前言
仅记录学习过程,有问题欢迎讨论
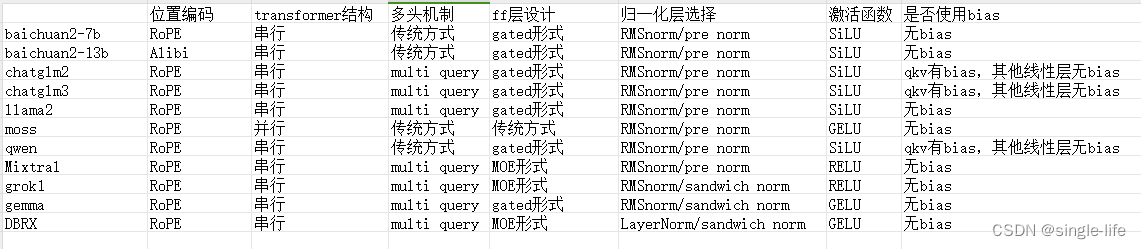
LLM的结构变化:
Muti-head 共享:
- Q继续切割为muti-head,但是K,V少切,比如切为2个,然后复制到n个muti-head
- 减少参数量,加速训练

attention结构改动:
- self-attention和feedforward并行计算(bert为顺序计算)
不算主流

归一化层位置变化:
- 在attention之前(pre norm),在feedforward之后(正常为 attention->++±>layer->FFN–>++±->layer)

归一化函数变化:layerNorm 改为 RMSNorm
- 主流为norm层提前到attention层之前

激活函数变化
- swish:两个线性层 gated

LLama2模型结构:
- transformer Block:
RMSNorm–>Liner–>q*k(T) *V -->softmax–>Liner–>RMSNorm–>swish–>Liner
计算qk带上位置编码

MOE架构:
- 在feed forward中有多个类型的前馈层,根据分类的结果来选择,每个前馈层都是一个专家

位置编码:
- 因为transformer的输入是token,而不是序列,所以需要位置编码来表示token之间的相对位置
- 正弦、余弦编码:每个字按公式计算位置维度信息,但是不能学习,得到position encoding+word embedding
- bert 自带可训练的位置编码 position embedding;但是无法外推,最大文本长度是多少就是多少(512)
- ROPE相对(旋转)位置编码;
在计算某个词的emb时,映射其之前的位置emb信息(Xm,Xn,m-n)
可以外推,也无需训练 - Alibi位置编码;
在QK中 加上位置矩阵m
总结:对于文本类任务,位置信息是重要的
可学习的位置编码缺点在于没有长度外推性
相对位置编码不需要学习,有一定的长度外推性,但是相对位置编码具有天然的远程衰减性
目前的主流是ROPE和Alibi两种相对位置编码
多模态:
常见:图像、音频、视频、文本
罕见:3D模型,神经信号,气味
输入到输出是不同的模态
要点:文本、图像如何编码;二者如何交互
flamingo:qkv ,其中Q为文本,KV为图像(KV决定输出),所以计算文本和图像之前的相关性,在attention中交互
LLava:文本和图像emb拼接 走类似llama的流程,但是没有多头机制,本质上还是self attention
cv基础:
图像=矩阵 使用RGB 3通道叠加展示色彩
视频就是多个图像组成的张量
Diffuse Model: sora背后的技术
diffusion思想:随机生成一副噪音图像,持续的进行有条件的去噪,直到显示出有意义的图像(类似于对石头雕像)
Denoise:使用Noise predictor 预测噪声(输入输出都是矩阵),
然后去噪就是:噪声图像-噪声
贴一个测试图: