文章目录
- 1.个性化配置,增加吞吐量
- 2.发送事务消息
- 3.消费组
- 手动提交offset
- 指定offset位置进行消费
- 指定时间消费
- 当新增消费者,或者消费组时,如何消费
- 漏消息和重复消息
- 如何解决消费解压问题
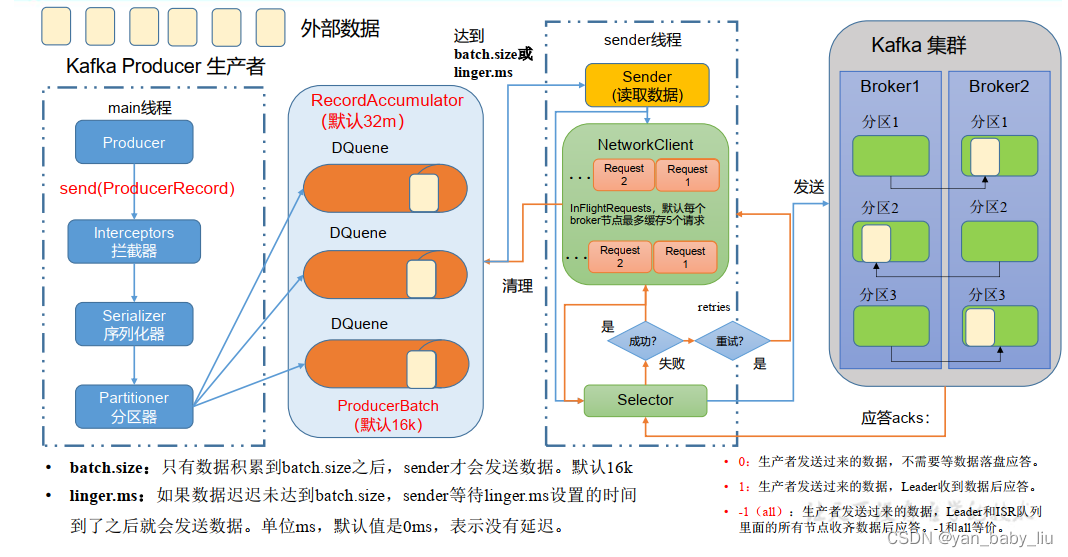
1.个性化配置,增加吞吐量
private static void sendWithCustomerParameter(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//默认16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
//默认1
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//默认32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 32*1024*1024);
//compression.type 压缩,默认是none,可配置为gzip,snappy,lz4,和zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
//创建生产者对象
KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("消息发送到"+metadata.partition()+"分区");
}
}
});
}
kafkaProducer.close();
}
消费端
[root@node3 kafka_2.12-3.0.0]# bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic first
hello0
hello1
hello2
hello3
hello4
如果想个性化设定消息推送的分区规则,可以自定义分区器
此外生产端,还可以设定ack机制,以及重试次数
properties.put(ProducerConfig.ACKS_CONFIG, "all");// 等于配置ack=-1
properties.put(ProducerConfig.RETRIES_CONFIG, 3);//默认是int的最大值
2.发送事务消息
private static void transactionSend(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092" );
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设置事务id
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaction_id_0" );
KafkaProducer producer = new KafkaProducer(properties);
//初始化事务
producer.initTransactions();
//开启事务
producer.beginTransaction();
try{
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord("first", "I love you "+i));
}
// int i = 4/0;
producer.commitTransaction();
}catch (Exception e){
e.printStackTrace();
//丢弃事务
producer.abortTransaction();
}finally {
producer.close();
}
}
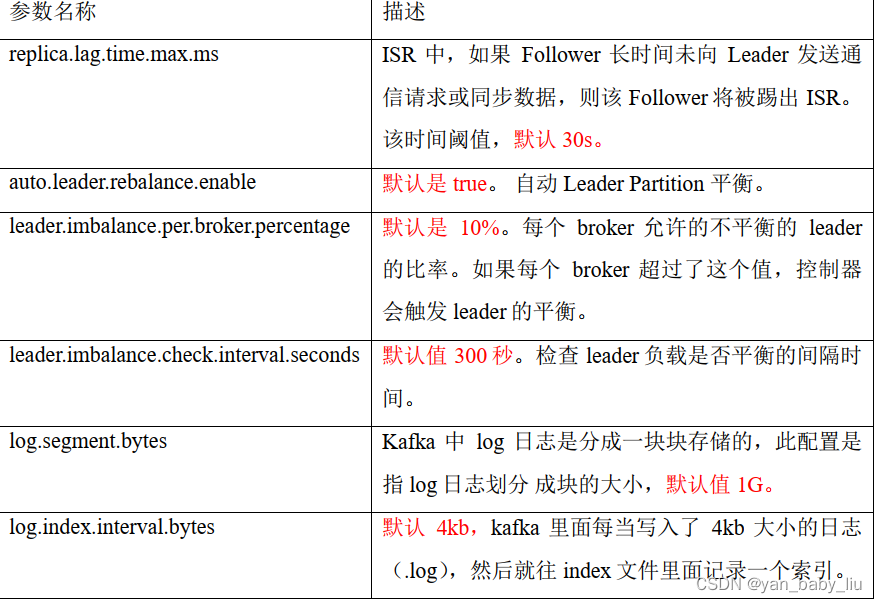
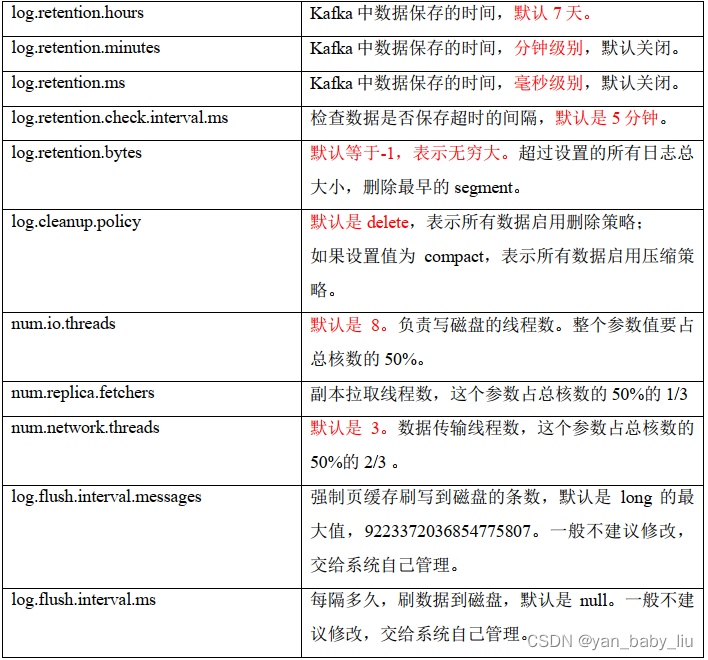
broker重要参数
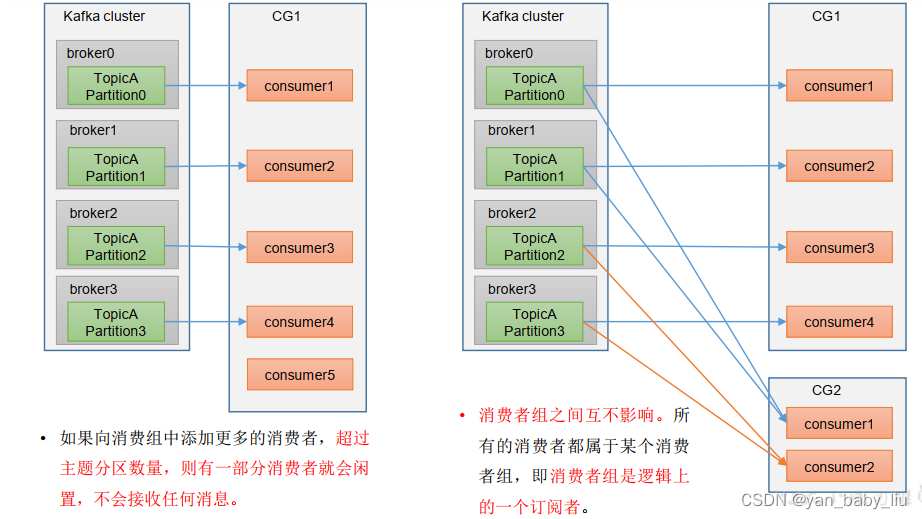
3.消费组
消费组中的消费者作为整体消费某个主题,而主题的每个分区只能被一个一个消费组中的一个消费者消费
同一个分区中的消息可以保证有序消费
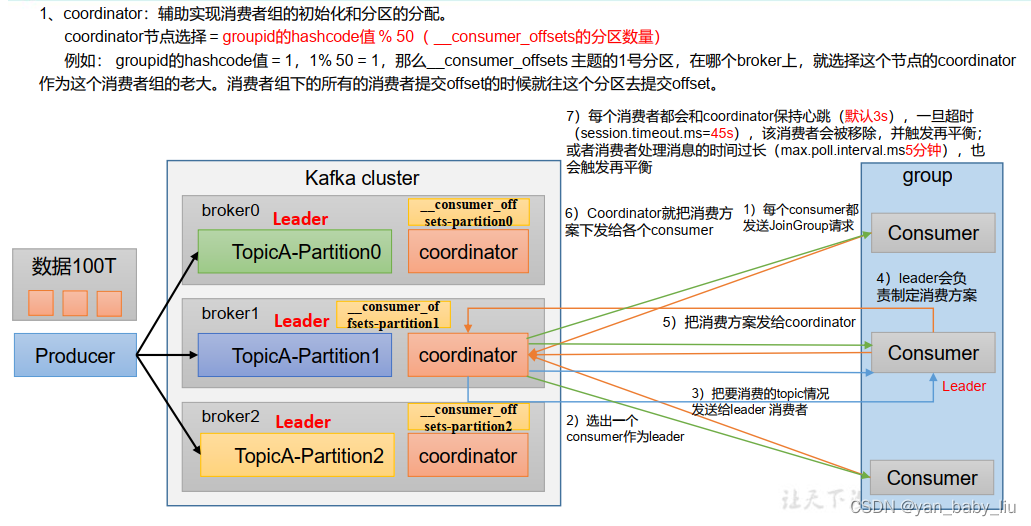
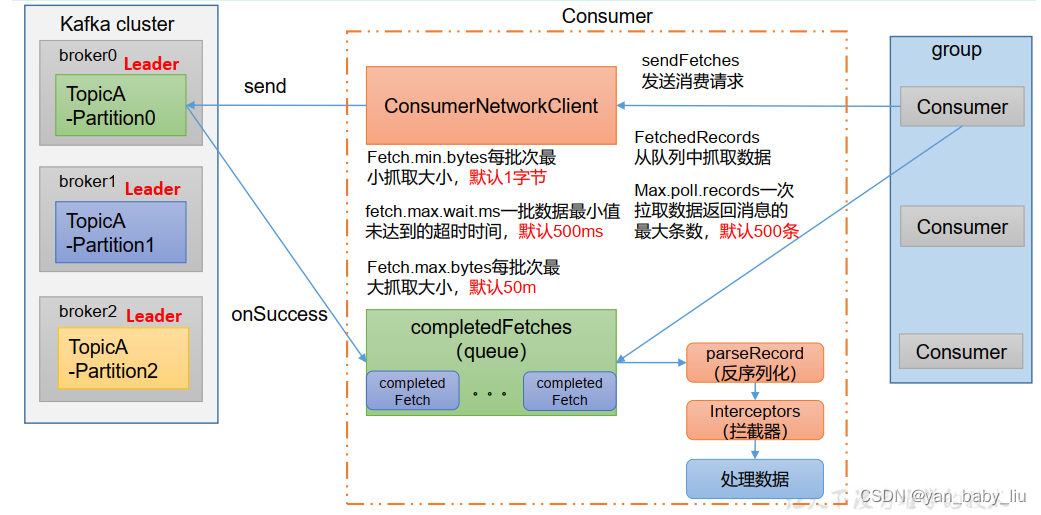
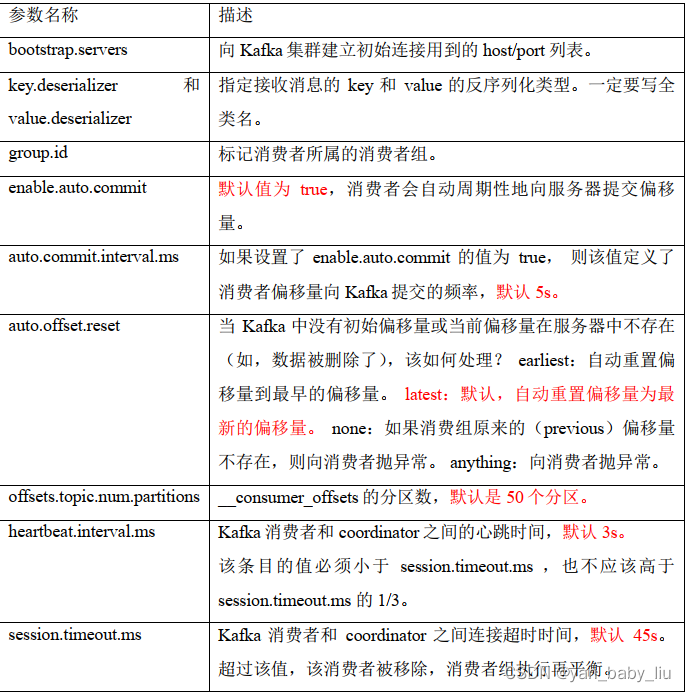
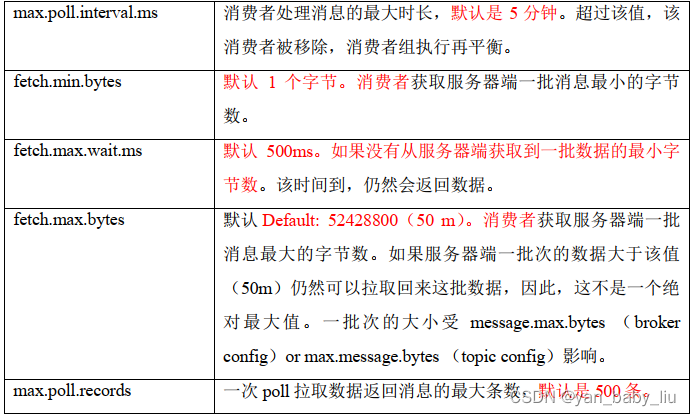
消费者参数
private static void consume() {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//配置消费组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1");
//创建消费者对象
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
//注册要消费的主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(20));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key());
System.out.println(consumerRecord.value());
}
}
}
key 是topic-分区编号

当发送的时候指定key
private static void sendWithCustomerParameter(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//默认16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
//默认1
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//默认32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 32*1024*1024);
//compression.type 压缩,默认是none,可配置为gzip,snappy,lz4,和zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
properties.put(ProducerConfig.ACKS_CONFIG, "all");// 等于配置ack=-1
properties.put(ProducerConfig.RETRIES_CONFIG, 3);//默认是int的最大值
//创建生产者对象
KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
kafkaProducer.send(new ProducerRecord<>("first","customer-first-"+i, "hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("消息发送到"+metadata.partition()+"分区");
}
}
});
}
kafkaProducer.close();
}
消费者接受到的key如下
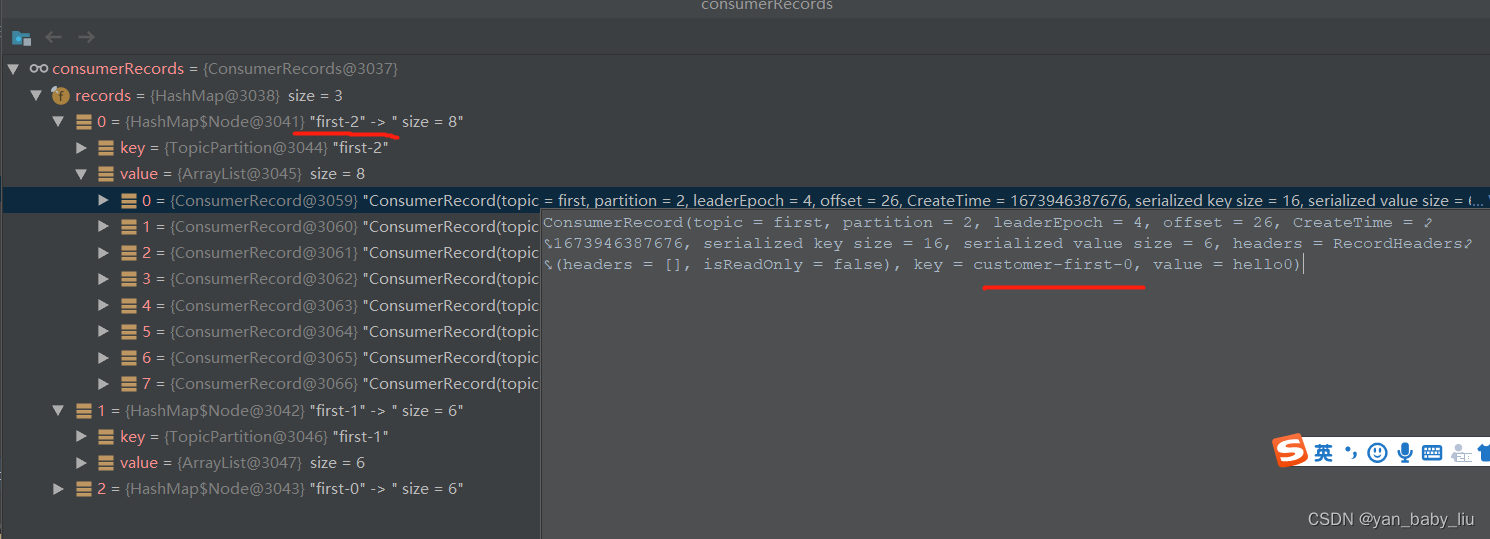
消费者也可以消费指定partition

手动提交offset
private static void commitByManual(){
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test" );
//是否自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false );
KafkaConsumer consumer = new KafkaConsumer(properties);
consumer.subscribe(Arrays.asList("first"));
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
System.out.println("接受到:"+record);
}
//异步提交
consumer.commitAsync();
//同步提交
// consumer.commitSync();;
}
}
指定offset位置进行消费
private static void assignOffset(){
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test" );
//是否自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false );
KafkaConsumer consumer = new KafkaConsumer(properties);
consumer.subscribe(Arrays.asList("first"));
Set<TopicPartition> assignment = new HashSet<>();
while(assignment.size()==0){
//获取分区消息
consumer.poll(Duration.ZERO);
assignment=consumer.assignment();
}
//遍历每个分区,指定offset从1700位置开始消费
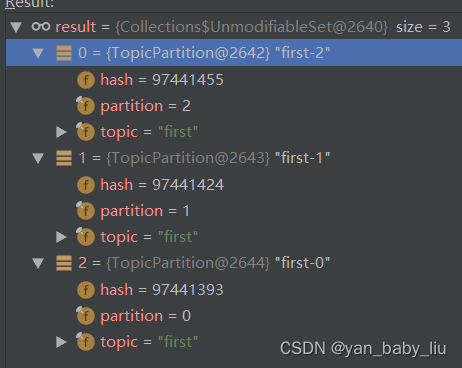
for (TopicPartition topicPartition : assignment) {
consumer.seek(topicPartition, 1700);
}
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
System.out.println("接受到:"+record);
}
//异步提交
consumer.commitAsync();
//同步提交
// consumer.commitSync();;
}
}
获取的分区集合为
指定时间消费
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//配置消费组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1");
//创建消费者对象
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
//注册要消费的主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
Set<TopicPartition> assignments = new HashSet<>();
while (assignments.size() == 0) {
kafkaConsumer.poll(Duration.ofSeconds(5));
//获取分区信息
assignments = kafkaConsumer.assignment();
}
HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>();
//封装集合存储,每个分区对应一天的数据
for (TopicPartition topicPartition : assignments) {
timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
}
//获取从一天前开始消费的每个分区的offset
Map<TopicPartition, OffsetAndTimestamp> offsets =
kafkaConsumer.offsetsForTimes(timestampToSearch);
//遍历每个分区,对每个分区设置消费时间
for (TopicPartition topicPartition : assignments) {
OffsetAndTimestamp offsetAndTimestamp= offsets.get(topicPartition);
kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());
}
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(20));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key());
System.out.println(consumerRecord.value());
}
}
}
}
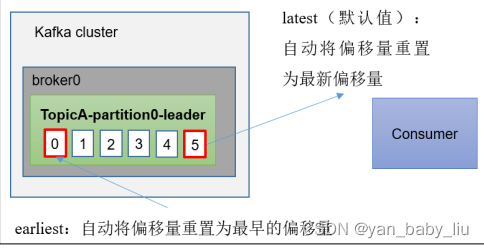
当新增消费者,或者消费组时,如何消费
auto.offset.reset=earliest | latest | none
当kafka没有偏移量(消费组第一次消费)或服务上不再存在当前偏移量时(例如数据已经被删除),该怎么办呢?
1.earliest 自动将偏移量设置为最早的偏移量 ,–from-beginning
2.latest
默认值,自动将偏移量设置为最新偏移量
3.none,如果未找到消费组以前的偏移量,则向消费者抛出异常
private static void sendWithCustomerParameter(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//默认16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
//默认1
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//默认32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 32*1024*1024);
//compression.type 压缩,默认是none,可配置为gzip,snappy,lz4,和zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
properties.put(ProducerConfig.ACKS_CONFIG, "all");// 等于配置ack=-1
properties.put(ProducerConfig.RETRIES_CONFIG, 3);//默认是int的最大值
//创建生产者对象
KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
kafkaProducer.send(new ProducerRecord<>("first","customer-first-"+i, "hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("消息发送到"+metadata.partition()+"分区");
}
}
});
}
kafkaProducer.close();
}
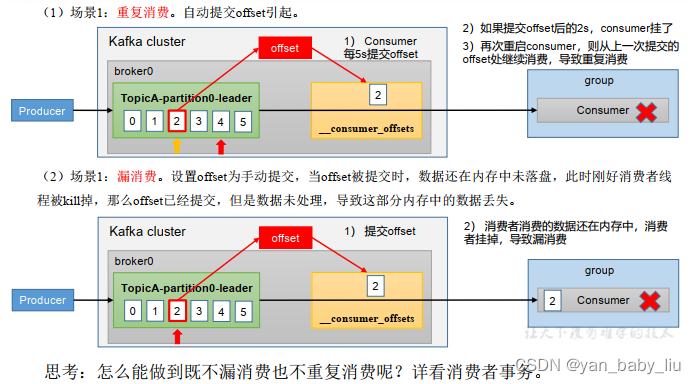
漏消息和重复消息
重复消费:已经消费了消息,但是offset未提交
先提交了offset,但是消息未消费
如何解决消费解压问题
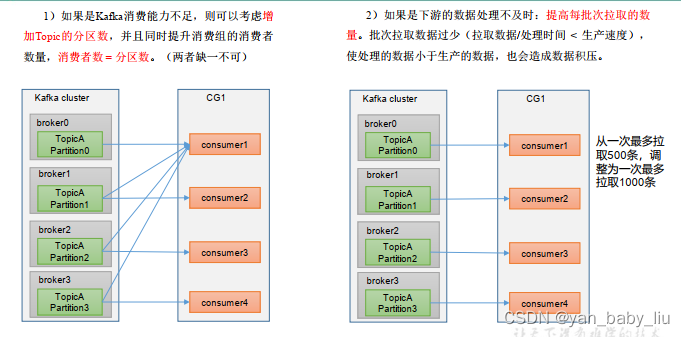
如何消费端为手动提交,且涉及到数据库交互IO操作,数据库操作慢,也会影响消费速度,大量的消费线程阻塞到数据库连接上,等待保存数据到db中
网络问题慢,也会导致消息挤压