最近我接手了一个有趣的需求,需要对用户评价进行分词,进行词频统计和情绪分析,并且根据词频权重制成词云图以供后台数据统计,于是我便引入了jieba分词器,但是我发现网上关于jiebaNET相关文档实在太少了,甚至连配置文件都很难搞清楚,所以我来大家介绍一下jiebaNET。
jiebaNET分词器介绍:
ieba.NET分词器是一款基于.NET平台的中文分词工具,它借鉴了jieba分词器的算法和思路,为.NET开发者提供了高效、准确的中文分词功能。jieba.NET分词器的主要功能和特点如下:
- 中文分词:jieba.NET分词器能够将中文文本按照词语进行切分,使得文本更易于被处理和分析。分词是中文文本处理的基础步骤,对于词频统计、文本分类、情感分析等任务具有重要意义。
- 多种分词模式:jieba.NET分词器支持多种分词模式,包括精确模式、全模式和搜索引擎模式。精确模式会将句子最精确地切分开,适合在文本分析时使用;全模式会将句子中所有成词的词语都扫描出来,速度非常快,但可能产生歧义;搜索引擎模式会在精确模式的基础上对长词再进行切分,提高召回率,适用于搜索引擎等场景。
- 自定义词典:jieba.NET分词器允许用户创建自定义词典,以确保特定词汇被正确切分。这对于处理特定行业或领域的文本非常有用,可以提高分词的准确性和效率。
- 高效快速:jieba.NET分词器采用了高效的分词算法和优化的数据结构,可以让分词速度非常快,能够满足大规模文本处理的需求。
- 接口友好:jieba.NET分词器提供了简洁易用的API接口,开发者可以方便地将其集成到自己的.NET项目中,进行中文文本处理和分析。
分词
字典文件存储在Resources中的dict.txt文件中,其中:
- “一个系列”是词条,也就是一个词语或者短语,是词典中存储的实际内容。
- “14”通常是这个词的词频,表示这个词在语料库中出现的次数或者重要程度。较高的词频意味着这个词在语料中较为常见。
- “m”代表词性标注,用来描述这个词的语法角色或词汇类别。在中文词性标注体系中,“m”通常代表“数词”,用于表示数量或序数的词语,比如“一个”、“两个”、“第一次”等
使用方法:
jieba.NET程序集中与分词相关的主要是JiebaSegmenter.Cut函数和JiebaSegmenter. CutForSearch函数,这两个函数都以字符串作为分词输入,不像之前盘古分词支持流式输入。
public IEnumerable<string> Cut(string text, bool cutAll = false, bool hmm = true)
public IEnumerable<string> CutForSearch(string text, bool hmm = true)
基于这两个函数,jieba.NET支持多种分词模式:全模式(把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义)、精确模式(试图将句子最精确地切开)、搜索引擎模式(在精确模式的基础上,对长词再次切分,提高召回率)。这三种方式的代码其实都比较简单,如下所示:
string textstr = txtContent.Text;
txtResult.Text= textstr;
var segmenter = new JiebaSegmenter();
if (RadioButtonListType.SelectedValue == "jz")
{
var segments = segmenter.Cut(textstr,cutAll:false,hmm:false);
txtResult.Text = "【精准模式】:" + string.Join("/ ", segments);
//他/ 来到/ 上海交通大学
}
else if (RadioButtonListType.SelectedValue == "jzhmm")
{
var segments = segmenter.Cut(textstr, cutAll: false, hmm: false);
txtResult.Text = "【精准模式、新词识别】:" + string.Join("/ ", segments);
} //新词识别:"我/ 在/ 玩/ 某某/ 游戏/ 时/ 遇到/ 了/ 一个/ 名叫/ 小明/ 的/ 玩家/ 。"
//"某某"和"小明"可能是游戏中的特定角色或者玩家的ID,不在默认词典中。启用了新词识别功能后,结巴分词器可能会尝试将它们识别为新词,并进行分割
else if (RadioButtonListType.SelectedValue == "cutAll")
{
var segments = segmenter.Cut(textstr, cutAll: true);
txtResult.Text = "【全模式】:" + string.Join("/ ", segments);
//【全模式】:他/ 来到/ 上海/ 上海交通大学/ 交通/ 大学
}
else if (RadioButtonListType.SelectedValue == "CutForSearch")
{
var segments = segmenter.CutForSearch(textstr, true);
txtResult.Text = "【搜索引擎模式】:" + string.Join("/ ", segments);
//他/ 毕业/ 于/ 上海/ 交通/ 大学/ 上海交通大学/ 机电/ 系/ ,/ 后来/ 在/ 一机部/ 上海/ 电器/ 科学/ 研究/ 研究所/ 工作
}关键词提取
jieba.NET支持通过两种算法提取文本关键词:TF-IDF算法和TextRank算法,关于这两种算法的介绍详见参考文献10-11,在jieba.NET中对应的类为TfidfExtractor和TextRankExtractor,这两个分词都都支持调用ExtractTags和ExtractTagsWithWeight函数,前者默认返回前20个关键词,后者还附带每个关键词的权重。
权重逆文档频率存储在Resources/idf.txt文件中:如下图所示:

代码如下:
//不带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TfidfExtractor extractor = new TfidfExtractor();
var keywords=extractor.ExtractTags(tr.ReadToEnd());
txtResult.Text = string.Join("/ ", keywords);
}
//带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TfidfExtractor extractor = new TfidfExtractor();
IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());
foreach (WordWeightPair p in results)
{
txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";
}
}
TextRankExtractor类的示例代码及运行效果如下所示,对比可以看出这两种算法的返回结果还是存在差异:
//不带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TextRankExtractorextractor = new TextRankExtractor();
var keywords=extractor.ExtractTags(tr.ReadToEnd());
txtResult.Text = string.Join("/ ", keywords);
}
//带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TextRankExtractorextractor = new TextRankExtractor();
IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());
foreach (WordWeightPair p in results)
{
txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";
}
}
并行分词
"并行分词" 意味着可以同时处理多个文本或文本集合的分词任务,以提高分词速度和效率。在处理大量文本数据时特别有用,可以利用多核处理器的并行能力,加速分词过程。
JiebaSegmenter类的CutInParallel和CutForSearchInParallel函数支持并行分词
- CutInParallel: 这个函数用于普通的分词任务。它可以同时处理一个字符串集合或单个字符串,并将其分词后返回结果。如果输入是单个字符串,Jieba.NET 会自动将其按行转换为字符串集合,然后并行进行分词处理。
- CutForSearchInParallel: 这个函数用于搜索引擎模式的分词任务。类似于 CutInParallel,它也支持并行处理,但会采用搜索引擎模式进行分词,以适应搜索引擎等应用场景的需求。
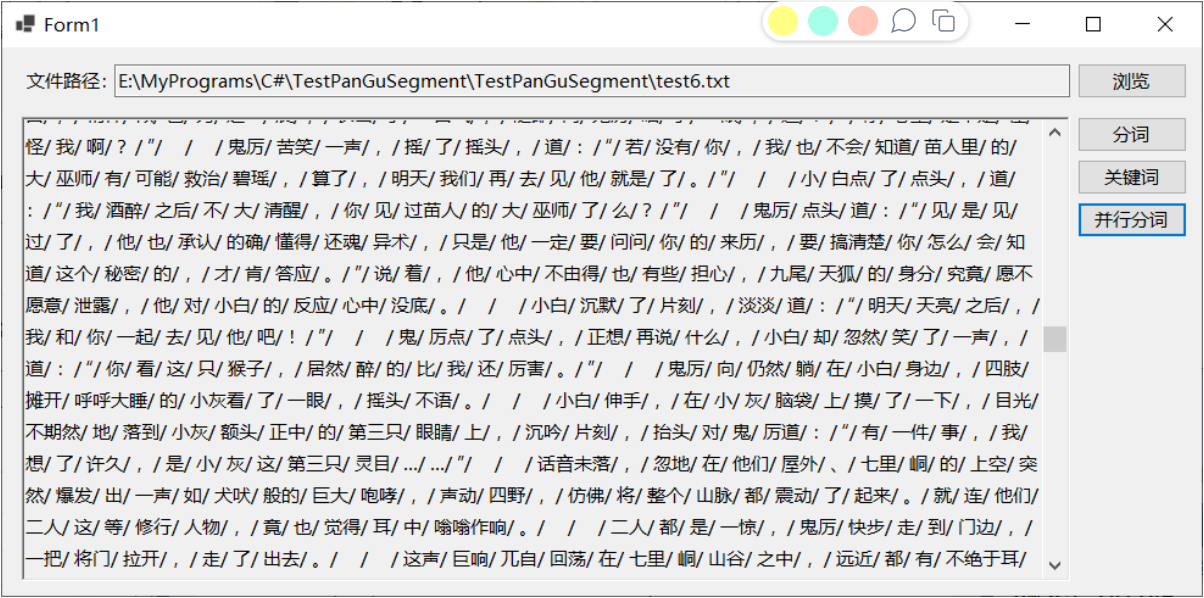
设置停用词
提取关键词时,部分词语可能不重要或者并非所需的词语,此时可以通过设置停用词,在提取关键词时过滤掉指定的停用词。jieba.NET的停用词词库放在Resources文件夹下的stopwords.txt,程序启动时会自动加载该文件。 以之前的测试文本为例,提取前20个关键词,将其中的“一声”、“一脉”两次设置停用词,即在stopwords.txt后追加这两词,再次运行程序提取关键词,可以看到这两个词已经消息
词性标注
jieba.NET中的PosSegmenter类支持在分词的同时,为每个词添加词性标注,词性标注的含义表如下所示:

- segmenter.Tokenize(text) 返回的是一个 IEnumerable<WordToken>,其中每个 WordToken 对象包含了词语、词性以及词语在原始文本中的起始位置。
1.在Resource的char_state_tab.json文件下存储了针对Unicode字符到其可能的词性的映射关系
2.在pos_prob_emit.json文件下存储了不同“词性”在遇到特定汉字时可能出现的概率大小,内容如图所示:

(这个指南不是直接给概率值,而是给了“负对数似然度”,你可以把它想象成衡量“不寻常程度”的一个指标——数值越小,表示这种情况越常见、越合理。)比如"E-e"下面"\u5440"的值是-0.65302718677052,意思是当某个词性是"E-e"时,汉字“\u5440”出现的概率相对较大,因为这个数字相比其他很多值是比较接近0的,也就是比较“不罕见”。
3.pos_prob_start.json /prob_emit.json 文件是用于存储词性标注模型中不同词性状态的先验概率或转移概率的数据。在自然语言处理任务,尤其是词性标注(Part-of-Speech Tagging)中,这样的文件起着至关重要的作用。(百度解释,不是太明白)
这个文件中的内容是每个词性对应的状态转移概率,以及每个状态的概率。每个词性都有一个对应的标识,比如 "E-e"、"E-d"、"S-rg" 等,这些标识可能是分别表示着不同的词性。而每个标识后面的数值则表示了该词性转移到下一个词性的概率,或者是该词性在句子中出现的概率。
4.pos_prob_trans/prob_trans.json 记录了不同词性之间的转移概率。其中,每个词性(比如 "E-e")后面跟着一个对象,对象的键是可能的下一个词性,而对应的值则是从当前词性转移到下一个词性的概率。例如,对于词性 "E-e",它可以转移到的词性有 "S-nr"、"S-ng"、"B-rz"、"B-mq" 等等,对应着不同的转移概率。这些值是负对数形式,数值越小代表从当前词性转移到目标词性的概率越高。
获取分词词语的起始位置
jieba.NET中的JiebaSegmenter类的Tokenize函数除了返回分词词语之外,还会返回每个分词词语的起止位置。该函数支持默认模式和搜索模式两种分词方式,根据官网说明及测试,默认模式类似于分词函数的精确模式分词,每个词语只会被分一次,而搜索模式类似于全模式及搜索引擎模式分词,把所有可能的分词形式都返回。代码使用如下所示
using JiebaNet.Segmenter;
using System;
class Program
{
static void Main(string[] args)
{
var segmenter = new JiebaSegmenter();
// 默认模式下的分词及位置信息
var tokensDefaultMode = segmenter.Tokenize("我爱自然语言处理");
foreach (var token in tokensDefaultMode)
{
Console.WriteLine($"Word: {token.Word}, Start Index: {token.StartIndex}, End Index: {token.EndIndex}");
}
// 搜索模式下的分词及位置信息
var tokensSearchMode = segmenter.Tokenize("我爱自然语言处理", TokenizerMode.Search);
foreach (var token in tokensSearchMode)
{
Console.WriteLine($"Word: {token.Word}, Start Index: {token.StartIndex}, End Index: {token.EndIndex}");
}
}
}
查找关键词
jieba.NET中的KeywordProcessor类预先指定的一组关键词,然后在指定的文本中查找存在哪些关键词,也即查找指定的关键词在文本中是否存在。
添加自定义词典
自定义词典,以便包含jeba词库里面没有的词,格式如下:
创新办 3 i
云计算 5
凱特琳 nz
载入词典
使用jieba,load_userdict(file_name)即可载入词典
动态调整词典
结巴分词器(Jieba)提供了 add_word(word, freq=None, tag=None) 和 del_word(word) 这两个方法,允许在程序运行过程中动态修改词典,以满足特定的需求。
- add_word(word, freq=None, tag=None): 这个方法用于向分词器的词典中添加新的词语。可以指定词语的频率(freq)和词性(tag),如果不指定频率和词性,则默认使用内部规则进行设置。这样一来,当分词器进行分词时,就可以识别和使用这些新增的词语了。
- del_word(word): 这个方法用于从分词器的词典中删除指定的词语。这在某些情况下可能很有用,比如当某些词语被错误地添加到词典中,或者需要动态地调整词典以适应不同的场景。
词频统计
词频统计功能可以计算文本中每个词语出现的频率以及统计词语的数量,这对文本分析、关键词提取、文本摘要等任务都非常有用。
Jieba 中的 cut 函数用于对文本进行分词,而分词后的结果可以通过 Counter 类进行词频统计。Counter 类可以统计一个可迭代对象中各个元素出现的次数。
using JiebaNet.Segmenter;
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// 创建 JiebaSegmenter 实例
var segmenter = new JiebaSegmenter();
// 文本
string text = "我爱自然语言处理,自然语言处理也很有趣。";
// 分词
var segments = segmenter.Cut(text);
// 统计词频
var wordCounts = segments.GroupBy(x => x)
.ToDictionary(g => g.Key, g => g.Count());
// 输出词频统计结果
foreach (var pair in wordCounts)
{
Console.WriteLine($"词语: {pair.Key},频率: {pair.Value}");
}
}
}
那么如何按照词频绘制词云图呢?我们下章就为大家讲解!






![Lora训练Windows[笔记]](https://img-blog.csdnimg.cn/direct/36027f1c45324ac1964b3318575b121a.png)