基于BERT模型的IMDB电影评论情感分类,是NLP经典的Hello World任务之一。
这篇文章我将带大家使用SwanLab、transformers、datasets三个开源工具,完成从数据集准备、代码编写、可视化训练的全过程。
观察了一下,中文互联网上似乎很少有能直接跑起来的BERT训练代码和教程,所以也希望这篇文章可以帮到大家。
- 代码:完整代码直接看本文第5节
- 模型与数据集:百度云,提取码: u9gi
- 实验过程:BERT-SwanLab
- SwanLab:https://swanlab.cn
- transformers:https://github.com/huggingface/transformers
- datasets:https://github.com/huggingface/datasets
1.环境安装
我们需要安装以下这4个Python库:
transformers>=4.41.0
datasets>=2.19.1
swanlab>=0.3.3
一键安装命令:
pip install transformers datasets swanlab
他们的作用分别是:
transformers:HuggingFace出品的深度学习框架,已经成为了NLP(自然语言处理)领域最流行的训练与推理框架。代码中用transformers主要用于加载模型、训练以及推理。datasets:同样是HuggingFace出品的数据集工具,可以下载来自huggingface社区上的数据集。代码中用datasets主要用于下载、加载数据集。swanlab:在线训练可视化和超参数记录工具,官网,可以记录整个实验的超参数、指标、训练环境、Python版本等,并可是化成图表,帮助你分析训练的表现。代码中用swanlab主要用于记录指标和可视化。
本文的代码测试于transformers4.41.0、datasets2.19.1、swanlab==0.3.3,更多库版本可查看SwanLab记录的Python环境。
2.加载BERT模型
BERT模型我们直接下载来自HuggingFace上由Google发布的bert-case-uncased预训练模型。
执行下面的代码,会自动下载模型权重并加载模型:
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
# 加载预训练的BERT tokenizer
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
如果国内下载比较慢的话,可以在这个百度云(提取码: u9gi)下载后,把bert-base-uncased文件夹放到根目录,然后改写上面的代码为:
model = AutoModelForSequenceClassification.from_pretrained('./bert-base-uncased', num_labels=2)
3.加载IMDB数据集
IMDB数据集(Internet Movie Database Dataset)是自然语言处理(NLP)领域中一个非常著名和广泛使用的数据集,主要应用于文本情感分析任务。
IMDB数据集源自全球最大的电影数据库网站Internet Movie Database(IMDb),该网站包含了大量的电影、电视节目、纪录片等影视作品信息,以及用户对这些作品的评论和评分。
数据集包括50,000条英文电影评论,这些评论被标记为正面或负面情感,用以进行二分类任务。其中,25,000条评论被分配为训练集,另外25,000条则作为测试集。训练集和测试集都保持了平衡的正负样本比例,即各含50%的正面评论和50%的负面评论.

我们同样直接下载HuggingFace上的imdb数据集,执行下面的代码,会自动下载数据集并加载:
from datasets import load_dataset
# 加载IMDB数据集
dataset = load_dataset('imdb')
如果国内下载比较慢的话,可以在这个百度云(提取码: u9gi)下载后,把imdb文件夹放到根目录,然后改写上面的代码为:
dataset = load_dataset('./imdb')
4.集成SwanLab
因为swanlab已经和transformers框架做了集成,所以将SwanLabCallback类传入到trainer的callbacks参数中即可实现实验跟踪和可视化:
from swanlab.integration.huggingface import SwanLabCallback
# 设置swanlab回调函数
swanlab_callback = SwanLabCallback()
...
# 定义Transformers Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
# 传入swanlab回调函数
callbacks=[swanlab_callback],
)
想了解更多关于SwanLab的知识,请看SwanLab官方文档。
5.开始训练!
训练过程看这里:BERT-SwanLab。
在首次使用SwanLab时,需要去官网注册一下账号,然后在用户设置复制一下你的API Key。
然后在终端输入swanlab login:
swanlab login
把API Key粘贴进去即可完成登录,之后就不需要再次登录了。
完整的训练代码:
"""
用预训练的Bert模型微调IMDB数据集,并使用SwanLabCallback回调函数将结果上传到SwanLab。
IMDB数据集的1是positive,0是negative。
"""
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from swanlab.integration.huggingface import SwanLabCallback
import swanlab
def predict(text, model, tokenizer, CLASS_NAME):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits).item()
print(f"Input Text: {text}")
print(f"Predicted class: {int(predicted_class)} {CLASS_NAME[int(predicted_class)]}")
return int(predicted_class)
# 加载IMDB数据集
dataset = load_dataset('imdb')
# 加载预训练的BERT tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 定义tokenize函数
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
# 对数据集进行tokenization
tokenized_datasets = dataset.map(tokenize, batched=True)
# 设置模型输入格式
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# 加载预训练的BERT模型
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 设置训练参数
training_args = TrainingArguments(
output_dir='./results',
eval_strategy='epoch',
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_first_step=100,
# 总的训练轮数
num_train_epochs=3,
weight_decay=0.01,
report_to="none",
# 单卡训练
)
CLASS_NAME = {0: "negative", 1: "positive"}
# 设置swanlab回调函数
swanlab_callback = SwanLabCallback(project='BERT',
experiment_name='BERT-IMDB',
config={'dataset': 'IMDB', "CLASS_NAME": CLASS_NAME})
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
callbacks=[swanlab_callback],
)
# 训练模型
trainer.train()
# 保存模型
model.save_pretrained('./sentiment_model')
tokenizer.save_pretrained('./sentiment_model')
# 测试模型
test_reviews = [
"I absolutely loved this movie! The storyline was captivating and the acting was top-notch. A must-watch for everyone.",
"This movie was a complete waste of time. The plot was predictable and the characters were poorly developed.",
"An excellent film with a heartwarming story. The performances were outstanding, especially the lead actor.",
"I found the movie to be quite boring. It dragged on and didn't really go anywhere. Not recommended.",
"A masterpiece! The director did an amazing job bringing this story to life. The visuals were stunning.",
"Terrible movie. The script was awful and the acting was even worse. I can't believe I sat through the whole thing.",
"A delightful film with a perfect mix of humor and drama. The cast was great and the dialogue was witty.",
"I was very disappointed with this movie. It had so much potential, but it just fell flat. The ending was particularly bad.",
"One of the best movies I've seen this year. The story was original and the performances were incredibly moving.",
"I didn't enjoy this movie at all. It was confusing and the pacing was off. Definitely not worth watching."
]
model.to('cpu')
text_list = []
for review in test_reviews:
label = predict(review, model, tokenizer, CLASS_NAME)
text_list.append(swanlab.Text(review, caption=f"{label}-{CLASS_NAME[label]}"))
if text_list:
swanlab.log({"predict": text_list})
swanlab.finish()
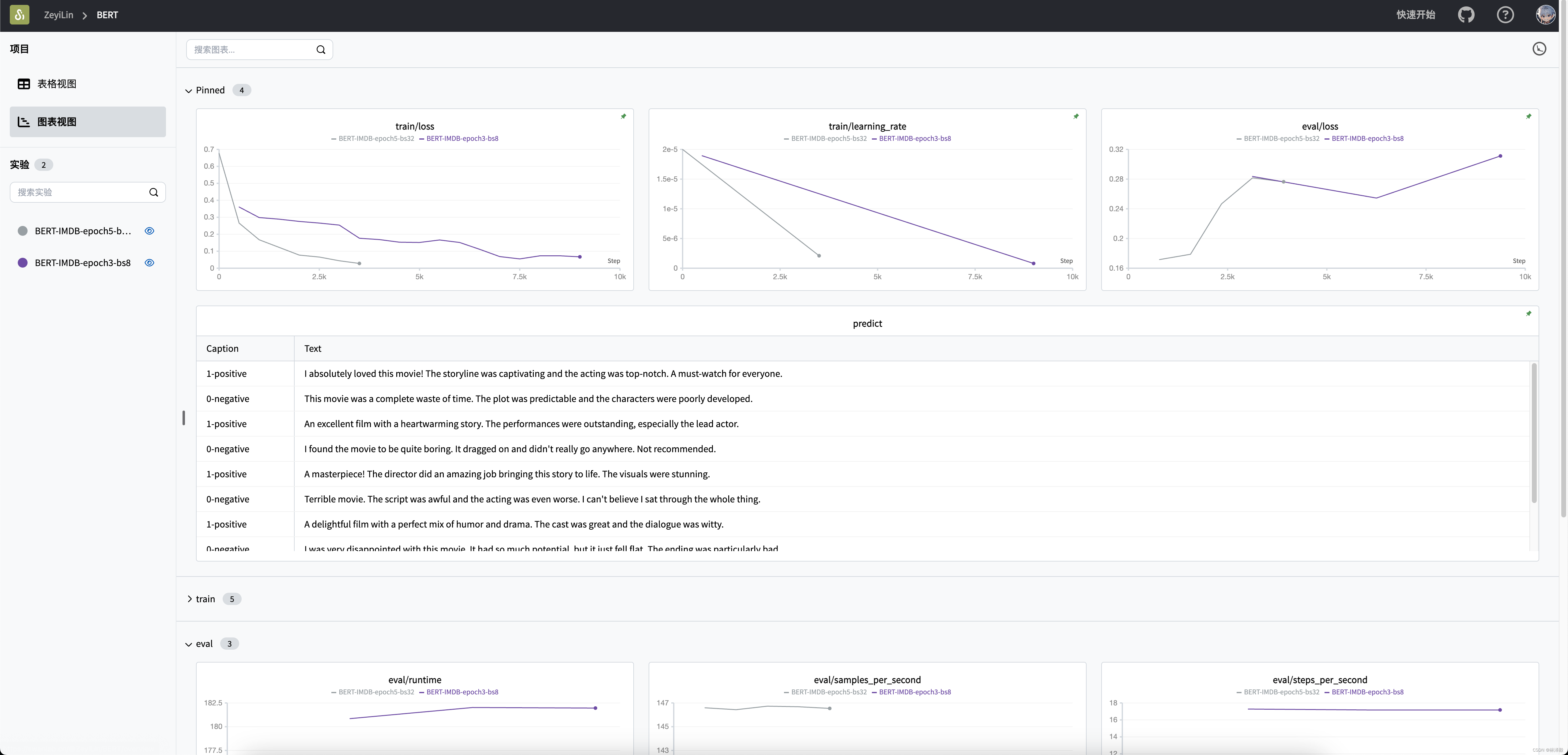
训练可视化过程:
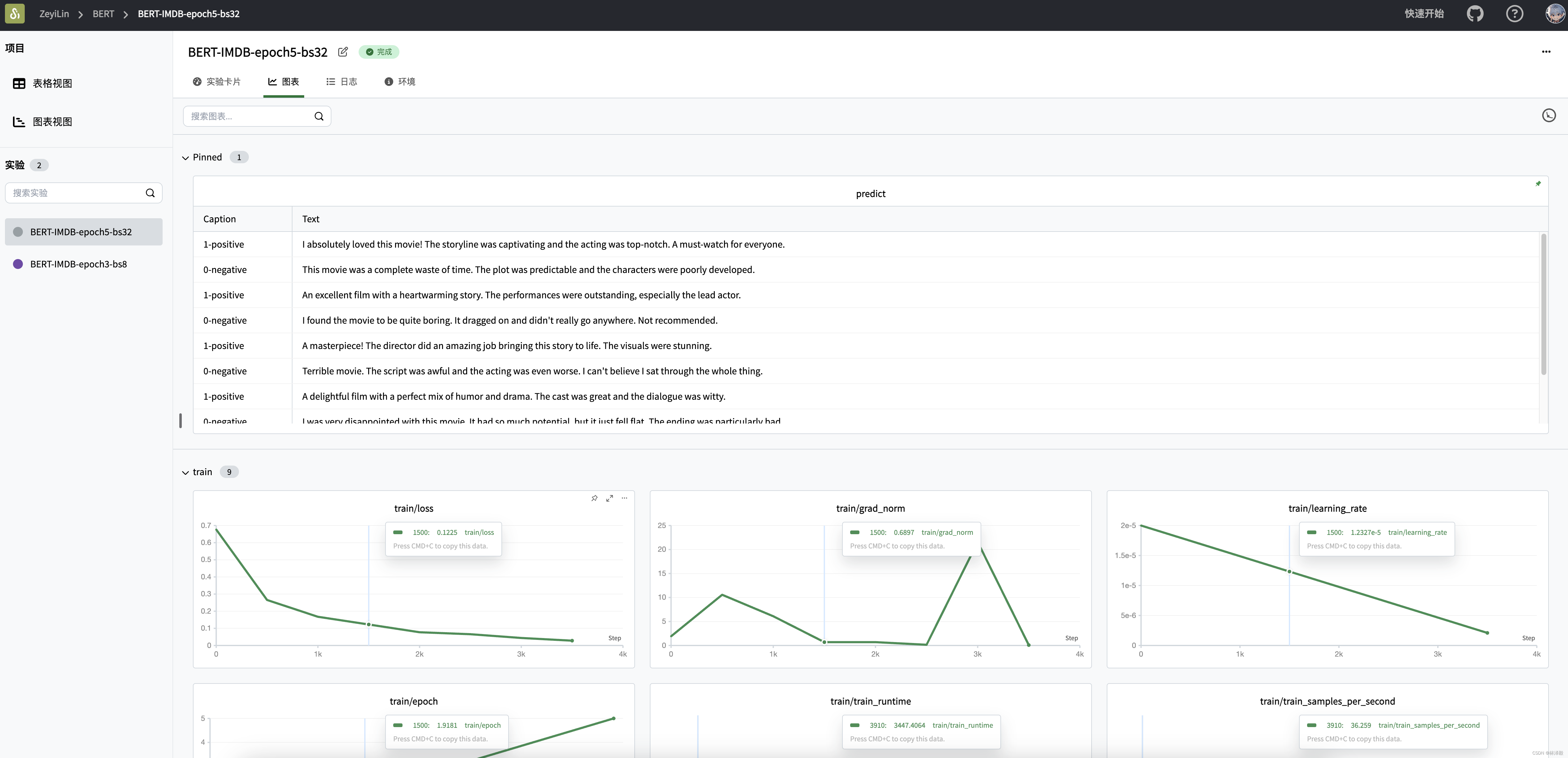
训练大概需要6G左右的显存,我在一块3090上跑了,1个epoch大概要12~13分钟时间。
训练的推理结果:

这里我生成了10个比较简单的测试文本,微调后的BERT模型基本都能答对。
至此,我们顺利完成了用BERT预训练模型微调IMDB数据的训练过程~
相关链接
- 代码:完整代码直接看本文第5节
- 模型与数据集:百度云,提取码: u9gi
- 实验过程:BERT-SwanLab
- SwanLab:https://swanlab.cn
- transformers:https://github.com/huggingface/transformers
- datasets:https://github.com/huggingface/datasets