本文作者:郑岩(华为云AI变革首席专家)全文约3313字,阅读约需8分钟,请仔细看看哦~
前阵子,我在公司内部发了一篇Sora的科普贴,本来只是个简单的技术总结,但让我意外的是,评论区非常热闹,而且完全是两个世界的声音,一半开始无限畅想,一半觉得吹过了。没想到,公司内部也有这么大的认知分歧。我想这可能就是一个合格的“技术革命”到来时,大家各抒己见,观点林立。
最近,我一直想做一个总结分享,梳理一下近期获得的一些新认知,以及在工作项目中对AI大模型应用的有趣发现,但是屡屡提笔又不知从何下手,这个话题确实太大了。于是就狠了狠心,干脆搞个系列连载好了,先从认知篇开始吧!
本期核心观点
- 上车:AGI是未来5~10年内,每个人都无法回避的技术革命,建议就近上车。
- 迭代:眼下的AI大模型应用都还只是过程稿,仍在快速迭代,切忌刻舟求剑。
- 预判:AI大模型的演进哪些是“不变项”?不要在AI大模型前进的车轮下“绣花”。
- 思考:AI大模型的底层逻辑是什么?紧跟第一性原理。
- 成长:AI应用的机会窗才刚刚开始,当下是最佳的成长周期,无论是组织还是个人。
PS.我虽然尽可能把得到多方佐证的信息和观点拿出来分享,但也不能保证完全准确,欢迎留言讨论,兼听则明。
01 上车:AGI是未来5~10年内,每个人都无法回避的技术革命,建议就近上车
在大变局面前,常见几种态度是 “看不见、看不懂、看不起、来不及”。
“看不见”目前可能性不大,“来不及”也还言之过早,可能更多是中间两者,夹杂着一些焦虑或是抵触,其实这很正常,谁不是呢。
关于AGI定义很多,问题就因为这个词儿太通用,不够具体,我觉得就以“AI智商超过人,能干好聪明人能干的事儿”为佳。
我最近观看了好多国内外大佬的采访,基本上对于AI的智商超过人这事儿是没有分歧的,只是如何实现、多久实现有些争议,至少可以说明一点,这个事儿靠谱,没必要再怀疑其真实性。至于是3~5年,还是5~10年,我觉得已经不再重要。哪怕短期高估一点也无所谓,长期不能低估就对了。
以后会发生啥,没有人能说清楚。只是基于每个人的风险偏好不同,给出不同的处置方式。但是,这就是现实,滚滚而来,认清和接纳现实也是一种态度。
讲个真实的段子:前阵子,Hinton老爷子(加拿大计算机学家和心理学家)在演讲上,建议安排人在关键时刻负责“数据中心断电”,认为低级智能掌握高级智能在自然界从未有过。(大刘诚不欺我,这不就是《三体》里的“执剑人”?)
不管怎么样,最近5年,对我们最重要的,就是积极拥抱AI大模型,理解AI大模型,并在生命中应用AI大模型。
从去年开始,我对自己的职业发展做了重新定位,就是专攻AI大模型2B应用,我认为这是我未来十年唯一值得做的事儿。从读书开始,前前后后小20年的技术积累,在这一刻有了新的意义。
我甚至给我家五岁的孩子搞了个数字人,设定成五年后的她,希望能够在日常生活中给她一些帮助和指导。
所以,这里我建议“就近上车”,也就是说,不管你的生活、工作是什么样的,都应该积极设想,我该怎么在我的日常生活中加入AI大模型?能用哪些AI工具来辅助和加持?未来还有哪些场景AI可以帮助到我?
02 迭代:眼下的AI大模型应用都还只是过程稿,仍在快速迭代,切忌刻舟求剑
当下哪怕是ChatGPT,也都只是AGI的过程稿,这个很关键:
- 一方面,这会影我们对未来的判断,拿着ChatGPT或是Mid-Journey当下的水平来对标未来、构思应用场景,可能有点刻舟求剑了。
- 另一方面,容易跟风地学,别人做了个啥,咱也要做个啥,都得是对话框、都得输入、能聊天、能生成......
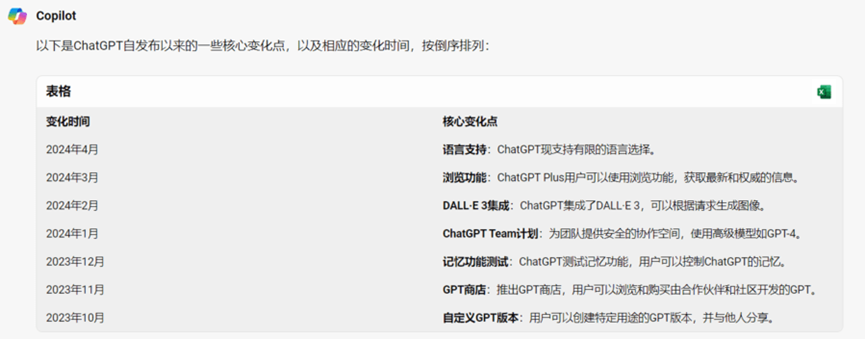
此外,值得关注的是,这并不意味着当前的AI过程稿“微不足道”,实际上其已经开始颠覆一些具体场景,比如Sora与短视频,Suno与音乐,MJ与插画,微软Copliot(New Bing)与搜索,Devin与编程,ChatGPT与很多很多琐事,等等,就在当下以肉眼可见的程度占据一席之地。(我自己也是AI工具的高频用户,也确实变懒了,今天数了下,手机装了不下十款各式AI软件,最近常用的是ChatGPT、文心一言、微软Copilot、Kimi Chat。)
03 预判:AI大模型的演进方向预判,不要在AI大模型前进的车轮下“绣花”
AI大模型演进非常快,说是“日新月异”一点也不夸张。但这对于我们这些用AI大模型的人来说,除了一惊一乍地看热闹,可能更重要的是从变化中,找到其中的不变性。
因此需要对AI大模型的演进方向,有个大致的预判,这样可以避免我们在大模型前进的车轮下“绣花”。不然好不容易搞点小突破、小创新,绣了个花,基模型一升级,就啥也不是了。
我有几个基本的逻辑判断 ——“五更”:
- 更快
- 更准
- 更长(上下文)
- 更便宜
- 更多模态
这一切从GPT、Claude、Gemini等TOP选手的演进上就看得出来。
04 思考:AI大模型的底层逻辑是什么?第一性原理是什么?
这里我不敢说自己完全理解,我只能把我听到、学到的分享出来:
1、scaling law,大力出奇迹: 我想这基本上就是搞AGI的公司唯一信奉的真理了,简单说就是“大力出奇迹”,scale发生在几个方面——数据、算力、参数,在算力恒定的情况下,目前最优先增加的是数据。就在这周,Databricks开源的DBRX模型,参数比Grok小3倍,数据量出奇的大,效果超过GPT3.5。(Scaling Law是指模型的性能与计算量、模型参数量和数据大小三者之间存在的关系。具体来说,当不受其他因素制约时,模型的性能与这三者呈现幂律关系。这意味着,增加计算量、模型参数量或数据大小都可能会提升模型的性能,但是提升的效果会随着这些因素的增加而递减。)
2、Next Token Prediction,生成式: 当然这里不仅是生成文字和图像token,还是生成视频patch。这里用illya(OpenAI 首席科学家)的话说,就是如果大模型能很好地预测下一个字,就意味着能对世界建模。说人话,就是如果我能猜到你打算说啥,我肯定也就很了解你。目前大模型因为学到了很多通用知识,所以对我们这个世界确实有一定的了解。(Next Token Prediction(NTP)是一种文本补全能力,或者说是文字接龙。它是自然语言处理(NLP)中的一个概念,具体指的是给定一段文本的前几个词(或称为tokens),预测并生成下一个词或tokens的过程。)
3、数据第一、算力第二:这句话我忘记具体出处,但是这句话一直在被证明。虽然AGI的路还不清晰,但是怎么搞出GPT3.5甚至GPT4这样的模型,我感觉顶级玩家之间已经没有太多护城河了。不然不可能一个个地都开始揭榜了。当然算力背后,除了卡,还有能源,所以微软的核能超算中心是极有可能的。
4、人才密度:与传统IT产品的外包方式不同,这波AI大模型初创公司主打的就是团队人才密度。如下是Sora的团队画像:小于10人、95后主导、北美计算机名校、AI Native。如果打算搞搞AI大模型、要组建团队,用好招新的机会,非常重要,最近几年的应届生质量也是非常高的。反观我们自己,这些技术老兵,就更要紧跟技术发展了,好在事物很新,有一些后发优势。

5、未来:一个更好的架构、一个自学习的AI:现在无论GPT背后的Transformer也好,Sora背后的DiT也罢,都没办法很好地把整个世界的各种模态统一起来,这可能需要一个更好的架构。然后就是一个不需要人类数据,通过跟世界互动就可以学习的AI,这样AI就不会局限于人类训练的数据量限制。
当然,除了这些,还有很多我没搞明白的,也有很多工程上的问题,但是我认为底层逻辑大致如此。我自己的认知迭代方式是,把每一个新事件套在这些逻辑上,如果能套进去,说明还没有超出认知,如果不能,那就再重新认识、迭代。
05 成长:AI应用的机会窗才刚刚开始,当下是最佳的成长周期,不求短期建功立业
我认为AI大模型带来的应用侧改变,一切才刚刚开始,甚至还不能说已经到来。理由很简单,因为基建还没稳定(无论是大模型,还是底层算力资源)。
所以我认为,当下是非常好的时机,来赋能用户、组建团队、培养人才、赋能业务、开始做知识管理和治理、开始积累AI大模型应用的经验和教训,持续迭代,一个场景成熟了就推广一个能力,不能指望短期内能建功立业。
《道德经》有云:“道可道,非常道”。关于AI的本质认知,其实还远未到清晰的程度,但是人认识世界不就是这样嘛,人们到现在也没有完全理解大脑是怎么玩儿的。
这轮AI大模型之所以称之为颠覆性创新,是因为桌子掀得太快。每个人在这轮变化中,都是迷茫和无助的,唯有刷新认知、重新定位,方能在5~10年后留下更多选择权。以上皆为个人观点,与君共勉~~
更多精彩内容可点击下方阅读原文了解
阅读原文