socket介绍
套接字的基本概念
1. 套接字的定义:
- 套接字(socket)是计算机网络中用于通信的端点,它抽象了不同主机上应用进程之间双向通信的机制。
2. 套接字的作用:
- 套接字连接应用进程与网络协议栈,使得应用程序能够利用网络协议进行通信。
- 它作为应用程序与网络协议栈的接口,通过操作系统提供的 API 进行数据交换。
套接字的工作机制
1. 双向通信:
- 在网络通信中,套接字充当两个应用程序之间的通信连接点。
- 一个应用程序可以将数据写入其所在主机的套接字,数据通过网络接口卡(NIC)和传输介质发送到目标主机的套接字,从而实现数据传输。
2. 组合与寻址:
- 套接字由 IP 地址和端口号组成,形成唯一的通信端点。
- 这种组合提供了一种机制,使数据包能够准确地传输到目标应用进程。
套接字在操作系统中的表示
1. 套接字作为文件:
- 在 Linux 环境下,套接字是一种特殊的文件类型,被内核用伪文件(pseudo-file)表示。
- 由于套接字被视为文件,因此可以使用文件描述符来引用和操作套接字。
- 这种设计使得套接字的读写操作与普通文件的读写操作一致,统一了接口。
2. 区别于管道:
- 虽然套接字与管道(pipe)类似,都用于进程间通信,但套接字主要用于网络进程间的数据传递,而管道主要用于本地进程间的通信。
套接字的类型
1. 常见的套接字类型:
- 流式套接字(Stream Socket):提供面向连接的、可靠的数据传输服务,典型的协议是 TCP。
- 数据报套接字(Datagram Socket):提供无连接的、不可靠的数据传输服务,典型的协议是 UDP。
总结
套接字是网络编程中的核心概念,提供了在不同主机上的应用进程之间进行通信的机制。它通过 IP 地址和端口号进行唯一标识,并在操作系统中作为特殊的文件类型进行管理,使得网络通信操作与文件操作一致,从而简化了编程接口。
socket 本身有“插座”的意思,在 Linux 环境下,用于表示进程间网络通信的特殊文件类型。本质为内核借助缓冲区形成的伪文件。既然是文件,那么理所当然的,我们可以使用文件描述符引用套接字。与管道类似的,Linux 系统将其封装成文件的目的是为了统一接口,使得读写套接字和读写文件的操作一致。区别是管道主要应用于本地进程间通信,而套接字多应用于网络进程间数据的传 递。
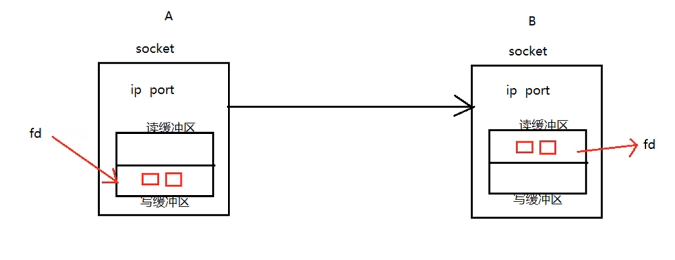
// 套接字通信分两部分:
- 服务器端:被动接受连接,一般不会主动发起连接
- 客户端:主动向服务器发起连接
socket是一套通信的接口,Linux 和 Windows 都有,但是有一些细微的差别。
字节序
字节序(Endian)问题是计算机系统中关于数据表示的重要概念,主要涉及到数据的存储和通信方式。在不同的计算机体系结构中,字节序可能不同,这就要求在进行数据传输和通信时必须明确字节序,以确保数据正确地被解释和处理。
大端字节序(Big-Endian)
大端字节序,也称为“网络字节序”,因为它是多数网络协议采用的字节序,包括TCP/IP。在大端字节序中,一个多字节数值的最高字节(即最重要的字节)被存储在最低的内存地址,其次是次高字节,依此类推。例如,一个32位整数0x12345678在内存中的存储方式如下(地址由低到高):
- 地址 x + 0: 0x12
- 地址 x + 1: 0x34
- 地址 x + 2: 0x56
- 地址 x + 3: 0x78
小端字节序(Little-Endian)
记忆:小低低
小端字节序则恰好相反,一个多字节数值的最低字节(即最不重要的字节)被存储在最低的内存地址。它被很多现代桌面计算机体系(如x86架构)采用。例如,同样的32位整数0x12345678在小端字节序的计算机中的存储方式如下:
- 地址 x + 0: 0x78
- 地址 x + 1: 0x56
- 地址 x + 2: 0x34
- 地址 x + 3: 0x12
字节序的重要性
在网络通信中,字节序的不一致会导致数据被错误解释,进而造成通信错误。因此,为了数据能在不同的计算机系统间正确传输和接收,往往需要在发送和接收端之间进行字节序的转换。例如,在一个小端字节序的机器上发送数据到一个大端字节序的机器上时,发送者需要将数据从小端转换为大端字节序。
在进行网络编程,尤其是跨平台通信时,理解并正确处理字节序问题是非常关键的。Socket编程中经常用到的htonl()和ntohl()等函数就是用于在主机字节序和网络字节序之间转换整数的字节序。
总结来说,字节序是一个基础而重要的概念,涉及到计算机体系、操作系统平台、网络通信等多个层面,正确处理字节序问题对保证数据交换的正确性和效率至关重要。


案例
/*
字节序:字节在内存中存储的顺序。
小端字节序:数据的高位字节存储在内存的高位地址,低位字节存储在内存的低位地址
大端字节序:数据的低位字节存储在内存的高位地址,高位字节存储在内存的低位地址
*/
// 通过代码检测当前主机的字节序
#include <stdio.h>
int main() {
union {
short value; // 2字节
char bytes[sizeof(short)]; // char[2]
} test;
test.value = 0x0102;
if((test.bytes[0] == 1) && (test.bytes[1] == 2)) {
printf("大端字节序\n");
} else if((test.bytes[0] == 2) && (test.bytes[1] == 1)) {
printf("小端字节序\n");
} else {
printf("未知\n");
}
return 0;
}
daic@daic:~/Linux/linuxwebserver/part04networkProgramming$ gcc byteorder.c
daic@daic:~/Linux/linuxwebserver/part04networkProgramming$ ./a.out
小端字节序
在进行网络编程时,处理字节序是保证跨平台数据通信正确性的一个重要方面。你已经很好地概括了如何利用大端字节序(即网络字节序)来实现数据的一致性和正确传输。下面我们详细解释这些概念和具体的函数使用:
字节序转换函数
网络字节序的重要性
**网络字节序是大端(Big-Endian)字节序,**这意味着数据的高位字节存储在低地址上。TCP/IP 协议族规定使用大端字节序是为了确保数据在不同计算架构的机器间传输时,每一台设备都能以相同的方式解释这些数据。这个标准化的处理方式避免了每个应用程序需要考虑目标机器字节序的复杂性。
h - host 主机,主机字节序
to - 转换成什么
n - network 网络字节序
s - short unsigned short
l - long unsigned int
#include <arpa/inet.h>
// 转换端口
uint16_t htons(uint16_t hostshort); // 主机字节序 - 网络字节序
uint16_t ntohs(uint16_t netshort); // 主机字节序 - 网络字节序
// 转IP
uint32_t htonl(uint32_t hostlong); // 主机字节序 - 网络字节序
uint32_t ntohl(uint32_t netlong); // 主机字节序 - 网络字节序
字节序转换函数
BSD Socket API 提供了一些函数来帮助程序员在主机字节序和网络字节序之间转换数据。主要的函数有:
htonl()(Host TO Network Long): 将一个长整型数从主机字节序转换到网络字节序。htons()(Host TO Network Short): 将一个短整型数从主机字节序转换到网络字节序。ntohl()(Network TO Host Long): 将一个长整型数从网络字节序转换到主机字节序。ntohs()(Network TO Host Short): 将一个短整型数从网络字节序转换到主机字节序。
使用场景
- 发送数据时: 在发送数据之前,数据需要从主机字节序转换为网络字节序,使用
htonl()和htons()。 - 接收数据时: 在读取从网络接收的数据时,需要将数据从网络字节序转换回主机字节序,使用
ntohl()和ntohs()。
示例
假设您正在编写一个跨平台的网络应用,您需要发送一个整数和一个短整型数:
#include <stdio.h>
#include <netinet/in.h>
int main() {
int num = 0x12345678;
short s_num = 0x1234;
// 转换为网络字节序
int net_num = htonl(num);
short net_s_num = htons(s_num);
// 发送 net_num 和 net_s_num ...
// 接收数据
// 假设接收到的数据存储在变量 net_num 和 net_s_num 中
int host_num = ntohl(net_num);
short host_s_num = ntohs(net_s_num);
printf("Original: %x, Received: %x\n", num, host_num);
printf("Original Short: %x, Received Short: %x\n", s_num, host_s_num);
return 0;
}
这个例子展示了如何在发送和接收数据时处理字节序问题,确保数据在不同系统间正确地传输和解释。通过这种方式,无论数据是在小端还是大端机器上生成或接收的,都能正确处理,从而实现真正的跨平台兼容性。
案例
/*
网络通信时,需要将主机字节序转换成网络字节序(大端),
另外一段获取到数据以后根据情况将网络字节序转换成主机字节序。
// 转换端口
uint16_t htons(uint16_t hostshort); // 主机字节序 - 网络字节序
uint16_t ntohs(uint16_t netshort); // 主机字节序 - 网络字节序
// 转IP
uint32_t htonl(uint32_t hostlong); // 主机字节序 - 网络字节序
uint32_t ntohl(uint32_t netlong); // 主机字节序 - 网络字节序
*/
#include <stdio.h>
#include <arpa/inet.h>
int main() {
// htons 转换端口
// typedef unsigned short int __uint16_t;
uint16_t a = 0x0102;
printf("a : %x\n", a);
unsigned short b = htons(a);
printf("b : %x\n", b);
printf("=======================\n");
// htonl 转换IP
char buf[4] = {192, 168, 1, 100};
int num = *(int *)buf;
int sum = htonl(num);
unsigned char *p = (char *)∑
printf("%d %d %d %d\n", *p, *(p+1), *(p+2), *(p+3));
printf("=======================\n");
// ntohl
unsigned char buf1[4] = {1, 1, 168, 192};
int num1 = *(int *)buf1;
int sum1 = ntohl(num1);
unsigned char *p1 = (unsigned char *)&sum1;
printf("%d %d %d %d\n", *p1, *(p1+1), *(p1+2), *(p1+3));
// ntohs
return 0;
}
daic@daic:~/Linux/linuxwebserver/part04networkProgramming$ gcc bytetrans.c
daic@daic:~/Linux/linuxwebserver/part04networkProgramming$ ./a.out
a : 102
b : 201
=======================
100 1 168 192
=======================
192 168 1 1
socket地址
// socket地址其实是一个结构体,封装端口号和IP等信息。后面的socket相关的api中需要使用到这个
socket地址。
// 客户端 -> 服务器(IP, Port)
通用 socket 地址
socket 网络编程接口中表示 socket 地址的是结构体 sockaddr,其定义如下:
#include <bits/socket.h>
struct sockaddr {
sa_family_t sa_family;
char sa_data[14];
};
typedef unsigned short int sa_family_t;
sa_family 成员是地址族类型(sa_family_t)的变量。地址族类型通常与协议族类型对应。常见的协议族(protocol family,也称 domain)和对应的地址族入下所示:
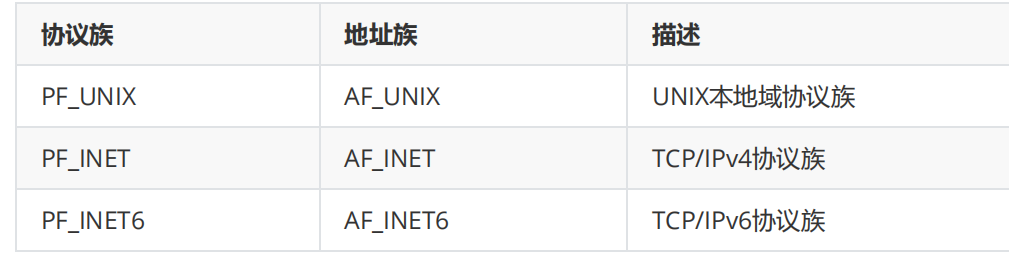
sa_data 成员用于存放 socket 地址值。但是,不同的协议族的地址值具有不同的含义和长度,如下所示:

由上表可知,14 字节的 sa_data 根本无法容纳多数协议族的地址值。因此,Linux 定义了下面这个新的通用的 socket 地址结构体,这个结构体不仅提供了足够大的空间用于存放地址值,而且是内存对齐的。
#include <bits/socket.h>
struct sockaddr_storage
{
sa_family_t sa_family;
unsigned long int __ss_align;
char __ss_padding[ 128 - sizeof(__ss_align) ];
};
typedef unsigned short int sa_family_t;
专用 socket 地址
很多网络编程函数诞生早于 IPv4 协议,那时候都使用的是 struct sockaddr 结构体,为了向前兼容,现 在sockaddr 退化成了(void *)的作用,传递一个地址给函数,至于这个函数是 sockaddr_in 还是sockaddr_in6,由地址族确定,然后函数内部再强制类型转化为所需的地址类型。
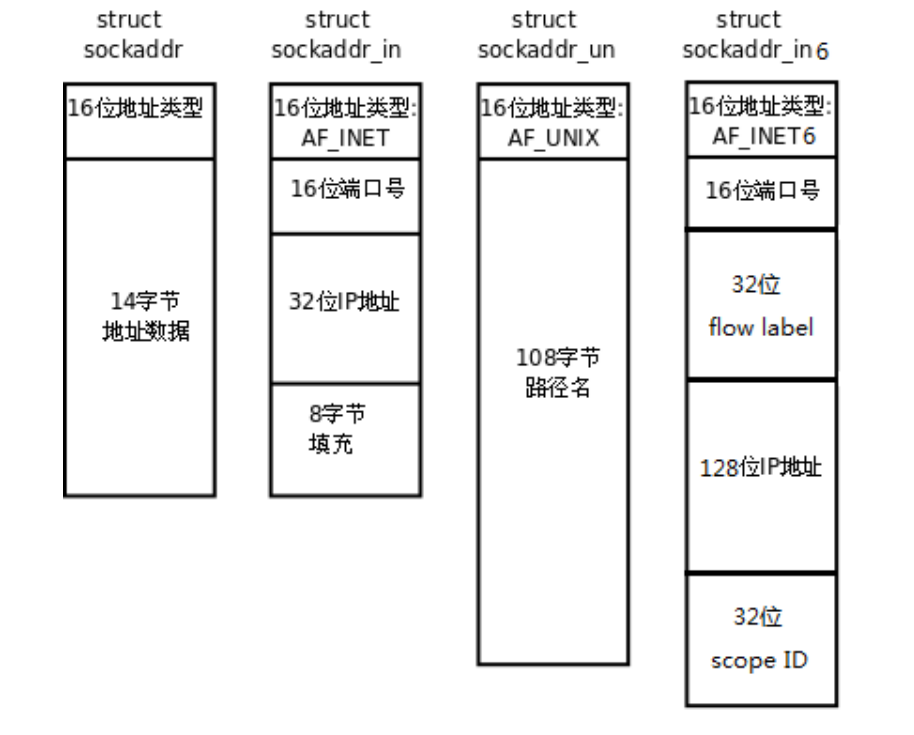
UNIX 本地域协议族使用如下专用的 socket 地址结构体:
#include <sys/un.h>
struct sockaddr_un
{
sa_family_t sin_family;
char sun_path[108];
};
TCP/IP 协议族有 sockaddr_in 和 sockaddr_in6 两个专用的 socket 地址结构体,它们分别用于 IPv4 和
IPv6:
#include <netinet/in.h>
struct sockaddr_in
{
sa_family_t sin_family; /* __SOCKADDR_COMMON(sin_) */
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE -
sizeof (in_port_t) - sizeof (struct in_addr)];
};
struct in_addr
{
in_addr_t s_addr;
};
struct sockaddr_in6
{
sa_family_t sin6_family;
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef uint16_t in_port_t;
typedef uint32_t in_addr_t;
#define __SOCKADDR_COMMON_SIZE (sizeof (unsigned short int))
所有专用 socket 地址(以及 sockaddr_storage)类型的变量在实际使用时都需要转化为通用 socket 地址类型 sockaddr(强制转化即可),因为所有 socket 编程接口使用的地址参数类型都是 sockaddr。