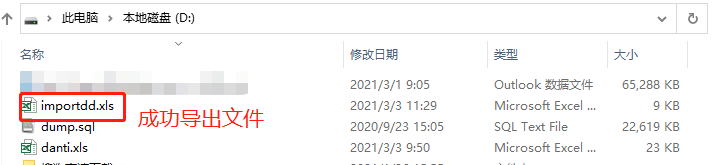
导出onnx模型
yolov5官方地址 git clone https://github.com/ultralytics/yolov5
利用官方命令导出python export.py --weights yolov5n.pt --include onnx
利用代码导出
import os
import sys
os.chdir(sys.path[0])
import onnx
import torch
sys.path.append('..')
from models.common import DetectMultiBackend
from models.experimental import attempt_load
DEVICE='cuda' if torch.cuda.is_available else 'cpu'
def main():
"""create model """
input = torch.randn(1, 3, 640, 640, requires_grad=False).float().to(torch.device(DEVICE))
model = attempt_load('./model/yolov5n.pt', device=DEVICE, inplace=True, fuse=True) # load FP32 model
#model = DetectMultiBackend('./model/yolov5n.pt', data=input)
model.to(DEVICE)
torch.onnx.export(model,
input,
'yolov5n_self.onnx', # name of the exported onnx model
export_params=True,
opset_version=12,
do_constant_folding=False,
input_names=["images"])
if __name__=="__main__":
main()onnx模型测试
import os
import sys
os.chdir(sys.path[0])
import onnxruntime
import torch
import torchvision
import numpy as np
import time
import cv2
sys.path.append('..')
from ultralytics.utils.plotting import Annotator, colors
ONNX_MODEL="./yolov5n.onnx"
DEVICE='cuda' if torch.cuda.is_available() else 'cpu'
def xywh2xyxy(x):
"""Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right."""
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
return y
def box_iou(box1, box2, eps=1e-7):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nm=0, # number of masks
):
"""
Non-Maximum Suppression (NMS) on inference results to reject overlapping detections.
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
# Checks
assert 0 <= conf_thres <= 1, f"Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0"
assert 0 <= iou_thres <= 1, f"Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0"
device = prediction.device
mps = "mps" in device.type # Apple MPS
if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
prediction = prediction.cpu()
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.5 + 0.05 * bs # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
mi = 5 + nc # mask start index
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
mask = x[:, mi:] # zero columns if no masks
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = x[:, 5:mi].max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
if merge and (1 < n < 3e3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if mps:
output[xi] = output[xi].to(device)
if (time.time() - t) > time_limit:
break # time limit exceeded
return output
def draw_bbox(image, result, color=(0, 0, 255), thickness=2):
# img_path = cv2.cvtColor(img_path, cv2.COLOR_BGR2RGB)
image = image.copy()
for point in result:
x1,y1,x2,y2=point
cv2.rectangle(image, (x1, y1), (x2, y2), color, thickness)
return image
def main():
input=torch.load("input.pt").to('cpu')
input_array=np.array(input)
onnx_model = onnxruntime.InferenceSession(ONNX_MODEL)
input_name = onnx_model.get_inputs()[0].name
out = onnx_model.run(None, {input_name:input_array})
out_tensor = torch.tensor(out).to(DEVICE)
pred = non_max_suppression(out_tensor,0.25,0.45,classes=None,agnostic=False,max_det=1000)
# Process predictions
for i, det in enumerate(pred): # per image
im0_=cv2.imread('../data/images/bus.jpg')
im0=im0_.reshape(1,3,640,640)
names=torch.load('name.pt')
annotator = Annotator(im0, line_width=3, example=str(names))
coord=[]
image=im0.reshape(640,640,3)
if len(det):
# Rescale boxes from img_size to im0 size
#det[:, :4] = scale_boxes(im0.shape[2:], det[:, :4], im0.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
# Add bbox to image
c = int(cls) # integer class
label = f"{names[c]} {conf:.2f}"
# 创建两个顶点坐标子数组,并将它们组合成一个列表``
coord.append([int(xyxy[0].item()), int(xyxy[1].item()),int(xyxy[2].item()), int(xyxy[3].item())])
image=draw_bbox(image,coord)
# Stream results
save_success =cv2.imwrite('result.jpg', image)
print(f"save image end {save_success}")
if __name__=="__main__":
main()测试结果

板端部署
环境准备
搭建好rknntoolkit以及rknpu环境
大致流程

模型转换
新建export_rknn.py用于将onnx模型转化为rknn模型
import os
import sys
os.chdir(sys.path[0])
import numpy as np
import cv2
from rknn.api import RKNN
import torchvision
import torch
import time
ONNX_MODEL = './model/yolov5n.onnx'
RKNN_MODEL = './model/yolov5n.rknn'
def main():
"""Create RKNN object"""
rknn = RKNN()
if not os.path.exists(ONNX_MODEL):
print('model not exist')
exit(-1)
"""pre-process config"""
print('--> Config model')
rknn.config(reorder_channel='0 1 2',
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
optimization_level=0,
target_platform = ['rv1126'],
output_optimize=1,
quantize_input_node=True)
print('done')
"""Load ONNX model"""
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL,
inputs=['images'],
input_size_list = [[3, 640, 640]],
outputs=['output0'])
if ret != 0:
print('Load yolov5 failed!')
exit(ret)
print('done')
"""Build model"""
print('--> Building model')
#ret = rknn.build(do_quantization=True,dataset='./data/data.txt')
ret = rknn.build(do_quantization=False,pre_compile=True)
if ret != 0:
print('Build yolov5 failed!')
exit(ret)
print('done')
"""Export RKNN model"""
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export yolov5rknn failed!')
exit(ret)
print('done')
if __name__=="__main__":
main()新建test_rknn.py用于测试rknn模型
import os
import sys
os.chdir(sys.path[0])
import numpy as np
import cv2
from rknn.api import RKNN
import torchvision
import torch
import time
RKNN_MODEL = './model/yolov5n.rknn'
DATA='./data/bus.jpg'
def xywh2xyxy(x):
coord=[]
for x_ in x:
xl=x_[0]-x_[2]/2
yl=x_[1]-x_[3]/2
xr=x_[0]+x_[2]/2
yr=x_[1]+x_[3]/2
coord.append([xl,yl,xr,yr])
coord=torch.tensor(coord).to(x.device)
return coord
def box_iou(box1, box2, eps=1e-7):
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nm=0, # number of masks
):
# Checks
assert 0 <= conf_thres <= 1, f"Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0"
assert 0 <= iou_thres <= 1, f"Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0"
device = prediction.device
mps = "mps" in device.type # Apple MPS
if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
prediction = prediction.cpu()
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
count_true = torch.sum(xc.type(torch.int))
# Settings
# min_wh = 2 # (pixels) minimum box width and height
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.5 + 0.05 * bs # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
mi = 5 + nc # mask start index
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
mask = x[:, mi:] # zero columns if no masks
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = x[:, 5:mi].max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
if merge and (1 < n < 3e3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if mps:
output[xi] = output[xi].to(device)
if (time.time() - t) > time_limit:
break # time limit exceeded
return output
def draw_bbox(image, result, color=(0, 0, 255), thickness=2):
# img_path = cv2.cvtColor(img_path, cv2.COLOR_BGR2RGB)
image = image.copy()
for point in result:
x1,y1,x2,y2=point
cv2.rectangle(image, (x1, y1), (x2, y2), color, thickness)
return image
def main():
# Create RKNN object
rknn = RKNN()
rknn.list_devices()
#load rknn model
ret = rknn.load_rknn(path=RKNN_MODEL)
if ret != 0:
print('load rknn failed')
exit(ret)
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(target='rv1126', device_id='86d4fdeb7f3af5b1',perf_debug=True,eval_mem=True)
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Set inputs
image=cv2.imread('./data/bus.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[image])
#post process
out_tensor = torch.tensor(outputs)
pred = non_max_suppression(out_tensor,0.25,0.45,classes=None,agnostic=False,max_det=1000)
# Process predictions
for i, det in enumerate(pred): # per image
im0_=cv2.imread(DATA)
im0=im0_.reshape(1,3,640,640)
coord=[]
image=im0.reshape(640,640,3)
if len(det):
"""Write results"""
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
coord.append([int(xyxy[0].item()), int(xyxy[1].item()),int(xyxy[2].item()), int(xyxy[3].item())])
print(f"[{coord[0][0]},{coord[0][1]},{coord[0][2]},{coord[0][3]}]:ID is {c}")
image=draw_bbox(image,coord)
# Stream results
save_success =cv2.imwrite('result.jpg', image)
print(f"save image end {save_success}")
rknn.release()
if __name__=="__main__":
main()板端cpp推理代码编写
拷贝一份template改名为yolov5,目录结构如下
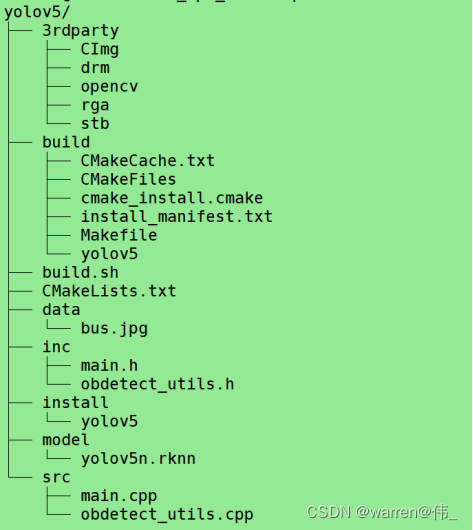
前处理代码
void PreProcess(cv::Mat *image)
{
cv::cvtColor(*image, *image, cv::COLOR_BGR2RGB);
}后处理代码
1:输出维度为[1,25200,85],其中85的前四个为中心点的x,y以及框的宽和高,第五个为框的置信度,后面80个为类别的置信度(有80个类别);
2:25200=(80∗80+40∗40+20∗20)∗3,stride为8、16、32,640/8=80,640/16=40,640/32=20
3:NMS删除冗余候选框
1:IOU交并比:检测两个框重叠程度=交集面积/并集面积
2:主要步骤:
- 首先筛选出大于阈值的所有候选框(>0.4)
- 接着针对每一个种类将候选框进行分类
- 找到第n个类别进行循环操作
- 先找到置信度最大的框,放到保留区
- 和候选区的其他框计算交并比(IOU),若大于iou阈值则删除
- 再从候选区找到第二大的候选框放到保留区
- 重复4操作,直至候选区没有框
- 重复3操作,直至所有类别
float iou(Bbox box1, Bbox box2) {
/*
iou=交并比
*/
int x1 = max(box1.x, box2.x);
int y1 = max(box1.y, box2.y);
int x2 = min(box1.x + box1.w, box2.x + box2.w);
int y2 = min(box1.y + box1.h, box2.y + box2.h);
int w = max(0, x2 - x1);
int h = max(0, y2 - y1);
float over_area = w * h;
return over_area / (box1.w * box1.h + box2.w * box2.h - over_area);
}
bool judge_in_lst(int index, vector<int> index_lst) {
//若index在列表index_lst中则返回true,否则返回false
if (index_lst.size() > 0) {
for (int i = 0; i < int(index_lst.size()); i++) {
if (index == index_lst.at(i)) {
return true;
}
}
}
return false;
}
int get_max_index(vector<Detection> pre_detection) {
//返回最大置信度值对应的索引值
int index;
float conf;
if (pre_detection.size() > 0) {
index = 0;
conf = pre_detection.at(0).conf;
for (int i = 0; i < int(pre_detection.size()); i++) {
if (conf < pre_detection.at(i).conf) {
index = i;
conf = pre_detection.at(i).conf;
}
}
return index;
}
else {
return -1;
}
}
vector<int> nms(vector<Detection> pre_detection, float iou_thr)
{
/*
返回需保存box的pre_detection对应位置索引值
*/
int index;
vector<Detection> pre_detection_new;
//Detection det_best;
Bbox box_best, box;
float iou_value;
vector<int> keep_index;
vector<int> del_index;
bool keep_bool;
bool del_bool;
if (pre_detection.size() > 0) {
pre_detection_new.clear();
// 循环将预测结果建立索引
for (int i = 0; i < int(pre_detection.size()); i++) {
pre_detection.at(i).index = i;
pre_detection_new.push_back(pre_detection.at(i));
}
//循环遍历获得保留box位置索引-相对输入pre_detection位置
while (pre_detection_new.size() > 0) {
index = get_max_index(pre_detection_new);
if (index >= 0) {
keep_index.push_back(pre_detection_new.at(index).index); //保留索引位置
// 更新最佳保留box
box_best.x = pre_detection_new.at(index).bbox[0];
box_best.y = pre_detection_new.at(index).bbox[1];
box_best.w = pre_detection_new.at(index).bbox[2];
box_best.h = pre_detection_new.at(index).bbox[3];
for (int j = 0; j < int(pre_detection.size()); j++) {
keep_bool = judge_in_lst(pre_detection.at(j).index, keep_index);
del_bool = judge_in_lst(pre_detection.at(j).index, del_index);
if ((!keep_bool) && (!del_bool)) { //不在keep_index与del_index才计算iou
box.x = pre_detection.at(j).bbox[0];
box.y = pre_detection.at(j).bbox[1];
box.w = pre_detection.at(j).bbox[2];
box.h = pre_detection.at(j).bbox[3];
iou_value = iou(box_best, box);
if (iou_value > iou_thr) {
del_index.push_back(j); //记录大于阈值将删除对应的位置
}
}
}
//更新pre_detection_new
pre_detection_new.clear();
for (int j = 0; j < int(pre_detection.size()); j++) {
keep_bool = judge_in_lst(pre_detection.at(j).index, keep_index);
del_bool = judge_in_lst(pre_detection.at(j).index, del_index);
if ((!keep_bool) && (!del_bool)) {
pre_detection_new.push_back(pre_detection.at(j));
}
}
}
}
}
del_index.clear();
del_index.shrink_to_fit();
pre_detection_new.clear();
pre_detection_new.shrink_to_fit();
return keep_index;
}
vector<Detection> PostProcess(float* prob,float conf_thr=0.3,float nms_thr=0.5)
{
vector<Detection> pre_results;
vector<int> nms_keep_index;
vector<Detection> results;
bool keep_bool;
Detection pre_res;
float conf;
int tmp_idx;
float tmp_cls_score;
for (int i = 0; i < 25200; i++) {
tmp_idx = i * (CLSNUM + 5);
pre_res.bbox[0] = prob[tmp_idx + 0]; //cx
pre_res.bbox[1] = prob[tmp_idx + 1]; //cy
pre_res.bbox[2] = prob[tmp_idx + 2]; //w
pre_res.bbox[3] = prob[tmp_idx + 3]; //h
conf = prob[tmp_idx + 4]; // 是为目标的置信度
tmp_cls_score = prob[tmp_idx + 5] * conf; //conf_thr*nms_thr
pre_res.class_id = 0;
pre_res.conf = 0;
// 这个过程相当于从除了前面5列,在后面的cla_num个数据中找出score最大的值作为pre_res.conf,对应的列作为类id
for (int j = 1; j < CLSNUM; j++) {
tmp_idx = i * (CLSNUM + 5) + 5 + j; //获得对应类别索引
if (tmp_cls_score < prob[tmp_idx] * conf){
tmp_cls_score = prob[tmp_idx] * conf;
pre_res.class_id = j;
pre_res.conf = tmp_cls_score;
}
}
if (conf >= conf_thr) {
pre_results.push_back(pre_res);
}
}
//使用nms,返回对应结果的索引
nms_keep_index=nms(pre_results,nms_thr);
// 茛据nms找到的索引,将结果取出来作为最终结果
for (int i = 0; i < int(pre_results.size()); i++) {
keep_bool = judge_in_lst(i, nms_keep_index);
if (keep_bool) {
results.push_back(pre_results.at(i));
}
}
pre_results.clear();
pre_results.shrink_to_fit();
nms_keep_index.clear();
nms_keep_index.shrink_to_fit();
return results;
}结果展示

至此板端部署结束,接下来进行优化;
优化加速
可以看到模型推理的时间近2s,对于实时处理来说是远远不够的,因此需要对模型进行加速