一、每日一题
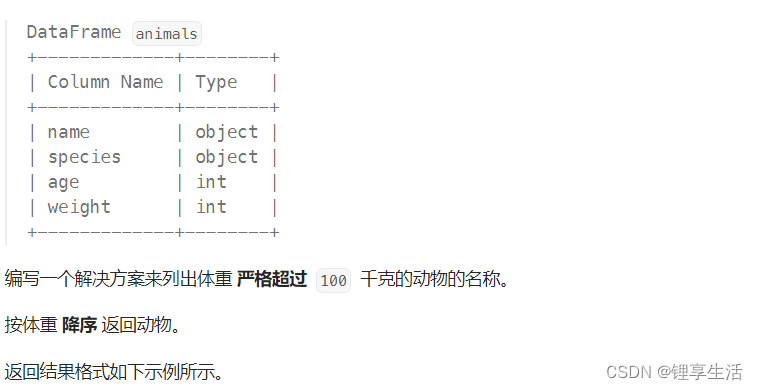
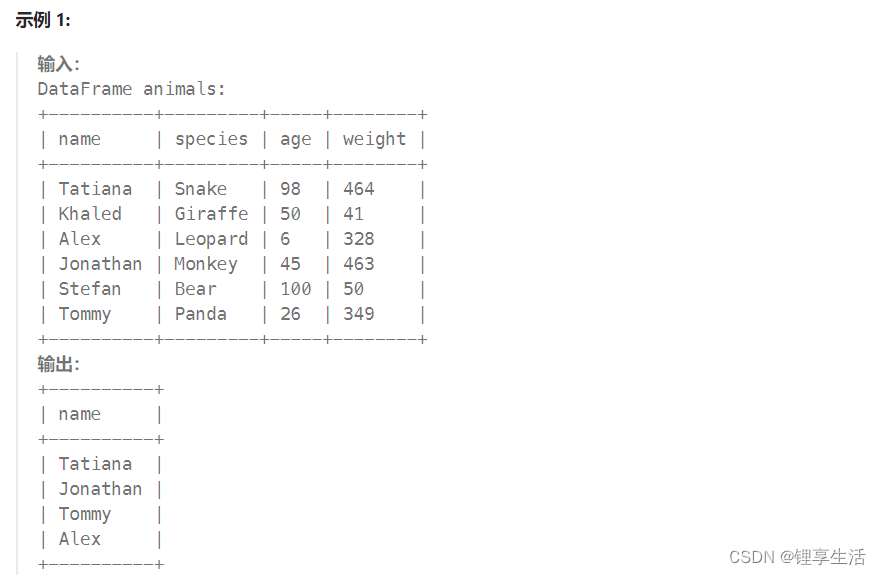 ;::
;::
解答:
import pandas as pd
def findHeavyAnimals(animals: pd.DataFrame) -> pd.DataFrame:
heavy_animals = animals[animals['weight'] > 100].sort_values(by='weight', ascending=False)
result = heavy_animals[['name']]
return result题源:Leetcode
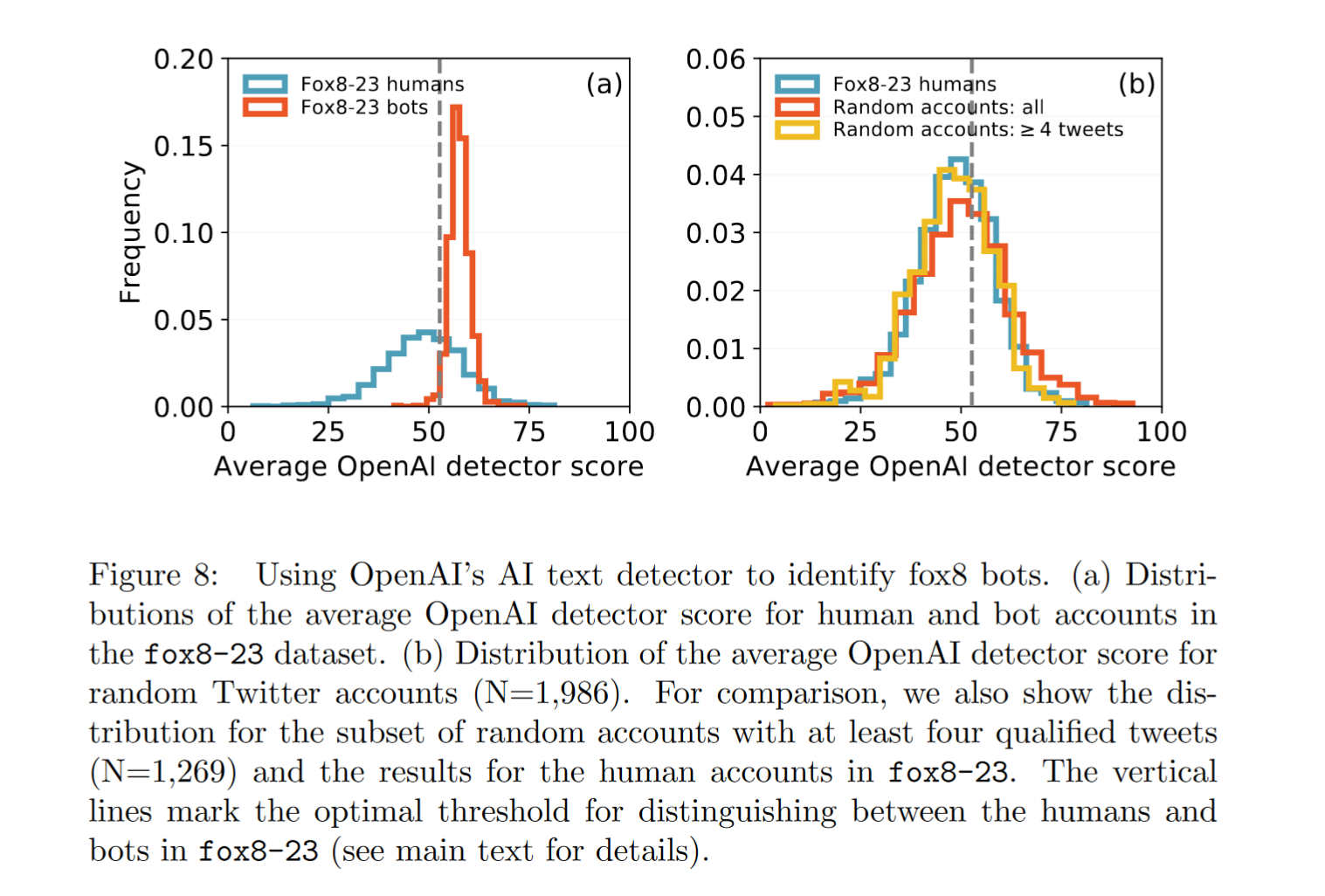
二、总结
本题用到了布尔索引以及排序函数。
1.布尔索引
布尔索引是Pandas库中一种强大的功能,它允许你根据条件逻辑直接从DataFrame或Series中选择数据子集。这种索引方式基于一个布尔数组,数组中的每个元素对应DataFrame/Series中的一个元素,值为True表示选择该元素,False则不选择。
基本概念
在Pandas中,当你对一个DataFrame或Series应用一个布尔条件时,Pandas会自动将这个条件应用于数据结构的每个元素,并生成一个相同形状的布尔数组。然后,你可以直接用这个布尔数组作为索引来选取满足条件的行或列。
应用场景
布尔索引常用于以下几种场景:
- 筛选特定值:例如,选择所有价格大于某个阈值的商品。
- 过滤缺失数据:通过检查是否为NaN来去除含有缺失值的行或列。
- 复合条件:结合多个条件进行复杂筛选,如同时满足年龄和收入两个条件的人群。
- 基于其他列的值:利用一个或多个列的值作为筛选依据。
实例:
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'Math': [88, 95, 70, 92, 85],
'English': [85, 80, 90, 88, 92]}
scores = pd.DataFrame(data)
# 选择数学成绩超过90分的学生记录:
high_scores = scores[scores['Math'] > 90]
print(high_scores)
# 选择数学和英语成绩都超过85分的学生:
both_high = scores[(scores['Math'] > 85) & (scores['English'] > 85)]
print(both_high)
# 选择数学成绩没有达到80分的学生:
low_math_scores = scores[scores['Math'] < 80]
print(low_math_scores)2.sort_values()排序
sort_values() 是 Pandas 库中一个非常实用的函数,用于对 DataFrame 或 Series 中的数据按指定列或行的值进行排序。这个函数提供了丰富的选项来控制排序的方式,包括升序或降序、处理缺失值的位置等。下面是 sort_values() 函数的基本用法和参数说明:
基本用法:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False,
kind='quicksort', na_position='last', ignore_index=False, key=None)参数说明:
-
by:这是排序的主要参数,可以是单个列名(字符串),或者是一个列名的列表,用于多列排序。列名也可以是索引级别,用于对MultiIndex的排序。
-
axis:指定排序的轴,接受
0或'index'表示按列排序(默认),1或'columns'表示按行排序。 -
ascending:确定排序的顺序,可以是布尔值(默认为
True表示升序,False表示降序),或者是一个布尔值的列表,用于多列排序时分别指定每列的排序方向。 -
inplace:如果设置为
True,则会就地排序DataFrame,不返回新的DataFrame实例(默认为False)。 -
kind:排序算法,可选的排序类型有 'quicksort', 'mergesort', 'heapsort' 等,不同的算法会影响排序的性能(默认为 'quicksort')。
-
na_position:决定缺失值(NaN)的位置,可选
'first'或'last',分别表示将缺失值排在最前或最后(默认为'last')。 -
ignore_index:如果设置为
True,则在返回的DataFrame中重置索引(默认为False)。 -
key:这是一个可选参数,可以是一个函数或者函数列表,用于在排序前对值进行预处理。
实例:
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David'],
'age': [24, 30, 35, 28],
'score': [88, 95, 90, 85]}
df = pd.DataFrame(data)
# 升序排序 age 列
df_sorted = df.sort_values(by='age')
# 降序排序 score 列
df_sorted_desc = df.sort_values(by='score', ascending=False)
# 按多列排序,先按 age 升序,再按 score 降序
df_multi_sorted = df.sort_values(by=['age', 'score'], ascending=[True, False])官方文档
2024.5.16