场景:
义务阶段为何要进行分层分班,这一点大家都心知肚明。你说的答案是不是也和我的一样:为了实行分层教学。"人往高处走,水往低处流",每次确定分班后,总会有一些学生向上调整,当然也会有一些不按常规行事的到B层次班级,这些变动的学生通常被称为"留学生"。留学生最终会回到原来的班级评价,导致每次考试后评价需要重新调整。手动操作时,一不留神,有些学生可能会调整时遗漏,这样会影响原班级评价,则需要重新调整,耗时且让人烦躁。第二个问题是,有时每个班级总会有几名学生不适合学习,评价时常根据总分降序排列,将末尾几位同学删除。由于班级众多,每班删除的人数不等,手动操作耗时费力,还易出错。第三个问题是, 有部分同学不参与评估时会将其班号标识为一个不存在的班号例如“0”或“最大班号+1" ,比如最大班号为15,则将不参与评估的标为16,最后将这些学生删除,方式很多。今天我们还是让gpt-4o来解决这些个问题。
今天不知什么原因,gpt-4o不是很稳定,常常异常退出!!!
以前是用Excel中的=VLOOKUP()根据ID来匹配的,现在只是用python模拟人工处理的过程。
表结构:
成绩表结构

对照表结构

提示词
"""
学生成绩表和对照表是两个独立的工作簿,
学生成绩表,表字段为:(准考证号 姓名 现在班级 评估班级 考场名称 座位号 语文 数学 英语 生物 历史 地理 政治 总分),
对照表的表字段为: (准考证号 评估班级 现在班级),
1、以准考证号为关联字段,用对照表中评估班级更新学生成绩表中的评估班级。
2、删除不参与评估学生,例如成绩表中评估班级为16的学生。
3、总分降序排列,根据给定列表中指定的数据保留参评的人数,人数相等或小于列表中指定人数不做处理,只有当人数多于列表中指定的数量,则将多余的删除,例如给的列表为[53,53,53,53,53,53,53,53,53,53,58,57,58,56,55], 以上列表每个元素对应1到15班级应参与评估的人数。只保留前面规定的人数。4、不要修改学生成绩表,请在其副本上做以上处理,以”最后结果+ 时间戳命名。
"""程序清单:
import pandas as pd
# 读取两个工作簿
student_grades_df = pd.read_excel('成绩表.xlsx')
mapping_df = pd.read_excel('对照表.xlsx')
# 1. 以准考证号为关联字段,更新学生成绩表中的评估班级字段
merged_df = pd.merge(student_grades_df, mapping_df[['准考证号', '评估班级']], on='准考证号', suffixes=('', '_mapping'))
merged_df['评估班级'] = merged_df['评估班级_mapping']
merged_df.drop(columns=['评估班级_mapping'], inplace=True)
# 2. 删除评估班级为16的学生
filtered_df = merged_df[merged_df['评估班级'] != 16]
# 3. 总分降序排列
sorted_df = filtered_df.sort_values(by='总分', ascending=False)
# 根据给定的列表,使得每个评估班级保留指定人数,多余的删除
# retain_count_by_class = [53, 53, 53, 53, 53, 53, 53, 53, 53, 53, 58, 57, 58, 56, 55]
# 从txt文件中逐行读入数据到列表
with open('班级评估人数.txt', 'r') as file:
retain_count_by_class = [int(line.strip()) for line in file]
final_df = pd.DataFrame()
for class_number, retain_count in enumerate(retain_count_by_class, start=1):
class_df = sorted_df[sorted_df['评估班级'] == class_number]
if len(class_df) > retain_count:
class_df = class_df.head(retain_count) # 如果某班级的学生数量超过了规定要保留的人数,只保留前 retain_count 个学生,即删除多余的学生。
final_df = pd.concat([final_df, class_df], ignore_index=True)
# 4. 不要修改原始学生成绩表,在其副本上做以上处理,以”最后结果+时间戳"命名
timestamp = pd.Timestamp.now().strftime('%Y%m%d%H%M%S')
output_filename = f'最后结果_{timestamp}.xlsx'
final_df.to_excel(output_filename, index=False)
将每个班级参与评估的人数写到一个txt文件中,从txt中读入。
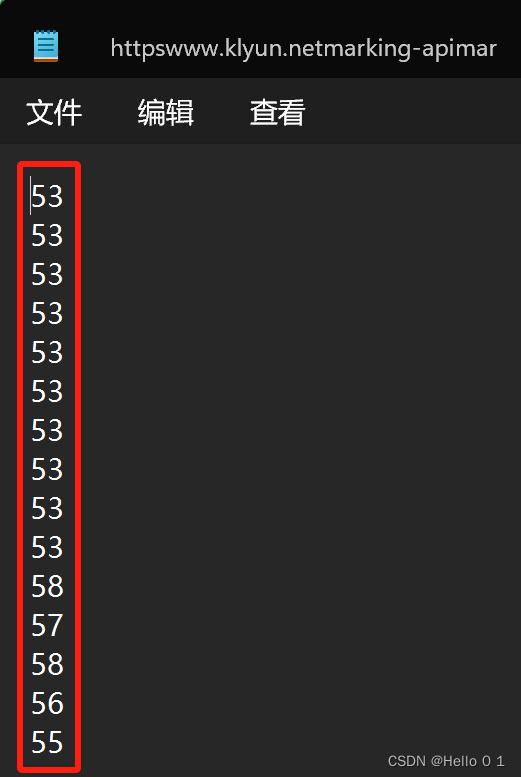
以上程序很好的完成了功能,提高了效率,避免手工出错。