自动微分和autograde
自动微分
机器学习/深度学习关键部分之一:反向传播,通过计算微分更新参数值。
自动微分的精髓在于它发现了微分计算的本质:微分计算就是一系列有限的可微算子的组合。
自动微分以链式法则为基础,依据运算逻辑把公式整理出一张有向无环图(DAG)
自动微分将一个复杂的数学运算过程分解为一系列简单的基本运算, 其中每一项基本运算都可以通过查表得出来。
自动微分法被认为是对计算机程序进行非标准的解释。
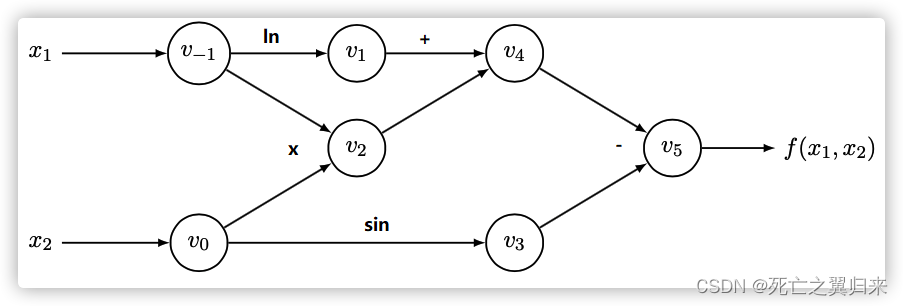
Torch autograde
pytorch实现了torch.autograd的内置反向自动微分引擎,号称能支持任何计算图的梯度自动计算。
autograd 记录了一个计算图,记录每一个张量的操作历史。在创建张量时,如果设置 requires_grad 为Ture,那么 Pytorch 就知道需要对该张量进行自动求导。
autograde具体动作如下:
前向传播计算时
- 运行请求的操作以计算结果张量
- 建立一个计算梯度的DAG图,在DAG图中维护所有已执行操作(包括操作的梯度函数以及由此产生的新张量)的记录 。每个tensor梯度计算的具体方法存放于tensor节点的grad_fn属性中。
在 DAG 根上调用.backward() 来执行后向传播
- 利用.grad_fn计算每个张量的梯度,并且依据此构建出包含梯度计算方法的反向传播计算图。
- 将梯度累积在各自的张量.grad属性中,并且使用链式法则,一直传播到叶子张量。
- 每次迭代都会重新创建计算图,这使得我们可以使用Python代码在每次迭代中更改计算图的形状和大小。
前向传播
策略:
- DDP 获取输入并将其传递给本地模型。
- 每个进程读去自己的训练数据,DistributedSampler确保每个进程读到的数据不同。
- 使用 _rebuild_buckets 来重置桶(需要计算梯度的参数已经分桶)
- 模型进行前向计算,结果设置为 out。
如果find_unused_parameters设置为True,DDP 会分析本地模型的输出,从 out 开始遍历计算图,把未使用参数标示为 ready,因为每次计算图都会改变,所以每次都要遍历。
此模式(Mode)允许在模型的子图上向后运行,并且 DDP 通过从模型输出out遍历 autograd 图,将所有未使用的参数标记为就绪,以减少反向传递中涉及的参数。
tips:遍历 autograd 图会引入额外的开销,因此应用程序仅在必要时才设置 find_unused_parameters为True。
后向传播
策略:
- Autograd 引擎进行梯度计算;当一个梯度准备好时,它在该梯度累加器上的相应 DDP hooks将自动触发
- 在 autograd_hook 之中进行all-reduce。如果某个桶里面梯度都ready,则该桶是ready。
- 当一个桶中的梯度都准备好时,会在该桶上Reducer启动异步all-reduce以计算所有进程的梯度平均值。(一边做反向计算,一边做梯度规约)
- 所有桶都准备好时,Reducer将阻塞等待所有allreduce操作完成。完成此操作后,将平均梯度写入param.grad所有参数的字段。
- 在向后传播完成之后,跨不同DDP进程的对应的相同参数上的 grad 字段应该是相等的。
- 梯度被归并之后,会再传输回autograd引擎。
数据并行
假设显卡数量为N,将每张卡的梯度分为N个桶,每张卡的梯度总量是K。
每张卡Scatter Reduce阶段:接收 N-1 次数据
每张卡allgather 阶段:接收 N-1 次数据
每张卡传输数据总量:2K*(1-1/N) ~= 2K
![[图片]](https://img-blog.csdnimg.cn/direct/051d7bd3e2e24746bec8ad12e7ed77fc.png#pic_center)
![[图片]](https://img-blog.csdnimg.cn/direct/f106ecc89cd743e69299cb8662fa416e.png#pic_center)
...
![[图片]](https://img-blog.csdnimg.cn/direct/d0b3faa3766840928666a54672c12e20.png#pic_center)
![[图片]](https://img-blog.csdnimg.cn/direct/de76e24d169b4f2682d0249bad49246d.png#pic_center)
数据并行细节总结:
- DDP中的Allreduce使用的是ring-allreduce,并且使用bucket来引入异步
- Allreduce发生在前向传播后的梯度同步阶段,并且与反向传播计算重叠
- Ring-allreduce优化了带宽,适用于中规模的集群,但其可能存在精度问题,不适合大规模的集群?
- allreduce的速度受到环中相邻GPU之间最慢连接的限制(木桶效应)
参考文档:
- pytorch ddp实现论文 2020-08-01




![[Algorithm][动态规划][路径问题][不同路径][不同路径Ⅱ][珠宝的最高价值]详细讲解](https://img-blog.csdnimg.cn/direct/ec3c5fa9e1ed4768818e45f6a98c52ec.png)