2024 年 5 种领先的小语言模型:Phi 3、Llama 3 等
近年来,GPT-3 和 BERT 等大型语言模型的发展改变了人工智能的格局,它们以其强大的功能和广泛的应用而闻名。
然而,除了这些巨头之外,一种新的 AI 工具类别也正在掀起波澜——小型语言模型 (SLM)。这些模型(例如 LLaMA 3、Phi 3、Mistral 7B 和 Gemma)提供了先进的 AI 功能与显著降低的计算需求的强大组合。
为什么需要小语言模型?
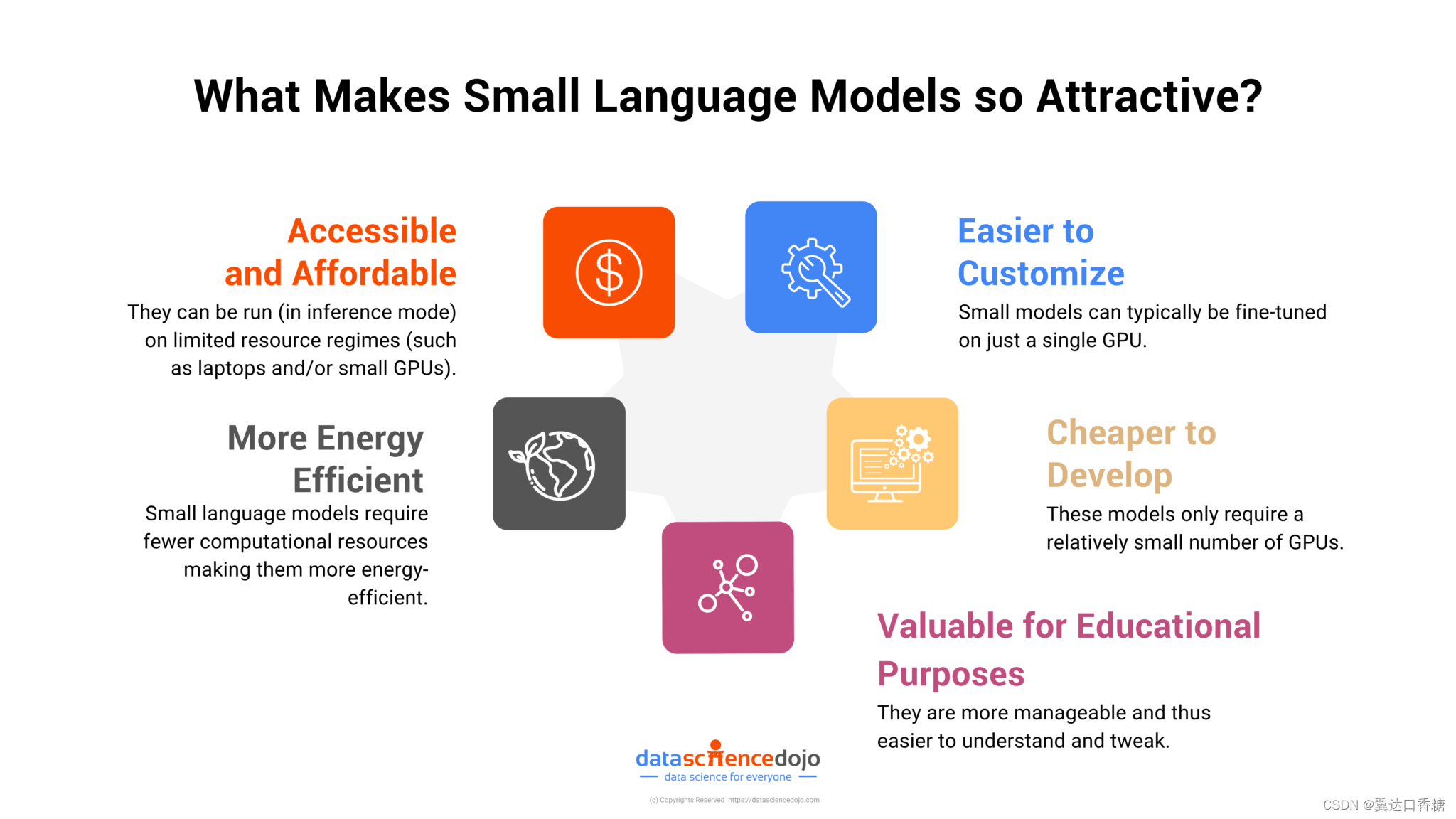
这种向更小、更高效模型的转变是由人工智能技术的可访问性、成本效益和民主化的需求所推动的。
小型语言模型需要的硬件更少、能耗更低、部署速度更快,因此非常适合初创企业、学术研究人员和不具备大型科技公司所拥有的大量资源的企业。
此外,它们的尺寸不仅仅意味着规模的缩小,也意味着跨各种平台和应用程序的适应性和易于集成的增加。
小型语言模型如何利用更少的参数脱颖而出?
有几个因素解释了为什么较小的语言模型能够以较少的参数有效地执行。
首先,先进的训练技术起着至关重要的作用。迁移学习等方法使这些模型能够建立在预先存在的知识库之上,从而提高其对专门任务的适应性和效率。
例如,从大型语言模型到小型语言模型的知识提炼可以实现相当的性能,同时显著降低对计算能力的需求。
此外,小型模型通常专注于小众应用。通过集中训练目标数据集,这些模型可以针对特定功能或行业进行定制,从而提高其在特定环境中的有效性。
例如,专门基于医疗数据训练的小型语言模型在理解医学术语和提供准确诊断方面可能会超越通用大型模型。
但需要注意的是,小型语言模型的成功在很大程度上取决于其训练方案、微调以及其设计用于执行的特定任务。因此,虽然小型模型可能在某些领域表现出色,但它们并不总是每种情况下的最佳选择。
2024 年最佳小语言模型

1. Meta 的 Llama 3
LLaMA 3 是Meta 开发的开源语言模型。它是 Meta 更广泛战略的一部分,旨在通过为社区提供功能强大且适应性强的工具,实现更广泛、更负责任的 AI 使用。该模型在其前辈成功的基础上,结合了先进的训练方法和架构优化,从而提高了其在翻译、对话生成和复杂推理等各种任务中的表现。
性能与创新
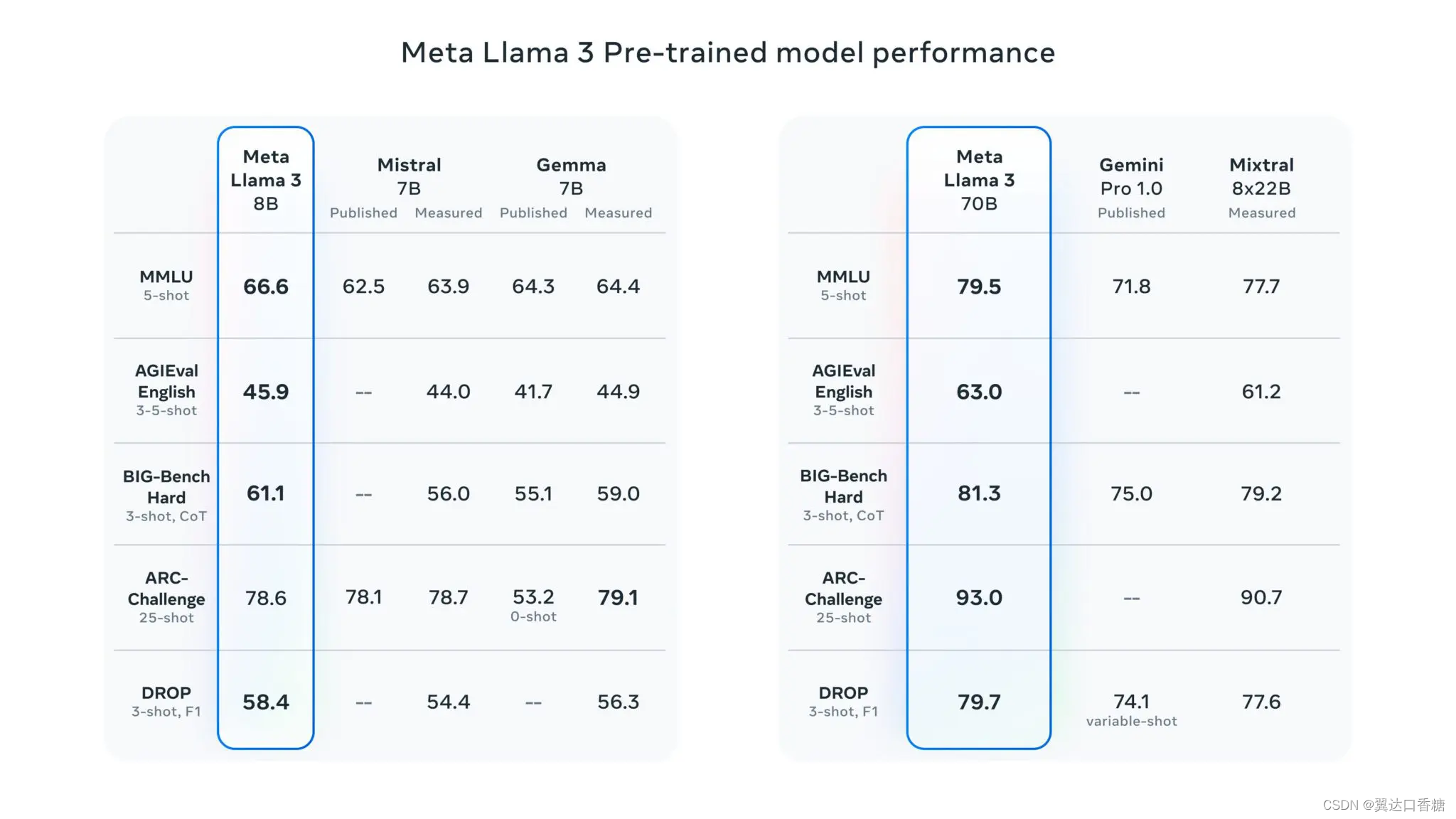
Meta 的 LLaMA 3 已经在比早期版本大得多的数据集上进行了训练,利用定制的 GPU 集群使其能够有效地处理大量数据。
经过广泛的训练,LLaMA 3 能够更好地理解语言的细微差别,并能够更有效地处理多步骤推理任务。该模型尤其以增强生成更一致和多样化响应的能力而闻名,使其成为旨在创建复杂的 AI 驱动应用程序的开发人员的强大工具。
为什么 LLaMA 3 很重要
LLaMA 3 的意义在于其可访问性和多功能性。作为开源模型,它使获取最先进的 AI 技术变得民主化,让更广泛的用户能够试验和开发应用程序。该模型对于促进 AI 创新至关重要,它提供了一个支持基础和高级 AI 研究的平台。通过提供模型的指令调整版本,Meta 确保开发人员能够针对特定应用程序微调 LLaMA 3,从而提高性能和与特定领域的相关性。
2. 微软的 Phi 3
Phi-3 是微软开发的开创性 SLM 系列,强调高性能和成本效益。作为微软对无障碍 AI 的持续承诺的一部分,Phi-3 型号旨在为广泛的应用提供强大的 AI 解决方案,这些解决方案不仅先进,而且更经济实惠、更高效。
这些模型是开放式 AI 计划的一部分,这意味着它们可供公众访问,并且可以集成和部署在各种环境中,从基于云的平台(如 Microsoft Azure AI Studio)到个人计算设备上的本地设置。
性能与意义
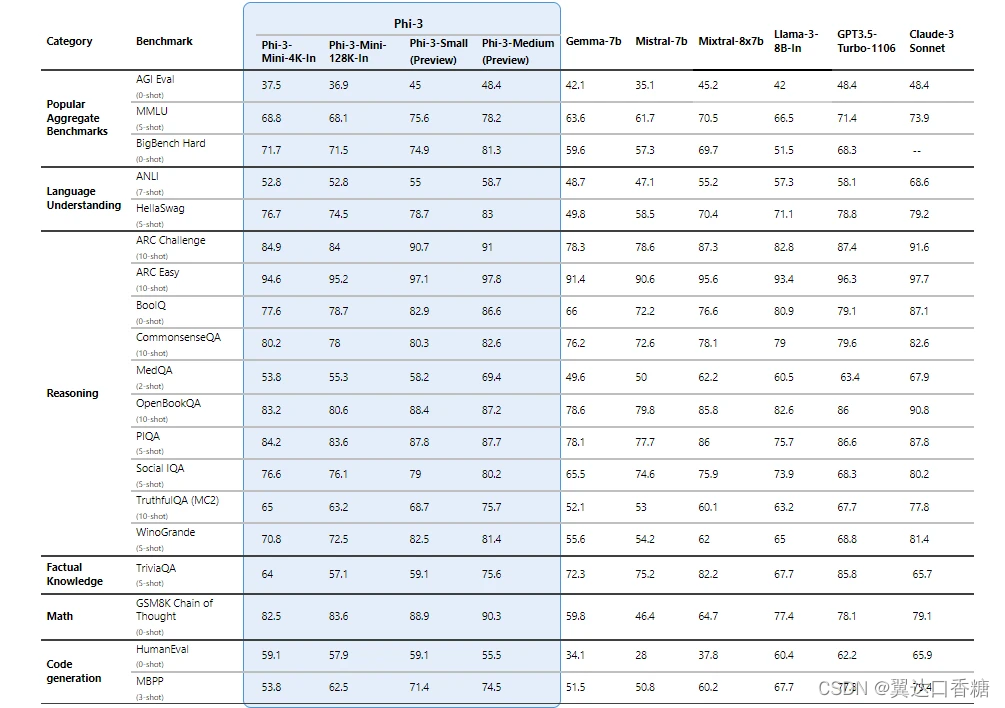
Phi 3 模型因其卓越的性能而脱颖而出,在涉及语言处理、编码和数学推理的任务中超越了同类和更大规模的模型。
值得注意的是,Phi-3-mini 是该系列中拥有 38 亿个参数的模型,其多个版本可以处理多达 128,000 个上下文标记,为在尽量减少质量损失的情况下灵活处理大量文本数据树立了新标准。
微软针对多样化的计算环境对Phi 3进行了优化,支持跨GPU、CPU和移动平台部署,充分体现了其多功能性。
此外,这些模型与其他 Microsoft 技术无缝集成,例如用于性能优化的 ONNX Runtime 和用于跨 Windows 设备广泛兼容性的 Windows DirectML。
为什么 Phi 3 很重要?
Phi 3 的开发反映了人工智能安全性和道德人工智能部署方面的重大进步。微软已将这些模型的开发与其负责任的人工智能标准相结合,确保它们遵守公平、透明和安全的原则,使它们不仅成为功能强大而且值得开发人员信赖的工具。
3. Mistral AI 的 Mixtral 8x7B
Mixtral是由 Mistral AI 开发的突破性模型,被称为稀疏混合专家 (SMoE)。它代表了 AI 模型架构的重大转变,注重性能效率和开放可访问性。
Mistral AI以其开放技术基础而闻名,它将 Mixtral 设计为仅解码器模型,其中路由器网络有选择地使用不同的参数组或“专家”来处理数据。
这种方法不仅使 Mixtral 非常高效,而且能够适应各种任务,而不需要通常与大型模型相关的计算能力。
性能与创新
Mixtral 擅长处理多达 32k 个标记的大型上下文,并支持英语、法语、意大利语、德语和西班牙语等多种语言。
它在代码生成方面表现出了强大的能力,并且可以进行微调以精确遵循指令,从而在 MT-Bench 等基准测试中取得高分。
Mixtral 的独特之处在于它的效率——尽管总参数数量为 467 亿,但每个标记有效利用的参数仅约 129 亿,在计算成本和速度方面与小得多的模型相当。
Mixtral 为何如此重要?
Mixtral 的意义在于它的开源性质和 Apache 2.0 许可,这鼓励开发者社区广泛使用和采用。
这种模式不仅是一项技术创新,也是促进更具协作性和透明度的人工智能发展的战略举措。通过使高性能人工智能更易于访问且资源密集程度更低,Mixtral 正在为更广泛、更公平地使用先进人工智能技术铺平道路。
Mixtral 的架构代表着向更可持续的 AI 实践迈出了一步,它降低了通常与大型模型相关的能源和计算成本。这不仅使其成为开发人员的强大工具,而且也是 AI 领域更环保的选择。
4. Google 的 Gemma
Gemma 是 Google 推出的新一代开放模型,其设计秉承了负责任的 AI 开发的核心理念。Gemma 由 Google DeepMind 和 Google 其他团队共同开发,利用了 Gemini 模型诞生的基础研究和技术。
技术细节和可用性
Gemma 模型结构轻巧且先进,确保它们可在各种计算环境中(从移动设备到基于云的系统)访问和运行。
Google 发布了 Gemma 的两个主要版本:20 亿参数模型和 70 亿参数模型。每个版本都提供预训练和指令调整版本,以满足不同开发人员的需求和应用场景。
Gemma 模型可免费使用,并由鼓励创新、协作和负责任使用的工具支持。
杰玛 (Gemma) 为何如此重要?
Gemma 模型的重要性不仅在于其技术稳健性,还在于其在普及 AI 技术方面发挥的作用。通过以开放模型格式提供最先进的功能,Google 促进了 AI 的更广泛采用和创新,让全球的开发者和研究人员能够构建高级应用程序,而无需承担大型模型通常带来的高昂成本。
此外,Gemma 模型具有很强的适应性,用户可以针对专门的任务进行调整,从而得到更高效、更有针对性的 AI 解决方案
5. Apple 的 OpenELM 系列
OpenELM是 Apple 开发的一系列小型语言模型。OpenELM 模型对于资源效率至关重要的应用程序尤其有吸引力。OpenELM 是开源的,具有透明度,并为更广泛的研究社区提供了根据需要修改和调整模型的机会。
性能和功能
尽管 OpenELM 模型规模较小且具有开源性质,但需要注意的是,它们并不一定能与一些规模较大、更闭源的模型的顶级性能相媲美。它们在各种基准测试中都达到了中等准确度水平,但在更复杂或更细致入微的任务中可能会落后。例如,虽然 OpenELM 在准确度方面比 OLMo 等类似模型表现出更好的性能,但这种改进是适度的。
OpenELM 为何重要?
OpenELM 代表了 Apple 的一项战略举措,旨在将最先进的生成式 AI 直接集成到其硬件生态系统(包括笔记本电脑和智能手机)中。
通过将这些高效模型嵌入到设备中,Apple 可以提供增强的设备 AI 功能,而无需不断连接到云端。
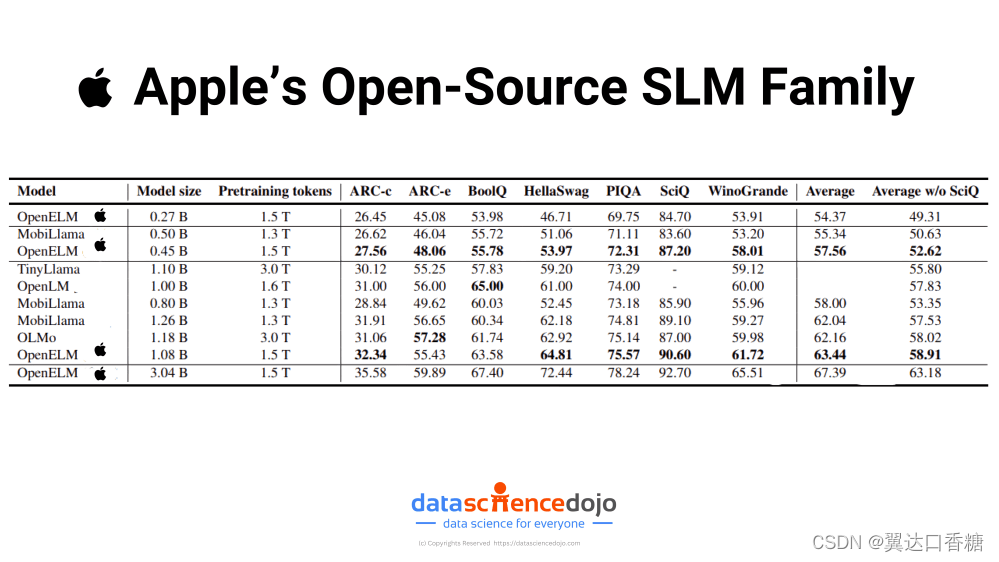
Apple 的开源 SLM 系列
这不仅改善了连接性较差地区功能,也满足了消费者对隐私和数据安全日益增长的需求,因为在本地处理数据可最大限度地降低网络暴露风险。
此外,将 OpenELM 嵌入到 Apple 的产品中可以使公司获得显着的竞争优势,使其设备更加智能,并且能够独立于云端处理复杂的 AI 任务。
这可以改变用户体验,直接在设备上提供响应更快、更个性化的人工智能互动。此举可能为人工智能的隐私设定新标准,吸引注重隐私的消费者,并可能重塑科技行业的消费者期望。
小型语言模型的未来
随着我们深入研究小型语言模型的功能和战略实施,我们可以清楚地看到,人工智能的发展在很大程度上倾向于效率和集成。苹果、微软和谷歌等公司正在引领这一转变,将先进的人工智能直接嵌入日常设备,在提升用户体验的同时,坚持严格的隐私标准。
这种方法不仅满足了消费者对强大而私密的技术解决方案日益增长的需求,而且还为科技公司的竞争格局树立了新的典范。