业内比较著名的监控解决方案,据笔者所知,大概是三套:
一个是zabbix的解决方案,一个是prometheus+grafana,一个是ELK
zabbix比较重,而且原生支持监控SNMP,自带一个仪表盘,不需要额外部署
promethues,对K8S的支持比较好,并且比较轻量化,但是需要配grafana才能出图
ELK非常重,笔者没咋玩过,但据说对大规模日志和实时分析非常好,你可以看到数据部门特别喜欢用Elastic search这个东西
今天笔者阳了,头疼的要命,哎上次阳了之后做了个核磁发现有脑萎缩和脱髓鞘希望这次不要加重。趁着这会写一个prometheus的搭建和配置教程吧。
一、【环境准备】
如果你打算创造就业岗位,建议用传统方法部署一个Prometheus,这样你可以创造一个专门维护Prometheus的岗位。
如果为了给自己省事,建议直接上docker(docker compose)或者K8S(chart),不过注意docker需要有root权限,虽然docker有root less版本,但是官网文档提出有一些潜在的和尚未探知的问题。
这里笔者就直接用docker搭了
prometheus是监控的中心节点,grafana是画图的,node-exporter是采集指标的放在哪台机器就是采集哪台机器指标,pushgateway是做短时任务的,alertmanager是告警的,当然你也可以用grafana自带的告警。
1. 安装docker
# 先查一下自己的发行版本,根据发行版本,下一步下载对应的安装包
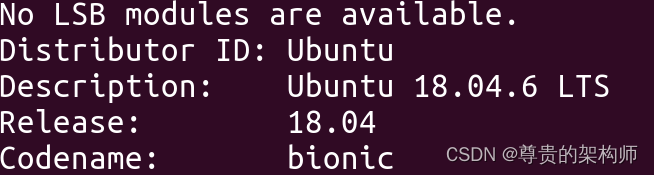
lsb_release
比如我这个是Ubuntu 18.04的版本,bionic,那么接下来我们就下载 对应的五个包
containerd.io_<version>_<arch>.debdocker-ce-cli_<version>_<arch>.debdocker-ce_<version>_<arch>.debdocker-buildx-plugin_<version>_<arch>.debdocker-compose-plugin_<version>_<arch>.deb
# 下载一下离线包,设法传到机器上
# ubuntu:https://download.docker.com/linux/ubuntu/dists/bionic/pool/stable/amd64/
# centos:https://download.docker.com/linux/centos/
# 随后逐个安装
sudo dpkg -i 安装包路径这个安装顺序一般是先装container,再装剩下的,有时候新版本的container在老版本的linux上会有依赖错误,更新一下依赖就行。
全部安装完后,最好还要换一下contanier的源,在/etc/containerd下面的config.toml,换源的教程很多,这里就不展开了
2. 测试docker
docker run helloword如果docker成功运行了你会看到这个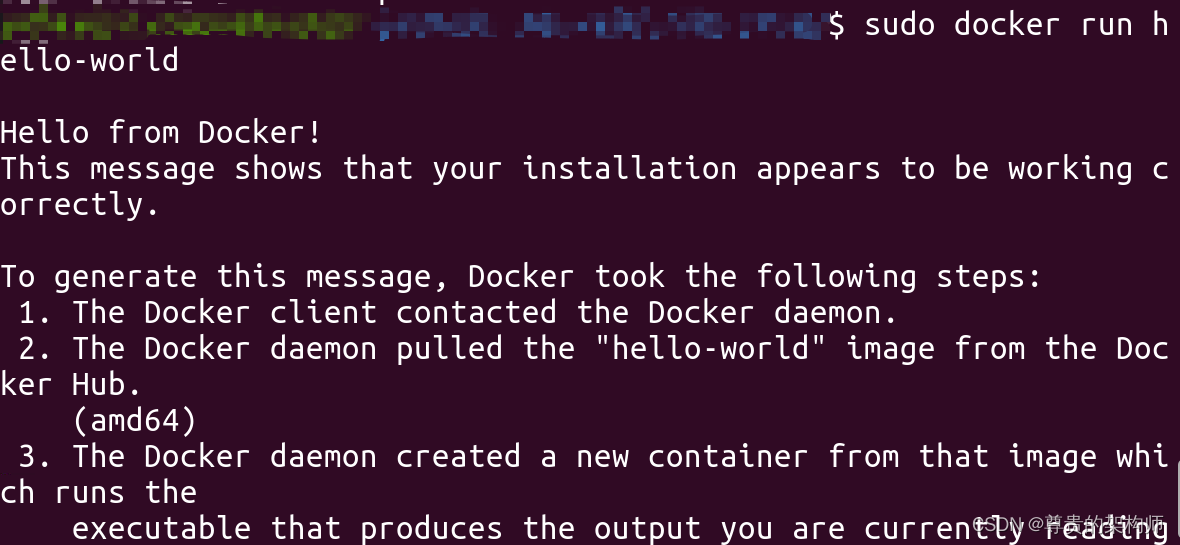
3. 写配置文件
这个是一个yml文件,简单来讲就是编排容器用的,可以一下起好几个,很方便。我们创建一个 docker-compose.yml
version: '3.7'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
ports:
- "9090:9090"
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
ports:
- "9100:9100"
command:
- '--path.rootfs=/host'
network_mode: "host"
pid: "host"
volumes:
- /:/host:ro,rslave
pushgateway:
image: prom/pushgateway:latest
container_name: pushgateway
ports:
- "9091:9091"
grafana:
image: grafana/grafana:latest
container_name: grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=your_password
volumes:
- grafana_data:/var/lib/grafana
ports:
- "3000:3000"
volumes:
prometheus_data:
grafana_data:
再写一个prometheus.yml,输入一下内容,这个是配置连接用的
global:
scrape_interval: 15s # 默认抓取间隔
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'pushgateway'
static_configs:
- targets: ['pushgateway:9091']
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
rule_files:
- 'alert.rules.yml'
再写一个 alermanager.yml,先这么写后期有告警加进去了再改
global:
resolve_timeout: 5m
route:
receiver: 'default'
receivers:
- name: 'default'
二、【容器!启动~】
然后cd到刚才你写docker-compose.yml的路径,输入
sudo docker compose up -d
# 如果要停止就是 sudo docker compose down看到这个,没报错,就算是成功了

三、【网页上的检查与配置】
1. 访问prometheus
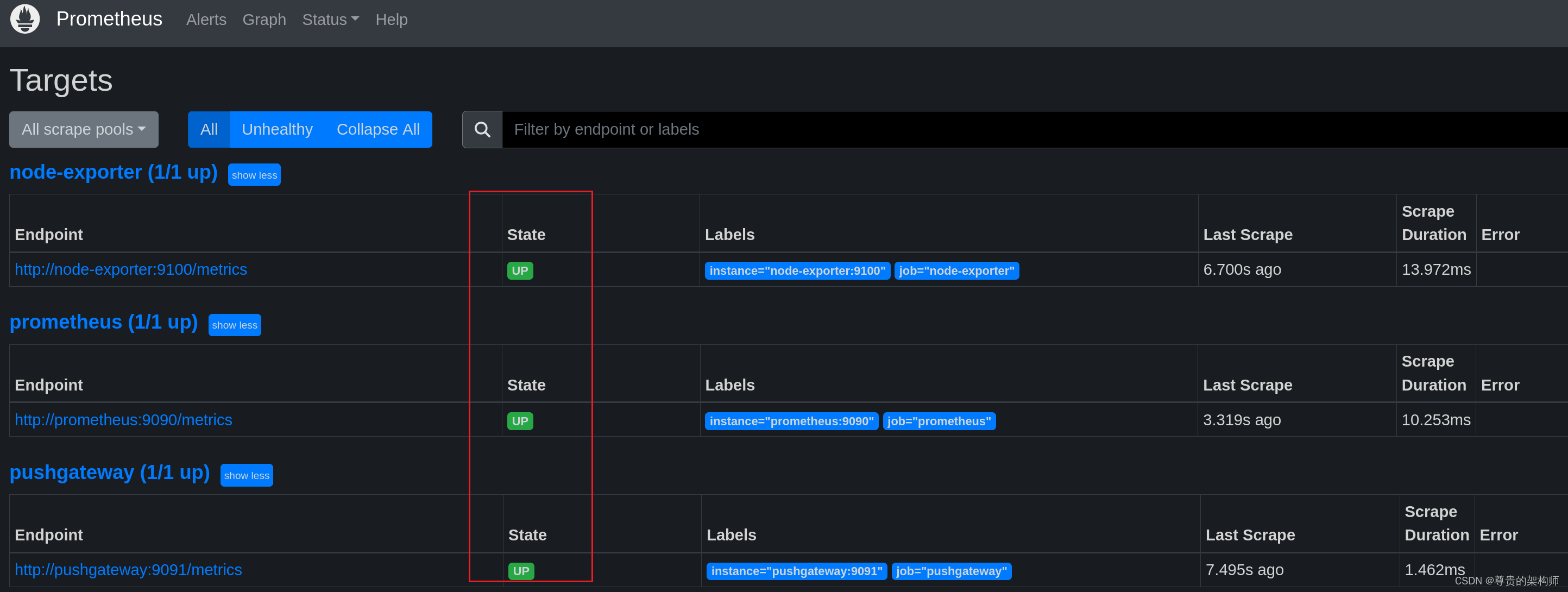
浏览器访问prometheus的地址(我们这里是127.0.0.1:9090)里面有个target
看到这边的state都是up状态,就是连接成功了
2. 访问grafana
浏览器访问prometheus的地址(我们这里是127.0.0.1:9094)
先配一个数据源,选prometheus
有了数据源就可以制图了,点左侧的dashboard仪表盘,new一个dashboard出来
点右上角新建一个视图

进来之后就可以设置自己的监控项目了,右侧有一些其他设置,感兴趣也可以看看,设置完右上角保存
然后再保存dashboard配置

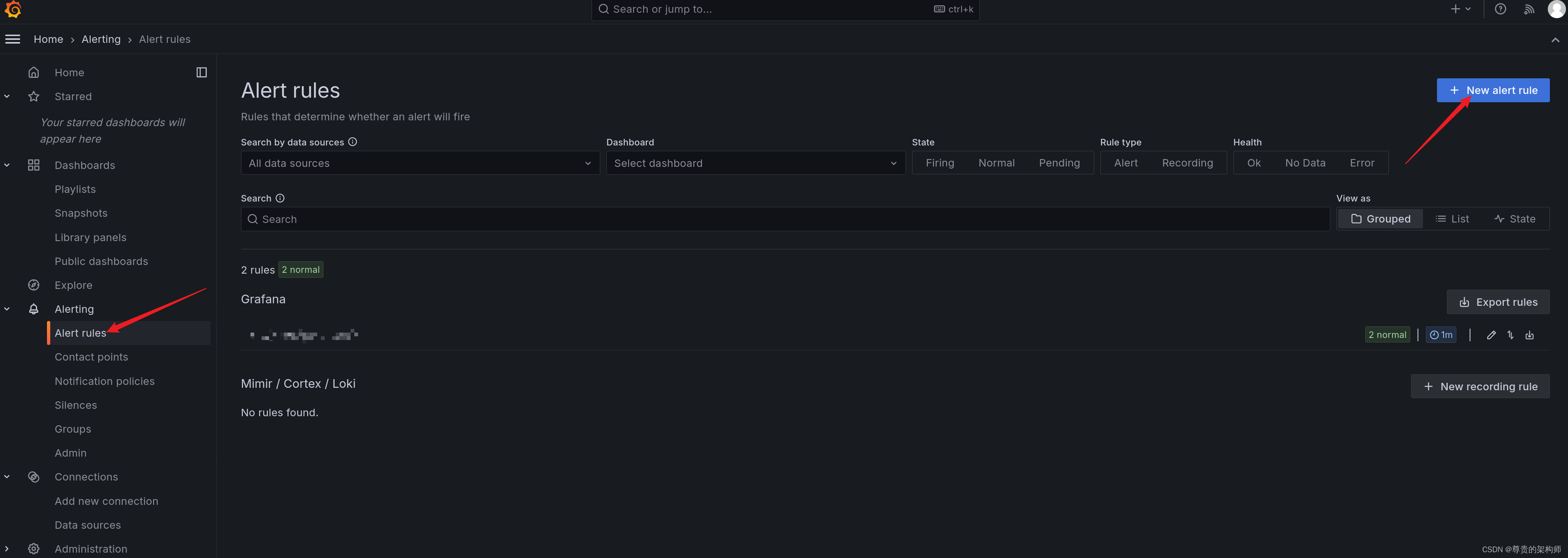
3. 配置告警
告警可以用alertmanager也可以用grafana的告警,前者需要写yml,后者可以在网页上点点点,如果告警量大建议用alertmanager,告警不多不复杂用grafana的告警也行
新建一个自己用的告警方式,这里有很多比如什么email、dingding、webhook、slack等
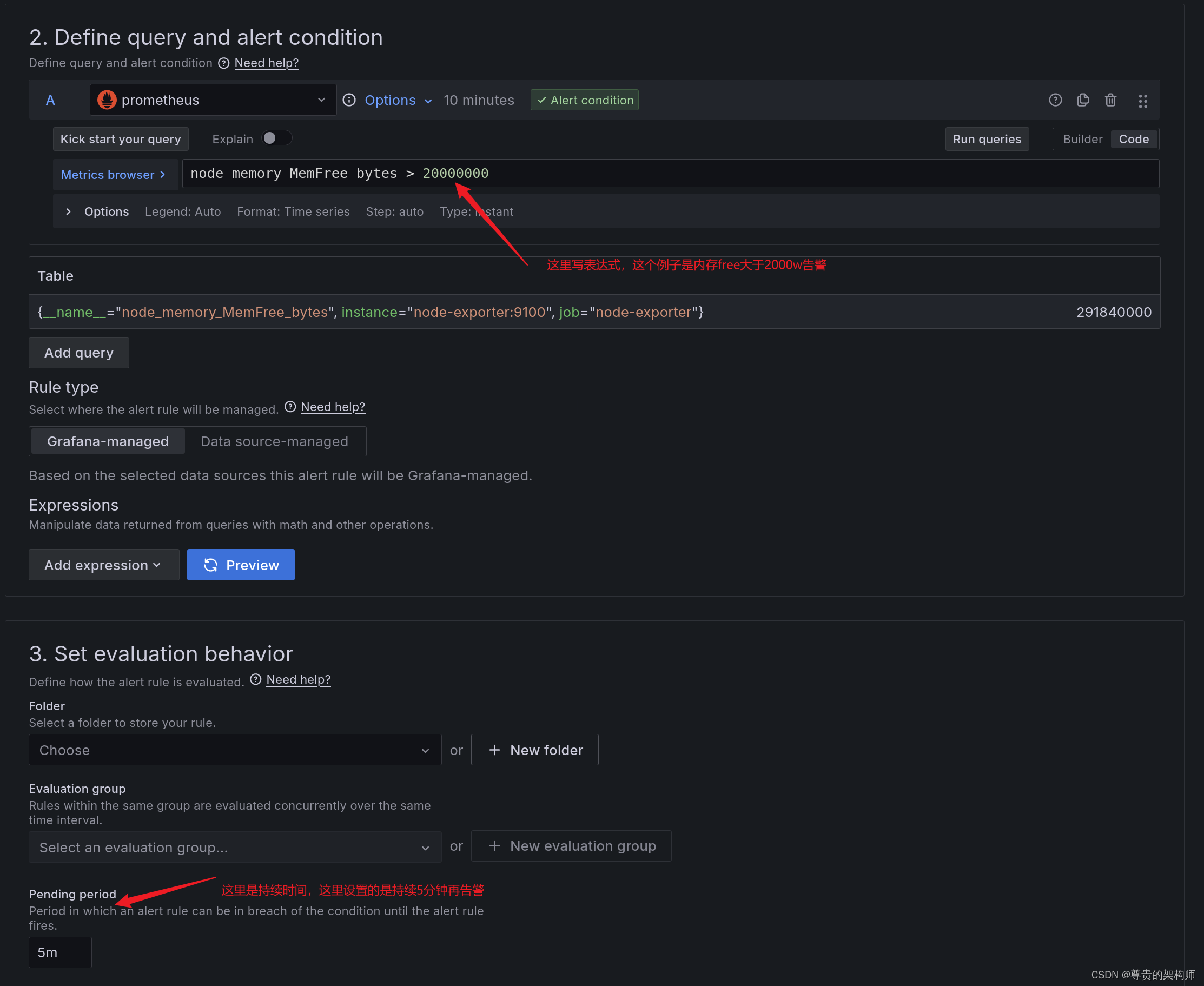
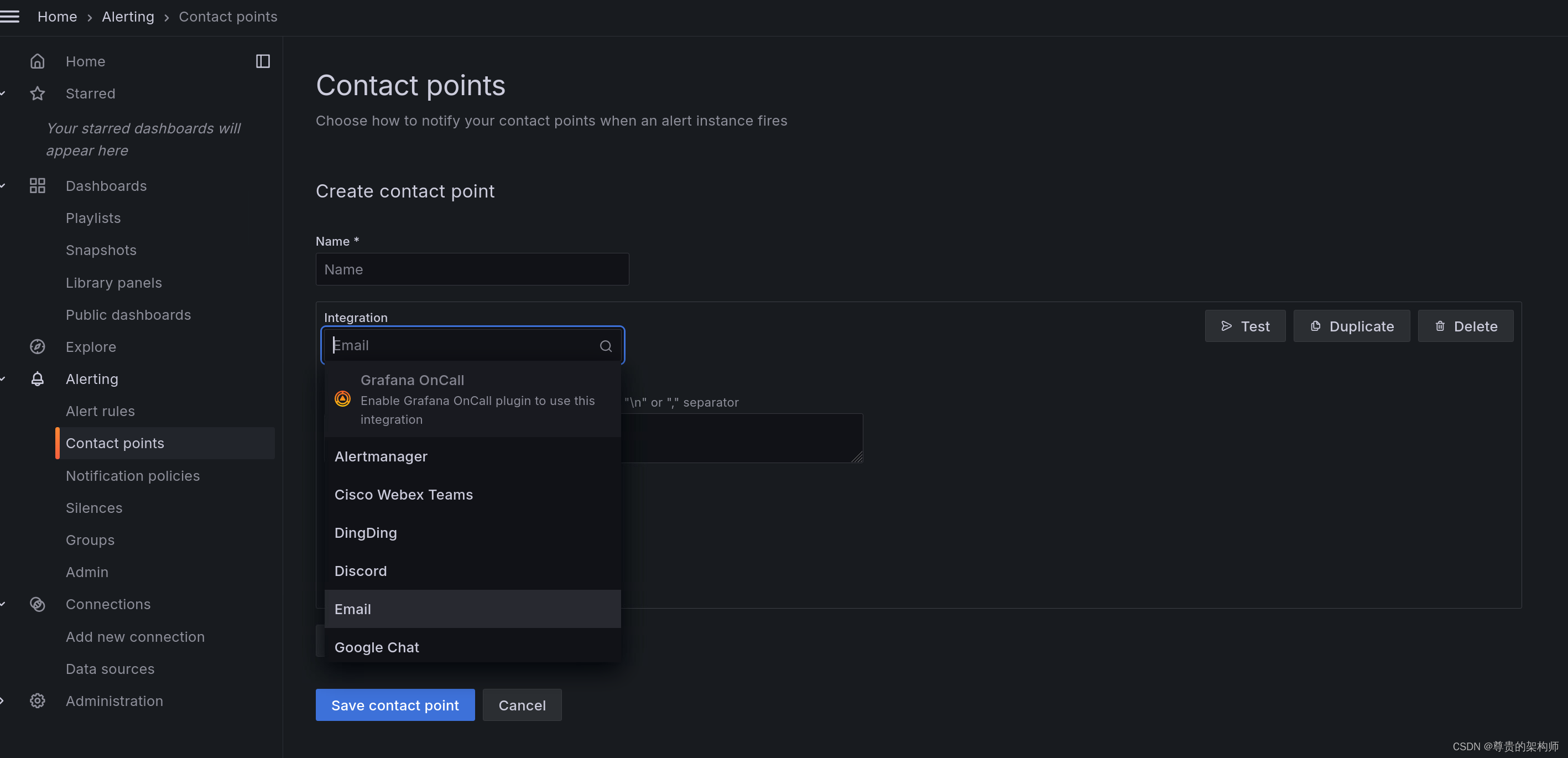 然后配置一下alert rules,简单来说就是在里面查询某个指标,达成条件了发出告警
然后配置一下alert rules,简单来说就是在里面查询某个指标,达成条件了发出告警