一、引言
数据可视化是机器学习流程中不可或缺的一部分。通过图形和图表展示数据,我们可以更直观地理解数据的分布、趋势和关联,从而更有效地进行数据分析、特征工程和模型评估。Plotly是一个功能强大且灵活的数据可视化库,它提供了丰富的图表类型和交互功能,使得数据可视化过程更加便捷和高效。本文将详细介绍Plotly的基础知识、图表类型、高级功能以及在机器学习中的应用,并通过示例展示其使用方法。
二、Plotly基础
Plotly简介
Plotly是一个基于Web的数据可视化库,它支持多种编程语言,包括Python、R、JavaScript等。Plotly具有强大的图表定制能力、丰富的图表类型和交互功能,广泛应用于数据分析、科学研究和机器学习等领域。Plotly的历史可以追溯到2012年,由克里斯·帕特尔(Chris Plotly)等人创建。经过多年的发展,Plotly已经成为数据可视化领域的佼佼者之一。
安装与设置
要在Python中使用Plotly,你需要首先安装相应的库。你可以使用pip命令来安装Plotly,如下所示:
pip install plotly
此外,为了能够在本地环境中查看Plotly生成的图表,你还需要安装plotly.offline模块。你可以通过以下命令来安装它:
pip install plotly[offline]
安装完成后,你就可以在Python代码中导入Plotly库并开始使用它了。
基本用法
Plotly的基本用法非常简单。下面是一个使用Plotly绘制简单折线图的示例:
import plotly.graph_objects as go
# 创建数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 创建折线图
fig = go.Figure(data=go.Scatter(x=x, y=y))
# 设置图表标题和轴标签
fig.update_layout(title='简单折线图', xaxis_title='X轴', yaxis_title='Y轴')
# 离线显示图表
import plotly.offline as pyo
pyo.plot(fig)
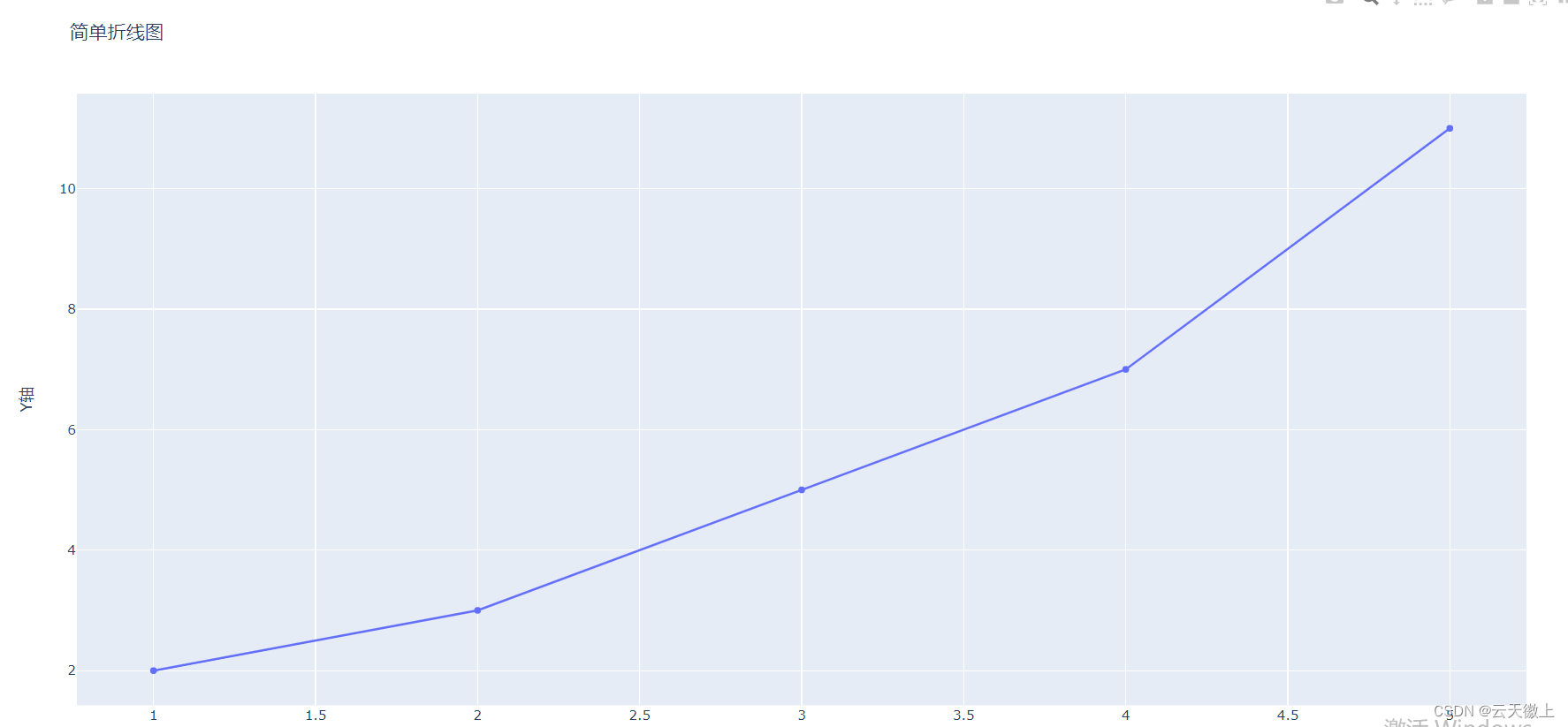
在这个示例中,我们首先导入了plotly.graph_objects模块,并创建了一个包含X轴和Y轴数据的折线图。然后,我们使用update_layout方法设置了图表的标题和轴标签。最后,我们使用plotly.offline模块的plot函数将图表离线显示在本地浏览器中,需要指出的是plotly.graph_objects模块提供了丰富的绘图函数,plotly.express模块也提供丰富的绘图函数,下面的介绍将两个模块配合使用。
通过修改数据和配置选项,你可以轻松地创建出各种不同类型的图表,如散点图、柱状图、饼图等。接下来,我们将详细介绍Plotly支持的图表类型及其用法。
三、Plotly图表类型详解
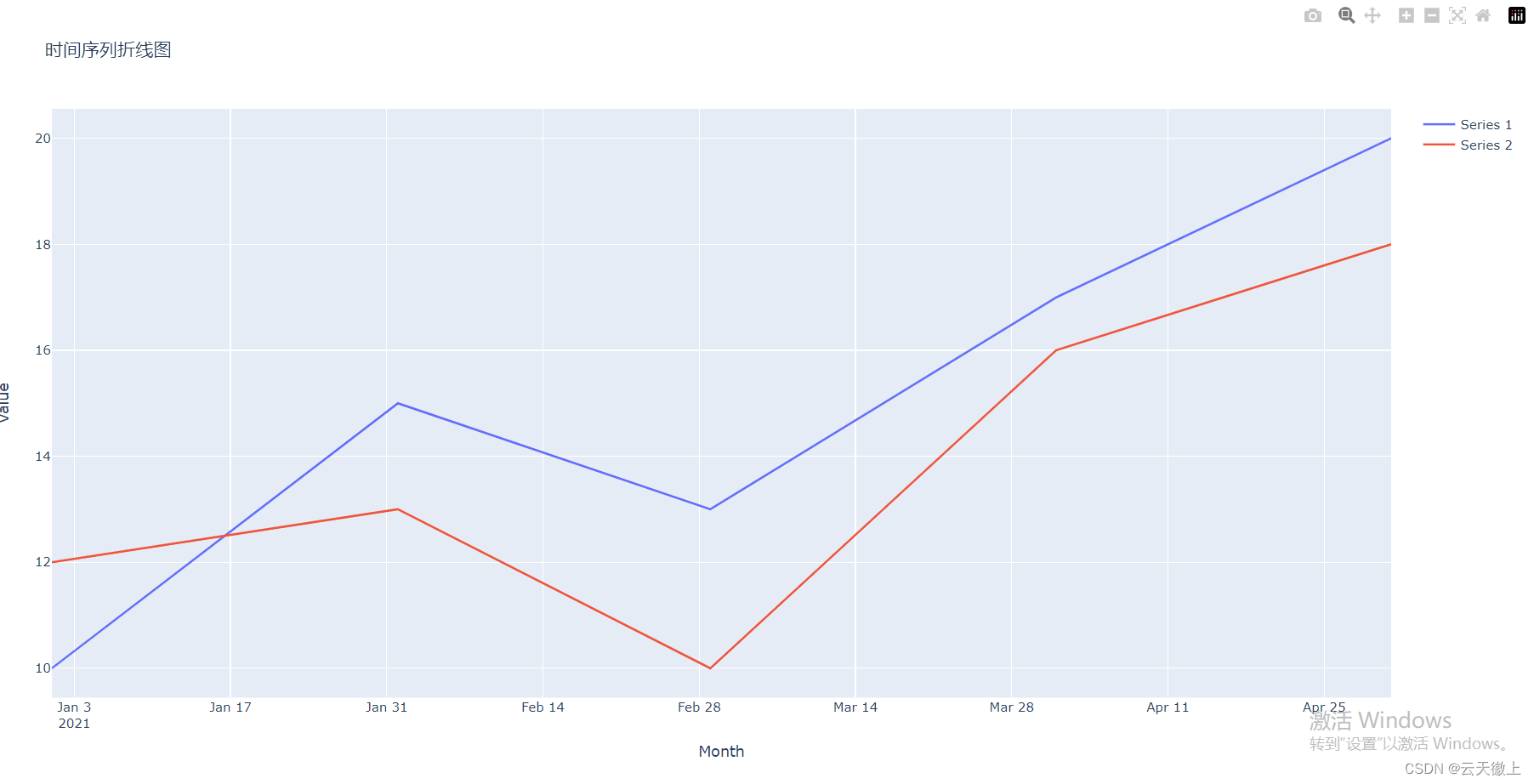
1. 折线图(Line Charts)
折线图通常用于展示时间序列数据或连续数据的变化趋势。Plotly可以轻松绘制多系列折线图,以比较不同数据集的动态。
import plotly.graph_objects as go
# 创建数据
x = ['2021-01', '2021-02', '2021-03', '2021-04', '2021-05']
y1 = [10, 15, 13, 17, 20]
y2 = [12, 13, 10, 16, 18]
# 创建折线图
fig = go.Figure()
fig.add_trace(go.Scatter(x=x, y=y1, mode='lines', name='Series 1'))
fig.add_trace(go.Scatter(x=x, y=y2, mode='lines', name='Series 2'))
# 设置图表标题和轴标签
fig.update_layout(title='时间序列折线图', xaxis_title='Month', yaxis_title='Value')
# 显示图表
fig.show()
2. 散点图(Scatter Plots)
散点图用于展示两个变量之间的关系。在Plotly中,你可以添加颜色、大小等属性来增强图表的可读性。
import plotly.graph_objects as go
# 创建数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
sizes = [10, 20, 30, 40, 50]
colors = ['red', 'orange', 'green', 'blue', 'purple']
# 创建散点图
fig = go.Figure(data=go.Scatter(
x=x, y=y,
mode='markers',
marker=dict(
size=sizes,
color=colors,
opacity=0.8
)
))
# 设置图表标题和轴标签
fig.update_layout(title='散点图', xaxis_title='X轴', yaxis_title='Y轴')
# 显示图表
fig.show()
下面我们可以使用plotly.express模块来绘制气泡图;
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(df.query("year==2007"), x="gdpPercap", y="lifeExp",
size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
fig.show()
3. 柱状图(Bar Charts)
柱状图用于展示分类数据的数量或比例。Plotly支持分组柱状图和堆叠柱状图等多种类型。
import plotly.graph_objects as go
# 创建数据
x = ['Category 1', 'Category 2', 'Category 3']
y1 = [10, 15, 12]
y2 = [8, 12, 16]
# 创建分组柱状图
fig = go.Figure(data=[
go.Bar(name='Series 1', x=x, y=y1),
go.Bar(name='Series 2', x=x, y=y2)
])
# 设置图表标题和轴标签
fig.update_layout(barmode='group', title='分组柱状图', xaxis_title='Category', yaxis_title='Value')
# 显示图表
fig.show()
4. 饼图(Pie Charts)
饼图用于展示分类数据的比例关系。在Plotly中,你可以轻松地绘制出各种颜色的扇形来代表不同分类。
import plotly.graph_objects as go
# 创建数据
labels = ['Category 1', 'Category 2', 'Category 3']
values = [15, 30, 55]
# 创建饼图
fig = go.Figure(data=[go.Pie(labels=labels, values=values)])
# 设置图表标题
fig.update_layout(title='饼图')
# 显示图表
fig.show()
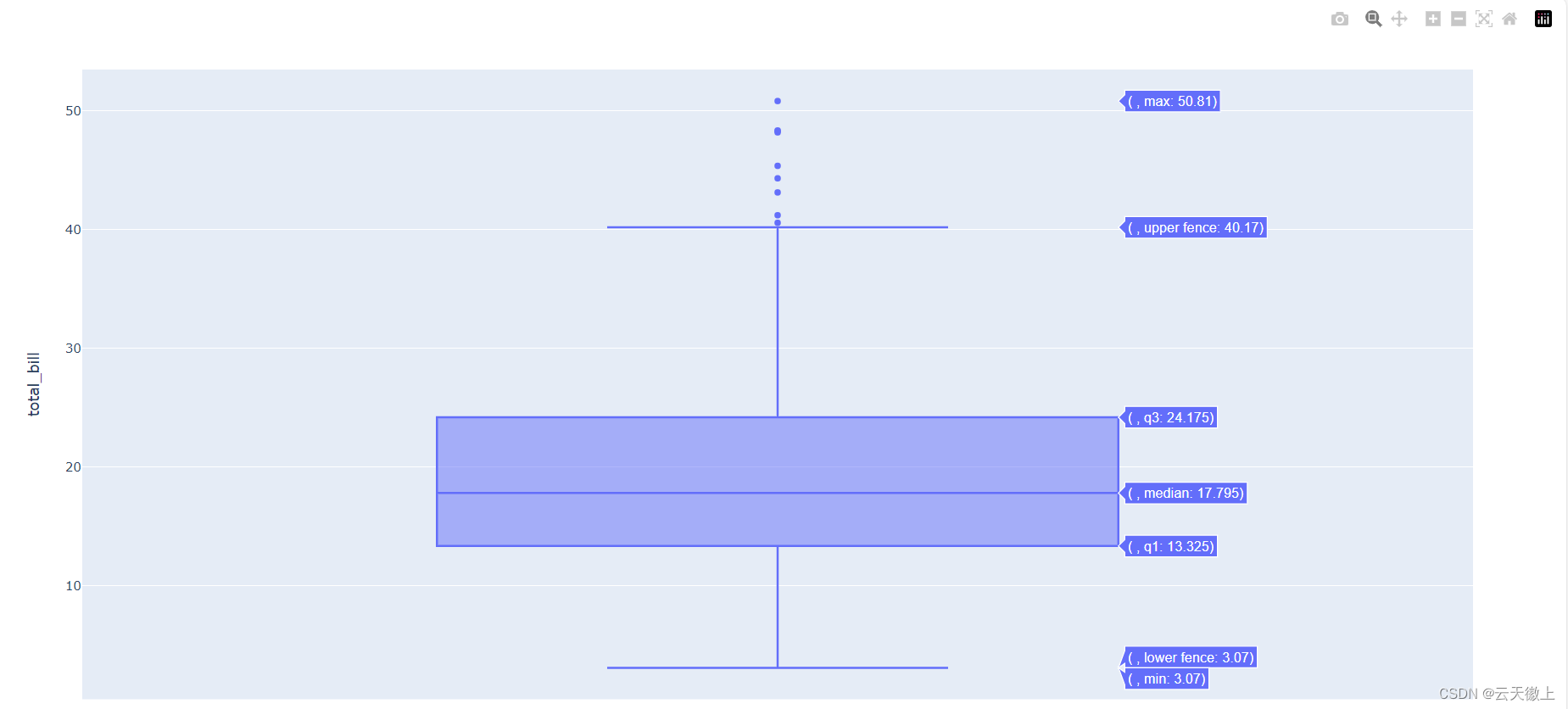
5. 箱线图(Box Plots)
箱线图是一种展示数据分布和异常值的图表类型。在Plotly中,你可以通过箱线图快速了解数据的四分位数、中位数和异常值。
import plotly.express as px
df = px.data.tips()
fig = px.box(df, y="total_bill")
fig.show()
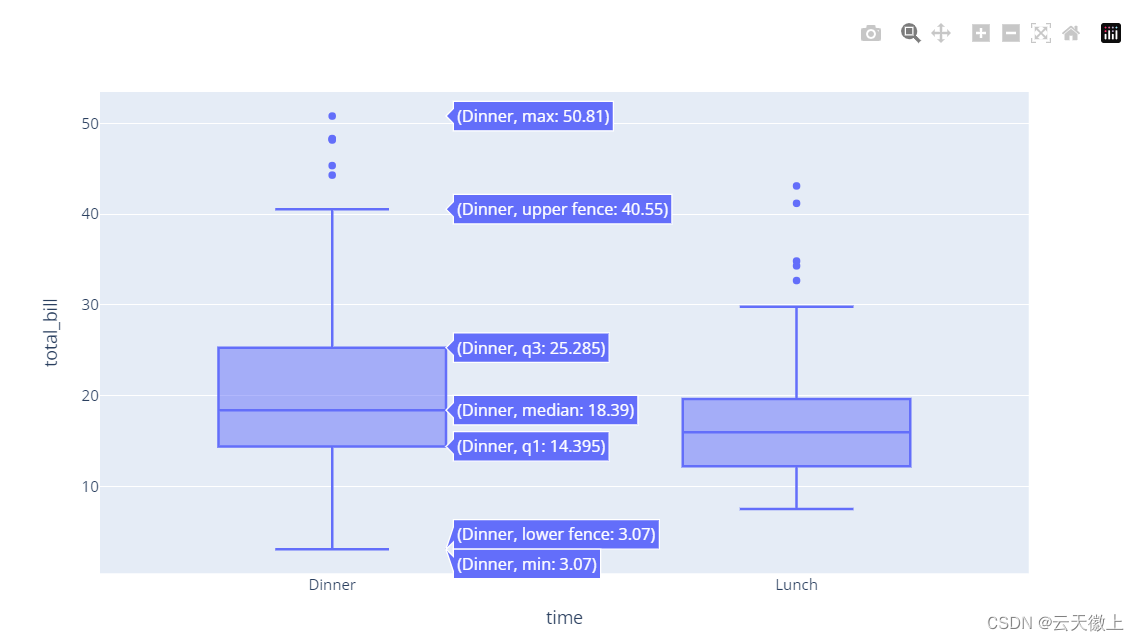
import plotly.express as px
df = px.data.tips()
fig = px.box(df, x="time", y="total_bill")
fig.show()
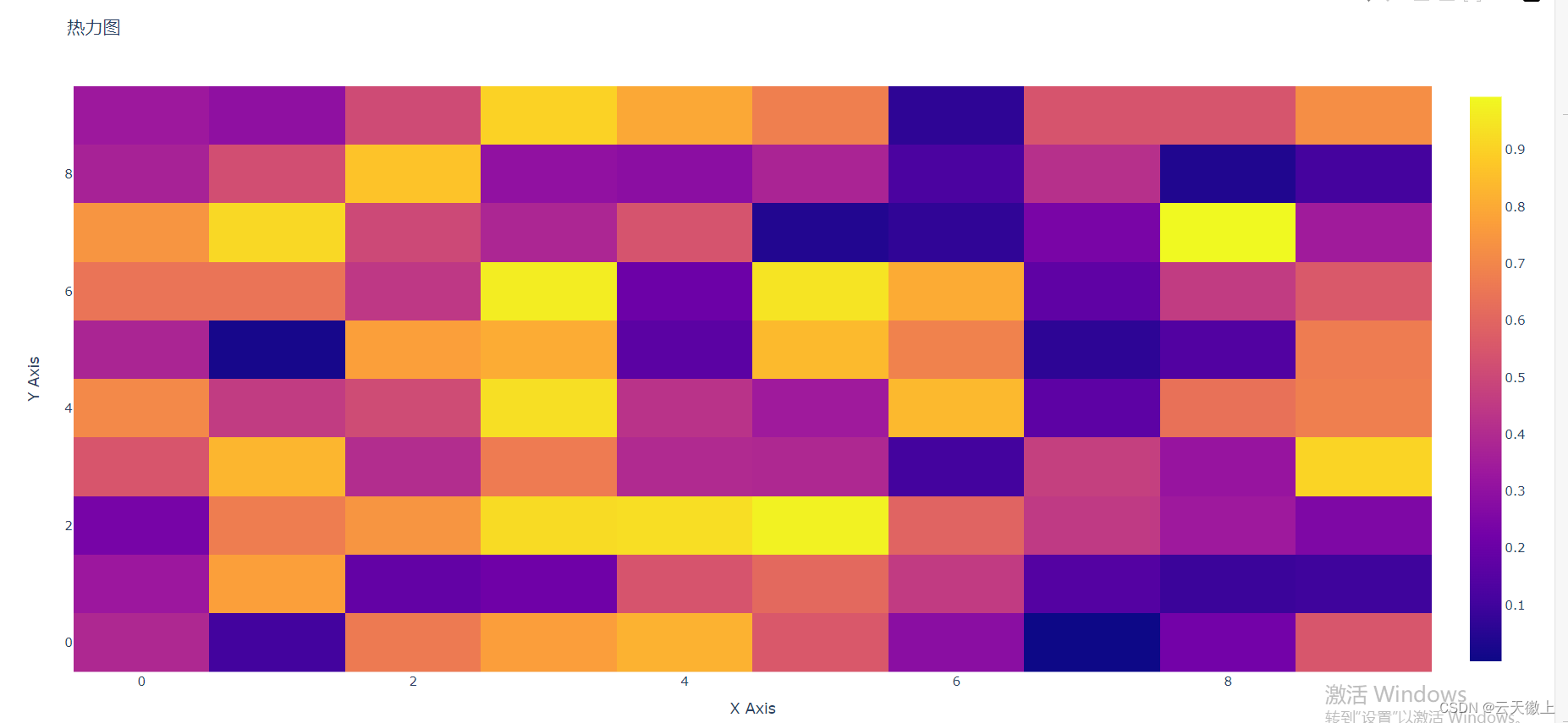
6. 热力图(Heatmaps)
热力图用于展示二维数据矩阵中的数值分布。颜色深浅表示数值的大小,非常适合用于展示表格数据或矩阵数据。
import plotly.graph_objects as go
import numpy as np
# 创建数据
z = np.random.rand(10, 10)
# 创建热力图
fig = go.Figure(data=go.Heatmap(z=z))
# 设置图表标题和轴标签
fig.update_layout(title='热力图', xaxis_title='X Axis', yaxis_title='Y Axis')
# 显示图表
fig.show()
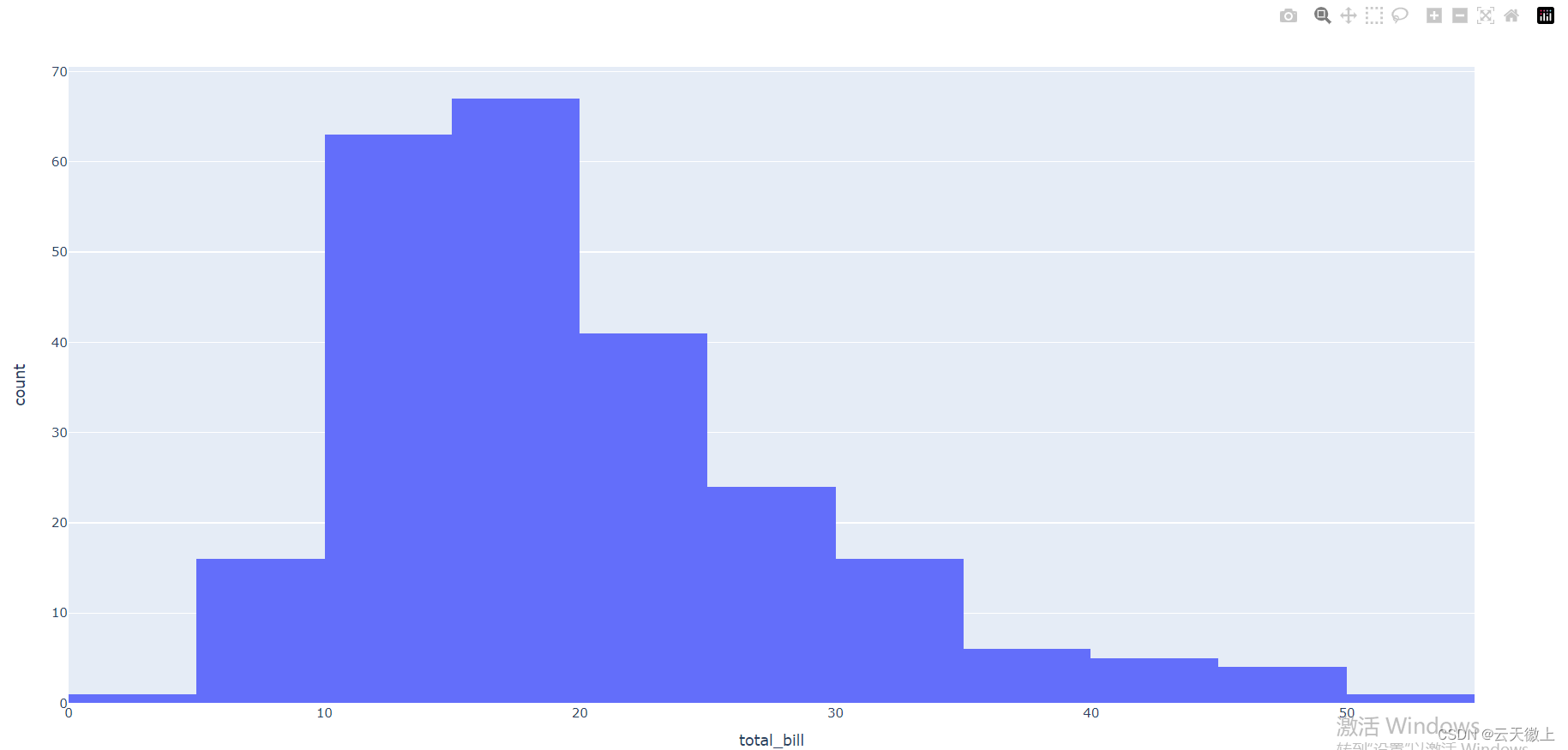
7.直方图
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", nbins=20)
fig.show()
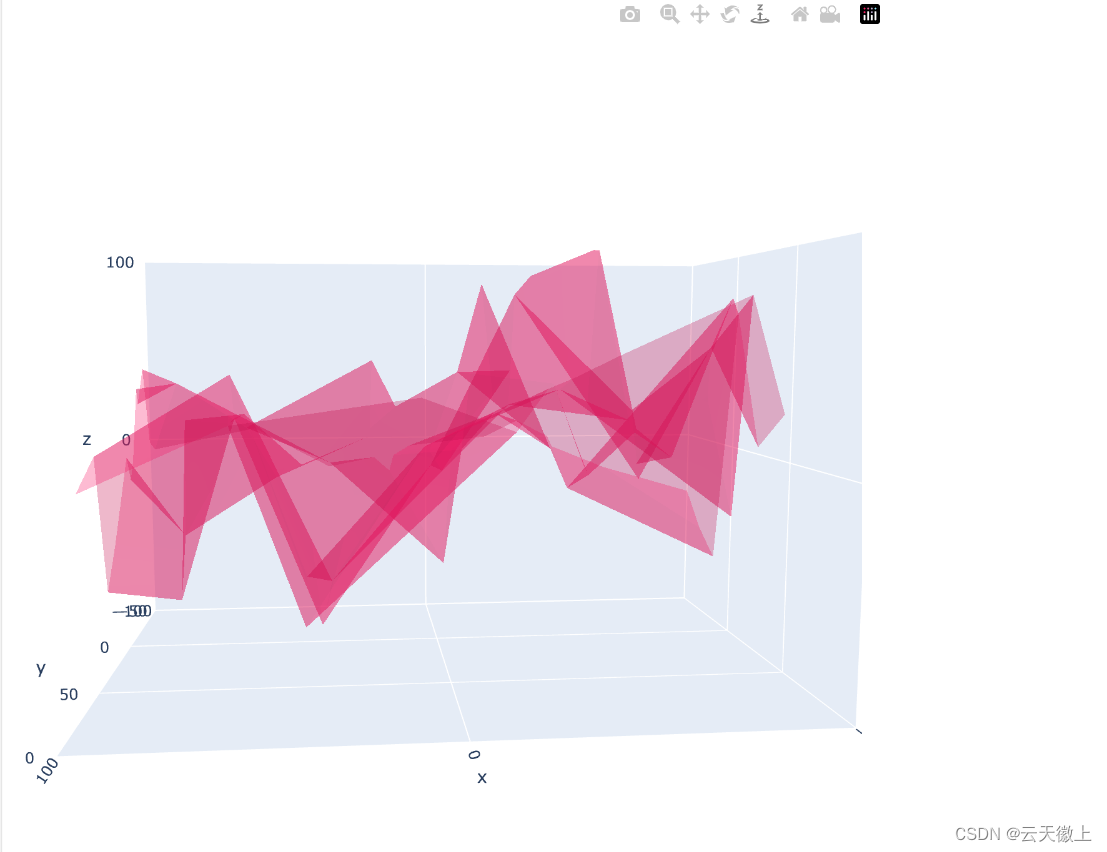
8. 三维图表(3D Charts)
Plotly还支持绘制三维图表,如三维散点图、三维曲面图等,用于展示三维空间中的数据。
import plotly.graph_objects as go
import numpy as np
np.random.seed(1)
N = 70
fig = go.Figure(data=[go.Mesh3d(x=(70*np.random.randn(N)),
y=(55*np.random.randn(N)),
z=(40*np.random.randn(N)),
opacity=0.5,
color='rgba(244,22,100,0.6)'
)])
fig.update_layout(
scene = dict(
xaxis = dict(nticks=4, range=[-100,100],),
yaxis = dict(nticks=4, range=[-50,100],),
zaxis = dict(nticks=4, range=[-100,100],),),
width=700,
margin=dict(r=20, l=10, b=10, t=10))
fig.show()
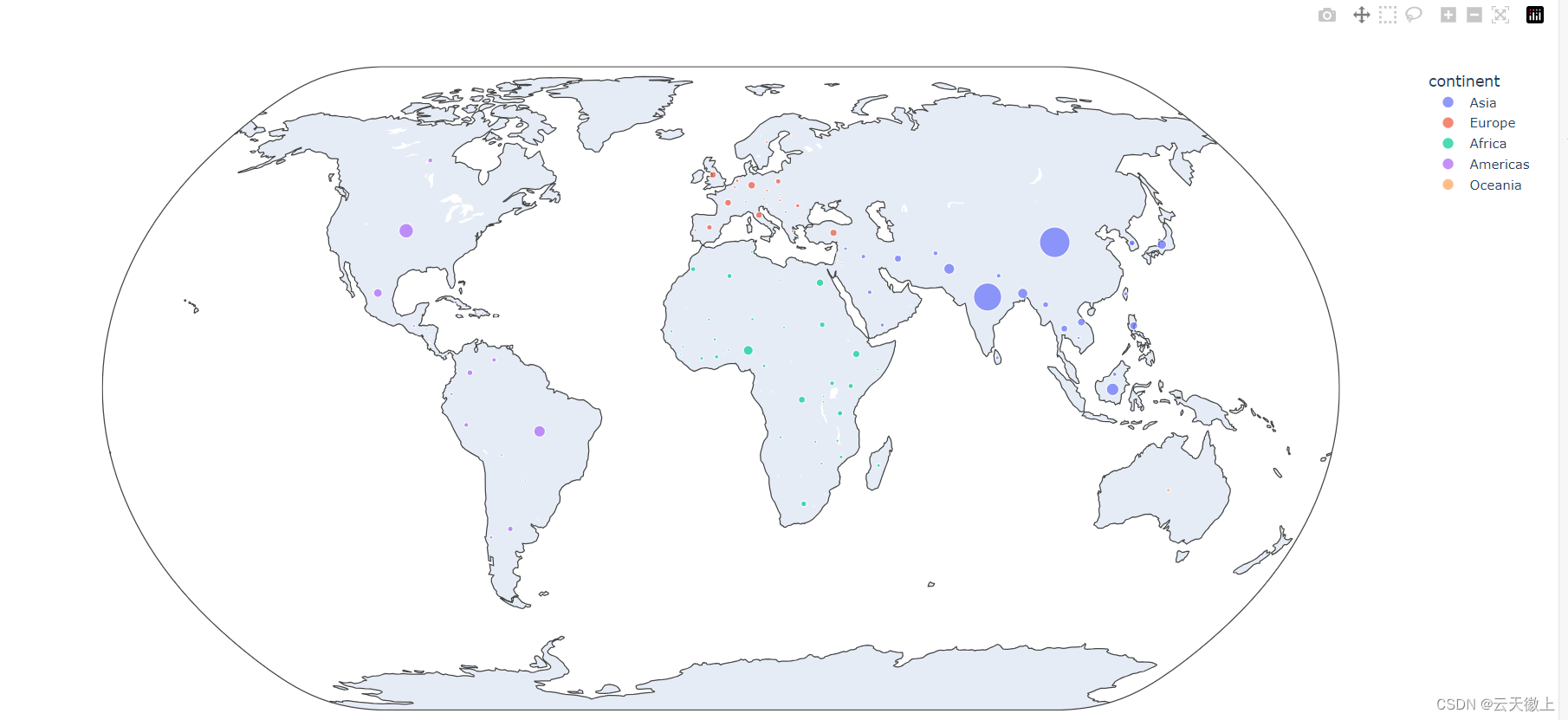
9. 地图可视化
Plotly支持地理数据的可视化,包括绘制散点图、热力图等在地图上。你可以使用内置的地图投影和坐标系统,或者上传自定义的GeoJSON文件。
import plotly.express as px
df = px.data.gapminder().query("year==2007")
fig = px.scatter_geo(df, locations="iso_alpha", color="continent",
hover_name="country", size="pop",
projection="natural earth")
fig.show()
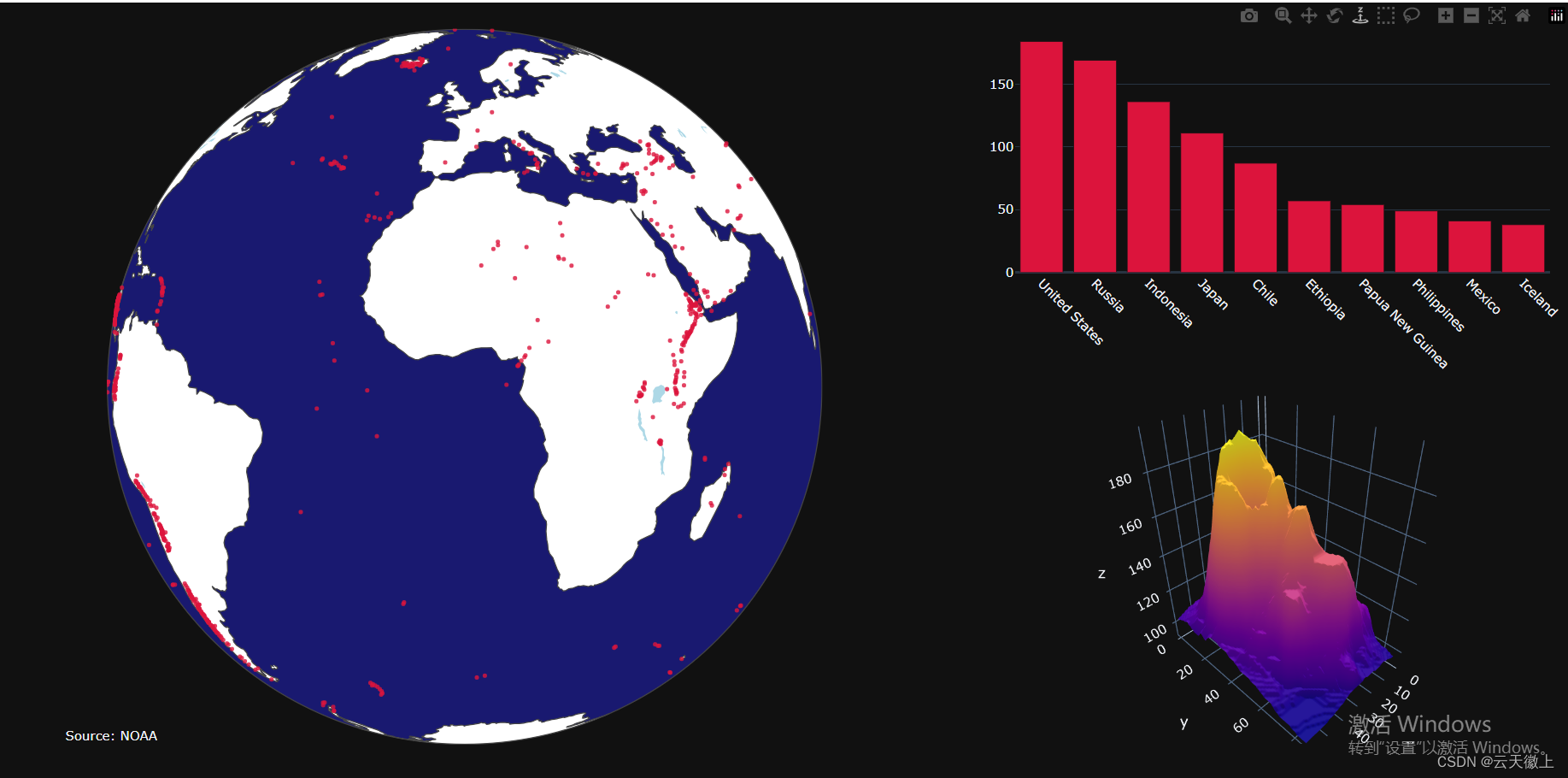
10. 子图(Subplots)
Plotly支持在一个图表中绘制多个子图,这对于比较不同数据集或展示多个维度的数据非常有用。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import pandas as pd
# read in volcano database data
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/volcano_db.csv",
encoding="iso-8859-1",
)
# frequency of Country
freq = df
freq = freq.Country.value_counts().reset_index().rename(columns={"index": "x"})
# read in 3d volcano surface data
df_v = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/volcano.csv")
# Initialize figure with subplots
fig = make_subplots(
rows=2, cols=2,
column_widths=[0.6, 0.4],
row_heights=[0.4, 0.6],
specs=[[{"type": "scattergeo", "rowspan": 2}, {"type": "bar"}],
[ None , {"type": "surface"}]])
# Add scattergeo globe map of volcano locations
fig.add_trace(
go.Scattergeo(lat=df["Latitude"],
lon=df["Longitude"],
mode="markers",
hoverinfo="text",
showlegend=False,
marker=dict(color="crimson", size=4, opacity=0.8)),
row=1, col=1
)
# Add locations bar chart
fig.add_trace(
go.Bar(x=freq["x"][0:10],y=freq["Country"][0:10], marker=dict(color="crimson"), showlegend=False),
row=1, col=2
)
# Add 3d surface of volcano
fig.add_trace(
go.Surface(z=df_v.values.tolist(), showscale=False),
row=2, col=2
)
# Update geo subplot properties
fig.update_geos(
projection_type="orthographic",
landcolor="white",
oceancolor="MidnightBlue",
showocean=True,
lakecolor="LightBlue"
)
# Rotate x-axis labels
fig.update_xaxes(tickangle=45)
# Set theme, margin, and annotation in layout
fig.update_layout(
template="plotly_dark",
margin=dict(r=10, t=25, b=40, l=60),
annotations=[
dict(
text="Source: NOAA",
showarrow=False,
xref="paper",
yref="paper",
x=0,
y=0)
]
)
fig.show()
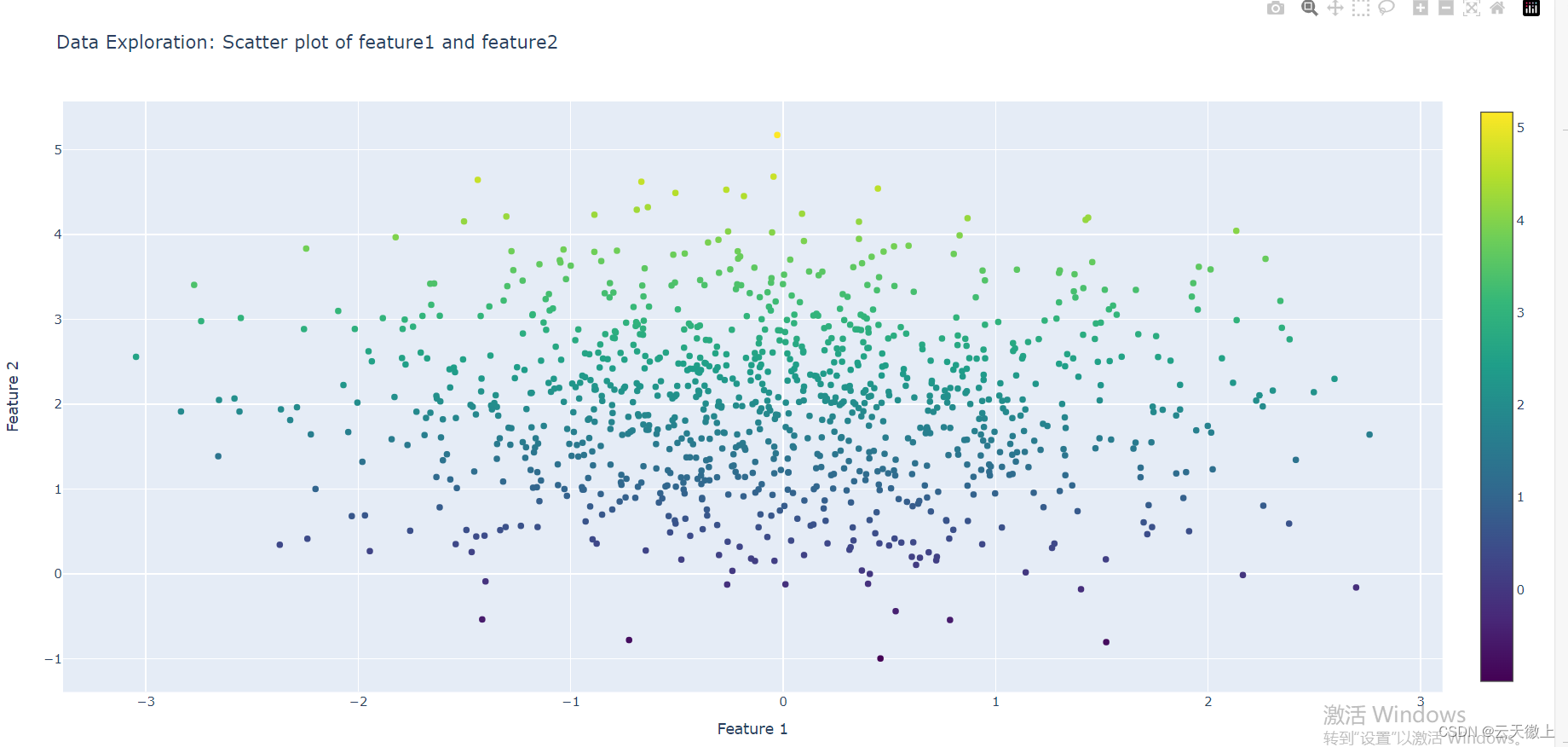
四、Plotly在机器学习中的应用
1. 数据探索
数据探索是机器学习项目中的关键步骤,通过可视化技术可以帮助我们更好地理解数据。Plotly可以轻松地创建各种图表来展示数据的分布、趋势和相关性。
示例代码:使用Plotly绘制散点图和直方图进行数据探索
import plotly.graph_objects as go
import numpy as np
import pandas as pd
# 假设我们有一个DataFrame,包含两个特征'feature1'和'feature2'
# 这里我们使用随机数据作为示例
np.random.seed(0)
data = pd.DataFrame({
'feature1': np.random.randn(1000),
'feature2': np.random.randn(1000) + 2
})
# 使用散点图查看特征之间的关系
fig = go.Figure(data=go.Scatter(
x=data['feature1'],
y=data['feature2'],
mode='markers',
marker=dict(
color=data['feature2'], # 设置颜色以区分不同数值
colorscale='Viridis', # 使用Viridis颜色比例尺
showscale=True
)
))
# 添加标题和轴标签
fig.update_layout(
title='Data Exploration: Scatter plot of feature1 and feature2',
xaxis_title='Feature 1',
yaxis_title='Feature 2'
)
# 显示图表
fig.show()
# 使用直方图查看特征的分布
fig = go.Figure([go.Histogram(x=data['feature1']), go.Histogram(x=data['feature2'])])
# 自定义直方图的布局
fig.update_layout(
barmode='overlay',
title='Data Exploration: Histogram of features',
xaxis_title='Value',
yaxis_title='Count'
)
# 显示图表
fig.show()
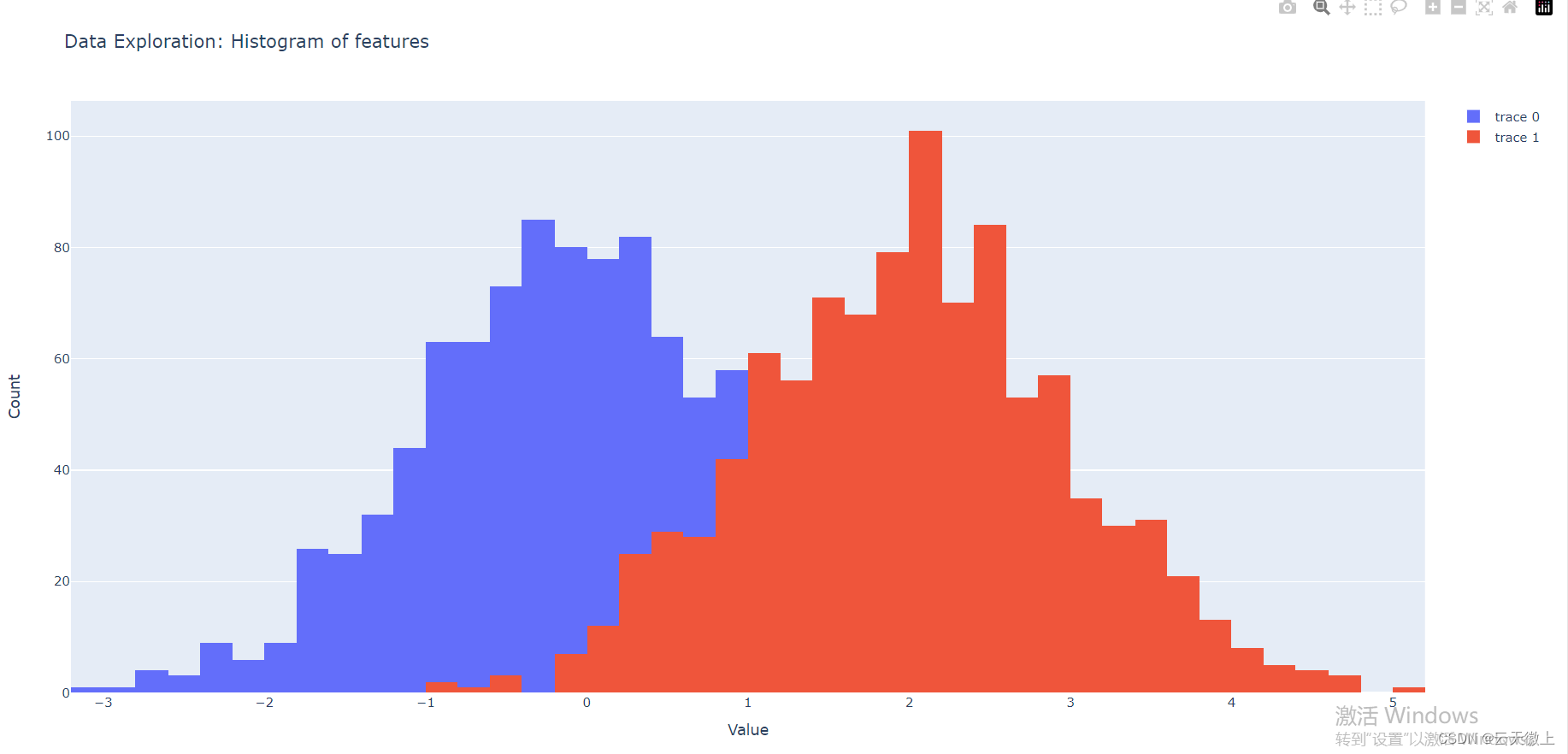
2. 模型评估
模型评估是机器学习项目中的重要环节,Plotly可以帮助我们绘制评估图表,如混淆矩阵、ROC曲线等,以直观地展示模型的性能。
示例代码:使用Plotly绘制混淆矩阵
import plotly.express as px
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=500, random_state=0)
model = LogisticRegression()
model.fit(X, y)
y_score = model.predict_proba(X)[:, 1]
fpr, tpr, thresholds = roc_curve(y, y_score)
# The histogram of scores compared to true labels
fig_hist = px.histogram(
x=y_score, color=y, nbins=50,
labels=dict(color='True Labels', x='Score')
)
fig_hist.show()
# Evaluating model performance at various thresholds
df = pd.DataFrame({
'False Positive Rate': fpr,
'True Positive Rate': tpr
}, index=thresholds)
df.index.name = "Thresholds"
df.columns.name = "Rate"
fig_thresh = px.line(
df, title='TPR and FPR at every threshold',
width=700, height=500
)
fig_thresh.update_yaxes(scaleanchor="x", scaleratio=1)
fig_thresh.update_xaxes(range=[0, 1], constrain='domain')
fig_thresh.show()
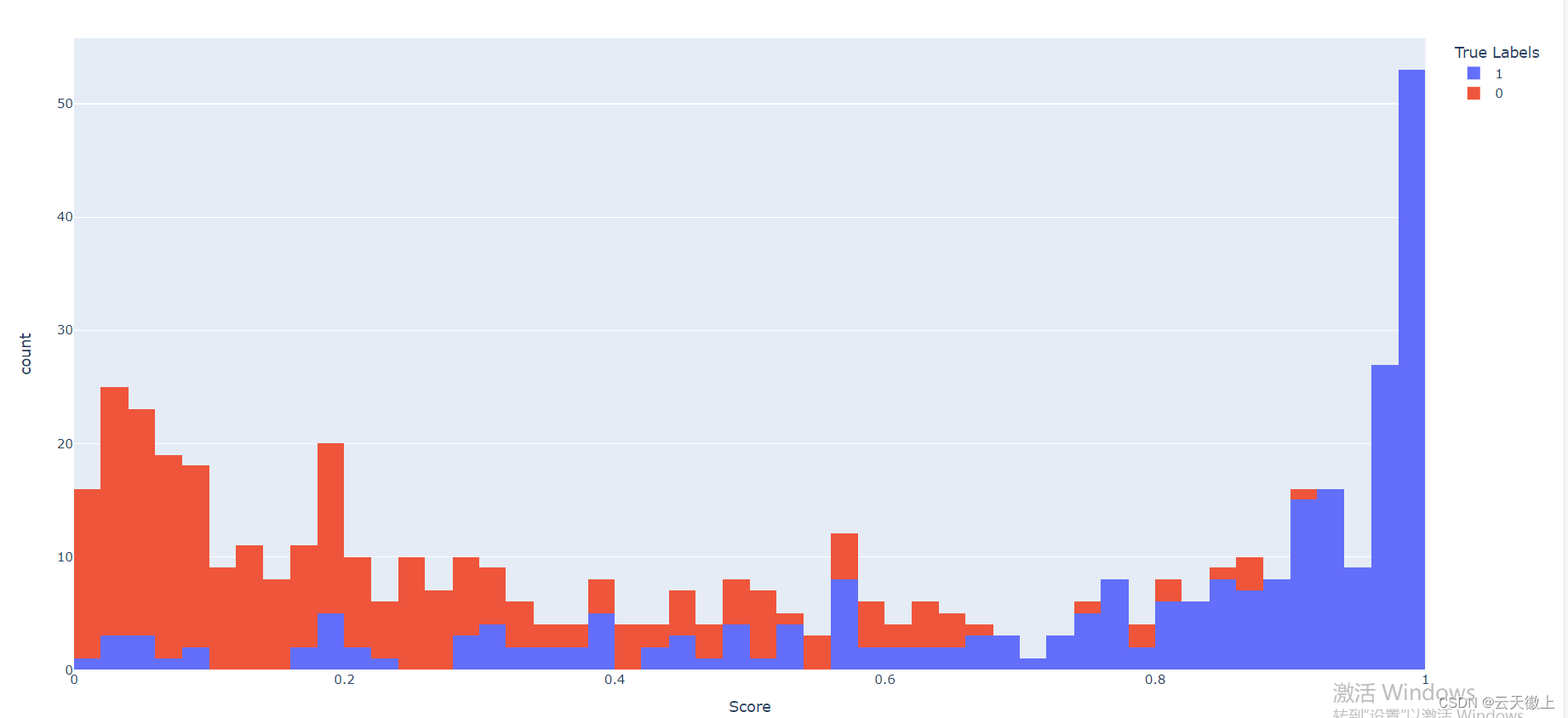
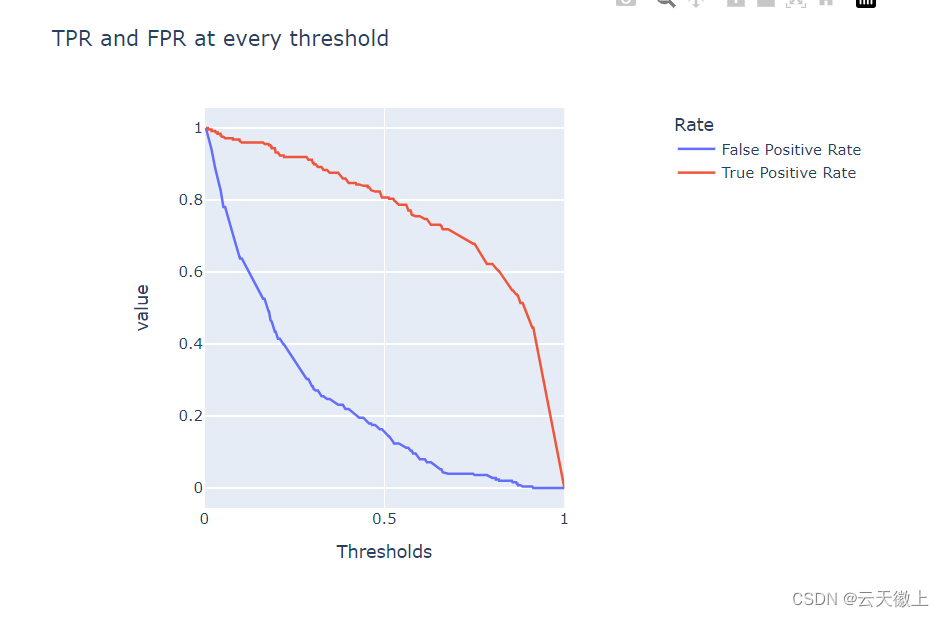
注意:对于更复杂的评估图表(如ROC曲线),可能需要使用sklearn.metrics中的函数来生成数据,并使用Plotly的曲线图(go.Scatter)或其他适合的图表类型进行绘制。
import plotly.express as px
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=500, random_state=0)
model = LogisticRegression()
model.fit(X, y)
y_score = model.predict_proba(X)[:, 1]
fpr, tpr, thresholds = roc_curve(y, y_score)
fig = px.area(
x=fpr, y=tpr,
title=f'ROC Curve (AUC={auc(fpr, tpr):.4f})',
labels=dict(x='False Positive Rate', y='True Positive Rate'),
width=700, height=500
)
fig.add_shape(
type='line', line=dict(dash='dash'),
x0=0, x1=1, y0=0, y1=1
)
fig.update_yaxes(scaleanchor="x", scaleratio=1)
fig.update_xaxes(constrain='domain')
fig.show()
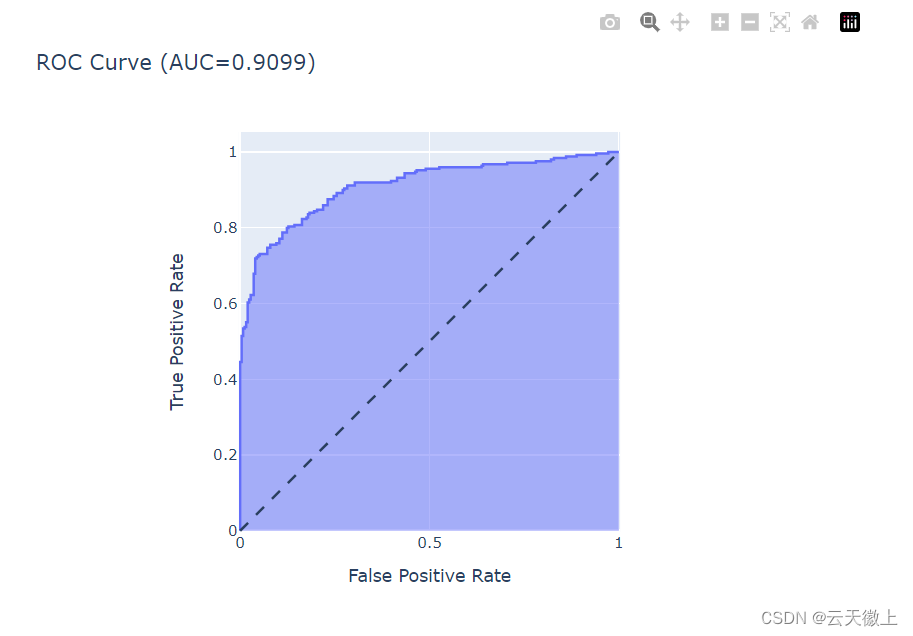
3. 特征工程
特征工程是机器学习项目中的另一个关键步骤,Plotly可以用于可视化特征之间的关系,以指导特征选择和转换。
示例代码:使用Plotly绘制特征之间的相关性矩阵
import seaborn as sns
import plotly.express as px
import pandas as pd
# 假设我们有一个包含多个特征的DataFrame
# 这里我们使用seaborn的内置数据集作为示例
data = sns.load_dataset('iris')
# 使用Plotly Express绘制相关性矩阵热力图
fig = px.imshow(data.corr(), color_continuous_scale='Viridis')
# 添加标题和轴标签
fig.update_layout(
title='Feature Correlation Matrix',
xaxis_title='Features',
yaxis_title='Features'
)
# 显示图表
fig.show()
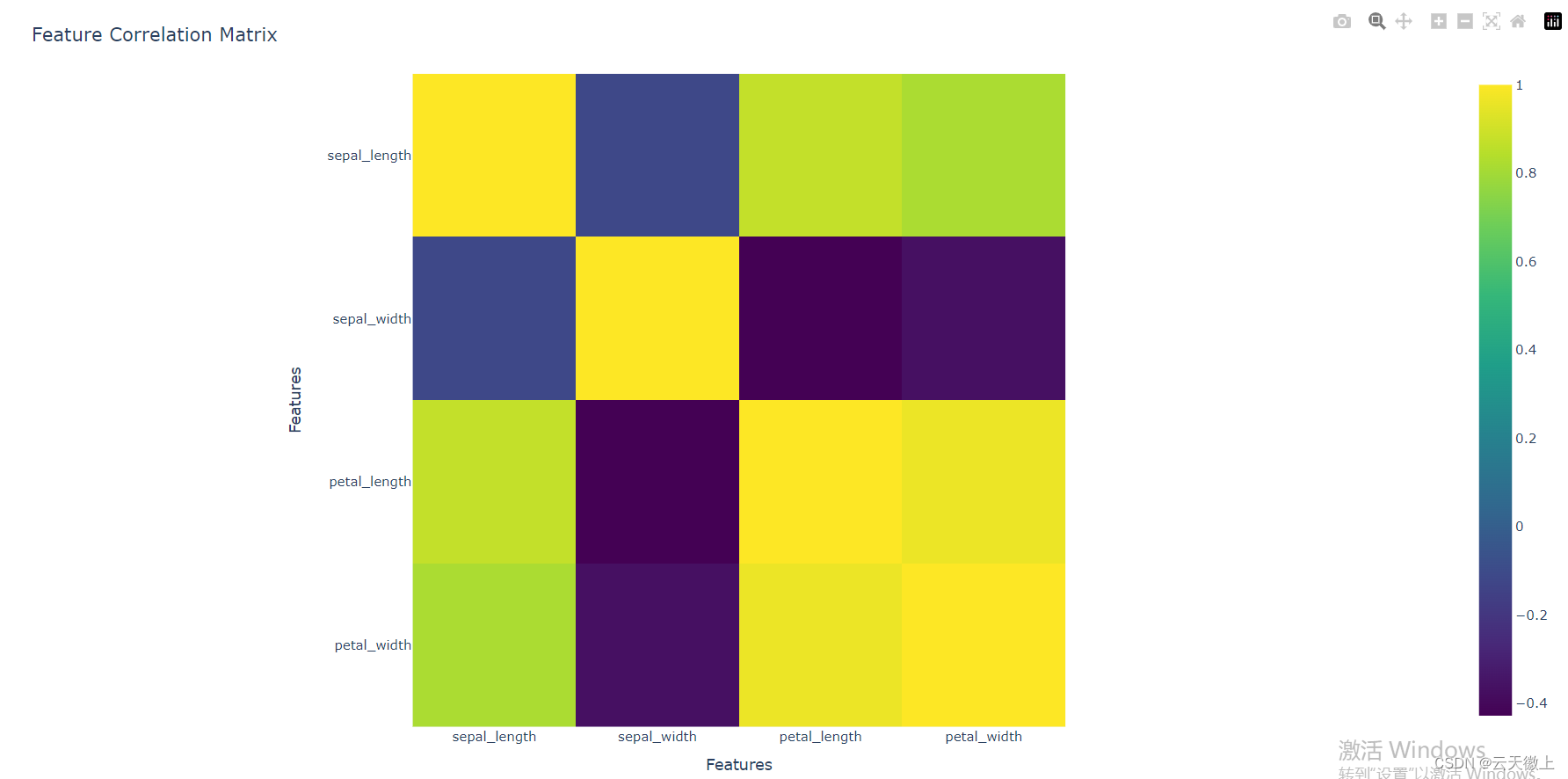
在这个例子中,我们使用了Plotly Express(Plotly的一个高级接口),它简化了数据可视化的流程。通过相关性矩阵热力图,我们可以快速识别出哪些特征之间存在高度相关性,从而指导特征选择和转换。
五、总结与展望
总结
Plotly作为一款功能强大的数据可视化库,在机器学习项目中发挥着重要作用。它支持多种编程语言,包括Python、R和JavaScript,提供了丰富的图表类型和高度可定制化的选项,使得数据探索和模型评估变得更加直观和高效。
在数据探索阶段,Plotly可以帮助我们快速生成各种图表,如散点图、直方图、箱线图等,以展示数据的分布、趋势和相关性。这些图表有助于我们更好地理解数据,发现数据中的模式和异常值,为后续的特征工程和模型训练提供有价值的指导。
在模型评估阶段,Plotly可以用于绘制混淆矩阵、ROC曲线等评估图表,以直观地展示模型的性能。这些图表有助于我们评估模型的分类效果和泛化能力,从而调整模型参数或选择更合适的模型。
在特征工程阶段,Plotly可以用于可视化特征之间的关系,如相关性矩阵热力图等。这些图表有助于我们识别出高度相关的特征,从而指导特征选择和转换,提高模型的预测性能。
展望
随着数据科学和机器学习的不断发展,数据可视化将变得越来越重要。Plotly作为一款功能强大的数据可视化库,未来将继续发展并改进其功能,以满足不断增长的需求。
首先,Plotly可以进一步加强对交互式图表的支持,使得用户能够更直观地探索和分析数据。例如,通过添加更多交互式元素和动画效果,用户可以更深入地了解数据的细节和模式。
其次,Plotly可以进一步扩展其图表类型和定制化选项,以满足更多领域和场景的需求。例如,可以添加更多适用于金融、医疗等领域的专业图表类型,并提供更多可定制的样式和主题选项。
最后,Plotly可以加强与其他数据科学和机器学习库的集成,提供更加便捷的数据处理和可视化解决方案。例如,可以与Pandas、NumPy等数据处理库进行无缝集成,使得数据预处理和可视化分析更加高效和简单。
六、附录
参考资料和链接
- Plotly官方文档:https://plotly.com/python/
- Plotly Express教程:https://plotly.com/python/plotly-express/
- Seaborn数据集:https://seaborn.pydata.org/generated/seaborn.load_dataset.html
建议进一步学习的资源和书籍
- 《Python数据可视化:使用Matplotlib、Pandas、Seaborn和Plotly》:这本书详细介绍了Python中常用的数据可视化库,包括Plotly的使用方法和技巧。
- 《数据科学实战》:这本书涵盖了数据科学领域的各个方面,包括数据探索、特征工程、模型训练和评估等,并提供了丰富的实战案例和代码实现。
- Plotly官方教程和社区论坛:Plotly官方提供了丰富的教程和示例代码,同时还有一个活跃的社区论坛,用户可以在其中提问和分享经验。