文章目录
- K8s deployment 进阶
- Deployment 更新策略
- Recreate
- RollingUpdate
- maxSurge 和 maxUnavailable
- minReadySeconds
- progressDeadlineSeconds
- Deployment 版本回滚
- Deployment 实现灰度发布
K8s deployment 进阶
Deployment 更新策略
Recreate
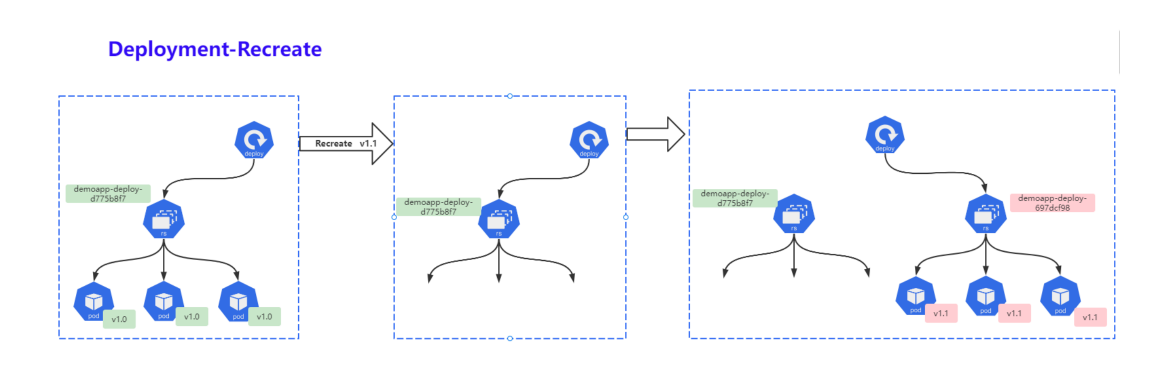
重建 (Recreate),当更新策略设定为 Recreate,在更新镜像时,它会先杀死正在运行的Pod,等彻底杀死后,重新创建新的RS,然后启动对应的Pod,那么在这个更新过程中,会造成服务一段时问无法提供服务;
- 第一步:同时杀死所有旧版本的Pod,此时Pod无法正常对外提供服务;
- 第二步:创建新的RS,启动新的Pod;
- 第三步:等待Pod就绪,对外提供服务;
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
namespace: default
spec:
strategy: # 更新策略
type: Recreate # 更新镜像的策略定义为Recreate
replicas: 5 # 副本数
selector: # 通过标签选择器选择要管理的Pod
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: webserver
image: nginx:1.7.9
ports:
- name: http
containerPort: 80
通常只有应用的新旧版本不兼容(例如依赖的后台数据的格式不同且无法兼容)时才会使用,这种更新会出现一段时间的服务无法访问
RollingUpdate
滚动更新 (RoILingupdate),一次仅更新一批Pod,当更新的Pod就绪后,在更新另一批,直到全部更新完成为止;该策路实现了不间断服务的目标,在更新过程中可能会出现不同的应用版本井存且,同时提供服务的情况。
- 第一步:创建新的Replicaset,然后根据新的镜像运行新的Pod;
- 第二步:删除1日的Pod,启动新的Pod,新Pod就绪后,继续删除1日
Pod,启动新Pod; - 第三步:持续第二步过程,一直到所有Pod都被更新成功。

apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
namespace: default
spec:
strategy:
type: RollingUpdate # 更新镜像的策略为RollingUpdate
replicas: 5 # 副本数
selector: # 通过标签选择器选择要管理的Pod
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: webserver
image: oldxu3957/demoapp:v1.1
ports:
- name: http
containerPort: 80
RollingUpdate 更新时,会出现新老版本同时存在,同时能访问的情况,让使用者无法明显感知到服务更新
maxSurge 和 maxUnavailable
Deployment 会在 spec.strategy.type=Rollingupdate 时,采取滚动更新的方式更新 Pods。可以指定 maxUnavailable 和
maxsurge 来控制滚动更新过程。
- maxSurge 最大可用Pod
- 用来指定可以创建超出期望Pod个数的 Pod数量。可以是数字,也可以是百分比(例如10%) 此字段的默认值为25%。
- 例如,当此值为 20% 时,启动滚动更新后,会立即对新的Replicaset 扩容,同时保证新1日 Pod 的总数不超过所需 Pod 总数的 120%。一旦1 Pods 被杀死,新的Replicaset 可以进一步扩容, 同时确保更新期间的任何时候行中的 Pods 总数最多为所需 Pods 总数的 120%。计算公式:10+(10x20%)=12
- maxUnavailable 最大不可用Pod
- 用来指定更新过程中不可用的 Pod 的个数上限。可以是数字,也可以是百分比(例如10%) 此字段的默认值为25%。
- 例如,当此值设置为 20% 时,滚动更新开始时会立即将旧Replicaset 缩容到期望 Pod 个数的70%。新 Pod 准备就绪后,继续缩容1旧有的 Replicaset,然后对新的Replicaset 扩容,确保在更新期间可用的 Pods 总数在任何时候都是所需的 Pod 个数的 70%。 计算公式:10-(1 0×20%)=8
maxSurge 和 maxUnavailable 两个属性协同工作,可组合定义出3中不同的策路完成多批次的应用更新。
- 先增新,后减旧:将maxSurge设置为30%,将maxUnavailable的值设为0;
- 先减旧,后增新:将maxUnavailabre设置为30%,将maxSurge的值设为0;
- 同时增减,将maxSurge和maxUnavailable分别设定为20%;期望是12Pod,至少就绪8个Pod
同时增减配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp-deploy
namespace: default
spec:
# pasued: true # 默认为false 设置为true 时,停止更新
minReadySeconds: 5 # 设置 就绪等待时长 5s 默认为0
strategy:
rollingUpdate:
maxSurge: 20%
maxUnavailable: 20%
type: RollingUpdate # 更新镜像的策略为RollingUpdate
replicas: 10 # 副本数
selector: # 通过标签选择器选择要管理的Pod
matchLabels:
app: demoapp
template:
metadata:
labels:
app: demoapp
spec:
containers:
- name: webserver
image: nginx:1.7.9
ports:
- name: http
containerPort: 80
minReadySeconds
Deployment支持使用 spec .minReadySeconds 字段来控制滚动更新的速度,默认值为0,表示新建的Pod对象一旦 “就绪“将立即被视作可用,随后即可开始下一轮更新过程。如果设定了spec .minReadySeconds:3 及表示新建的Pod对象至少要成功运行多久才会被视作可用,即就绪之后还要等待指定的 3s 才能开始下一批次的更新。在一个批次内新建的所有Pod就绪后在转为可用状态前,更新操作会被阻塞,并且任何一个Pod就绪探测失败,都会导致滚动更新被终止。
因此,为ninReadySeconds 设定一个合理的值,不仅能够减缓更新的速度,还能够让Deployment提前发现一部分程序因为Bug导致的升级故障。
progressDeadlineSeconds
滚动更新故障超时时长,默认时600秒,在升级版本过程中,出现各种问题导致升级进程卡住,比如拉镜像网络不好,没有权限等。 当超时后,就会上报这个异常,这个时候deployment 状态会被标记为False,并注明原因。但是并不会阻止 deployment 继续进行卡在后面的升级操作
Deployment 版本回滚
当deployment 不稳定进入反复崩溃状态时。默认情况下,deployment 的所有上线记录都保存在系统中,以便随时回滚。(可以通过修改spec.revisionHistoryLimit 调整保留数量, 默认10条)
1. 查看历史版本
$ kubectl rollout history deployment demo-deploy
2. 查看对应version 的具体信息
$ kubectl rollout history deployment demo-deploy --version=1
3. 回滚对应版本
$ kubectl rollout undo deployment demo-deploy --to-version=1
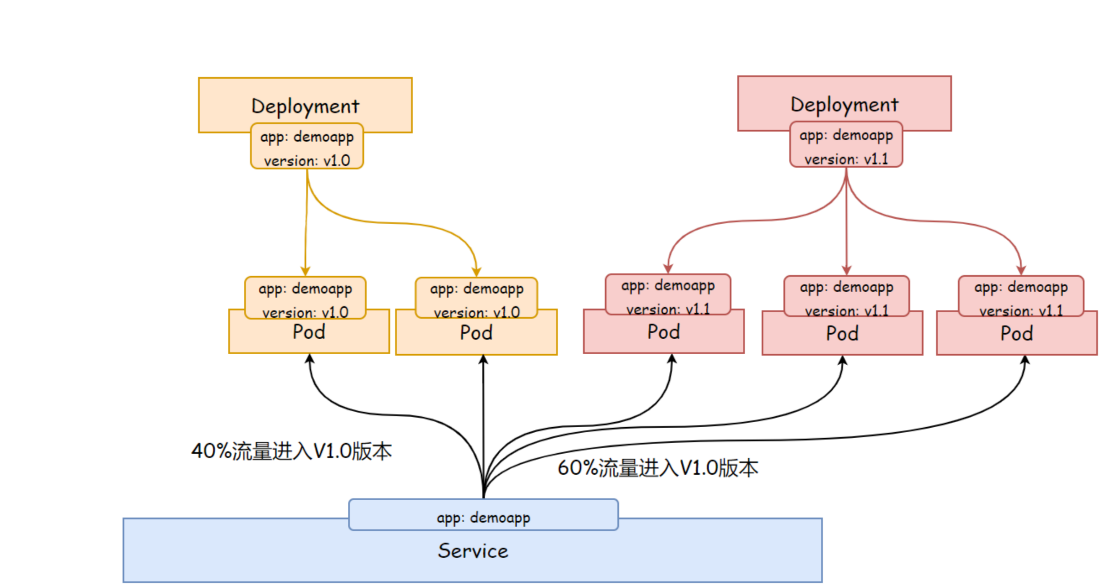
Deployment 实现灰度发布
灰度发布(又名金丝雀发布) 是指黑与白之前,能够平滑过度的一种发布方式,在上面可以进行 A/B Testing
- 首先:让一部分用户继续使用产品特性A (旧版本)
- 其次:让一部分用户开始使用产品特性B(新版本)
- 最后:如果用户对产品特性B没有反对意见,那么逐步扩大反问,将用户的流量迁移到B上面来。
使用灰度发布的模式,可以及时发现问题,调整问题,以减少影响的速度,保证整体系统的稳定运行。简单点说就是同时运行两个版本的deployment,用同一个 service 代理 两个deployment。










![[Spring Boot]baomidou 多数据源](https://img-blog.csdnimg.cn/img_convert/8172da499bf5415a93f9032567b3b04f.png)