Virtual Size(文件对齐后的大小),将这两个值修改为N。从前面的学习,我们了解到文件对其后的大小不一定大于实际大小,我们只需选择其中那个大的值max,N=max+S。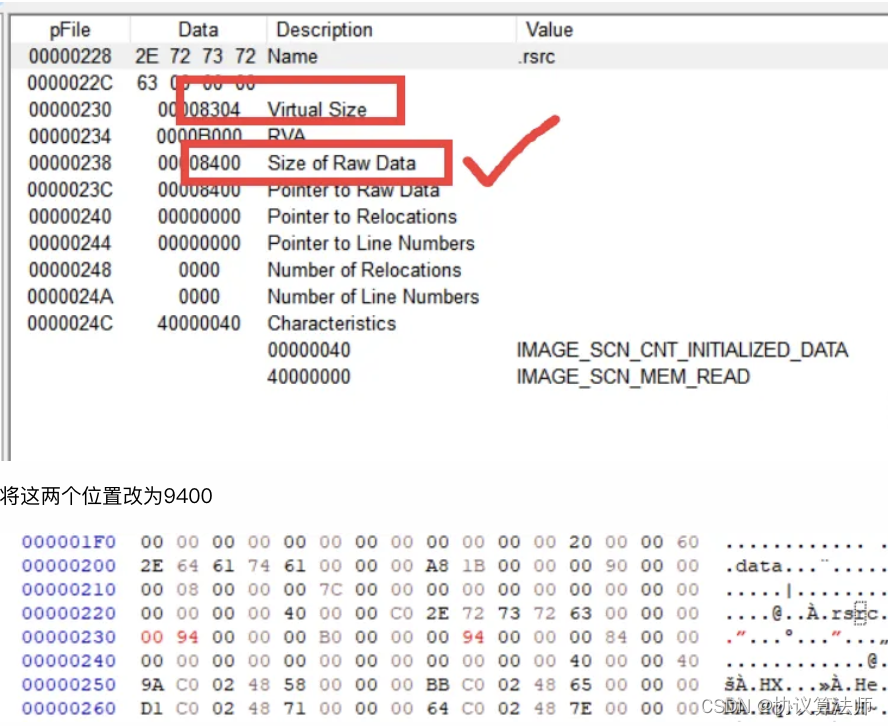

将该值按照内存对齐之后,再加上新增的0x1000即可,修改完保存,程序正常运行。
新增节
合并节
详解导入导出表
导出表
前置知识,一个可执行程序是有多个pe文件组成的。
导入表:描述pe文件引用了哪些文件,相当于进货清单。
导出表:当前pe文件提供哪些函数供其他文件使用,相当于饭店的菜单。
导出表在哪里?
在扩展pe头,最后一个成员,是个结构体数组,这个结构体的第一个成员就存放着导出表的相关信息。



导出表的第一个成员VirtualAddress记录着内存偏移地址(RVA),Size记录着导出表的大小。
我们动一下手,拿keyHook.dll试试手
RVA是80B0,查了一下在rdata段,rdata段的起始RVA为6000,所以相对地址就是20B0,rdata段的pointer to raw data及文件偏移地址为5000,所以他的FOA为70B0,大小是5B字节。


它还含有三张子表格,我们可以看到这是40字节的内容,而我们刚才查看的是5B字节,其实这个5B是算上子表之后的大小。
Name
name指针,对应的值是000080EC,对应的FOA是70EC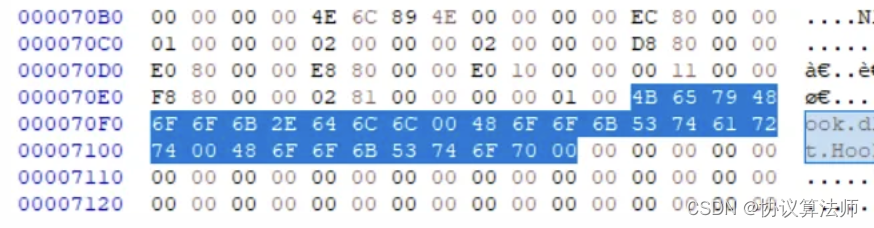
指向一个ascii字符串(当前dll的名称),0表示结尾。
NumberOfFunctions
所有导出函数的个数
NumberOfNames
根据函数名到处函数的个数,除了根据函数名导出函数,还能根据序号,也就是启用函数名定义一套序号规则,在一定程度上,通过序号导出函数能够增加程序的分析难度。
AddressOfFunctions
导出函数地址表RVA,又是一张表,表的成员每一个都是四字节大小,代表的是函数所在的地址。
AddressOfNames
导出函数名称表。存储的函数名称所在的地址。每个成员四字节大小。
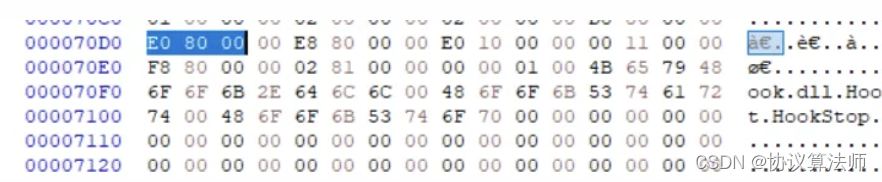
首先查到AddressOfNames的RVA为80D0,那么FOA是70D0,第一个成员80F8注意这是RVA,换算成FOA是70F8,对应可以看到“HookStart”,后面一个是8102,换算成FOA是7102,对应“Hookstop”
AddressOfNamesOrdinals
导出函数序列号表。有几个根据函数名称导出的函数,该表就有几个成员。每个成员二字节大小。
这是一个API,它有两个参数,DLL的句柄就是该DLL在内存展开时的地址,函数名

当API通过函数名调用函数,比如说它调用了hookstart,那么它会前往函数名称列表获得hookstart的索引值0,之后会去序号列表,序号列表下标为零的值是0,拿到这个0再去函数地址列表充当索引最终找到函数的地址。有时候不是通过函数名而是通过函数序号查找函数,这就要用到刚才没介绍的一个成员Base,它的值是函数地址列表的起始序号,如果其实序号为10,所调用的函数的序号是11,那么第二个成员hookstop的序号对应为11,完成调用。
导入表
导入几个模块就有几张导入表,每个表记录该模块的信息。
两个成员分别是导入表的地址和导入表的大小。有没有指明导入表数量的成员?答案是没有,我们可以通过查看16进制数据判断,每个导入表的大小是20个字节,从起始位置划分每20字节一组,直到出现一组20字节全部为0即代表结束,从而可以判断数量。
这个联合指向的是IMAGE_THUNK_DATA结构体,这些结构体组成INT(import name table),要用到该模块的几个函数,就有几个IMAGE_THUNK_DATA结构体,每个结构体大小是4字节,当出现连续的4字节为0,则说明INT截止。
导入表的地址是6B24,6B24处的第一个成员的值是7b60,转换成foa是6b60,IMAGE_THUNK_DATA结构体就在6B60处



完整的理一遍,首先通过扩展pe头的左后一个成员import table找到了导入表,导入表的第四个成员是个RVA指向了kernel32.dll字符串,这是导入的模块的名称,通过导入表的第一个成员(一个RVA指向)IMAGE_THUNK_DATA,该成员的最高位不为1,说明是个RVA,通过这个RVA找到了importbyname,通过该成员的第三个字节找到了导入的这个模块所使用的一个函数GetModuleFileNameA
PE文件加载前后,IAT(import address table)导入地址表发生变化,IAT不在指向函数名称,而是已经根据函数名称更换了表格。INT那里相当于一层保险,当程序IAT被修改(脱壳时就要修复导入表),无法找到函数时,可以根据INT和相关函数得到函数地址,从而修复IAT。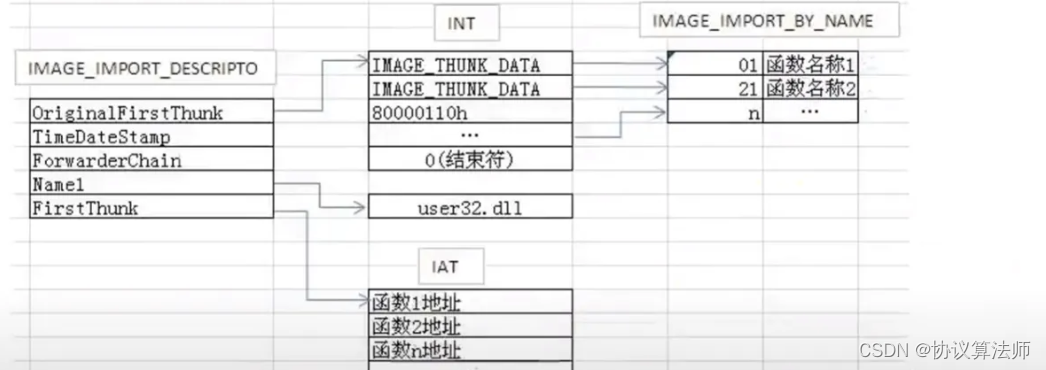
重定位表
重定位表的作用:如果可执行文件中的全部的地址相关的数值都是RVA即相对imagebase来的,那么重定位表可有可无。但是有的全局变量他的地址是硬编码,只有文件被加载到了内存中特定的位置在能正常使用,但是可执行文件往往要加载多个dll,原来那个位置可能已经被占了,这时候只能再选一个空闲的地址,此时imagebase就不是预期的值了,这种情况就要根据重定位表进行修改。
| 1 2 3 4 5 |
|
上面的代码的汇编码如下,mov 【00427e34】,11h 由于全局变量使用了硬编码,显然只有加载的特定的位置该代码才能生效。

上图代表的就是这个结构体,x表示第一个成员,y表示大小,第一个结构体的y为16,所以该结构体16字节大小,再往下就是下一个,下一个是20字节大小,再往下是12字节大小,当遇到连续的八个字节为0,也就是x和y都为0时,代表该表格结束。解释一下为什么要这样设计,其实这个表存放的是要进行重定位的成员的地址,X代表的相当于一个基地址,Y后的每一个成员即从第九个字节开始,每两个字节为一个成员,比如X的值为80 00 00 00,后面的字节为12,16,18,则代表 80 00 00 12、80 00 00 16、80 00 00 16需要进行重定位,可以看到存放一个实际的地址需要4个字节,存放10个是40字节,而我们采用基地址加偏移的方法只使用了24个字节,需要重定位的值越多,节省的空间就越多。(这个区块是根据内存页进行划分的,每个页4KB,每个页有一个重定位表,而两个字节的偏移地址能表示0~ffff,足够对一个页进行寻址,若要寻址至少需要12个位,一字节不够,所以选择二字节作为偏移地址的单位)。
重点: Y后的成员,两字节即16位一组,其实表示有效地址的是低12位,高四位并非没有作用,当高四位位0011的时候,才代表该处的值需要进行修复,比如说第一个成员为0011 0011 1111 1111,前四位为0011,代表该成员需要被修复,取低12位加上X基地址即是真正需要修改的。若高4位不是0011,则该处数据无作用,可以理解为用来内存对齐的垃圾数据。
完结撒花了!!!!!!!!!!!!!!!!!!!!!! hhh