目录
- 解决什么问题
- 基本结构理解
解决什么问题
传统的transformer处理于长序列需要非常大的计算量,而且很慢。且传统的transformer虽然的全局信息的获取上有着很好的效果,但是在局部信息的获取上就没有那么强了。Swim transformer的主要的贡献就是使用分层和窗口的概念来为这个框架提供了一个类似CNN感受野的东西,不仅可以兼顾了transformer本身优秀的全局信息获取的能力,且通过窗口的设计也提供了局部信息的获取能力。
基本结构理解
主要的结构图如下(来自原文)
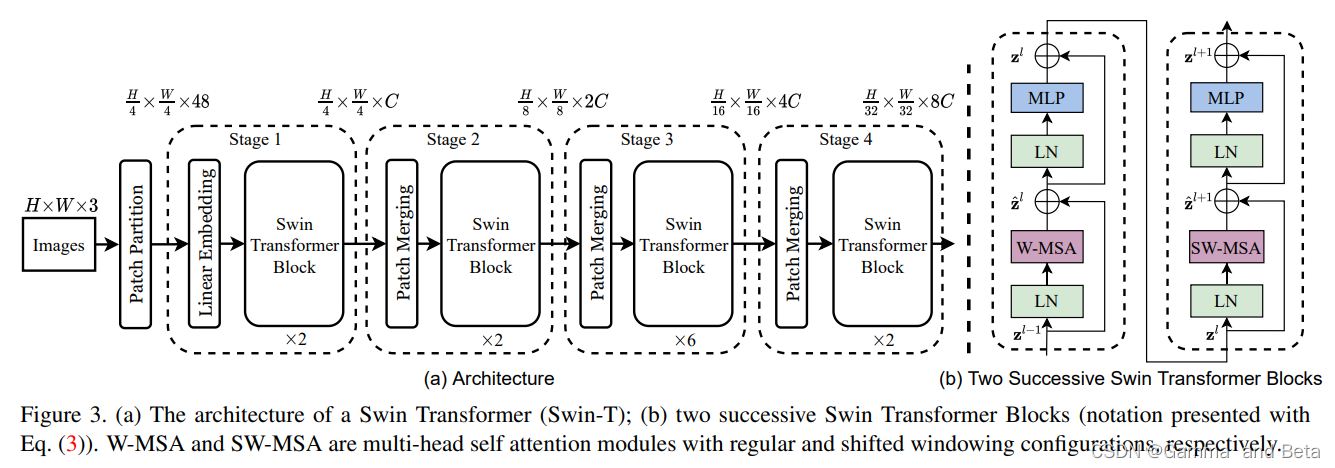
其主要的结构是S-MSA, SW-MSA,这个两个新的注意力机制。首先需要注意的是这两个注意力机制需要配合使用,单独使用的效果不佳。 首先从patch partition 开始,首先和传统的transformer一样将输入的数据打散成一个个小的patch。假设输入图像为(224,224,3), 将图像打散有16个patches的一组,每一个图片的大小就是(56,56,96)。这里只需要使用一个卷积核大小为4的2D卷积即可完成。因为打散图像是用的卷积,所以这里的96是指的特征通道数。将小patch像在传统transformer中一样展开变成(56x56,96)=(3136,96)。 和之前transformer不同的是在swin transformer中 我们还需要对分开的patch在进一步的细分成更小的窗口,这里将每一个小patch继续分成大小为7*7的64个更小的窗口。然后对每一个小窗口来做多头注意力机制。这里模型主要专注在自己窗口之内的特征信息(也就是有点CNN感受野的感觉了)。
上述的过程只重视了窗口之内的特征,但是完全没有考虑到窗口之间的特征联系。所以这里需要使用SW-MSA 也就是滑动窗口注意力机制,来捕获窗口与窗口之间的特征联系。具体的做法和S-MSA是基本一致的。但是会出现计算量变大的问题,因为滑动会使得窗口变多从而使得计算量激增。文中使用的mask-MSA实现了使用滑动窗口attention但是计算量保持不变。具体怎么做的?首先使用滑动窗口之后每一个patch内就不再只是包含窗口内的特征了,也包含了相邻窗口的特征。然后将每一个窗口做上index,通过特征移位的操作将9个窗口又变成4个了,然后做attention的时候只和index一样的窗口,通过mask把其他无关的设成大负数(例如,-100),softmax就会不考虑这个值。
这过程大概如下:

patch merging 类似下采样的操作。窗口数量越来越少。就有点像感受野越来越大,最后变成一个大的特征图。