探索非关系型数据库:从入门到实践
1. 引言
1.1 非关系型数据库的崛起:背景与重要性
在过去的几十年里,关系型数据库(RDBMS)一直在数据存储和管理领域占据主导地位。其严谨的结构化数据模型以及强大的事务处理能力,使得它们在各种应用场景中得以广泛应用。然而,随着互联网的快速发展,数据的规模和复杂性不断增加,传统关系型数据库逐渐显露出一些局限性。这些局限性主要体现在以下几个方面:
-
扩展性问题:随着数据量的爆炸式增长,关系型数据库在扩展性方面遇到了瓶颈。虽然可以通过纵向扩展(即增加单台机器的处理能力)来提高性能,但这种方法成本高且有物理限制。而横向扩展(即通过增加更多的服务器进行分布式处理)在关系型数据库中实现起来非常复杂。
-
数据结构的灵活性不足:关系型数据库要求预先定义数据的模式(Schema),这对于一些数据结构灵活多变的应用场景来说,显得过于僵化。例如,社交网络、物联网等快速变化的数据类型和结构,使得关系型数据库难以快速响应业务需求的变化。
-
大数据处理能力的局限:关系型数据库在处理大规模数据时,性能和效率都受到限制。特别是在高并发读写和实时数据分析的场景中,传统关系型数据库难以满足需求。
基于上述背景,非关系型数据库(NoSQL)逐渐崭露头角。NoSQL数据库通过提供更高的扩展性、灵活的模式以及强大的大数据处理能力,成为了应对现代数据挑战的重要工具。NoSQL数据库的兴起不仅是技术发展的结果,更是市场需求的推动。它们为现代应用系统提供了更加灵活和高效的数据管理解决方案。
1.2 从关系型到非关系型的转变:需求驱动与技术选择
非关系型数据库的出现并不是偶然,而是由实际需求驱动以及技术选择共同促成的结果。我们可以从以下几个方面来理解这一转变:
-
需求驱动:
- 高并发处理:随着互联网和移动应用的普及,系统需要处理大量的并发访问。NoSQL数据库通过分布式架构,能够更好地支持高并发的读写操作。
- 大数据处理:在大数据时代,数据量巨大且种类繁多。NoSQL数据库能够处理海量数据,支持分布式存储和分布式计算,满足大数据处理的需求。
- 灵活的数据模型:许多现代应用(如社交网络、内容管理系统)需要处理结构化、半结构化和非结构化数据。NoSQL数据库提供了灵活的数据模型,允许数据模式动态变化。
-
技术选择:
- 分布式计算:NoSQL数据库通常采用分布式架构,能够通过添加节点来实现横向扩展,提高系统的整体性能和可靠性。
- 去中心化设计:许多NoSQL数据库采用去中心化设计,避免了单点故障的问题,提高了系统的可用性和容错性。
- 灵活的事务处理:虽然关系型数据库以其强大的ACID(原子性、一致性、隔离性、持久性)事务处理能力而著称,但在一些应用场景下,严格的ACID特性并非必须。NoSQL数据库提供了BASE(基本可用、软状态、最终一致性)模型,满足了高可用性和性能的需求。
举个具体的例子,Facebook的消息系统最初是基于关系型数据库构建的,但随着用户量的增加和消息量的爆炸式增长,系统面临严重的扩展性问题。为了解决这一问题,Facebook最终选择了Cassandra,一个分布式的NoSQL数据库。Cassandra通过其去中心化和高扩展性的架构,成功解决了消息系统的性能瓶颈问题。
总之,从关系型数据库到非关系型数据库的转变,是技术发展和市场需求共同作用的结果。通过理解这一转变的背景和驱动力,我们可以更好地掌握NoSQL数据库的使用场景和技术优势,为实际应用提供更为高效和灵活的数据管理方案。

2. 非关系型数据库的分类
2.1 键值存储:特点与常见用途
键值存储(Key-Value Store)是最简单、最基础的非关系型数据库类型之一。它们依赖于一个简单的键值对(key-value pair)结构,每个键(key)都是唯一的,通过键可以高效地存储和检索对应的值(value)。这种存储方式类似于传统的哈希表(hash table),但其设计更加复杂以适应分布式系统的需求。
特点
-
简单性:键值存储的基本结构非常简单,每个键对应唯一的值。这种简单性使得键值存储非常易于理解和使用。
-
高性能:由于键值存储的简单架构,它们通常能够提供非常高的读写性能。通过直接使用键进行查找,键值存储可以在常数时间内完成数据的检索和存储操作。
-
扩展性:大多数键值存储系统设计为分布式系统,可以方便地进行横向扩展(scale horizontally),即通过增加更多的服务器来提高存储容量和处理能力。这种扩展性对于处理大规模数据和高并发访问的应用场景非常重要。
-
灵活性:键值存储对存储的数据没有固定的格式,值可以是简单的字符串、数值,甚至是复杂的对象。这种灵活性使得键值存储适用于多种不同的应用场景。
-
持久性:许多键值存储系统提供数据持久化的功能,即使在系统故障后也能恢复数据。这种特性对于数据安全和可靠性至关重要。
常见用途
-
缓存:键值存储最常见的用途之一是作为缓存系统。例如,Redis作为一个键值存储,经常用于缓存数据库查询结果、会话信息和其他需要快速访问的数据。这种用法可以显著提高应用程序的响应速度并减轻后台数据库的负担。
-
会话管理:在Web应用中,键值存储可以用于存储用户会话数据。每个用户的会话数据可以通过用户ID作为键进行存储和检索,从而实现快速的会话管理。
-
配置管理:键值存储还可以用于存储应用程序的配置信息。例如,ETCD经常用于分布式系统的配置管理,提供了一个高可用的配置存储服务。
-
实时统计:许多应用程序需要实时统计和分析数据,例如网站访问量、用户行为数据等。键值存储可以高效地处理这种高频次的数据读写需求。
-
消息队列:一些键值存储系统可以实现简单的消息队列功能,通过使用列表和集合等数据结构来存储和处理消息。Redis的List和Pub/Sub功能便是此类用途的典型例子。
数学公式与解释
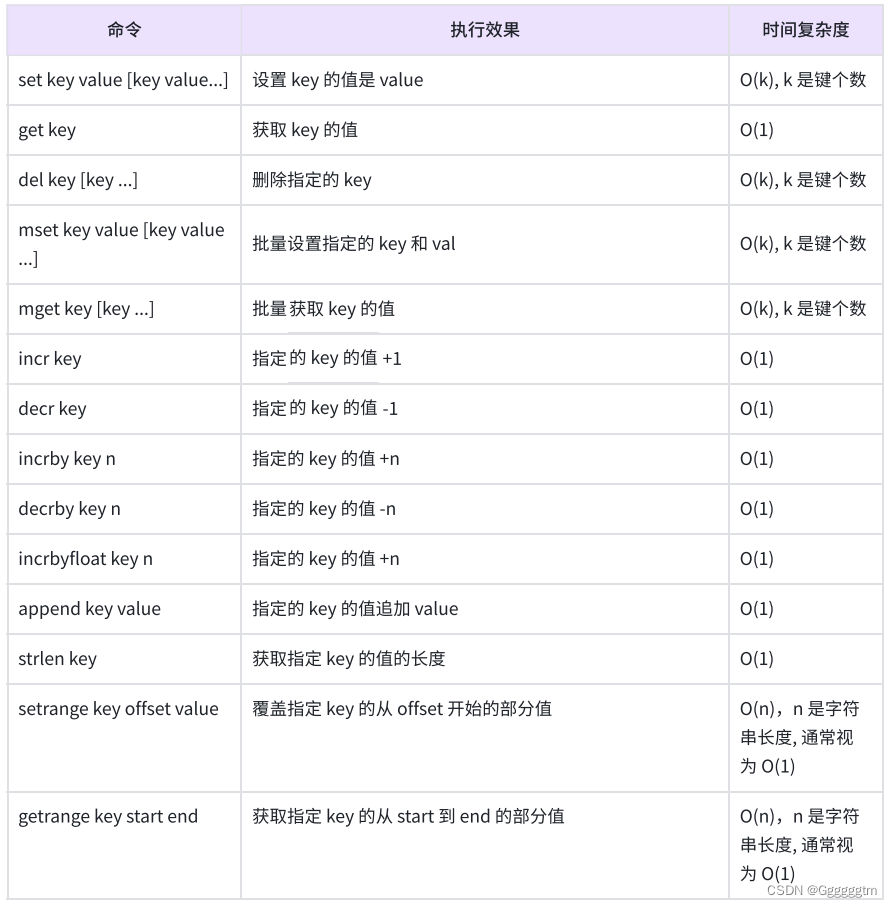
键值存储系统在理论上可以用哈希表来解释。哈希表最基本的操作是插入(insert)、删除(delete)和查找(search)。假设哈希函数为 h ( k ) h(k) h(k),其中 k k k 是键,哈希表的基本操作可以定义为:
-
插入操作:将键值对 ( k , v ) (k, v) (k,v) 插入到哈希表中,时间复杂度为 O ( 1 ) O(1) O(1)。
H [ h ( k ) ] = v H[h(k)] = v H[h(k)]=v
其中, H H H 是哈希表, h ( k ) h(k) h(k) 是键 k k k 对应的哈希值, v v v 是值。
-
删除操作:从哈希表中删除键 k k k 及其对应的值,时间复杂度为 O ( 1 ) O(1) O(1)。
H [ h ( k ) ] = null H[h(k)] = \text{null} H[h(k)]=null
-
查找操作:通过键 k k k 查找对应的值 v v v,时间复杂度为 O ( 1 ) O(1) O(1)。
v = H [ h ( k ) ] v = H[h(k)] v=H[h(k)]
在分布式键值存储系统中,数据往往需要分布在多个节点上进行存储和处理。常用的一种分布式哈希表(DHT,Distributed Hash Table)的算法是一致性哈希(consistent hashing)。一致性哈希通过将哈希空间映射到一个虚拟的环上来实现负载均衡和数据分布。
一致性哈希的主要公式为:
hash ( k ) m o d N \text{hash}(k) \mod N hash(k)modN
其中, hash ( k ) \text{hash}(k) hash(k) 是键 k k k 的哈希值, N N N 是总的节点数。通过这种方式,每个键都会被映射到一个特定的节点上,从而实现数据的分布式存储和处理。
举例说明
让我们通过一个具体的例子来说明键值存储的应用场景。假设我们正在开发一个电子商务网站,需要一个高效的缓存系统来存储用户的购物车信息,以提高网站的响应速度和用户体验。
我们选择使用Redis作为缓存系统,以下是使用Redis的Python代码示例:
- 插入购物车数据:
import redis
# 连接到本地Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 插入购物车数据
r.set('user:1001', '{"product_id": "12345", "quantity": 2}')
- 检索购物车数据:
import redis
# 连接到本地Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 检索购物车数据
cart = r.get('user:1001')
print(cart.decode('utf-8')) # 输出:{"product_id": "12345", "quantity": 2}
- 删除购物车数据:
import redis
# 连接到本地Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 删除购物车数据
r.delete('user:1001')
这段代码演示了如何使用Python与Redis进行连接并进行基本的插入、检索和删除操作。确保你的Redis服务器正在运行,并且相关连接参数(如主机名和端口号)是正确的。
通过这种方式,我们能够高效地管理每个用户的购物车数据,从而在用户访问购物车页面时提供快速的响应。在这个例子中,键值存储的高性能和灵活性得到了充分的体现。
总结来说,键值存储作为一种简单而高效的非关系型数据库,在多种应用场景中展现了其独特的优势。无论是缓存、会话管理、配置管理,还是实时统计与消息队列,键值存储都能够提供优秀的性能和灵活性,满足现代应用程序的需求。
2.2 文档存储:结构化与半结构化数据处理
在非关系型数据库的丰富谱系中,文档存储以其独特的灵活性和对结构化与半结构化数据的天然亲和力而脱颖而出。文档存储数据库,如MongoDB,允许存储和检索文档集合,这些文档通常以JSON或BSON格式表示,它们是键值对的集合,但具有层次结构和嵌套的能力。这种数据模型非常适合那些数据结构多变、需要快速迭代和灵活查询的应用场景。
2.2.1 实例:MongoDB 代码示例与应用场景
让我们深入探讨MongoDB,这是一个广泛使用的文档存储数据库。MongoDB的数据模型是基于文档的,这意味着数据被组织成类似JSON的文档,这些文档可以包含复杂的嵌套结构。这种模型的一个关键优势是它能够自然地映射到许多应用程序的数据结构,从而简化了数据模型设计和应用程序开发。
Python代码示例:
from pymongo import MongoClient
# 连接到本地MongoDB服务器
client = MongoClient('mongodb://localhost:27017/')
# 选择数据库和集合
db = client['mydb']
collection = db['users']
# 要插入的文档
my_document = { "name": "John", "age": 30, "city": "New York" }
# 插入文档
result = collection.insert_one(my_document)
# 输出插入的文档ID
print("Document inserted with ID:", result.inserted_id)
# 关闭数据库连接
client.close()
在这个示例中,我们连接到本地MongoDB服务器,选择了一个名为“mydb”的数据库,并在“users”集合中插入了一个文档。这个文档包含了名字、年龄和城市信息。
应用场景:
文档存储数据库非常适合以下场景:
- 内容管理系统:由于内容通常具有复杂的结构,文档存储可以轻松处理各种内容类型和元数据。
- 实时分析系统:文档存储支持复杂的查询和聚合操作,非常适合实时数据分析。
- 日志和事件数据存储:日志和事件数据通常是半结构化的,文档存储可以灵活地存储这些数据。
数学模型与公式:
在文档存储中,数据的组织和查询往往涉及到集合论和逻辑运算。例如,我们可以使用集合论中的交集、并集和差集来描述文档集合之间的关系。在MongoDB中,聚合框架允许我们使用这些概念来处理数据。
例如,如果我们有两个集合A和B,我们可以使用以下公式来描述它们的交集:
A ∩ B = { x ∣ x ∈ A and x ∈ B } A \cap B = \{x | x \in A \text{ and } x \in B\} A∩B={x∣x∈A and x∈B}
在MongoDB中,这可以通过$lookup操作符来实现,它允许我们在两个集合之间执行类似SQL的JOIN操作。
文档存储的灵活性也体现在它对数据模型的数学表达能力上。例如,我们可以使用树结构来表示文档的嵌套关系,其中每个节点代表一个文档或文档的一部分,而边表示键值对之间的关系。这种树结构可以用图论中的概念来描述,如节点的度、树的高度等。
在处理文档存储中的数据时,我们还可以利用概率论和统计学来优化查询性能和数据分布。例如,我们可以使用概率分布来估计文档在集合中的分布情况,从而优化索引和缓存策略。
文档存储数据库,以其对结构化和半结构化数据的强大支持,为现代应用程序提供了一个灵活而高效的数据存储解决方案。通过深入理解其背后的数学模型和算法,我们可以更好地利用这些数据库的潜力,构建出更加健壮和智能的应用系统。
2.3 宽列存储:列式存储的优势
在非关系型数据库的丰富谱系中,宽列存储(Wide-Column Stores)以其独特的数据组织方式和处理大规模数据集的能力而脱颖而出。这种存储模式,也被称为列式存储,与传统的关系型数据库中的行式存储形成鲜明对比。在列式存储中,数据按列而非行进行存储和处理,这一特性赋予了宽列存储一系列显著优势。
2.3.1 实例:Cassandra 代码示例与应用场景
列式存储的优势
-
高效的压缩和存储:列式存储允许对同一列的数据进行高效压缩,因为这些数据通常具有相似的类型和结构。例如,如果我们考虑一个存储用户年龄的数据库,所有年龄值都可以使用相同的压缩算法进行处理,从而减少存储空间的需求。
压缩率 = 原始数据大小 − 压缩后数据大小 原始数据大小 × 100 % \text{压缩率} = \frac{\text{原始数据大小} - \text{压缩后数据大小}}{\text{原始数据大小}} \times 100\% 压缩率=原始数据大小原始数据大小−压缩后数据大小×100%
在实际应用中,这种压缩可以显著降低存储成本,尤其是在处理大量数据时。
-
快速的列查询:由于数据按列存储,查询特定列的数据时,数据库只需读取相关的列,而不是整个表。这种读取方式减少了I/O操作,提高了查询速度。例如,如果我们只需要查询用户的年龄分布,列式存储可以直接访问年龄列,而不必加载其他无关列的数据。
-
并行处理能力:列式存储支持对不同列的并行处理,这对于执行复杂的分析查询尤为重要。在数学上,这可以通过矩阵运算的并行化来体现,其中每个列可以被视为矩阵的一列,并行处理可以显著加快计算速度。
并行处理时间 = 总计算量 并行处理单元数 \text{并行处理时间} = \frac{\text{总计算量}}{\text{并行处理单元数}} 并行处理时间=并行处理单元数总计算量
Cassandra:宽列存储的典范
Apache Cassandra是一个高度可扩展的分布式数据库,它专为处理大量数据而设计,广泛应用于需要高可用性和无单点故障的场景。Cassandra的设计灵感来源于Amazon的Dynamo和Google的Bigtable,它结合了这两个系统的特点,提供了宽列存储的能力。
代码示例
以下是一个使用Cassandra的Python代码示例,展示了如何创建表、插入数据和执行查询:
from cassandra.cluster import Cluster
from cassandra.auth import PlainTextAuthProvider
# 连接到Cassandra集群
auth_provider = PlainTextAuthProvider(username='cassandra', password='cassandra')
cluster = Cluster(['127.0.0.1'], port=9042, auth_provider=auth_provider)
session = cluster.connect()
# 创建一个表
session.execute("""
CREATE TABLE IF NOT EXISTS example.users (
user_id int PRIMARY KEY,
first_name text,
last_name text,
age int
)
""")
# 插入数据
session.execute("""
INSERT INTO example.users (user_id, first_name, last_name, age)
VALUES (%s, %s, %s, %s)
""", (1, 'John', 'Doe', 30))
# 查询数据
result = session.execute("SELECT * FROM example.users WHERE age > 25")
for row in result:
print(f"User ID: {row.user_id}, Name: {row.first_name} {row.last_name}, Age: {row.age}")
应用场景
Cassandra的宽列存储特性使其非常适合以下场景:
- 大数据分析:当需要对大量数据进行分析时,Cassandra的高效压缩和快速列查询能力可以显著提升性能。
- 实时应用:对于需要实时数据处理的应用,如在线游戏或实时分析系统,Cassandra的高可用性和低延迟特性非常适用。
- 写密集型应用:Cassandra优化了写操作,使其成为写入频繁的应用程序的理想选择,如日志记录或传感器数据收集。
在探索非关系型数据库的旅程中,宽列存储提供了一种强大的工具,它不仅改变了我们处理数据的方式,也为应对现代数据挑战提供了新的解决方案。
2.4 图数据库:关系数据的高效处理
在非关系型数据库的丰富谱系中,图数据库以其独特的数据模型和处理复杂关系的能力而脱颖而出。图数据库的核心思想是将数据存储为节点(Nodes)和边(Edges),其中节点代表实体,边代表实体间的关系。这种模型特别适合于那些数据间关系错综复杂的场景,如社交网络分析、推荐系统、网络拓扑结构等。
2.4.1 实例:Neo4j 代码示例与应用场景
Neo4j 是图数据库领域的佼佼者,它提供了一个原生的图存储和处理引擎,使得图遍历和查询变得异常高效。在Neo4j中,节点和边都可以拥有属性,这为数据的丰富性和表达力提供了可能。
应用场景
以社交网络为例,我们可以使用Neo4j来构建一个社交网络图。每个用户是一个节点,用户之间的关注关系是一条边。通过图数据库,我们可以轻松地查询某个用户的所有朋友,或者找出两个用户之间的最短关系链。
代码示例
在Neo4j中,我们可以使用Cypher查询语言来操作图数据。以下是一个简单的创建节点和关系的示例:
CREATE (user1:User {name: 'Alice'})-[:FOLLOWS]->(user2:User {name: 'Bob'})
这条语句创建了两个用户节点Alice和Bob,并建立了一个FOLLOWS关系。
数学公式
在图数据库中,图的数学模型可以用一个二元组G=(V, E)来表示,其中V是节点的集合,E是边的集合。每条边e∈E可以表示为一个有序或无序的节点对(u, v),其中u, v∈V。在有向图中,边(u, v)和(v, u)代表不同的关系;而在无向图中,它们是相同的。
G = ( V , E ) E = { ( u , v ) ∣ u , v ∈ V } G = (V, E) \\ E = \{(u, v) | u, v \in V\} G=(V,E)E={(u,v)∣u,v∈V}
图遍历算法
图数据库的高效处理能力很大程度上依赖于其遍历算法。例如,最短路径问题可以通过Dijkstra算法或Floyd-Warshall算法来解决。这些算法在图数据库中的实现通常会被优化以适应图的特定存储结构。
性能优化
Neo4j通过索引和缓存机制来优化图遍历的性能。例如,对于节点的属性,Neo4j会创建索引以加速查询。此外,Neo4j还支持事务处理,确保数据的一致性和完整性。
总结
图数据库如Neo4j提供了一种强大的工具来处理复杂的关系数据。通过节点和边的直观模型,以及高效的图遍历算法,图数据库在处理社交网络、推荐系统等领域展现出了其独特的优势。随着数据关系复杂性的增加,图数据库的应用前景将更加广阔。
3. NoSQL数据库的核心原理和优势
3.1 CAP定理:一致性、可用性、分区容错性
CAP定理,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance),是分布式系统领域的一个重要理论。它由Eric Brewer在2000年提出,并在2002年由Seth Gilbert和Nancy Lynch形式化证明。通过理解CAP定理,可以更好地设计和选择适合的分布式系统架构,特别是在NoSQL数据库的选择和实现中。
3.1.1 一致性(Consistency)
一致性指的是在分布式系统中,所有节点在同一时间对同一请求返回相同的数据结果。即,不管用户连接到哪个节点,系统所返回的数据是一致的。形式化地讲,对于一个分布式数据库,如果系统在某个时刻接收到某个读请求,系统返回的结果必须是最新写入的数据或是一个错误。
一致性的数学表达可以用以下公式表示:
∀ r ∈ R , ∃ w ∈ W : Order ( w ) < Order ( r ) ⇒ Read ( r ) = Write ( w ) \forall r \in R, \exists w \in W: \text{Order}(w) < \text{Order}(r) \Rightarrow \text{Read}(r) = \text{Write}(w) ∀r∈R,∃w∈W:Order(w)<Order(r)⇒Read(r)=Write(w)
这里,® 表示读操作集合,(W) 表示写操作集合, ( Order ( x ) ) (\text{Order}(x)) (Order(x)) 表示操作 (x) 的顺序, ( Read ( r ) ) (\text{Read}(r)) (Read(r)) 表示读操作 ® 的结果, ( Write ( w ) ) (\text{Write}(w)) (Write(w)) 表示写操作 (w) 的内容。公式的意思是,对于每一个读操作 ®,必须存在一个写操作 (w),读操作 ® 的结果等于写操作 (w) 的结果。
例子:假设有一个分布式系统,包含三个节点A、B和C。如果一个用户在节点A上写入数据X=1,而另一个用户在写入之后立即从节点B读取数据X,所读取到的结果必须是X=1,这样才能保证一致性。
3.1.2 可用性(Availability)
可用性指的是系统在任何时候都能响应用户的请求,即使有某些节点出现故障或无法通信,系统仍然能够对每一个请求给出一个合理的回应。
可用性的数学表达可以用以下公式表示:
∀ t ≥ 0 , ∀ p ∈ P : Respond ( p , t ) = true \forall t \ge 0, \forall p \in P: \text{Respond}(p, t) = \text{true} ∀t≥0,∀p∈P:Respond(p,t)=true
这里,(P) 表示请求的集合, ( Respond ( p , t ) ) (\text{Respond}(p, t)) (Respond(p,t)) 表示系统在时间 (t) 对请求 (p) 的响应状态。公式的意思是,对于每一个请求 (p),系统在任意时间 (t) 都能够做出响应。
例子:假设系统中存在节点A和B,如果节点A由于某些原因不可用,但用户的请求仍然能被节点B处理并给予响应,那么系统是可用的。
3.1.3 分区容错性(Partition Tolerance)
分区容错性指的是分布式系统能够继续运行并保持其特性,即使在网络分区(网络故障导致部分节点之间无法通信)的情况下。分区容错性是分布式系统的一个重要特性,因为网络分区在大型分布式系统中是不可避免的。
分区容错性的数学表达可以用以下公式表示:
∀ p ∈ P , ∀ t ≥ 0 : Partition ( p , t ) ⇒ SystemOperational ( t ) = true \forall p \in P, \forall t \ge 0: \text{Partition}(p, t) \Rightarrow \text{SystemOperational}(t) = \text{true} ∀p∈P,∀t≥0:Partition(p,t)⇒SystemOperational(t)=true
这里,(P) 表示分区的集合, ( Partition ( p , t ) ) (\text{Partition}(p, t)) (Partition(p,t)) 表示在时间 (t) 发生的分区 (p), ( SystemOperational ( t ) ) (\text{SystemOperational}(t)) (SystemOperational(t)) 表示系统在时间 (t) 的运行状态。公式的意思是,对于每一个分区 (p),在任意时间 (t) 系统都能够保持运行。
例子:假设分布式系统中的节点A和B之间的网络出现了故障,导致它们无法相互通信。如果系统中的其余节点仍能够正常工作并处理请求,那么系统是具有分区容错性的。
3.1.4 CAP定理的权衡与三角形展示
CAP定理指出,在一个分布式系统中,不可能同时完全满足一致性、可用性和分区容错性这三个特性。具体来说,系统最多只能同时满足其中的两个特性,而必须牺牲第三个特性。这意味着在系统设计和实现过程中,开发者需要在一致性、可用性和分区容错性之间做出权衡。
可以通过CAP定理三角形图形化展示这一点:
一致性(C)
/ \
/ \
/ \
可用性(A) - 分区容错性(P)
在实际应用中,不同的NoSQL数据库会根据具体需求在CAP三角形中选择不同的平衡点。例如:
- Cassandra:优先考虑可用性和分区容错性,牺牲了一致性。这使得Cassandra在分布式环境中表现出色,但可能会出现短暂的不一致。
- MongoDB:在默认配置下,也优先考虑可用性和分区容错性,但通过某些配置选项可以调整以更好地满足一致性需求。
- HBase:优先考虑一致性和分区容错性,牺牲了可用性。这意味着在网络分区发生时,系统可能会拒绝某些请求以保证数据的一致性。
总结来说,CAP定理为分布式系统的设计和实现提供了一个重要的理论框架,理解并合理应用CAP定理,可以帮助我们在构建NoSQL数据库系统时做出更明智的选择和优化方案。
3.2 可扩展性:横向扩展 vs 纵向扩展
在当今数据驱动的世界中,数据库的可扩展性是决定其能否成功应对大量数据和高并发请求的关键因素。可扩展性主要包括两种策略:横向扩展(Scaling Out)和纵向扩展(Scaling Up)。这两种方法各有优缺点,选择哪种策略需要根据具体应用和系统需求来决定。
横向扩展(Scaling Out)
横向扩展,即通过增加更多的服务器(节点)来扩展系统的能力。这种方法通常用于分布式系统,如许多NoSQL数据库,来处理大规模数据和高并发请求。
概念解释
横向扩展的核心在于将数据和负载分布在多个节点上,这些节点共同工作,以提高系统的处理能力和存储容量。这种方法的最大优势在于其理论上可以无限扩展。将新节点添加到集群中,系统的处理能力和存储空间将成比例增加。
数学公式
假设我们有一个系统,其处理能力用C表示,每个节点的处理能力为( C_n ),则系统的总处理能力
(
C
t
o
t
a
l
)
( C_{total} )
(Ctotal) 可表示为:
C
t
o
t
a
l
=
N
×
C
n
C_{total} = N \times C_n
Ctotal=N×Cn
其中,N是节点的数量。
举例说明
例如,使用Cassandra数据库时,可以通过添加更多的Cassandra节点来增加系统的处理能力和存储容量。假设每个节点可以处理1000个请求/秒,并且存储1TB的数据。如果我们需要处理10000个请求/秒并存储10TB的数据,则只需增加到10个节点即可满足要求。
# 在Cassandra中添加新节点
nodetool addnode --cluster myCluster --node <new_node_ip>
纵向扩展(Scaling Up)
纵向扩展,即通过提升单个服务器(节点)的硬件配置来增强系统的能力。通常,这意味着增加CPU核心数、内存容量、存储速度等硬件资源。
概念解释
纵向扩展的核心在于提升单个节点的性能,通过升级硬件,使其能够处理更多的数据和更高的并发请求。这种方法的优势在于其简单性,不需要对现有系统架构进行大规模改动。但其缺点在于存在硬件升级的上限,且成本较高。
数学公式
假设一个节点的处理能力为( C_n ),通过升级硬件将其处理能力提升到 ( C_n’ ),则系统的总处理能力
(
C
t
o
t
a
l
)
( C_{total} )
(Ctotal) 可表示为:
C
t
o
t
a
l
=
N
×
C
n
′
C_{total} = N \times C_n'
Ctotal=N×Cn′
其中,N是节点的数量,通常N=1,即只提升单个节点的性能。
举例说明
例如,使用Redis数据库时,可以通过升级Redis服务器的硬件来增强其处理能力。如果原来的服务器拥有4个CPU核心和16GB内存,可以处理5000个请求/秒。通过将服务器升级到8个CPU核心和64GB内存,处理能力可以增加到20000个请求/秒。
# 升级服务器硬件配置
sudo shutdown -r now
# 在新配置下重新启动Redis服务
sudo systemctl start redis
横向扩展 vs 纵向扩展:如何选择
选择横向扩展还是纵向扩展,取决于系统的具体需求和限制。
横向扩展的优势
- 高可用性和容错性:通过分布式架构,故障节点不会导致系统整体崩溃,数据和负载可在其他节点上继续处理。
- 理论上的无限扩展:可以通过添加更多节点来不断提升系统容量。
- 灵活的资源利用:可以根据需要动态增加或减少节点。
横向扩展的劣势
- 系统复杂性增加:需要考虑数据分片、网络通信和一致性问题。
- 网络延迟和带宽瓶颈:节点间的数据同步和协调可能导致延迟和带宽问题。
纵向扩展的优势
- 实现简单:不需要修改系统架构,只需升级硬件即可。
- 单节点性能提升显著:通过提升硬件配置,可以显著提高单节点的处理能力。
纵向扩展的劣势
- 存在硬件上限:硬件配置有物理限制,无法无限制扩展。
- 成本高:高性能硬件成本昂贵,且随着硬件不断升级,花费急剧增加。
综合考虑
在实际应用中,横向扩展和纵向扩展常常结合使用。初期可以通过纵向扩展来快速提升系统性能,当单节点性能无法满足需求时,再考虑通过横向扩展来提升整体系统的处理能力。
例如,在一个初创企业的初期阶段,使用纵向扩展可以快速应对业务增长。但当业务规模进一步扩大,用户量和数据量快速增长时,横向扩展可以提供更好的弹性和高可用性。
总之,选择横向扩展还是纵向扩展,需要根据具体的业务需求、系统架构、预算和未来的发展规划来决定。无论选择哪种策略,目标都是确保系统能够稳定、高效地处理不断增长的数据和请求量。
3.3 灵活的数据模型:与关系型数据库的对比
在探讨非关系型数据库(NoSQL)的众多优势时,其灵活的数据模型无疑是最引人注目的特点之一。与传统的关系型数据库(RDBMS)相比,NoSQL数据库提供了更加自由和多样的数据组织方式,这使得它们能够更好地适应现代应用中复杂多变的数据需求。
关系型数据库的局限性
关系型数据库,如MySQL、Oracle和SQL Server,采用固定的表结构,数据以行和列的形式存储。这种结构要求在数据存储之前定义好所有的表、字段以及它们之间的关系。虽然这种模型在处理结构化数据时表现出色,但在面对以下情况时却显得力不从心:
- 数据模式变更:在应用开发过程中,数据模型可能需要频繁变更。在关系型数据库中,这种变更通常意味着复杂的DDL(数据定义语言)操作和潜在的数据迁移。
- 非结构化数据:随着大数据时代的到来,非结构化和半结构化数据变得越来越普遍。关系型数据库在处理这类数据时效率低下,因为它们需要将非结构化数据映射到固定的表结构中。
- 大规模数据集:关系型数据库在处理大规模数据集时可能会遇到性能瓶颈,尤其是在需要进行复杂查询和分析时。
NoSQL数据库的灵活性
NoSQL数据库通过提供更加灵活的数据模型来解决上述问题。以下是几种常见的NoSQL数据模型及其特点:
- 键值存储:数据以键值对的形式存储,其中键是唯一的,而值可以是任意类型的数据。这种模型非常简单,适用于存储简单的数据结构,如缓存数据。
- 文档存储:数据以文档的形式存储,通常是JSON或BSON格式。文档可以包含复杂的嵌套结构,这使得文档存储非常适合存储半结构化数据。
- 宽列存储:数据以列族的形式存储,每个列族包含多个列。这种模型适用于存储大量数据,并且可以高效地进行列级别的操作。
- 图数据库:数据以节点和边的形式存储,用于表示实体之间的关系。图数据库非常适合处理复杂的关系数据,如社交网络或推荐系统。
数学视角下的灵活性
从数学的角度来看,NoSQL数据库的灵活性可以被视为对数据结构的一种泛化。在关系型数据库中,数据结构通常是线性的,即数据以表格的形式组织,每个表可以被视为一个线性代数中的矩阵。而在NoSQL数据库中,数据结构可以是多维的、图状的,甚至是动态变化的。
例如,在文档存储中,一个文档可以被视为一个多维数组,其中每个元素可以是标量、数组或对象。这种结构可以用以下数学公式表示:
D = { d 1 , d 2 , . . . , d n } d i = { k 1 : v 1 , k 2 : v 2 , . . . , k m : v m } v j = { s , a , o } D = \{d_1, d_2, ..., d_n\} \\ d_i = \{k_1: v_1, k_2: v_2, ..., k_m: v_m\} \\ v_j = \{s, a, o\} D={d1,d2,...,dn}di={k1:v1,k2:v2,...,km:vm}vj={s,a,o}
其中, D D D 是文档集合, d i d_i di 是单个文档, k j k_j kj 是键, v j v_j vj 是值, s s s 是标量, a a a 是数组, o o o 是对象。
实例分析
让我们通过一个具体的例子来进一步说明NoSQL数据库的灵活性。假设我们正在构建一个博客平台,用户可以发布包含文本、图片和视频的博客文章。在关系型数据库中,我们可能需要创建多个表来存储这些数据,例如users、posts、images和videos表,并且需要定义复杂的关联关系。
而在NoSQL数据库中,我们可以使用文档存储来简化这个过程。每个博客文章可以作为一个文档存储,文档中包含文章的标题、内容、作者信息以及嵌套的图片和视频对象。这种结构不仅更加直观,而且可以轻松地适应未来可能出现的新数据类型,如音频或3D模型。
结论
NoSQL数据库的灵活数据模型为现代应用提供了强大的支持,使得它们能够更好地适应快速变化的数据需求。通过提供更加自由和多样的数据组织方式,NoSQL数据库不仅简化了数据存储和管理的复杂性,还提高了数据处理的效率和灵活性。随着大数据和云计算的不断发展,NoSQL数据库的这种灵活性将变得越来越重要,它们将继续在未来的数据处理领域扮演关键角色。

4. 入门级NoSQL系统分析
4.1 Redis:内存数据库与缓存应用
Redis(Remote Dictionary Server)是一个开源的内存数据库,广泛用于缓存和消息队列等应用场景。它以其卓越的性能和丰富的数据结构支持而著称,使其成为许多高性能应用的首选。本章节将深入探讨Redis的关键特性、使用场景、以及实例代码,帮助读者全面了解和应用Redis。
4.1.1 关键特性与使用场景
关键特性
-
内存存储:
Redis将数据全部存储在内存中,读取和写入速度极快。这使得Redis非常适合需要快速响应的应用场景,如实时数据分析、会话管理等。 -
丰富的数据结构:
Redis不仅支持简单的键值对,还支持多种复杂的数据结构,包括字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)、哈希(Hash)以及位图(Bitmaps)、HyperLogLog等。这些数据结构使Redis在处理不同类型的数据时更加灵活和高效。 -
持久化:
虽然Redis是内存数据库,但它提供了多种持久化机制以确保数据的持久性。主要的持久化方式有RDB快照和AOF(Append-Only File)日志。RDB会在特定的时间间隔生成数据快照,而AOF则记录每次写操作,这两者可以结合使用以平衡持久性和性能。 -
高可用性和分布式架构:
Redis具有内置的主从复制功能,可以实现读写分离和数据冗余。同时,Redis的Sentinel机制可以监控主服务器的运行状态,当主服务器出现故障时,Sentinel会自动进行故障转移。Redis Cluster进一步支持分片存储,实现水平扩展。 -
Lua脚本:
Redis支持通过Lua脚本实现原子操作,避免了多步骤操作中的数据不一致问题。Lua脚本在Redis中执行时是原子的,可以确保在执行过程中数据的完整性。
使用场景
-
缓存:
由于Redis的高性能特点,它被广泛应用于缓存层,显著减少数据库的访问压力。例如,在Web应用中,可以将频繁访问的数据缓存到Redis中,从而提高响应速度。 -
消息队列:
Redis的List结构可以用作简单且高效的消息队列,支持高级特性如发布/订阅(Pub/Sub)模式。这使得Redis成为构建实时消息系统和任务队列的理想选择。 -
会话存储:
Redis的内存存储特性和支持过期时间的功能,使其成为会话存储的绝佳选择。在用户登录验证和会话管理中,Redis可以快速存储和检索会话数据。 -
实时数据分析:
由于Redis的快速读写能力和对复杂数据结构的支持,它在实时数据分析和统计应用中表现出色。例如,使用HyperLogLog进行独特值统计,使用Sorted Set进行排行榜维护等。
4.1.2 实例代码:基本操作与高级功能示例
基本操作
以下是一些基本的Redis操作示例,展示了如何使用不同的数据结构。
import redis
# 连接到本地的Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 字符串操作
r.set('key1', 'value1')
print(r.get('key1')) # 输出:b'value1'
# 列表操作
r.lpush('mylist', 1, 2, 3)
print(r.lrange('mylist', 0, -1)) # 输出:[b'3', b'2', b'1']
# 哈希操作
r.hset('myhash', 'field1', 'value1')
print(r.hget('myhash', 'field1')) # 输出:b'value1'
# 集合操作
r.sadd('myset', 1, 2, 3)
print(r.smembers('myset')) # 输出:{b'1', b'2', b'3'}
# 有序集合操作
r.zadd('myzset', {'one': 1, 'two': 2})
print(r.zrange('myzset', 0, -1, withscores=True)) # 输出:[(b'one', 1.0), (b'two', 2.0)]
高级功能
接下来,我们展示一些Redis的高级功能,如持久化、Lua脚本和分布式实现。
- 持久化操作:
# 手动触发RDB快照
r.save()
# 手动触发AOF重写
r.bgrewriteaof()
- Lua脚本:
# 定义一个简单的Lua脚本,原子性地增加一个键的值
lua_script = """
return redis.call('incrby', KEYS[1], ARGV[1])
"""
incr_by_script = r.register_script(lua_script)
result = incr_by_script(keys=['counter'], args=[5])
print(result) # 输出:5(假设counter初始值为0)
- 分布式操作:
# 配置和使用Redis Sentinel实现高可用性
# 假定已经配置好Sentinel实例
sentinel = redis.sentinel.Sentinel([('localhost', 26379)], socket_timeout=0.1)
master = sentinel.master_for('mymaster', socket_timeout=0.1)
slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
# 写入操作通过主节点
master.set('foo', 'bar')
# 读取操作可以通过从节点
print(slave.get('foo')) # 输出:b'bar'
4.1.3 数学公式
在Redis的使用中,特别是在性能调优和容量规划时,数学公式也起到了重要作用。例如,内存使用的估算可以通过以下公式进行:
Total Memory Usage = ∑ ( Key Size + Value Size + Overhead ) \text{Total Memory Usage} = \sum (\text{Key Size} + \text{Value Size} + \text{Overhead}) Total Memory Usage=∑(Key Size+Value Size+Overhead)
其中,键和值的大小可以通过实际数据的类型和内容来估算,而开销部分则取决于Redis底层实现的具体数据结构。假设有N个键,每个键的平均大小为K bytes,每个值的平均大小为V bytes,开销为O bytes,那么总内存使用可以表示为:
Total Memory Usage = N × ( K + V + O ) \text{Total Memory Usage} = N \times (K + V + O) Total Memory Usage=N×(K+V+O)
例如,如果我们有100万个键,每个键的大小为50 bytes,每个值的大小为100 bytes,开销为32 bytes,那么总内存使用为:
Total Memory Usage = 1 0 6 × ( 50 + 100 + 32 ) = 182 × 1 0 6 bytes = 182 MB \text{Total Memory Usage} = 10^6 \times (50 + 100 + 32) = 182 \times 10^6 \text{ bytes} = 182 \text{ MB} Total Memory Usage=106×(50+100+32)=182×106 bytes=182 MB
4.1.4 总结
Redis作为一种高性能的内存数据库和缓存系统,其关键特性和丰富的功能使其在实际应用中表现出色。通过本章节的讲解和代码示例,读者可以更好地理解和应用Redis,以提高系统的性能和灵活性。无论是在缓存、消息队列、会话存储还是实时数据分析等场景中,Redis都能够提供高效的解决方案。通过合理的持久化和分布式实现,Redis还能够满足高可用性和扩展性的需求。
4.2 MongoDB:文档存储的多功能数据库
4.2.1 关键特性与使用场景
MongoDB,作为一款领先的文档型NoSQL数据库,以其灵活的数据模型和强大的查询能力在现代数据存储领域占据了一席之地。它的核心特性包括:
- 灵活的文档模型:MongoDB使用BSON(Binary JSON)格式存储数据,支持嵌套文档和数组,这种结构化的数据模型为复杂数据结构的存储提供了极大的便利。
- 高性能:MongoDB支持索引,包括单键索引、复合索引、地理空间索引等,这极大地提升了查询效率。
- 高可用性:通过副本集(Replica Set)机制,MongoDB能够实现数据的自动故障转移和恢复。
- 水平扩展:通过分片(Sharding)技术,MongoDB可以实现数据在多个服务器上的分布式存储,从而支持大规模数据集和高并发访问。
MongoDB的使用场景广泛,特别适合以下情况:
- 内容管理和发布系统:MongoDB的文档模型非常适合存储和查询内容丰富的数据,如博客文章、评论等。
- 实时分析系统:MongoDB的聚合框架和索引支持可以用于实时数据分析和处理。
- 移动应用和游戏:MongoDB的灵活性和高性能使其成为移动应用和游戏后端存储的理想选择。
4.2.2 实例代码:CRUD操作与聚合框架示例
在MongoDB中,基本的CRUD(创建、读取、更新、删除)操作非常直观。以下是一些基本的操作示例:
- 创建(Create):
from pymongo import MongoClient
# 连接MongoDB
client = MongoClient('mongodb://localhost:27017/')
# 选择数据库
db = client['test_database']
# 选择集合(类似于关系数据库中的表)
collection = db['test_collection']
# 插入单个文档
collection.insert_one({"name": "John", "age": 30})
# 插入多个文档
collection.insert_many([
{"name": "Jane", "age": 28},
{"name": "Doe", "age": 32}
])
- 读取(Read):
# 查询所有文档
for doc in collection.find():
print(doc)
# 查询特定条件的文档
for doc in collection.find({"age": {"$gt": 30}}):
print(doc)
- 更新(Update):
# 更新单个文档
collection.update_one({"name": "John"}, {"$set": {"age": 31}})
# 更新多个文档
collection.update_many({"age": {"$gte": 30}}, {"$inc": {"age": 1}})
- 删除(Delete):
# 删除单个文档
collection.delete_one({"name": "John"})
# 删除多个文档
collection.delete_many({"age": {"$lt": 30}})
对于聚合操作,Python代码如下:
# 计算每个年龄的人数
pipeline = [
{"$group": {"_id": "$age", "count": {"$sum": 1}}},
{"$sort": {"count": -1}}
]
for result in collection.aggregate(pipeline):
print(result)
在这个聚合操作中,我们定义了一个聚合管道,首先使用$group操作符按年龄分组,并计算每个年龄的人数。然后使用$sort操作符按人数降序排序。
以上代码展示了如何在Python中使用pymongo库与MongoDB进行交互,执行基本的CRUD操作以及聚合操作。这些操作可以帮助你管理和分析存储在MongoDB中的数据。
MongoDB作为一款多功能的数据库,不仅支持基础的CRUD操作,还提供了丰富的聚合工具和数学计算能力,使其成为处理复杂数据结构的强大工具。无论是小型应用还是大型企业级系统,MongoDB都能提供高效、灵活的数据存储解决方案。
4.3 Cassandra:分布式数据库的强大力量
4.3.1 关键特性与使用场景
Apache Cassandra,一个开源的分布式NoSQL数据库系统,以其强大的可扩展性和高可用性而闻名。它设计用于处理大量数据分布在多个服务器上,提供无单点故障的高效数据存储解决方案。Cassandra的架构灵感来源于Google的Bigtable和Amazon的DynamoDB,它结合了两者的优点,形成了一个独特的数据模型和分布式架构。
关键特性:
- 分布式架构:Cassandra是一个完全分布式的系统,数据可以在集群中的任何节点上进行读写,没有单点瓶颈。
- 无中心节点:Cassandra没有主节点或从节点之分,每个节点都是对等的,这消除了单点故障的风险。
- 可调的一致性:Cassandra允许用户根据应用需求调整一致性级别,从强一致性到最终一致性。
- 高性能写入:Cassandra优化了写入操作,通常将数据写入提交日志,然后写入内存表,这使得写入操作非常快速。
- 灵活的数据模型:Cassandra的数据模型类似于宽列存储,允许用户定义列族和列,提供了极大的灵活性。
使用场景:
Cassandra非常适合以下场景:
- 写密集型应用:如实时分析、日志处理等,需要高吞吐量的写入操作。
- 地理分布式数据存储:Cassandra的分布式特性使其非常适合在全球多个数据中心存储数据。
- 需要高可用性和容错性的应用:Cassandra的无单点故障设计保证了系统的高可用性。
- 大数据应用:Cassandra能够处理PB级别的数据,非常适合大数据存储和分析。
4.3.2 实例代码:数据建模与复杂查询示例
在Cassandra中,数据建模是关键,因为它直接影响到查询的性能。Cassandra的数据模型包括键空间(Keyspace)、列族(Column Family)、行(Row)和列(Column)。
数据建模示例:
假设我们有一个社交媒体应用,需要存储用户的状态更新。我们可以创建一个名为status_updates的列族,其中每行代表一个用户的状态更新,列代表状态更新的内容和时间戳。
CREATE KEYSPACE IF NOT EXISTS SocialNetwork
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3};
USE SocialNetwork;
CREATE TABLE IF NOT EXISTS status_updates (
user_id int,
update_time timestamp,
status_message text,
PRIMARY KEY (user_id, update_time)
);
复杂查询示例:
在Cassandra中,查询通常是基于主键的。如果我们想要获取某个用户最近的状态更新,我们可以使用以下查询:
SELECT * FROM status_updates
WHERE user_id = 123
ORDER BY update_time DESC
LIMIT 10;
Cassandra的查询语言CQL(Cassandra Query Language)与SQL类似,但有一些限制,因为它是为了优化分布式查询而设计的。
数学公式:
在Cassandra中,数据分布通常基于一致性哈希算法。一致性哈希是一种特殊的哈希方法,它允许添加或删除节点时最小化数据的重新分布。一致性哈希的数学表达如下:
H ( k ) = k m o d ( n + 2 32 ) H(k) = k \mod (n + 2^{32}) H(k)=kmod(n+232)
其中, H ( k ) H(k) H(k)是键 k k k的哈希值, n n n是节点的数量。这个公式确保了即使节点数量变化,也只有少量的键需要重新分配到新的节点。
Cassandra的强大之处在于它的分布式能力和灵活的数据模型,这使得它成为处理大规模、高可用性数据存储需求的理想选择。通过深入理解其关键特性和数据建模技巧,开发人员可以充分利用Cassandra的潜力,构建出高性能的分布式应用。
4.4 Neo4j:图数据库的强大表达力
图数据库作为非关系型数据库中的一种,以其独特的数据结构和高效的关系查询能力,成为大数据和复杂网络分析中的重要工具。Neo4j作为图数据库的佼佼者,不仅在学术研究和企业应用中广泛使用,还因其强大的表达力和易用性而备受推崇。
4.4.1 关键特性与使用场景
1. 图数据库的核心概念
图数据库以图形结构存储数据,图由节点(Nodes)、关系(Relationships)和属性(Properties)构成:
- 节点(Nodes):表示实体或对象,例如用户、产品等。
- 关系(Relationships):表示节点之间的连接,例如用户购买了产品。
- 属性(Properties):节点或关系的详细信息,例如用户名或购买日期。
这种数据模型非常适合表示和处理复杂关系数据,例如社交网络、推荐系统等。
2. Cypher查询语言
Neo4j使用Cypher作为其查询语言。Cypher是一种声明式查询语言,专门用于图数据查询,语法直观、易学。例如,下面的Cypher查询语句用于查找“用户A”的所有朋友:
MATCH (a:User {name: '用户A'})-[:FRIEND]->(friend)
RETURN friend.name
3. 高效的关系处理
传统关系型数据库在处理多层嵌套关系时性能往往不佳,而Neo4j通过内存中的图遍历和索引优化,实现了常数时间复杂度的关系查询。例如,查找两个人之间的最短路径:
MATCH p=shortestPath((user1:User {name: '用户A'})-[*]-(user2:User {name: '用户B'}))
RETURN p
4. 可视化工具
Neo4j附带强大的可视化工具,可以直观地展示数据和关系,便于分析和理解。例如,对于社交网络分析,用户可以在图形界面中直接看到用户与朋友之间的关系链。
使用场景
Neo4j的应用场景非常广泛,以下是一些典型应用:
- 社交网络分析:分析用户之间的关系和互动,推荐好友或内容。
- 推荐系统:利用用户行为和兴趣数据,推荐商品或内容。
- 网络安全:检测和分析网络攻击路径,识别潜在威胁。
- 知识图谱:构建和查询复杂的知识图谱,支持智能搜索和问答。
4.4.2 实例代码:节点与关系操作示例
1. 创建节点
首先,创建两个用户节点:
CREATE (userA:User {name: '用户A', age: 29})
CREATE (userB:User {name: '用户B', age: 34})
这段代码创建了两个标签为User的节点,并赋予它们不同的属性。
2. 创建关系
接下来,创建用户A和用户B之间的朋友关系:
MATCH (a:User {name: '用户A'}), (b:User {name: '用户B'})
CREATE (a)-[:FRIEND]->(b)
这段代码匹配到User标签下名称为用户A和用户B的节点,并在它们之间创建了一条FRIEND关系。
3. 查询节点和关系
查询特定用户的所有朋友:
MATCH (a:User {name: '用户A'})-[:FRIEND]->(friend)
RETURN friend.name, friend.age
这段代码返回了用户A所有朋友的姓名和年龄。
4. 更新节点属性
更新用户B的年龄:
MATCH (b:User {name: '用户B'})
SET b.age = 35
RETURN b
这段代码找到User标签下名称为用户B的节点,将其年龄更新为35。
5. 删除节点和关系
删除用户A和用户B之间的朋友关系:
MATCH (a:User {name: '用户A'})-[r:FRIEND]->(b:User {name: '用户B'})
DELETE r
这段代码删除了用户A和用户B之间的FRIEND关系。
删除用户A节点:
MATCH (a:User {name: '用户A'})
DELETE a
这段代码删除了名称为用户A的节点。
数学基础:图遍历和最短路径算法
图数据库的高效查询基于图遍历和最短路径算法,如深度优先搜索(DFS)、广度优先搜索(BFS)和Dijkstra算法。
深度优先搜索(DFS)
DFS是一种用于遍历或搜索图的算法,从起始节点出发,沿着每一个分支走到底,然后再回溯。其递归定义如下:
DFS ( G , v ) = { visit ( v ) if v is unvisited for each w adjacent to v DFS ( G , w ) \text{DFS}(G, v) = \begin{cases} \text{visit}(v) & \text{if } v \text{ is unvisited} \\ \text{for each } w \text{ adjacent to } v & \text{DFS}(G, w) \end{cases} DFS(G,v)={visit(v)for each w adjacent to vif v is unvisitedDFS(G,w)
广度优先搜索(BFS)
BFS使用队列实现,从起始节点开始,依次访问所有相邻节点,然后再访问这些相邻节点的相邻节点。其定义如下:
BFS ( G , v ) = queue ← v while queue is not empty current ← dequeue visit current enqueue all unvisited neighbors of current \text{BFS}(G, v) = \text{queue} \leftarrow v \\ \text{while queue is not empty} \\ \quad \text{current} \leftarrow \text{dequeue} \\ \quad \text{visit current} \\ \quad \text{enqueue all unvisited neighbors of current} BFS(G,v)=queue←vwhile queue is not emptycurrent←dequeuevisit currentenqueue all unvisited neighbors of current
Dijkstra算法
Dijkstra算法用于计算加权图中从单个源点到其他节点的最短路径。其基本思想是每次选择当前最短路径的节点进行扩展。其伪代码如下:
Dijkstra ( G , s ) = { initialize distances and priority queue while queue is not empty u ← dequeue for each neighbor v of u alt ← distance [ u ] + weight ( u , v ) if alt < distance [ v ] distance [ v ] ← alt update priority queue \text{Dijkstra}(G, s) = \begin{cases} \text{initialize distances and priority queue} \\ \text{while queue is not empty} \\ \quad u \leftarrow \text{dequeue} \\ \quad \text{for each neighbor } v \text{ of } u \\ \quad \quad \text{alt} \leftarrow \text{distance}[u] + \text{weight}(u, v) \\ \quad \quad \text{if alt } < \text{distance}[v] \\ \quad \quad \quad \text{distance}[v] \leftarrow \text{alt} \\ \quad \quad \quad \text{update priority queue} \end{cases} Dijkstra(G,s)=⎩ ⎨ ⎧initialize distances and priority queuewhile queue is not emptyu←dequeuefor each neighbor v of ualt←distance[u]+weight(u,v)if alt <distance[v]distance[v]←altupdate priority queue
通过这些算法,Neo4j实现了对复杂关系数据的高效查询,使得图数据库在处理社交网络、推荐系统和知识图谱等应用中表现出色。
Neo4j的强大功能不仅体现在对图数据的高效存储和查询上,还在于其灵活的Cypher查询语言和丰富的可视化工具。对于需要处理复杂关系和网络结构的数据应用,Neo4j无疑是一个强有力的选择。
5. 实战指南
5.1 选择合适的NoSQL数据库:需求分析与技术选型
在浩瀚的NoSQL数据库海洋中,如何挑选出那颗最璀璨的明珠,以满足我们项目的需求?这不仅是一场技术的较量,更是一次智慧的考验。让我们一起深入探讨,如何根据需求分析来做出明智的技术选型。
5.1.1 具体场景分析:如何选择合适的NoSQL数据库
首先,我们需要对项目的需求进行细致的分析。这包括但不限于数据模型、访问模式、性能要求、可扩展性、数据一致性以及成本预算。每一种NoSQL数据库都有其独特的优势和局限性,因此,了解每种数据库的特点是做出正确选择的关键。
数据模型:
- 键值存储(如Redis)适用于简单的键值对数据,它们提供了快速的读写速度,适合缓存和会话存储。
- 文档存储(如MongoDB)支持复杂的数据结构,如JSON文档,适合需要灵活数据模型的应用。
- 宽列存储(如Cassandra)擅长处理大量数据,尤其是写密集型的工作负载,适合日志和时间序列数据。
- 图数据库(如Neo4j)专注于处理复杂的关系网络,适合社交网络、推荐系统和知识图谱。
访问模式:
- 如果应用需要频繁的读取操作,那么选择一个读取性能优异的数据库至关重要。
- 对于写入密集型的应用,需要考虑数据库的写入性能和数据持久化策略。
性能要求:
- 性能通常与CAP定理中的C(一致性)、A(可用性)和P(分区容错性)有关。根据应用对这三者的不同要求,选择合适的数据库。
可扩展性:
- 横向扩展(水平扩展)意味着通过增加更多的节点来提高系统的处理能力,而纵向扩展(垂直扩展)则是通过增强单个节点的硬件配置来实现。NoSQL数据库通常更易于横向扩展。
数据一致性:
- 根据应用对数据一致性的要求,选择支持强一致性、弱一致性或最终一致性的数据库。
成本预算:
- 考虑数据库的许可费用、硬件成本、维护成本以及开发和运维人员的培训成本。
在数学上,我们可以将选择NoSQL数据库的过程视为一个多目标优化问题,其中目标函数包括性能、成本、可扩展性等。我们可以使用线性加权和法、目标规划法等数学方法来辅助决策。例如,我们可以为每个目标分配一个权重,然后计算每个数据库的总得分,从而做出决策。
总得分 = w 1 × 性能 + w 2 × 成本 + w 3 × 可扩展性 + ⋯ \text{总得分} = w_1 \times \text{性能} + w_2 \times \text{成本} + w_3 \times \text{可扩展性} + \cdots 总得分=w1×性能+w2×成本+w3×可扩展性+⋯
其中, w 1 , w 2 , w 3 , ⋯ w_1, w_2, w_3, \cdots w1,w2,w3,⋯ 是各个目标的权重,它们的和为1。
在实际操作中,我们还需要考虑团队的技术栈、经验以及社区支持等因素。选择一个团队熟悉且有良好社区支持的数据库,可以大大降低项目的风险和成本。
最后,不要忘记进行实际的测试和评估。通过构建原型系统,我们可以更直观地感受不同数据库的性能和适用性,从而做出最终的选择。
在这个过程中,我们不仅是在选择一个数据库,更是在为我们的项目选择一个可靠的伙伴。每一步的深思熟虑,都将为项目的成功奠定坚实的基础。让我们携手前行,在NoSQL的世界中,找到那片属于我们的星辰大海。
5.2 使用NoSQL数据库的最佳实践:性能优化与数据一致性
在NoSQL数据库的世界里,性能优化和数据一致性是两个至关重要的议题。它们如同数据库的双翼,缺一不可,共同支撑着系统的稳定与高效。在本节中,我们将深入探讨如何在这两个方面达到最佳实践,并通过具体的Python代码示例来展示这些策略的实际应用。
5.2.1 性能调优与数据一致性策略
性能调优:
性能调优的核心在于最大化数据库的吞吐量和最小化响应时间。以下是一些关键的性能调优策略:
- 索引优化:在NoSQL数据库中,索引是提高查询性能的关键。例如,在MongoDB中,我们可以使用
create_index()方法来创建索引:
from pymongo import MongoClient, ASCENDING
client = MongoClient()
db = client['mydatabase']
collection = db['mycollection']
# 创建索引
collection.create_index([('username', ASCENDING)], unique=True)
-
读写分离:通过将读操作和写操作分离到不同的节点上,可以减少单个节点的压力,提高整体性能。在Cassandra中,可以通过配置不同的
read_request_timeout_in_ms和write_request_timeout_in_ms来优化读写性能。 -
数据分片:分片是将数据分布在多个节点上的过程,可以提高系统的可扩展性和性能。在Redis中,可以通过
redis-trib.rb工具来实现数据分片。
数据一致性策略:
在分布式系统中,数据一致性是一个复杂的问题。CAP定理告诉我们,在分布式系统中,我们只能在一致性(C)、可用性(A)和分区容错性(P)中选择两个。以下是一些常见的数据一致性策略:
-
最终一致性:在最终一致性模型中,系统保证如果不再有写操作,所有读操作最终都会返回最新的值。这是许多NoSQL数据库(如Cassandra)的默认一致性模型。
-
强一致性:强一致性要求任何时刻,所有节点都能读取到最新的数据。在Redis中,可以通过配置主从复制来实现强一致性。
-
一致性哈希:一致性哈希是一种特殊的哈希方式,它可以在节点加入或离开时,最小化数据迁移的数量。在Cassandra中,数据分布就是基于一致性哈希算法。
数学公式在数据一致性中也有其应用,例如,在分布式系统中,我们经常使用Paxos或Raft算法来保证数据的一致性。这些算法通过一系列的投票和确认过程来确保所有节点上的数据最终是一致的。
一致性 = { 强一致性 , 如果所有节点都能立即读取到最新数据 最终一致性 , 如果所有节点最终都会读取到最新数据 \text{一致性} = \begin{cases} \text{强一致性}, & \text{如果所有节点都能立即读取到最新数据} \\ \text{最终一致性}, & \text{如果所有节点最终都会读取到最新数据} \\ \end{cases} 一致性={强一致性,最终一致性,如果所有节点都能立即读取到最新数据如果所有节点最终都会读取到最新数据
在实际应用中,我们需要根据具体的业务需求和系统特点来选择合适的性能优化和数据一致性策略。通过不断的测试和调整,我们可以找到最适合自己系统的最佳实践。
在NoSQL数据库的旅途中,性能优化和数据一致性是我们永恒的追求。它们如同星辰指引着我们前行,让我们在数据的海洋中航行得更远、更稳。让我们继续探索,不断优化,让NoSQL数据库发挥出它们最大的潜力。
6. 可视化图表
6.1 NoSQL系统对比图:性能、扩展性、灵活性等方面的对比
在现代数据管理中,选择合适的NoSQL数据库系统对于确保应用程序的性能和灵活性至关重要。本文将通过对比几种主流NoSQL数据库系统的性能、扩展性和灵活性,帮助您更好地理解它们各自的特点和优势。
性能
性能方面的对比主要考虑以下几个指标:
- 读写延迟(Latency):读写操作的响应时间。
- 吞吐量(Throughput):单位时间内系统能处理的请求数量。
- 数据一致性(Data Consistency):确保数据在多个副本之间的一致性。
以下图表展示了Redis、MongoDB、Cassandra和Neo4j在这些方面的一些性能对比数据:
| 系统 | 读延迟 | 写延迟 | 吞吐量(写) | 吞吐量(读) | 一致性模式 |
|---|---|---|---|---|---|
| Redis | 极低 | 极低 | 高 | 高 | 最终一致性 |
| MongoDB | 中等 | 中等 | 中等 | 中等 | 可配置一致性模式 |
| Cassandra | 较低 | 较低 | 非常高 | 高 | 可配置一致性模式 |
| Neo4j | 低 | 低 | 中等 | 中等 | 强一致性 |
扩展性
扩展性是NoSQL数据库系统的核心优势之一,主要体现在以下方面:
- 水平扩展(Horizontal Scalability):通过增加更多的服务器来提升系统的处理能力。
- 垂直扩展(Vertical Scalability):通过增加单个服务器的硬件资源来提升系统的处理能力。
以下是几种NoSQL数据库系统在扩展性方面的能力对比:
| 系统 | 水平扩展 | 垂直扩展 |
|---|---|---|
| Redis | 支持 | 支持 |
| MongoDB | 支持 | 支持 |
| Cassandra | 强支持 | 支持 |
| Neo4j | 支持 | 支持 |
Cassandra在水平扩展方面表现尤为出色,得益于其分布式架构设计,可以轻松扩展到数百甚至上千个节点。
灵活性
灵活性衡量的是数据库在数据模型和查询能力上的适应性。以下是几种NoSQL数据库系统在灵活性方面的对比:
- 数据模型灵活性:支持不同类型的数据结构。
- 查询语言:支持复杂查询的能力。
| 系统 | 数据模型灵活性 | 查询语言 |
|---|---|---|
| Redis | 高 | 简单命令 |
| MongoDB | 非常高 | 丰富的查询语言 |
| Cassandra | 高 | CQL(类SQL) |
| Neo4j | 非常高 | Cypher |
MongoDB和Neo4j在数据模型的灵活性上表现突出,前者适合处理文档数据,后者则擅长处理图数据。
数学公式与性能评估
性能评估中常用的数学公式包括响应时间的计算和吞吐量的计算。
响应时间
响应时间通常可以用以下公式表示:
T r e s p o n s e = T s e r v i c e + T w a i t T_{response} = T_{service} + T_{wait} Tresponse=Tservice+Twait
其中, ( T r e s p o n s e ) ( T_{response} ) (Tresponse) 是总响应时间, ( T s e r v i c e ) ( T_{service} ) (Tservice) 是服务时间, ( T w a i t ) ( T_{wait} ) (Twait) 是等待时间。
吞吐量
吞吐量可以通过以下公式计算:
T h r o u g h p u t = N u m b e r o f R e q u e s t s T i m e Throughput = \frac{Number\ of\ Requests}{Time} Throughput=TimeNumber of Requests
假设在一个小时内处理了3600个请求,那么吞吐量就是:
T h r o u g h p u t = 3600 3600 s e c o n d s = 1 r e q u e s t / s e c o n d Throughput = \frac{3600}{3600\ seconds} = 1\ request/second Throughput=3600 seconds3600=1 request/second
示例代码
以下是如何使用Python代码进行简单的性能测试,以比较Redis和MongoDB的写入性能:
import time
import redis
import pymongo
# Redis 性能测试
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
start_time = time.time()
for i in range(10000):
redis_client.set(f'key_{i}', f'value_{i}')
end_time = time.time()
print(f"Redis 写入时间: {end_time - start_time} 秒")
# MongoDB 性能测试
mongo_client = pymongo.MongoClient("mongodb://localhost:27017/")
db = mongo_client["test_db"]
collection = db["test_collection"]
start_time = time.time()
for i in range(10000):
collection.insert_one({"key": f'key_{i}', "value": f'value_{i}'})
end_time = time.time()
print(f"MongoDB 写入时间: {end_time - start_time} 秒")
通过这段代码,我们可以清晰地比较Redis和MongoDB在写入操作上的性能差异。
结论
通过对比Redis、MongoDB、Cassandra和Neo4j的性能、扩展性和灵活性,我们可以得出以下结论:
- Redis:适用于需要极低延迟和高吞吐量的场景,如缓存和实时数据处理。
- MongoDB:适合处理需要高度灵活的数据模型和复杂查询的场景,如内容管理系统和实时分析。
- Cassandra:在需要大规模数据存储和高可用性要求的分布式系统中表现出色,如电商网站和物联网。
- Neo4j:适用于复杂关系数据的处理,如社交网络和推荐系统。
选择合适的NoSQL数据库系统应基于具体需求和应用场景,综合考虑性能、扩展性和灵活性,才能最大化地发挥其优势。
6.2 数据模型示意图:不同类型NoSQL数据库的数据模型展示
在深入探讨NoSQL数据库的奇妙世界时,我们不得不提及它们的核心——数据模型。每一种NoSQL数据库都有其独特的数据模型,这些模型决定了数据的存储方式、查询效率以及应用场景。在本节中,我们将通过示意图来直观展示不同类型NoSQL数据库的数据模型,并辅以详细的解释和数学公式的推导,以期为您揭开这些模型的神秘面纱。
键值存储(Key-Value Stores)
键值存储是最简单的NoSQL数据模型,它将数据存储为键值对,其中键是唯一的。这种模型的核心思想可以用一个简单的数学表达式来表示:
K V = { ( k 1 , v 1 ) , ( k 2 , v 2 ) , . . . , ( k n , v n ) } KV = \{(k_1, v_1), (k_2, v_2), ..., (k_n, v_n)\} KV={(k1,v1),(k2,v2),...,(kn,vn)}
其中, k i k_i ki 是键, v i v_i vi 是对应的值。键值存储的示意图如下:
```mermaid
graph LR
A[Key] --> B((Value))
在这个模型中,查询操作非常高效,因为它只需要通过键来索引值。例如,在Redis中,我们可以使用Python代码来存储和检索数据:
```python
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
r.set('name', 'Alice') # 存储键值对
print(r.get('name')) # 检索值
文档存储(Document Stores)
文档存储模型以文档为单位存储数据,文档通常是半结构化的,如JSON或BSON格式。这种模型的数学表达式可以表示为:
D = { d 1 , d 2 , . . . , d n } D = \{d_1, d_2, ..., d_n\} D={d1,d2,...,dn}
其中, d i d_i di 是一个文档,它包含了一系列的键值对。文档存储的示意图如下:
```mermaid
graph LR
A[Document] --> B((Field1: Value1))
A --> C((Field2: Value2))
A --> D((...))
在MongoDB中,我们可以使用Python代码来操作文档:
```python
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['mydatabase']
collection = db['customers']
doc = { "name": "John", "address": "Highway 37" }
collection.insert_one(doc) # 插入文档
宽列存储(Wide-Column Stores)
宽列存储模型以列族的形式存储数据,每个列族包含多个列。这种模型的数学表达式可以表示为:
C = { c 1 , c 2 , . . . , c n } C = \{c_1, c_2, ..., c_n\} C={c1,c2,...,cn}
其中, c i c_i ci 是一个列族,它包含了一系列的列。宽列存储的示意图如下:
```mermaid
graph LR
A[Row Key] --> B[Column Family 1]
B --> C((Column 1: Value1))
B --> D((Column 2: Value2))
A --> E[Column Family 2]
E --> F((Column 1: Value1))
E --> G((Column 2: Value2))
在Cassandra中,我们可以使用Python代码来操作列族:
```python
from cassandra.cluster import Cluster
cluster = Cluster(['127.0.0.1'])
session = cluster.connect()
session.execute("""
CREATE TABLE users (
user_id int PRIMARY KEY,
first_name text,
last_name text
)
""")
session.execute("INSERT INTO users (user_id, first_name, last_name) VALUES (%s, %s, %s)", (1, 'John', 'Doe'))
图数据库(Graph Databases)
图数据库模型以图的形式存储数据,图由节点和边组成。这种模型的数学表达式可以表示为:
G = ( V , E ) G = (V, E) G=(V,E)
其中, V V V 是节点的集合, E E E 是边的集合。图数据库的示意图如下:
```mermaid
graph LR
A[Node1] -->|Edge1| B[Node2]
B -->|Edge2| C[Node3]
在Neo4j中,我们可以使用Python代码来操作图:
```python
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
with driver.session() as session:
session.run("CREATE (a:Person {name: $name})", name="Alice")
session.run("MATCH (a:Person) WHERE a.name = 'Alice' CREATE (a)-[:KNOWS]->(:Person {name: 'Bob'})", name="Bob")
通过这些示意图和代码示例,我们可以更清晰地理解不同类型NoSQL数据库的数据模型。每种模型都有其独特的优势和适用场景,理解它们将帮助我们在实际应用中做出更合适的选择。

7. 深入学习与参考资料
7.1 推荐阅读
在深入了解非关系型数据库的道路上,书籍是不可或缺的伴侣。以下是一些值得推荐的书籍,它们涵盖了NoSQL数据库的理论基础、实际应用以及最佳实践:
-
《NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence》 by Martin Fowler and Pramod J. Sadalage:这本书由软件开发领域的知名专家Martin Fowler撰写,提供了对NoSQL数据库的简洁而深入的介绍,适合初学者和有经验的开发者。
-
《Cassandra: The Definitive Guide》 by Jeff Carpenter and Eben Hewitt:对于想要深入了解Cassandra的读者来说,这本书是权威的指南。它详细介绍了Cassandra的设计原则、数据模型以及如何有效地使用它。
-
《MongoDB: The Definitive Guide》 by Shannon Bradshaw, Eoin Brazil, and Kristina Chodorow:MongoDB的官方指南,涵盖了从基础到高级的所有内容,是MongoDB用户必备的参考书。
-
《Graph Databases》 by Ian Robinson, Jim Webber, and Emil Eifrem:这本书专注于图数据库,特别是Neo4j,它解释了图数据库的理论和实践,以及它们在解决复杂关系问题中的应用。
7.2 在线资源
互联网是一个宝库,提供了大量的学习资源。以下是一些在线资源,可以帮助你进一步学习和探索NoSQL数据库:
-
官方文档:每个NoSQL数据库都有其官方文档,这是最权威和最全面的学习资源。例如,Redis、MongoDB、Cassandra和Neo4j的官方文档都提供了详细的指南和API参考。
-
社区论坛:Stack Overflow、Reddit以及各个数据库的官方论坛都是提问和分享经验的好地方。在这些社区中,你可以找到许多实际问题的解决方案。
-
学习平台:Coursera、edX、Udemy等在线学习平台提供了许多关于NoSQL数据库的课程。这些课程通常由行业专家授课,结合了理论和实践。
-
GitHub:GitHub上有许多开源项目和示例代码,你可以通过阅读和运行这些代码来学习NoSQL数据库的实际应用。
-
博客和文章:许多技术博客和在线杂志,如Medium、InfoQ和DZone,经常发布关于NoSQL数据库的最新文章和教程。
7.3 数学公式与推导
在深入学习NoSQL数据库时,你可能会遇到一些数学概念,尤其是在处理分布式系统和数据一致性时。例如,CAP定理中的数学基础涉及到概率论和图论。以下是一个简单的数学公式,用于描述分布式系统中的一致性问题:
P ( 一致性 ) = 1 N ∑ i = 1 N P ( 节 点 i 一致 ) P(一致性) = \frac{1}{N} \sum_{i=1}^{N} P(节点_i 一致) P(一致性)=N1i=1∑NP(节点i一致)
这个公式表示,一个分布式系统的一致性概率是所有节点一致性概率的平均值。在实际应用中,这个公式可以帮助我们理解如何通过增加节点数量或提高单个节点的一致性来提高整个系统的一致性。
7.4 示例代码
以下是一个使用Python操作Redis的简单示例代码:
import redis
# 连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
# 设置键值对
r.set('name', 'Alice')
# 获取键值
name = r.get('name')
print(name) # 输出: b'Alice'
这段代码展示了如何使用Python的redis库连接到Redis服务器,并执行基本的键值对操作。通过这样的示例,你可以开始实践并深入理解NoSQL数据库的操作。
通过这些推荐阅读、在线资源、数学公式和示例代码,你可以进一步扩展你的知识,并在实际应用中更加熟练地使用非关系型数据库。记住,实践是学习的关键,不断地尝试和探索将帮助你成为NoSQL数据库的专家。

8. 结论
8.1 总结:非关系型数据库的应用与未来发展趋势
在本文的探索旅程中,我们深入了解了非关系型数据库(NoSQL)的多样性和强大功能。从键值存储到文档存储,从宽列存储到图数据库,每一种类型都以其独特的方式满足了现代应用对数据存储和处理的需求。我们看到了Redis如何以其出色的性能成为缓存和消息队列的首选,MongoDB如何以其灵活的文档模型适应了快速变化的数据结构,Cassandra如何以其分布式架构处理大规模数据集,以及Neo4j如何以其图数据模型揭示了复杂关系网络的奥秘。
我们探讨了NoSQL数据库的核心原理,包括CAP定理的权衡,可扩展性的实现,以及灵活数据模型的优势。这些原理不仅是理论上的探讨,更是指导我们选择和使用NoSQL数据库的实践指南。通过实例代码和应用场景的分析,我们展示了如何将这些理论应用于实际问题解决中。
在实战指南部分,我们提供了一系列的策略和技巧,帮助读者在面对具体业务需求时,能够做出明智的技术选型,并在使用NoSQL数据库时实现性能优化和数据一致性。我们还通过可视化图表,直观地展示了不同NoSQL系统的对比和数据模型的差异,为读者提供了更全面的视角。
8.2 展望:NoSQL数据库在大数据与云计算中的前景
随着大数据和云计算技术的不断发展,NoSQL数据库的应用前景愈发广阔。在大数据领域,NoSQL数据库以其高可扩展性和灵活的数据模型,能够有效地处理和分析海量数据,为数据科学家和分析师提供了强大的工具。在云计算环境中,NoSQL数据库的分布式特性使其能够无缝地与云服务集成,为用户提供弹性的数据存储解决方案。
未来,我们可以预见NoSQL数据库将继续在以下几个方面发展:
-
性能优化:随着硬件技术的进步,NoSQL数据库将能够利用更先进的存储和计算资源,进一步提升性能。
-
功能增强:为了满足更复杂的应用需求,NoSQL数据库将不断增加新的功能,如更强大的查询语言、更丰富的数据类型支持等。
-
集成与互操作性:NoSQL数据库将更好地与其他系统和工具集成,提供更流畅的数据工作流。
-
安全性与合规性:随着数据保护法规的日益严格,NoSQL数据库将加强数据安全和隐私保护功能,确保合规性。
-
智能化:结合人工智能和机器学习技术,NoSQL数据库将能够提供更智能的数据分析和决策支持。
总之,NoSQL数据库作为现代数据处理的重要组成部分,将继续在技术创新和应用实践中发挥其不可替代的作用。我们期待着NoSQL数据库在未来的发展,以及它们将如何继续推动数据驱动时代的进步,为我们的数字生活带来更多的可能性。