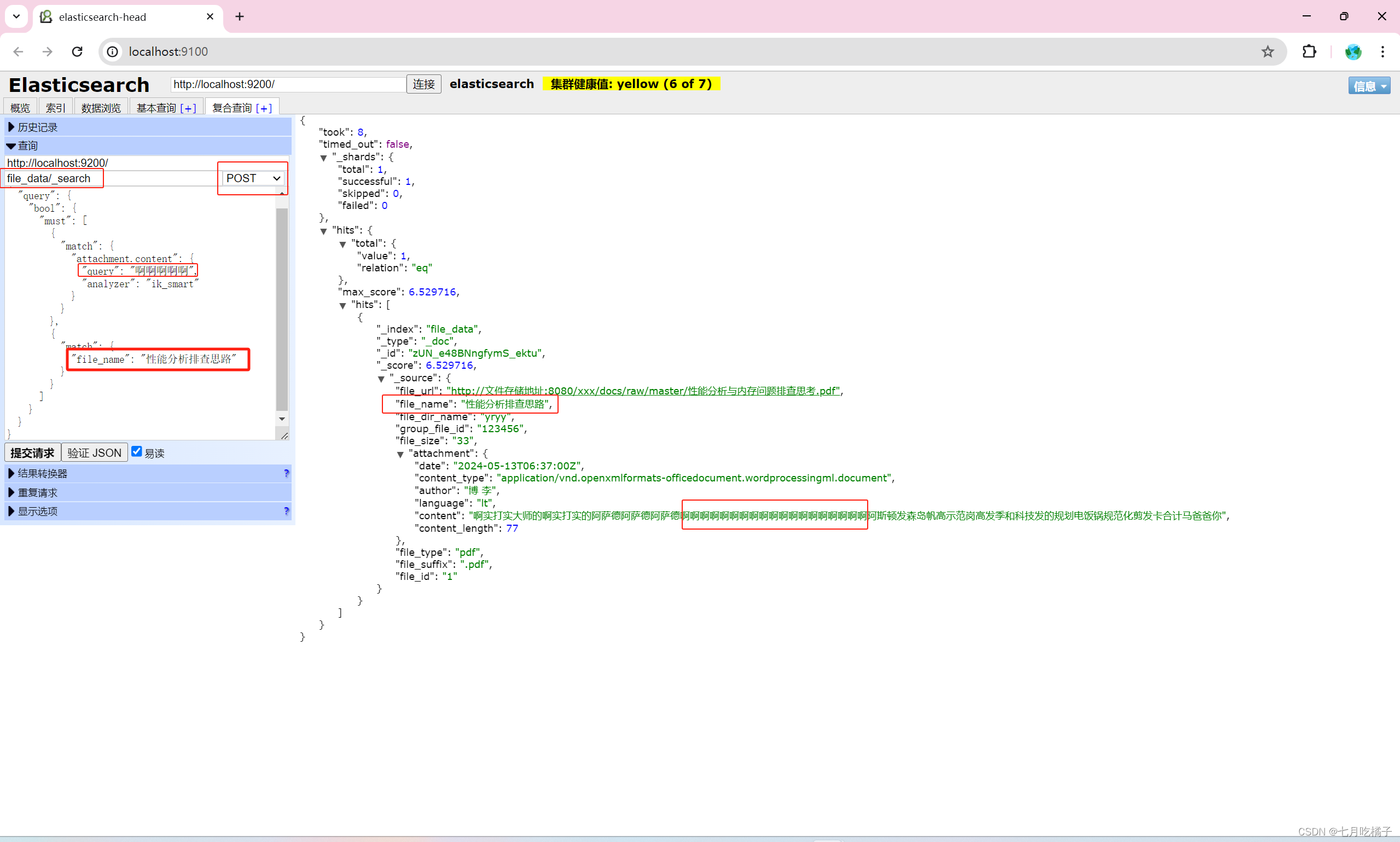
摘要
利用机器学习根据给定的文本描述生成图像的技术已经取得了显著的进步,例如CLIP图像-文本编码器模型的发布;然而,当前的方法缺乏对生成图像风格的艺术控制。我们提出了一种方法,用于为给定的文本描述生成指定风格的绘图,用户可以通过一个样本图像来指定所需的绘图风格。受到艺术理论的启发,该理论认为在创作过程中风格和内容通常是不可分割的,我们提出了一个耦合的方法,称为StyleCLIPDraw,通过在整个过程中同时优化风格和内容来生成绘图,而不是在创建内容后应用风格转移。根据人类评估,StyleCLIPDraw生成的图像风格比顺序方法生成的图像风格更受偏好。尽管对于某些风格的内容生成质量有所下降,但总体而言,考虑到内容和风格,StyleCLIPDraw更受偏好,这表明机器生成图像的风格、外观和感觉对人们的重要性,以及风格在绘图过程中是耦合的。
1 引言

图1:我们的方法(StyleCLIPDraw)与基线方法(CLIPDraw + 风格迁移)的比较。顶部行显示了语言输入,紧接着是风格图像输入。

图2:第一行显示了用于生成以下图像的风格图像。第二行使用文本提示“阿尔伯特·爱因斯坦跳舞”,最后一行使用“一只戴着高顶礼帽的羊”。
创建视觉内容是一项具有挑战性的任务,需要技能、时间和资源。绘画课程可能很昂贵,对于许多人来说,参与这些课程的时间成本是难以承受的。虽然视觉内容创作技能可能是一种特权,但大多数人可以使用一些共同的技能来分享他们的想法,例如口头交流。例如,人们可能会发现很难画出一个复杂的场景,但他们很可能能够用语言描述它。在这种背景下,我们的研究探讨了人工智能(AI)如何作为一种工具来克服这一障碍,并赋予人们享受他们原本无法实现的创造性实践的乐趣。在本文中,我们特别关注从文本描述生成绘图。
语言是一种常见的交流方式,可以在某种程度上抽象地描述视觉信息。最近的技术进步,如OpenAI的对比语言-图像预训练(CLIP)Radford等人(2021),已经实现了高质量的语言-视觉翻译方法,如Dall-E Ramesh等人(2021)、GLIDE Nichol等人(2021)和CLIPDraw Frans等人(2021)。使用这些技术,人们可以编写简短的语言描述来创建与AI系统合作的图像;然而,如图1第二行所示的CLIPDraw生成的绘图,都具有相似的视觉风格。语言描述可以用来改变绘图的风格,但只能在一定程度上,如图3所示,因为用语言描述绘图风格并不容易。
我们的方法基于这样一个假设:为视觉内容创建系统增加更多的控制权是让用户感觉他们拥有艺术所有权和控制输出的一种方式。据报道,为了感到独立并拥有所有权,人类更喜欢拥有控制权而不是被一个完全自主的系统服务Selvaggio等人(2021);Bretan等人(2016)。如果机器在没有人类输入的情况下为人类用户执行任务,用户可能会对产品感到满意,但感觉他们在过程中参与得不够,无法感到他们拥有输出的艺术方面,就像专业动画师的情况Bateman(2021)。此外,保留输入在任务中可以是一种方式,当人们在身体或精神上受到限制时,可以维护他们的人性和自主权Kim等人(2011)。在这种背景下,我们提出了一种方法,用户可以通过示例图像指定风格,以及文本描述。
机器风格转移的任务长期以来一直被研究Gatys等人(2016);Kolkin等人(2019),其中一种风格被应用到给定的内容图像上。这导致了一种直观的解耦方法,通过连续使用现有的技术,例如,CLIPDraw根据文本生成绘图,然后使用给定的风格图像对绘图应用风格转移算法。虽然这种方法确实结合了风格和内容,但这种结合是解耦的。
在艺术中,风格(通常被称为“形式”)和内容通常是相互关联的。风格和内容可以独立于彼此应用,但通常一个会影响另一个。Robertson(1967)解释说,用不同风格表示的相同内容会创造出具有不同信息或意义的独特艺术作品,而且每种不同风格的艺术作品之间,内容、意义和信息的抽象相似性很小;因此,艺术作品的内容、意义和信息取决于该作品的风格选择。根据这一理论,我们的方法StyleCLIPDraw使用语言和风格作为输入生成绘图,并且事先知道在绘图过程中风格和内容是耦合的。

图3:通过改变文本描述来控制CLIPDraw生成的绘画风格。
本文包括以下贡献:
1)我们提出了一种结合文本和风格的图像生成方法;
2)我们公开发布了完整的用户评估结果和352幅AI生成的绘画作为首个此类评估图像风格的全面数据集;
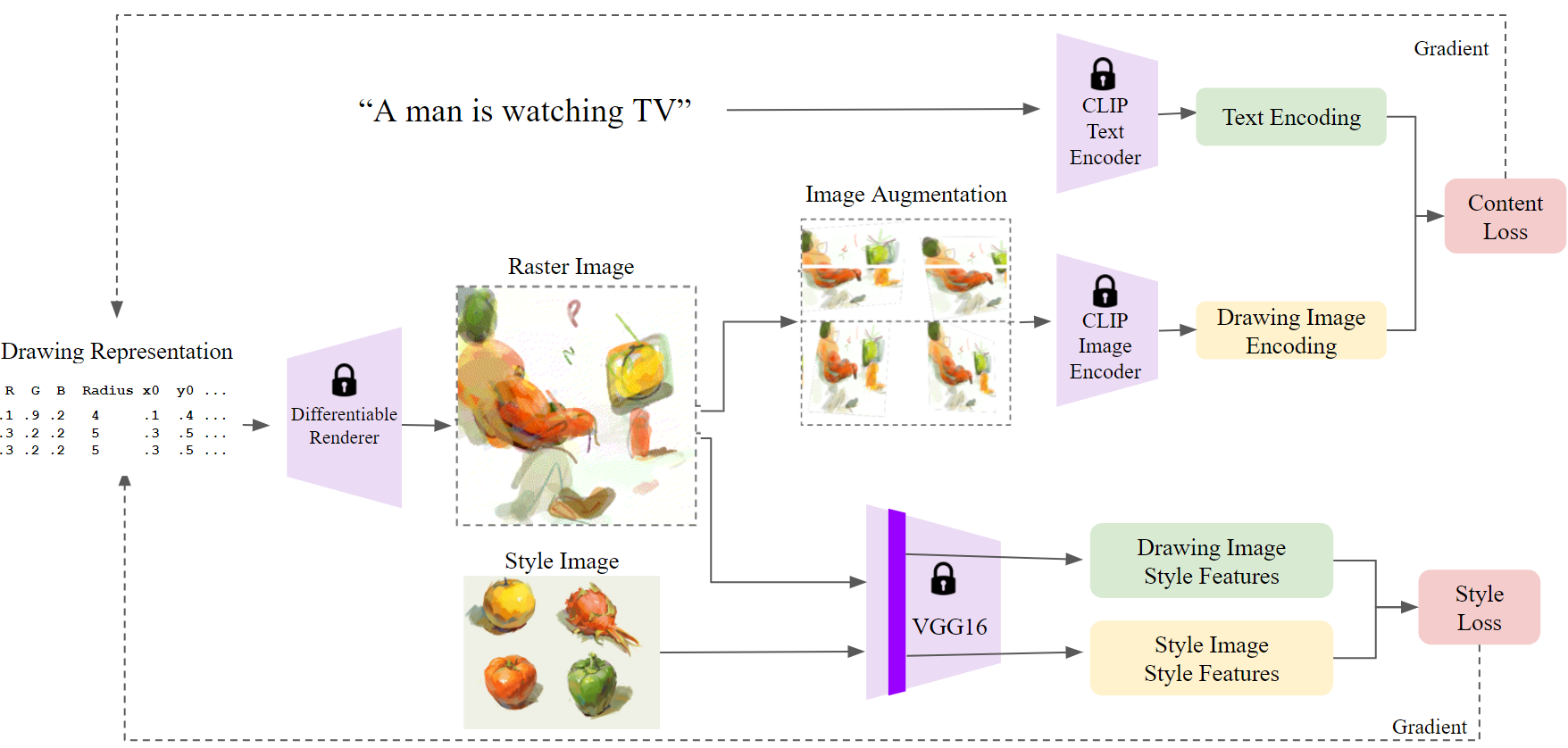
图4:StyleCLIPDraw通过计算两个损失来优化绘图表示:一个使用文本描述进行内容计算,另一个使用风格图像进行风格计算。绘图表示被光栅化,然后使用CLIP和VGG16模型分别提取风格和内容特征。使用距离函数比较风格和内容特征以计算损失。
2. 相关工作
2.1 文本到图像合成模型
最近最通用和成功的文本到图像合成方法要么涉及以监督方式训练一个模型来执行该任务,要么使用CLIP Radford等人(2021)指导生成的预训练图像生成模型。前者的例子包括Dall-E Ramesh等人(2021)和GLIDE Nichol等人(2021),它们使用大约4亿个图像-文本对进行训练。在如此庞大的数据集上训练这些模型需要大量的资源。Dall-E和GLIDE都没有完全公开发布。
2.2 CLIP引导的文本到图像合成
一种更计算高效的文本到图像合成方法是逐个创建文本到图像的转换,并利用预训练模型。可以使用任何预训练的图像生成模型作为图像生成器。用作生成器模型输入的潜在向量被随机初始化,并作为要优化的参数空间。CLIP对潜在空间生成的图像以及用户给出的文本描述进行编码。通过最小化生成图像的编码和文本编码之间的余弦距离来优化潜在空间。该方法在科技艺术界非常流行,并已被多次使用不同的预训练模型进行实现Galatolo等人(2021);Smith和Colton(2021)。
2.3 文本到绘图合成
前面提到的方法直接生成光栅图像。在这项工作中,我们关注的是可以表示为可以渲染成光栅图像的笔触的绘图。先前关于绘图的工作通常关注将图像分解为笔触,称为基于笔触的渲染(SBR)。SBR的最新方法使用深度强化学习或转换器模型以概率方式生成笔触Liu等人(2021);Schaldenbrand和Oh(2020);Huang等人(2019)。
CLIPDraw是一种结合了SBR的动作空间和CLIP引导的图像生成方法论的方法。它不是优化一个模型来执行所有可以想象的文本到绘图合成任务,而是单独优化每个转换。因此,不是修改神经网络模型的参数,而是修改笔触本身来优化目标。
2.4 绘图和风格评估
在相关工作中,如改变图像的风格(如风格转换Gatys等人(2016);Kolkin等人(2019)),风格没有被正确定义,或者只被定义为与图像的颜色和纹理有关,而忽略了形状和空间等重要概念。艺术家通常使用艺术特征,如颜色、线条、纹理和形状Thorson(2020)来描述艺术品。在计算机视觉领域,研究表明,使用这些特征来描述图像可以积极影响图像检索Alsmadi(2020)和图像分类Banerji等人(2013)。这些特征可以用作图像风格的强代表,因此有些被用作艺术品的评价方法Kim等人(2022);Kim(2010)。在这项工作中,我们将绘图的风格定义为Thorson(2020)和Beck(2014)中7种艺术元素的组合,如表1所示。注意,形式与绘图不相关,因为绘图是二维图像。
3.方法
我们的方法如图4所示。在每次迭代中,通过计算两个损失来同时优化内容和风格。我们基于CLIPDraw Frans等人(2021)的绘图表示和内容损失方法论进行构建,为自包含性,我们包括简要描述。
3.1 绘图表示
绘图使用一系列虚拟笔触表示,每个笔触都有轨迹、颜色和宽度的参数,如Frans等人(2021)中定义的那样。轨迹由二维坐标平面上的四个控制点的三次贝塞尔曲线描述。笔触的颜色由四个实数表示,定义颜色中的红、绿、蓝量以及控制笔触不透明度的alpha通道。笔触的宽度由笔触的半径表示,单位为像素。
绘图表示不能被CLIP或VGG16等直接使用,因为它们需要光栅图像作为输入。为了光栅化绘图表示,我们使用Li等人(2020)的DiffVG软件包,它以可微分的方式呈现矢量图形。
3.2 绘图增强
在优化过程中,预训练模型中的微小缺陷可能会被利用,导致局部最小值具有高分但结果较差,有时被称为对抗样本Rebuffi等人(2021)。为了稳定优化,光栅化绘图在输入CLIP之前会进行随机裁剪和透视增强,如Frans等人(2021);Tian和Ha(2021)中所述。
3.3 内容损失
内容损失的计算遵循Frans等人(2021)的方法论。输入文本描述是图像内容的主要控制。CLIP用于将文本描述与绘图表示联系起来。绘图表示(x)被光栅化、增强,然后使用CLIP的图像编码器(方程1)进行编码。给定的文本描述由CLIP的文本编码器编码。使用余弦相似性(方程2中的S_C)比较这两个编码,并取平均值以形成模型的损失函数,该函数指导绘图类似于文本描述。我们将余弦相似性乘以-1,因为我们的优化算法旨在减小损失。

3.4风格损失
生成画作的风格通过给定的示例风格图像来指定。示例图像和生成画作的风格由纹理、空间使用、物体形状、线条、颜色以及图像中颜色的明暗值组成。为了从光栅图像中提取这种风格信息,通常使用预训练的神经网络,如Gatys等人(2016);Kolkin等人(2019)。我们根据Kolkin等人(2019)的STROTSS方法提取风格特征。这些特征基于VGG16物体检测模型的早期层从画作和风格图像中提取。模型的早期层倾向于提取低级图像特征,如纹理和颜色,Chandrarathne等人(2020)指出,这些特征与人类会认同的风格信息高度相关。我们使用地球移动距离(Earth Mover’s Distance)比较这些特征,计算风格的损失项,这个损失项可以通过反向传播进行优化。
3.5优化算法
画作表示通过随机初始化开始优化算法,以可控数量的笔触开始。如图4所示,画作被光栅化并用于计算内容和风格的损失。优化算法的目标是找到画作表示(公式3中的𝑥̂),使得内容(ℒ𝑐𝑜𝑛𝑡𝑒𝑛𝑡)和风格(ℒ𝑠𝑡𝑦𝑙𝑒)的加权损失和最小化。权重𝜆1和𝜆2控制文本或风格图像对画作外观的影响程度。我们在第5.1节报告了这两个权重的影响。
𝑥̂=min𝑥𝜆1ℒ𝑐𝑜𝑛𝑡𝑒𝑛𝑡+𝜆2ℒ𝑠𝑡𝑦𝑙𝑒
在优化算法的每次迭代中,计算损失,通过反向传播计算导数,并改变画作表示以减少损失。画作表示的修改通过RMSProp算法进行。由于数据的量级不同,需要使用不同的学习率(例如,分别为0.3、0.3和0.03),因此为笔触轨迹、笔触宽度和笔触颜色分别使用一个RMSProp实例。
两个损失项在一次反向传播步骤中结合并优化,因为它们在公式3中相加。另外,也可以分别优化每个损失项,交替进行内容优化和风格优化,我们称之为“联合优化”和“交替优化”,并在第5.2节讨论它们的效率。
4实验
4.1解耦基线
基于文本的画作合成可以通过将现有技术串联起来进行。这在本工作中形成了基线:首先使用CLIPDraw将语言输入转换为画作,然后使用STROTSS风格迁移算法作为后处理将画作风格化。
4.2人类评估调查
主要实验:我们手工制作了22个文本提示,并选择了8种不同的风格图像来生成176幅StyleCLIPDraw和基线方法的画作。对于每一对风格图像和提示,我们生成了4幅画作,并选择了与文本描述的CLIP编码之间余弦相似度最高的那一幅。我们使用Amazon Mechanical Turk(AMT)平台进行研究。参与者首先被教育关于艺术的不同维度及其含义(表1)。然后向参与者展示用于生成画作的风格图像,以及来自StyleCLIPDraw和基线的两幅画作,顺序随机。对每对画作提出了9个问题。前6个问题是关于表1中的每个风格元素,即“哪幅画与风格图像在[风格元素]方面最相似?”参与者还被要求选择哪幅画总体上最适合风格图像。接下来,给出了用于生成画作的文本提示,参与者被要求选择哪幅画最适合描述,如果两者都不适合,或者两者都同样适合。最后,参与者被问及哪幅画(如果有的话)最适合文本和风格。
辅助问题:为了比较研究中使用的风格图像的现实性,我们要求AMT工人对我们在研究中使用的8幅风格图像在5个类别中进行评分:非常简单、简单、中性、详细和非常详细。
| 艺术元素 | 描述 |
|---|---|
| 线条 | 能够通过其外形产生纹理的轮廓。 |
| 形状 | 绘画中对象的一般几何形状和构成。 |
| 空间 | 形状和对象之间的透视和比例。 |
| 质地 | 物体看起来的触感,即如果触摸可能会感觉到的样子。 |
| 价值 | 色调或颜色的明暗。 |
| 颜色 | 绘画中颜色的色调、明暗、深浅和强度。 |
| 形式 | 作品的三维属性(在评估2D图像时不使用,因为它与2D图像关联较小)。 |
表1:构成艺术品风格的七种艺术元素
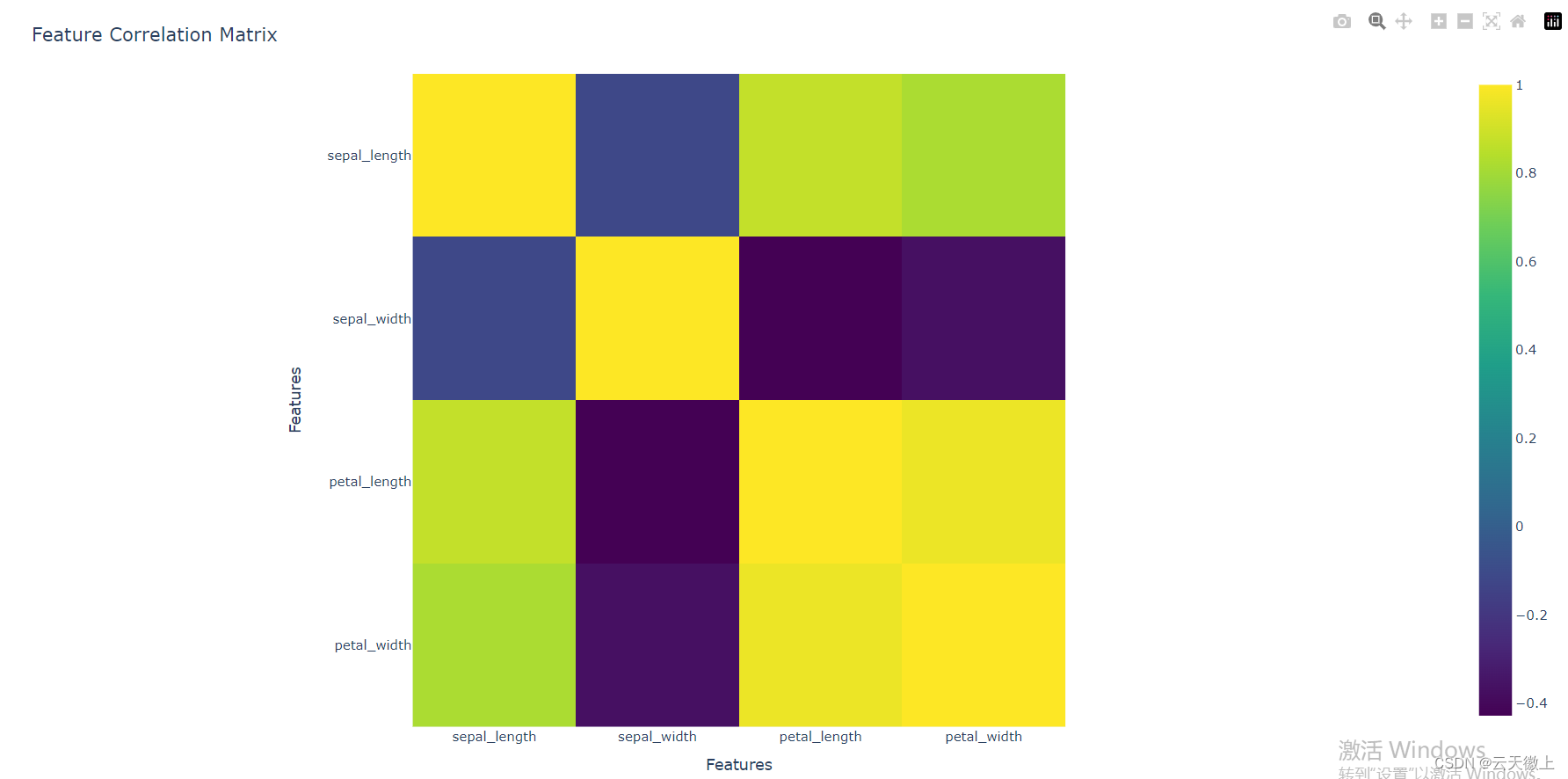
5.结果
我们报告了对我们方法的分析结果,然后呈现了评估结果。
5.1 风格和内容权重
我们定性地报告了所提出优化方法(方程3)中的风格和内容权重的选择如何影响输出绘图的质量。我们使用相同的文本提示和风格图像生成绘图,并改变了风格和内容权重。在图5中,从左到右,随着风格损失权重的减小和内容损失权重(方程3中的λ2和λ1)的增加而生成了绘图。当仅使用风格权重时,绘图能够很好地捕捉风格,但与文本描述缺乏相似性,而当仅使用内容权重时,绘图能够很好地表示文本,但缺乏来自风格图像的风格。基于这些定性结果,我们选择了λ1和λ2都为1.0,以平衡内容和风格的强度。

图5:从左到右:增加内容损失的权重并减少风格损失的权重(分别为等式3中的λ1和λ2)。这些绘图是使用最左边的风格图像和文本提示“一个人正在城市街道上行走”生成的。
5.2 协同优化与交替优化
基于一项与第4.2节中描述的主要调查设计相似的AMT研究,涉及51名用户,协同优化和交替优化方法在内容和风格生成方面是可比的,尽管在风格生成方面交替优化显示出轻微的优势;然而,就计算效率而言,协同优化方法是极其优越的。具体来说,交替优化的运行时间比协同优化长十倍,而在风格方面只有两倍更受欢迎。协同优化方法在我们的Google Colab笔记本上使用P100 NVIDIA GPU大约需要1分钟,这是开发实时系统的一个有希望的消息。
| 维度(比较) | 我们的 | 基准 | 任何一个 | 两者 |
|---|---|---|---|---|
| 线条 | 75.4 | 24.6 | ||
| 形状 | 76.6 | 23.4 | ||
| 空间 | 82.1 | 17.9 | ||
| 质地 | 77.6 | 22.4 | ||
| 价值 | 77.4 | 22.6 | ||
| 颜色 | 80.8 | 19.2 | ||
| 整体风格 | 84.9 | 15.1 | ||
| 内容 | 24.3 | 52.1 | 9.1 | 14.4 |
| 风格与内容 | 48.1 | 23.3 | 19.8 | 8.9 |
表2:在我们的StyleCLIPDraw方法与基线方法直接比较中,对绘画的偏好百分比。更多细节见第4.2节。
5.3 定性结果
在图1中,我们将StyleCLIPDraw的性能与原始的CLIPDraw(Frans等人,2021年)和解耦基线方法:CLIPDraw + 风格迁移(第4.1节)进行了比较。我们使用了四个提示和风格图像对来生成绘画。在内容生成方面,所有三种方法似乎都能很好地适应给定文本描述的内容。在风格生成方面,我们的耦合方法能够根据给定的风格输入忠实地生成输出图像。相比之下,将风格迁移作为后处理应用于CLIPDraw绘画的解耦基线方法改变了图像的颜色和纹理,但缺乏对其他艺术元素(如形状、空间和线条)的适应。
图2展示了StyleCLIPDraw对不同提示和风格图像的响应示例。
我们注意到,由于缺乏抽象风格,CLIPDraw绘画似乎更清晰、更直接地捕捉文本内容。某些风格的绘画比其他风格更具约束性。例如,与高度抽象的线条画示例相比,更具画家风格的图像似乎为该方法提供了更多的灵活性。由于StyleCLIPDraw比基线更强烈地应用了风格,因此风格可能比基线更损害了图像内容的外观。在我们的调查中使用辅助问题,我们发现风格图像的现实主义与图像内容的外观之间存在强烈的正相关(相关系数为0.72,p值为0.04),即风格图像的现实主义越模糊,生成输出的内容就越不受欢迎。
5.4 定量结果
基于139名参与者的人类评估研究结果总结在表2中。正如我们在定性分析中所推测的,解耦方法生成的内容更清晰,更容易被人类用户识别。在风格方面,根据表1中的所有风格维度,我们的StyleCLIPDraw方法比解耦方法更受欢迎。这一结果为我们的假设提供了强有力的证据,即风格和内容的生成是一个耦合过程,这两个目标在整个创作过程中应该共同优化。
总的来说,当询问风格和内容时,参与者远远更喜欢我们的方法而不是基线,这强调了风格、外观和感觉对生成图像的重要性。这一结果也为我们的假设提供了有希望的信号,即对输出的额外控制可能会潜在地提高用户的艺术所有权。
5.5 局限性
我们的方法依赖于现有的图像-文本模型,如CLIP,这些模型通常是在大量非公开数据上训练的。根据我们的实验,现有模型能够处理的文本描述的复杂性相对简单,如论文中使用的示例所示。
正如结果中所讨论的,使用抽象风格图像似乎会阻碍内容质量。使用抽象风格创建可识别的内容通常需要更多的创造力。作为未来的研究方向,我们考虑包括额外的损失项,以优化可识别性或整体感。
我们目前的方法仍然不够快,无法用于实时应用,如通信辅助。
6 结论
本文探讨了一个问题:AI如何被用来赋予非专业人员参与创造性视觉内容生成的能力。基于这样的假设:通过人类输入的方式为AI系统增加更多的控制,可以使用户获得更令人满意的创作所有权和控制权,我们提出了一种图像生成方法,用户可以基于示例进行风格控制,也可以基于文本进行内容控制。遵循艺术理论,即绘画的风格与其内容是相互交织的,我们提出了StyleCLIPDraw,这是一种耦合方法,其中风格和内容在每个迭代中从开始到结束都共同优化。
基于139名随机人类评估者的评估,StyleCLIPDraw在各种风格元素方面比解耦方法更受欢迎,占84.9%的时间,这与我们方法的底层理论相匹配。值得注意的是,尽管在内容方面它不太受欢迎,但当考虑到风格和内容时,StyleCLIPDraw绘画非常受欢迎。这一结果表明,风格对于人们对生成图像感知的重要性至少与图像内容一样,甚至更重要。
作为贡献的一部分,我们开源了我们的方法,以促进未来在这方面的研究。我们的在线演示为非技术用户提供了利用我们工作的工具。我们还公开了研究结果,包括352幅数字绘画,以及整个风格、风格的各个元素和内容的比较。据我们所知,这是第一个包含关于艺术各个元素质量信息的公共数据集,可以为未来自动评估生成图像风格的方法做出贡献。StyleCLIPDraw的未来工作包括以构图输入的形式增加更多的艺术控制,并将运行时间改进到接近实时。