聚类算法
小白的机器学习笔记 2024/5/15 9:52
文章目录
- 聚类算法
- 步骤
- K-means算法
- 优缺点
- 示例

聚类算法的核心思想:
样本点到每个中心点的距离,最近的就是这个类
步骤
要聚成3类,先初始化3个点
第一步大致确定类别
第二步更新中心点
第三步继续做第一步
所有中心点都不再变化时,聚类结束
为什么中心点的值是所有坐标点的均值?
K-means算法

优缺点

示例
#coding=UTF-8
import pandas as pd
defaultencoding = 'utf-8'
import matplotlib as mpl
import matplotlib.pyplot as plt
import sys
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
import sklearn.datasets as ds#导入sklearn数据集
#1.加载数据
N=1500
#make_blobs生成团状数据,1500个样本 n_features=2列数等于2
x1,y1=ds.make_blobs(n_samples=N,n_features=2,centers=4,cluster_std=1,random_state=2)#
from sklearn.cluster import KMeans
#2.创建模型和训练模型
kmeans=KMeans(n_clusters=4,init="k-means++")
kmeans.fit(x1)#用第一份数据进行训练 求中心点及每个样本的类别
y1_hat=kmeans.predict(x1)#预测y值
#3.评估
print(kmeans.score(x1)) #所有样本到各中心点距离和相反数 越大越好
plt.figure()
plt.subplot(2,1,1)
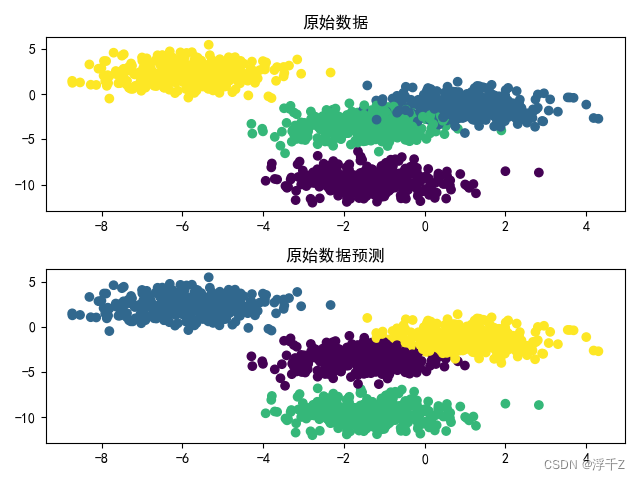
plt.scatter(x1[:,0],x1[:,1],c=y1,label="原始数据")
plt.title("原始数据")
plt.subplot(2,1,2)
plt.scatter(x1[:,0],x1[:,1],c=y1_hat,label="预测数据")
plt.title("原始数据预测")
plt.show()
#对不同方差预测不准 对旋转数据预测不准
print("样本到所有中心点距离和", kmeans.inertia_)
print("clf_KMeans聚类中心\n", (kmeans.cluster_centers_))
quantity = pd.Series(kmeans.labels_).value_counts()
print ("cluster2聚类数量\n", (quantity))
#获取聚类之后每个聚类中心的数据
# print kmeans.labels_
print(x1[kmeans.labels_==0])#打0类别样本
# print"类别为1的数据\n",(df.iloc[res0.index])