VMamba:视觉状态空间模型

code:https://github.com/MzeroMiko/VMamba
Background
CNN拥有线性复杂度因而可以处理高分辨率的图像,而ViT在拟合能力方面超过了CNN,但ViT是二次复杂度,在处理高分辨率图像时计算开销较大。ViT通过整合全局感受野和动态权重实现了卓越的视觉建模性能,使用状态空间模型可以在继承这些组件的同时提高计算效率。
Novelty
选择性扫描状态空间模型(S6)可以将二次复杂度降低为线性,但由于视觉数据的非因果性,直接将这种策略应用于图像会因为无法估计当前patch与未扫描patch之间的关系。于是引入的交叉扫描模块(CSM),CSM 不是以单向模式(列向或行向)遍历图像特征图的空间域,而是采用四向扫描策略,即从整个特征图的四个角落扫描到相反的位置。这种策略可确保特征图中的每个元素都能整合来自不同方向上所有其他位置的信息,从而在不增加线性计算复杂度的情况下形成全局感受野。
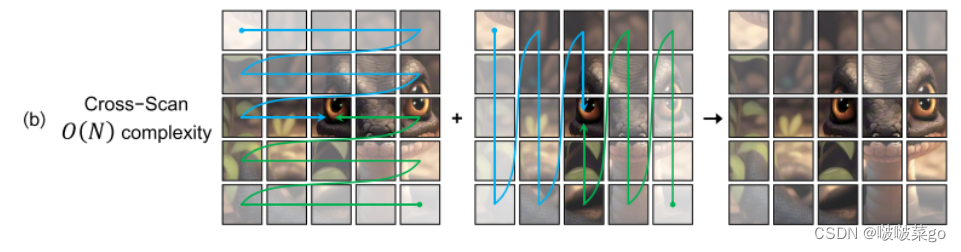
Contribution
- 提出了具有全局感受野和动态权值的视觉状态空间模型VMamba,用于视觉表示学习。VMamba为视觉基础模型提供了一种新的选择,超越了现有的CNN和ViT选择。
- 引入了交叉扫描模块(CSM),弥补了一维阵列扫描和二维平面遍历之间的差距,在不影响感受野的情况下,促进了S6向视觉数据的扩展。
- VMamba在各种视觉任务中,包括图像分类、对象检测和语义分割,都能取得很好的结果,表现了VMamba的潜力。
Method
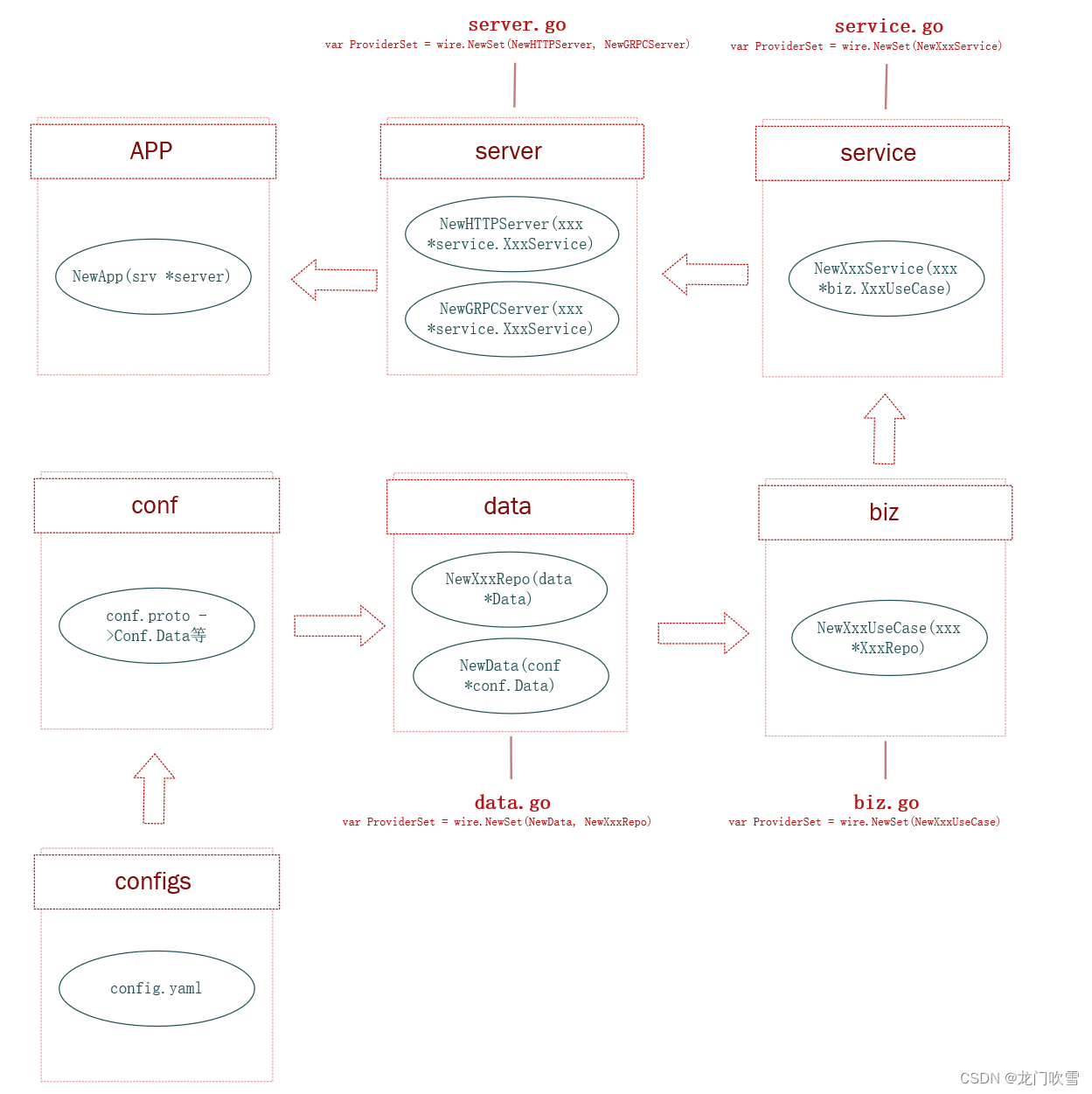
二维选择性扫描
S6在处理输入数据时采用因果关系方式,只能捕捉到它扫描过的数据部分的信息。在自然语言处理等涉及时间数据的任务中,这种特性是合适的,因为信息通常按时间顺序排列,每个数据点(如文本中的词或句子)都有其在序列中的固定位置。
但当S6用于处理非因果性数据,如图像、图表或集合时,就会遇到挑战。因为这些类型的数据包含的信息不仅仅是一维的,而是具有更复杂的结构,比如图像包含的是二维的空间信息。因此,仅仅沿着一个方向扫描数据将无法捕捉到所有相关信息。
为了解决这个问题,文章提出了一种解决方案:通过沿着两个不同的方向(即前向和后向)扫描数据,这样可以互相补偿感受野,而不增加计算复杂度。但直接将S6的处理机制从一维扩展到二维,会导致权重变得静态(即与输入数据无关),从而失去基于上下文的数据建模能力。
为保留动态权重的特性,文章选择坚持使用选择性扫描方法,但这限制了将卷积操作整合进来。作为一种补充方案,文章提出了交叉扫描模块(CSM),该模块通过沿四个不同的方向扩展图像块(从左上到右下,从右下到左上,等等),使得任何一个像素点(如中心像素)能够整合来自不同方向的其他所有像素的信息。这种方法能够使S6在保持线性复杂度的同时,扩大其感受野,使其更适用于视觉模型构建。

然后将所有序列重新合并为单个图像。
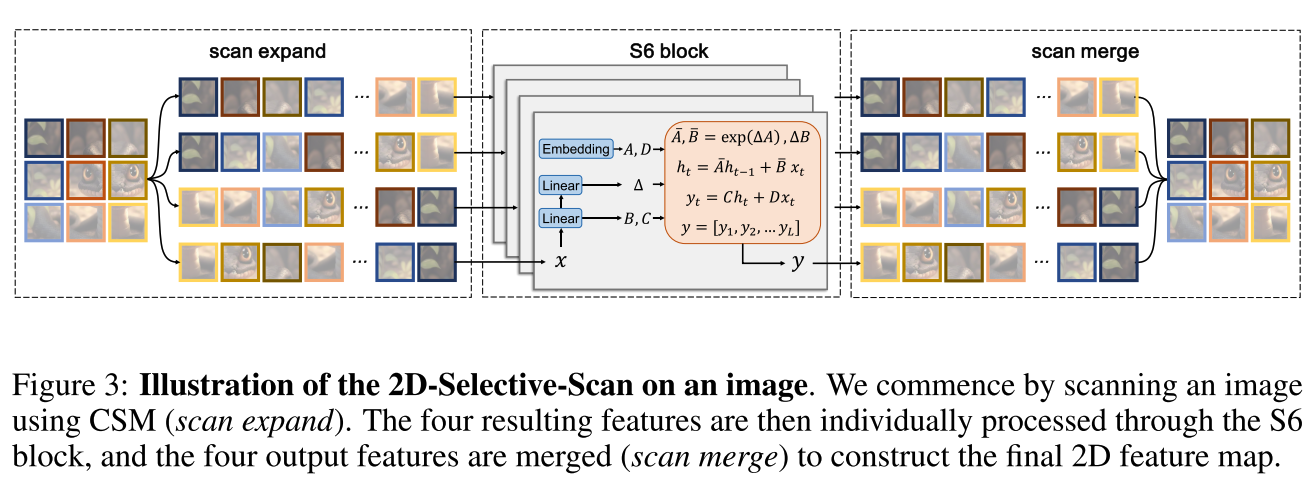
VMamba
整体架构
首先使用stem模块将输入图像分割成若干patch,但没有像ViT一样进一步将patch扁平化为一维序列,从而保留了图像的二维结构。接着堆叠VSS块和下采样。
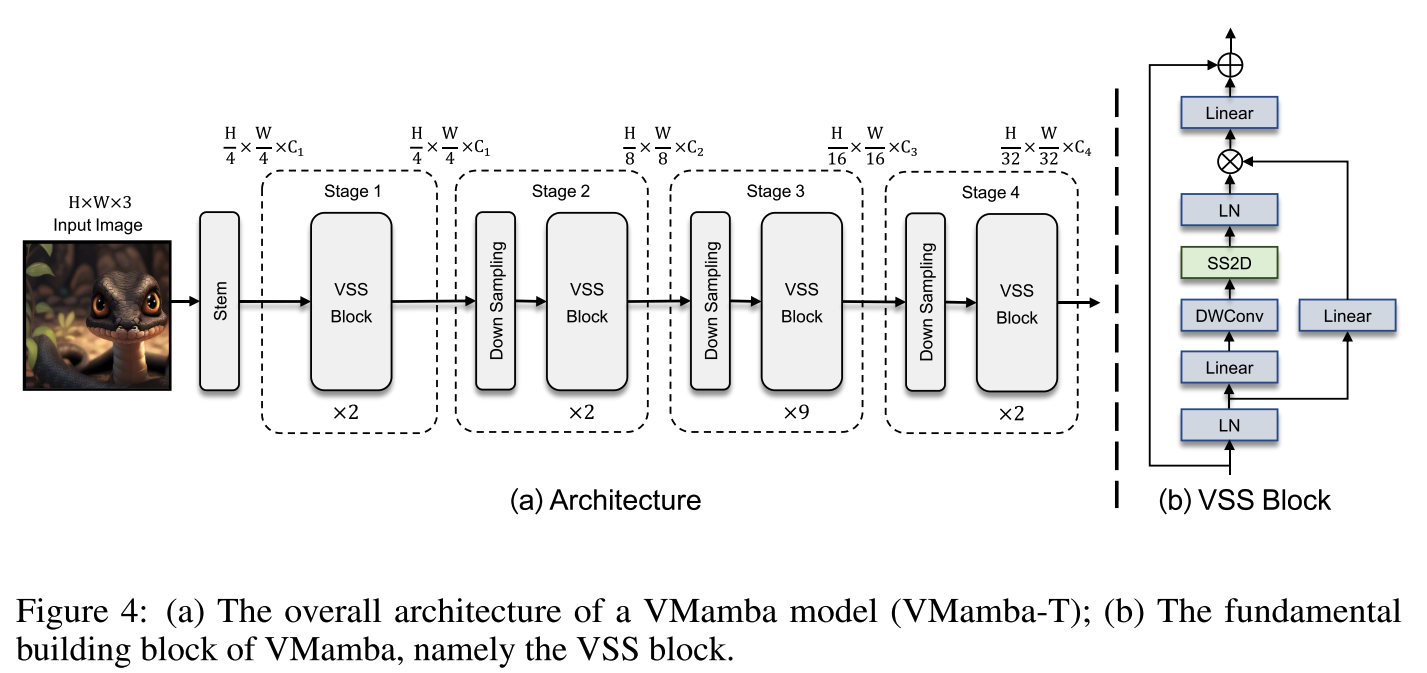
提出了类似这样结构的三种不同规模的VMamba模型即 VMamba-Tiny、VMamba-Small 和 VMambaBase:

VSS模块
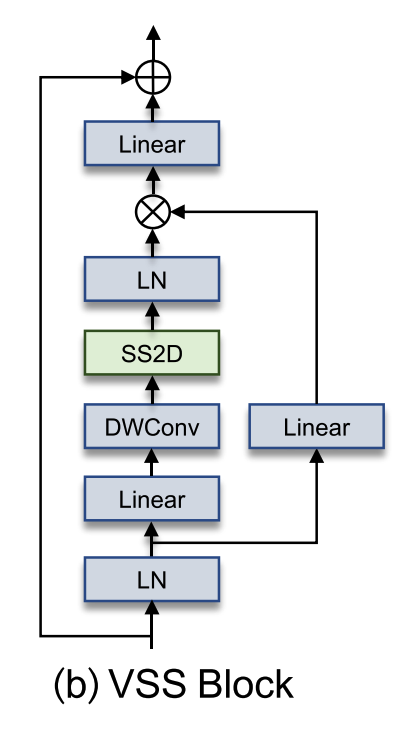
与ViT不同,由于位置嵌入的因果性质,在 VMamba 中没有使用位置嵌入。
VSS 模块比 ViT 模块更浅,这样就可以在总模型深度预算相近的情况下堆叠更多的VSS模块。
Experiment
图像分类
使用ImageNet-1K数据集。
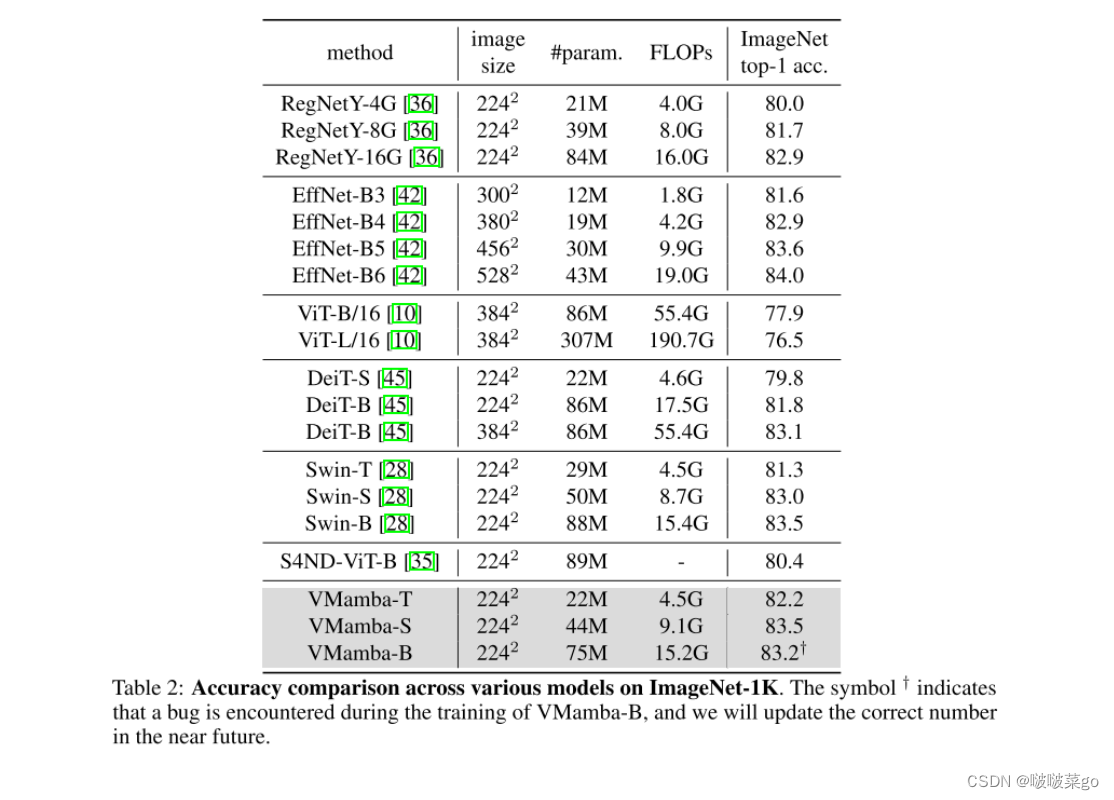
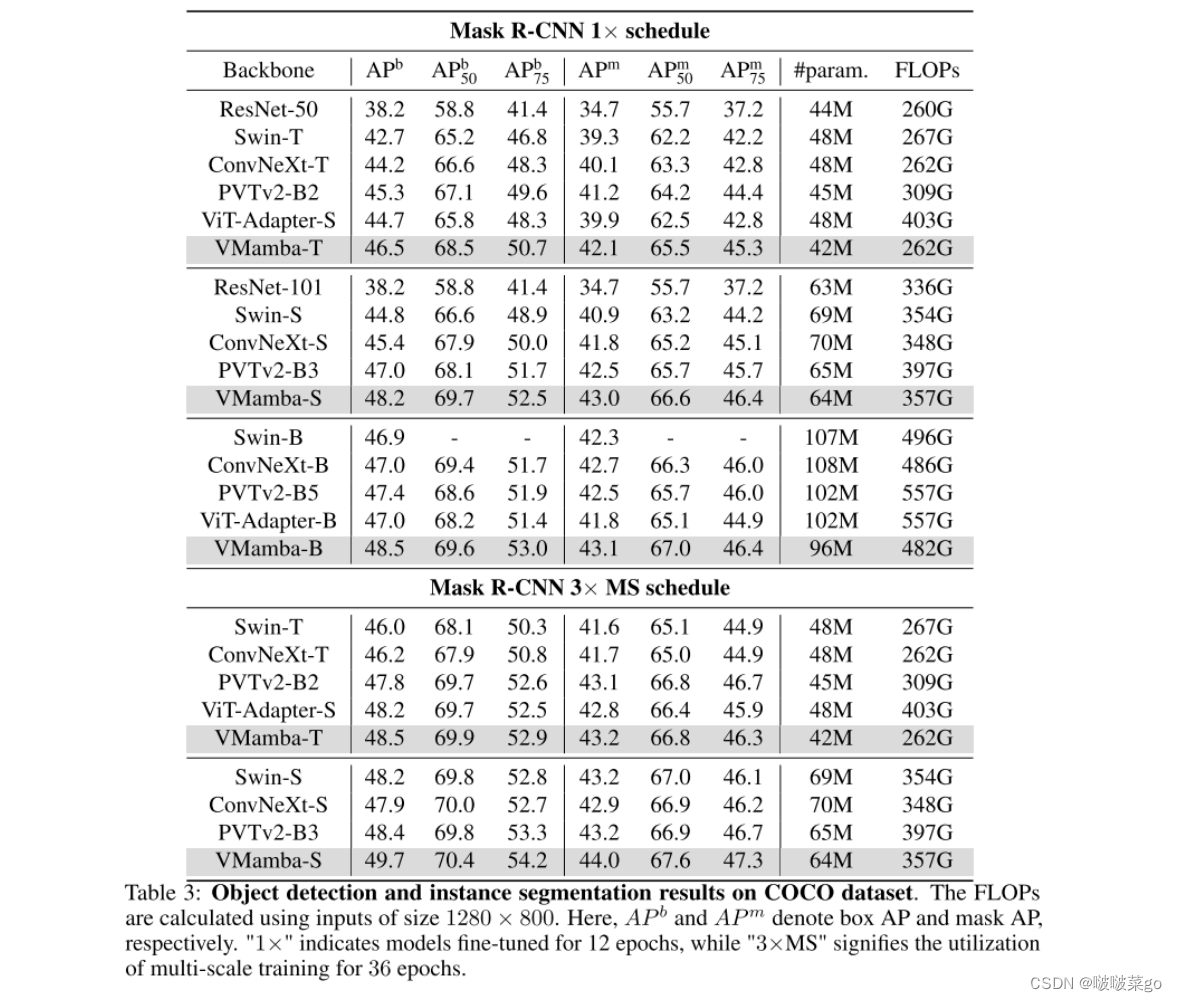
目标检测
使用MSCOCO 2017 数据集。训练框架建立在 mmdetection 库之上,并采用了 Swin中的超参数和 Mask-RCNN 检测器。
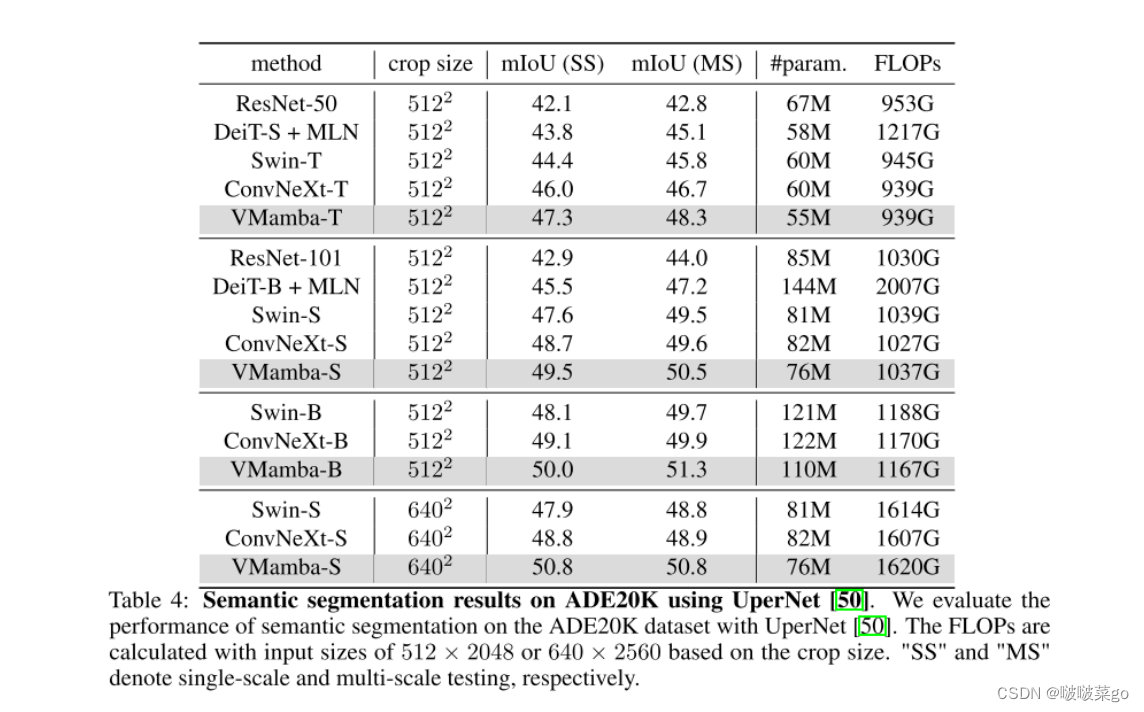
使用ADE20K数据集,按照 Swin 的方法,在预训练模型的基础上构建了一个 UperHead进行分割。
分析实验
有效感受野
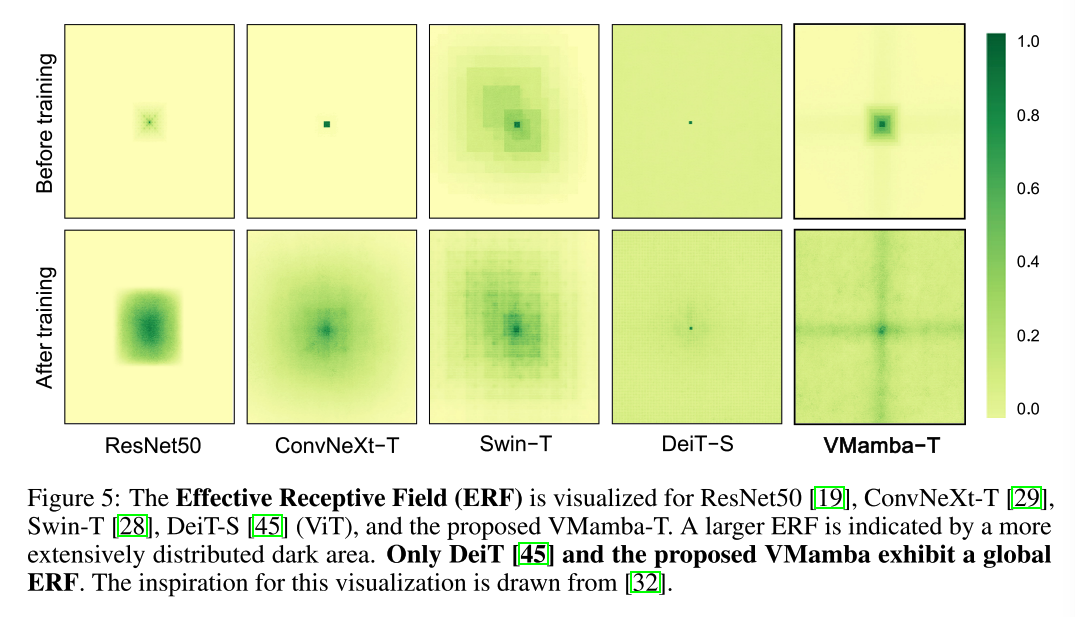
只有 DeiT (ViT) 和 VMamba 表现出全局有效感受野,但DeiT (ViT) 模型的复杂度是二次的。
与DeiT(ViT)的均匀激活不同,VMamba通过其交叉扫描模块的扫描机制,不仅激活所有像素,而且特别强调交叉形状的激活。这表明VMamba模型在处理每个像素时,更倾向于考虑长期依赖的上下文信息,而不仅仅是局部信息。
VMamba在训练前只展示了局部的有效感受野。但在训练后,其有效感受野变为全局性的,这表明VMamba经历了一种适应性过程,使得模型的全局处理能力得到了显著提升。这与DeiT的表现形成对比,后者在训练前后保持了几乎相同的有效感受野。
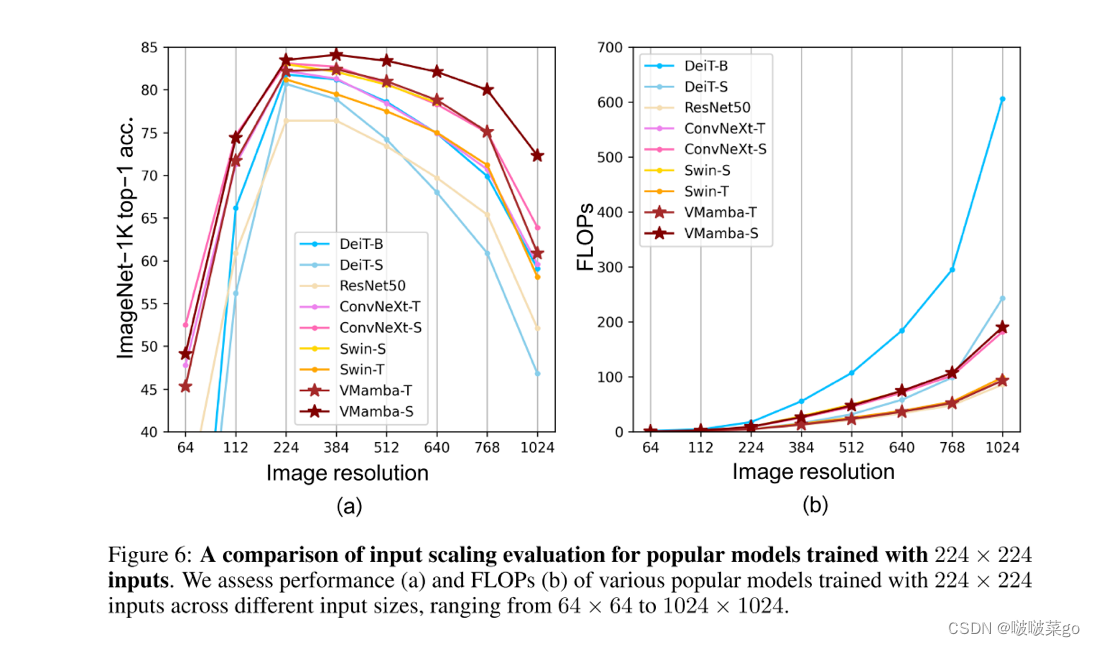
输入缩放
进行输入缩放实验,评估了流行模型(使用 224×224 输入尺寸训练)在不同图像分辨率下的推理性能。VMamba 在不同输入图像尺寸下的性能最为稳定。当输入图像尺寸从 224 × 224 增大到 384 × 384 时,只有 VMamba 的性能呈上升趋势,这凸显了它对输入图像尺寸变化的鲁棒性。
使用不同的图像分辨率(也从 64 × 64 到 1024 × 1024)对 FLOP 进行了评估。VMamba 系列的复杂度呈线性增长,与 CNN 模型一致。VMamba 的复杂度与 Swin 等精心设计的视觉ViT一致。但只有 VMamba 实现了全局有效感受野(ERF)。同样具有全局有效感受野的 DeiT 的复杂度则呈二次方增长。