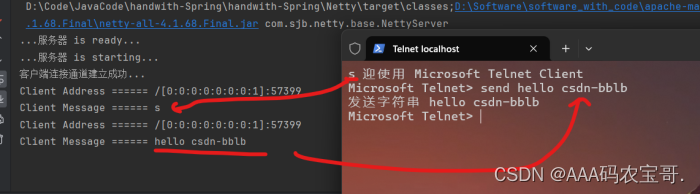
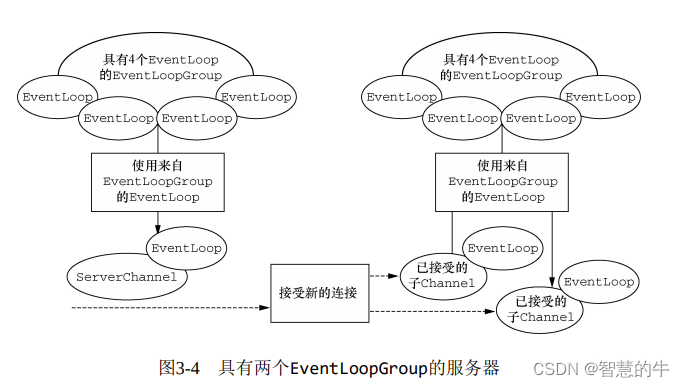
网络输入输出缓冲区(Buffer)是为了优化网络通信性能而设计的。通过将数据存储在缓冲区中,可以减少对网络的频繁访问,提高数据传输效率。缓冲区还可以帮助处理数据流中的突发性和短时延,使得数据的发送和接收更加稳定和可靠。
引言
epoll LT模式
在使用 epoll 时常常选择 LT(Level Triggered,水平触发)模式而不是 ET(Edge Triggered,边缘触发)模式。
-
与 poll 兼容: LT 模式在某种程度上与 poll 函数的行为兼容,因为它会在文件描述符就绪时通知应用程序,并且不会遗漏任何就绪事件。
-
避免 busy loop: 在 LT 模式下,应用程序不需要立即关注 POLLOUT 事件,因为一旦出现 POLLOUT 事件,它会一直触发直到将数据完全写入内核缓冲区。因此,可以将未写入的数据添加到应用层的输出缓冲区,直到数据全部写入完成。这相当于在数据写入完成时进行一个写完成的回调,避免了 busy loop 的情况,即不断循环等待 POLLOUT 事件而没有实际的数据可写入的情况。
-
避免等待 EAGAIN: 在 LT 模式下,应用程序可以在读写操作中不必等待 EAGAIN 错误,这可以节省系统调用次数并降低延迟。因为 LT 模式会持续通知应用程序文件描述符就绪的状态,所以应用程序可以立即执行读写操作而无需等待额外的信号,从而提高效率。
为什么需要有应用层缓冲区?
应用层缓冲区Buffer设计
设计要求
muduo库的 buffer 设计考虑常见网络编程需求,在易用性和性能之间找一个平衡点,目前更偏向易用性。
- 对外表现为一块连续的内存(char*, len),以便客户代码的编写。
- size()可以自动增长,以适应不同大小的消息,不是一个固定大小的数组。
- 内部以vector of char来保存数据,并提供相应的访问函数。
Buffer是非线程安全的,原因在于任何处理缓冲区的操作都是在同一个线程中完成的,因此不需要考虑线程安全性。
Buffer数据结构
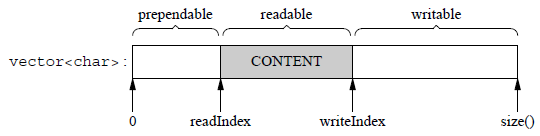
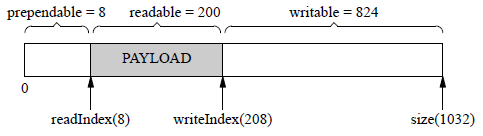
2个index标记 readIndex、writeIndex把vector内容分为3块:prependable、readable、writable,各块大小关系:
prependable(可添加部分):这部分的大小由readIndex标记确定,即在readIndex之前的部分。在这个区域内,程序可以以很低的代价在数据的前面添加几个字节,因为它们不会覆盖到已有的数据。
readable(可读部分):这部分的大小由writeIndex和readIndex之差确定,即writeIndex减去readIndex。这表示已经写入的数据,但尚未读取的部分。
writable(可写部分):这部分的大小由vector的总大小减去writeIndex确定,即size()减去writeIndex。这表示还可以写入数据的部分。
Buffer class的核心数据成员:
class Buffer : public muduo::copyable
{
public:
...
private:
std::vector<char> buffer_; // 存储数据的线性缓冲区, 大小可变
size_t readerIndex_; // 可读数据首地址, i.e. readable空间首地址
size_t writerIndex_; // 可写数据首地址, i.e. writable空间首地址
...
};
Buffer中有2个常数:kCheapPrepend,kInitialSize,分别定义了prependable初始大小,writable的初始大小。readable初始大小0。
static const size_t kCheapPrepend = 8; // 初始预留的prependable空间大小
static const size_t kInitialSize = 1024; // Buffer初始大小
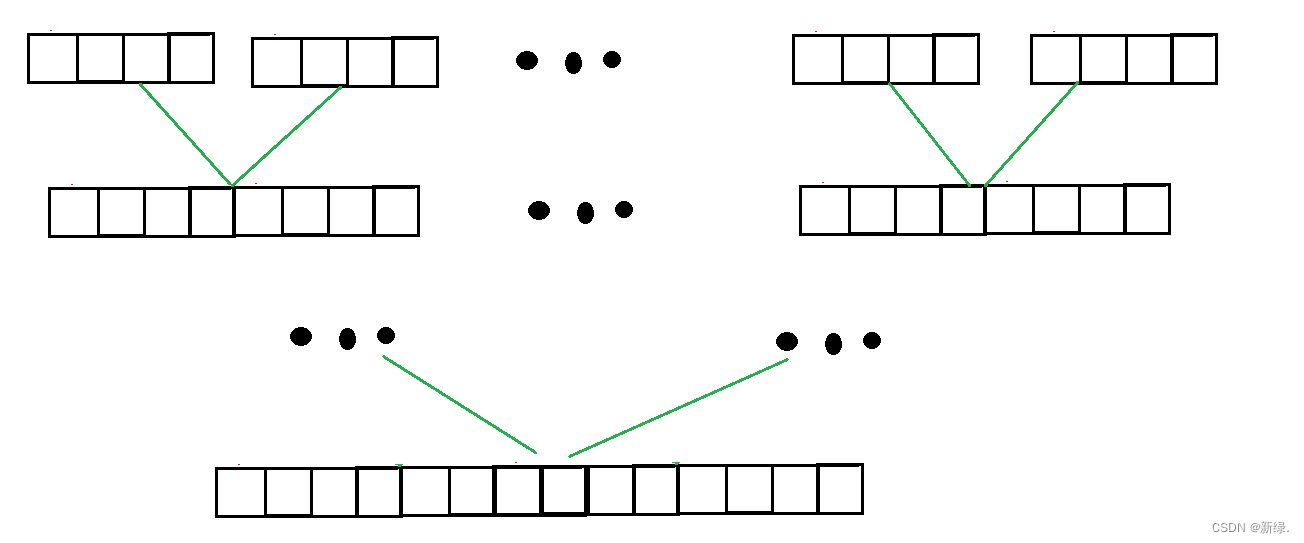
初始化完成后,Buffer数据结构如下:

基本IO操作
Buffer初始化完成后,向Buffer写入200byte,其布局是:
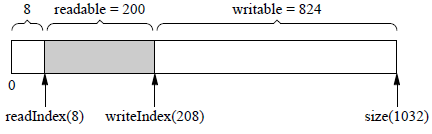
可以看到,writeIndex向后移动了200,readIndex保持不变。readable、writable都有变化。
如果从Buffer 读入 50byte,其布局是:
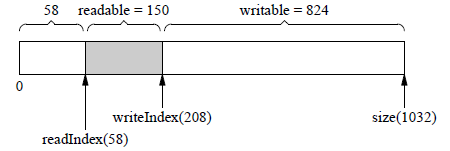 可以看到,readIndex向后移动50,writeIndex保持不变,readable和writable的值也有变化。
可以看到,readIndex向后移动50,writeIndex保持不变,readable和writable的值也有变化。
自动增长
Buffer长度不是固定的,可以自动增长,因为底层存储利用的是vector。
假设当前可写空间writable为624 byte,现客户代码一次写入1000,那么buffer会自动增长。
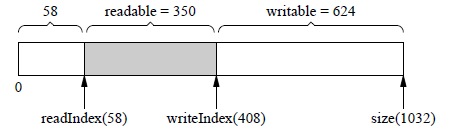
增长后:
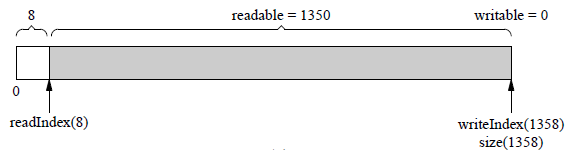
readable由350增长为1350(刚好增加了1000),writable由624减为0。另外,readIndex由58回到了初始位置8,保证prependable等于kCheapPrependable。
buffer没有缩小功能,下次写入1350byte就不会重新分配内存,一方面避免浪费内存,另一方面避免反复分配内存。
size()和capacity()
Buffer使用vector存储数据,可以得到它的capacity()机制的好处,减少内存分配次数。在写入的数据不超过capacity() - size()时,都不会重新分配内存。
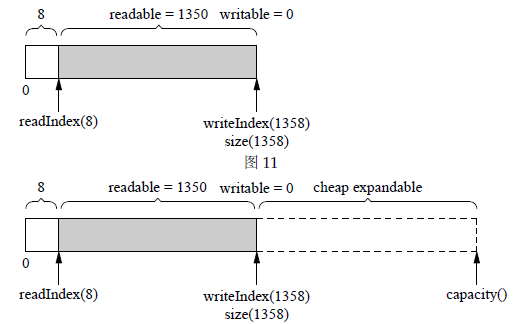
在Muduo中,如果不手动调用reserve()方法来预先分配足够的空间,而是在构造Buffer对象时将初始大小设为1K,当Buffer中的数据量超过1K时,vector会自动扩容,这个扩容操作实际上相当于调用了resize()方法来增加vector的容量,从而达到了预分配空间的效果。
内部腾挪
经过若干次读写,readIndex移到了比较靠后的位置,留下了很大的prependable空间,如下图已由初始8 byte,变成532。
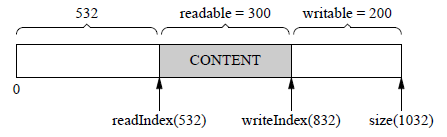
此时,如果想写入300byte,而writable只有200,怎么办?
Buffer不会重新分配内存,而是先把已有的数据移到前面去,减小多余prependable空间,为writable腾出空间。
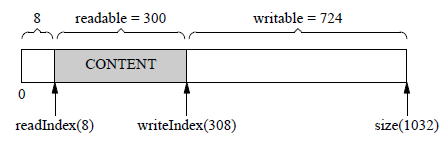
这样,writable变成724 byte,就可以写入300 byte 数据了。
prepend
通过预留kCheapPrepend空间,即提前分配一定大小的prependable空间,可以简化客户端代码。客户端在准备数据时,只需要将要添加的信息直接填充到prependable空间即可,而无需担心prepend操作可能导致的内存重新分配和数据移动。
Buffer类的实现
构造函数与析构函数
构造函数见下,析构函数用编译器合成的默认版本。
/* 构造函数 内部缓冲区buffer_初始大小默认kCheapPrepend + initialSize (1032byte) */
explicit Buffer(size_t initialSize = kInitialSize):
buffer_(kCheapPrepend + initialSize),
readerIndex_(kCheapPrepend), // 8
writerIndex_(kCheapPrepend) // 8
{
assert(readableBytes() == 0);
assert(writableBytes() == initialSize);
assert(prependableBytes() == kCheapPrepend);
}
读取属性
读取prependable, readable, writable空间地址、大小等属性的方法
public:
/* 返回 readable 空间大小 */
size_t readableBytes() const
{ return writerIndex_ - readerIndex_; }
/* 返回 writeable 空间大小 */
size_t writableBytes() const
{ return buffer_.size() - writerIndex_; }
/* 返回 prependable 空间大小 */
size_t prependableBytes() const
{ return readerIndex_; }
/* readIndex 对应元素地址 */
const char* peek() const
{ return begin() + readerIndex_; }
/* 返回待写入数据的地址, 即writable空间首地址 */
char* beginWrite()
{ return begin() + writerIndex_; }
const char* beginWrite() const
{ return begin() + writerIndex_; }
/* 将writerIndex_往后移动len byte, 需要确保writable空间足够大 */
void hasWritten(size_t len)
{
assert(len <= writableBytes());
writerIndex_ += len;
}
/* 将writerIndex_往前移动len byte, 需要确保readable空间足够大 */
/*
* Cancel written bytes.
*/
void unwrite(size_t len)
{
assert(len <= readableBytes());
writerIndex_ -= len;
}
private:
/* 返回缓冲区的起始位置, 也是prependable空间起始位置 */
char* begin()
{ return &*buffer_.begin(); }
const char* begin() const
{ return &*buffer_.begin(); }
retrieve 取走数据
retrieve系列函数从readable空间取走数据,只关心移动readableIndex,改变readable空间大小,通常不关心读取数据具体内容,除非有指定具体的返回值,如retrieveAllAsString。
retrieve系列函数会改变readable空间大小,但通常不会改变writable空间大小,除非retrieveAll取完所有readable空间的数据,readable空间将会合并到writable空间。
/* 从readable头部取走最多长度为len byte的数据. 会导致readable空间变化, 可能导致writable空间变化.
* 这里取走只是移动readerIndex_, writerIndex_, 并不会直接读取或清除readable, writable空间数据 */
void retrieve(size_t len)
{
assert(len <= readableBytes());
if (len < readableBytes()) // readable 中数据充足时, 只取走len byte数据
{
readerIndex_ += len;
}
else
{ // readable中数据不足时, 取走所有数据
retrieveAll();
}
}
/* 从readable空间取走 [peek(), end)这段区间数据, peek()是readable空间首地址 */
void retrieveUntil(const char* end)
{
assert(peek() <= end);
assert(end <= beginWrite());
retrieve(end - peek());
}
/* 从readable空间取走一个int64_t数据, 长度8byte */
void retrieveInt64()
{
retrieve(sizeof(int64_t));
}
/* 从readable空间取走一个int32_t数据, 长度4byte */
void retrieveInt32()
{
retrieve(sizeof(int32_t));
}
/* 从readable空间取走一个int16_t数据, 长度2byte */
void retrieveInt16()
{
retrieve(sizeof(int16_t));
}
/* 从readable空间取走一个int8_t数据, 长度1byte */
void retrieveInt8()
{
retrieve(sizeof(int8_t));
}
/* 从readable空间取走所有数据, 直接移动readerIndex_, writerIndex_指示器即可 */
void retrieveAll()
{
readerIndex_ = kCheapPrepend;
writerIndex_ = kCheapPrepend;
}
/* 从readable空间取走所有数据, 转换为字符串返回 */
std::string retrieveAllAsString()
{
return retrieveAsString(readableBytes());
}
/* 从readable空间头部取走长度len byte的数据, 转换为字符串返回 */
std::string retrieveAsString(size_t len)
{
assert(len <= readableBytes());
string result(peek(), len);
retrieve(len);
return result;
}
peek 读取而不取走缓冲区数据
peek系列函数只从readable空间头部(peek())读取数据,而不取走数据,不会导致readable空间变化。
/* 从readable的头部peek()读取一个int64_t数据, 但不移动readerIndex_, 不会改变readable空间 */
int64_t peekInt64() const
{
assert(readableBytes() >= sizeof(int64_t));
int64_t be64 = 0;
::memcpy(&be64, peek(), sizeof(be64));
return sockets::networkToHost64(be64); // 网络字节序转换为本地字节序
}
/* 从readable的头部peek()读取一个int32_t数据, 但不移动readerIndex_, 不会改变readable空间 */
int32_t peekInt32() const
{
assert(readableBytes() >= sizeof(int32_t));
int32_t be32 = 0;
::memcpy(&be32, peek(), sizeof(be32));
return sockets::networkToHost32(be32); // 网络字节序转换为本地字节序
}
/* 从readable的头部peek()读取一个int16_t数据, 但不移动readerIndex_, 不会改变readable空间 */
int16_t peekInt16() const
{
assert(readableBytes() >= sizeof(int16_t));
int16_t be16 = 0;
::memcpy(&be16, peek(), sizeof(be16));
return sockets::networkToHost16(be16); // 网络字节序转换为本地字节序
}
/* 从readable的头部peek()读取一个int8_t数据, 但不移动readerIndex_, 不会改变readable空间.
* 1byte数据不存在字节序问题 */
int8_t peekInt8() const
{
assert(readableBytes() >= sizeof(int8_t));
int8_t x = *peek();
return x;
}
readInt 取数据
readInt系列函数从readable空间读取指定长度(类型)的数据,不仅从readable空间读取数据,还会利用相应的retrieve函数把数据从中取走,导致readable空间变小。 相当于retrieve和peek函数复合使用。
/* 从readable空间头部读取一个int64_类型数, 由网络字节序转换为本地字节序 */
int64_t readInt64()
{
int64_t result = peekInt64();
retrieveInt64();
return result;
}
/* 从readable空间头部读取一个int32_类型数, 由网络字节序转换为本地字节序 */
int32_t readInt32()
{
int32_t result = peekInt32();
retrieveInt32();
return result;
}
/* 从readable空间头部读取一个int16_类型数, 由网络字节序转换为本地字节序 */
int16_t readInt16()
{
int16_t result = peekInt16();
retrieveInt16();
return result;
}
/* 从readable空间头部读取一个int8_类型数, 由网络字节序转换为本地字节序 */
int8_t readInt8()
{
int8_t result = peekInt8();
retrieveInt8();
return result;
}
prepend 预置数据到缓冲区
prepend系列函数将预置指定长度数据到prependable空间,但不会改变prependable空间大小。
/* 在prependable空间末尾预置int64_t类型网络字节序的数x, 预置数会被转化为本地字节序 */
/**
* Prepend int64_t using network endian
*/
void prependInt64(int64_t x)
{
int64_t be64 = sockets::hostToNetwork64(x);
prepend(&be64, sizeof(be64));
}
/* 在prependable空间末尾预置int32_t类型网络字节序的数x, 预置数会被转化为本地字节序 */
/**
* Prepend int32_t using network endian
*/
void prependInt32(int32_t x)
{
int64_t be32 = sockets::hostToNetwork32(x);
prepend(&be32, sizeof(be32));
}
/* 在prependable空间末尾预置int16_t类型网络字节序的数x, 预置数会被转化为本地字节序 */
void prependInt16(int16_t x)
{
int16_t be16 = sockets::hostToNetwork16(x);
prepend(&be16, sizeof(be16));
}
/* 在prependable空间末尾预置int8_t类型网络字节序的数x, 预置数会被转化为本地字节序 */
void prependInt8(int8_t x)
{
prepend(&x, sizeof(x));
}
/* 在prependable空间末尾预置一组二进制数据data[len].
* 表面上看是加入prependable空间末尾, 实际上是加入readable开头, 会导致readerIndex_变化 */
void prepend(const void* data, size_t len)
{
assert(len <= prependableBytes());
readerIndex_ -= len;
const char* d = static_cast<const char*>(data);
std::copy(d, d+len, begin()+readerIndex_);
}
内部缓冲区操作
包含3个操作:
- shrink自动收缩内部缓冲区(buffer_)大小
- 返回buffer_的capaticy
- makeSpace生产足够大小的writable空间,以写入新的len byte数据
/* 收缩缓冲区空间, 将缓冲区中数据拷贝到新缓冲区, 确保writable空间最终大小为reserve */
void shrink(size_t reserve)
{
Buffer other;
other.ensureWritableBytes(readableBytes() + reserve);
other.append(toStringPiece());
swap(other);
}
/* 返回buffer_的容量capacity() */
size_t internalCapacity() const
{
return buffer_.capacity();
}
/* writable空间不足以写入len byte数据时,
如果writable空间 + prependable空间不足以存放数据, 就resize 申请新的更大的内部缓冲区buffer_
如果足以存放数据, 就将prependable多余空间腾挪出来, 合并到writable空间 */
void makeSpace(size_t len)
{
if (writableBytes() + prependableBytes() < len + kCheapPrepend)
{ // writable 空间大小 + prependable空间大小 不足以存放len byte数据, resize内部缓冲区大小
// FIXME: move readable data
buffer_.resize(writerIndex_ + len);
}
else
{
// writable 空间大小 + prependable空间大小 足以存放len byte数据, 移动readable空间数据, 合并多余prependable空间到writable空间
assert(kCheapPrepend < readerIndex_);
size_t readable = readableBytes();
std::copy(begin() + readerIndex_,
begin() + writerIndex_,
begin() + kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}
readFd从指定fd读取数据
readFd从指定连接对应fd读取数据,当读取的数据超过内部缓冲区writable空间大小时,采用的策略是先用一个64K栈缓存extrabuf临时存储,然后根据需要合并prependable空间到writable空间,或者resize buffer_大小。
/**
* 从fd读取数据到内部缓冲区, 将系统调用错误保存至savedErrno
* @param 要读取的fd, 通常是代表连接的conn fd
* @param savedErrno[out] 保存的错误号
* @return 读取数据结果. < 0, 发生错误; >= 成功, 读取到的字节数
*/
ssize_t Buffer::readFd(int fd, int* savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read.
char extrabuf[65536]; // 65536 = 64K bytes
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin() + writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof(extrabuf);
const int iovcnt = (writable < sizeof(extrabuf)) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0)
{ // ::readv系统调用错误
*savedErrno = errno;
}
else if (implicit_cast<size_t>(n) <= writable)
{
writerIndex_ += n;
}
else
{// 读取的数据超过现有内部buffer_的writable空间大小时, 启用备用的extrabuf 64KB空间, 并将这些数据添加到内部buffer_的末尾
// 过程可能会合并多余prependable空间或resize buffer_大小, 以腾出足够writable空间存放数据
// n >= 0 and n > writable
// => buffer_ is full, then append extrabuf to buffer_
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
return n;
}
readable空间特定字符串查找
有时,用户需要先对readable空间中的字符进行专门的查找,如找CRLF,EOL,而不取走数据,根据查找结果再决定取走多少数据。muduo库提供了几个辅助函数,便于用户进行这样的读取操作。
/* 在readable空间找CRLF位置, 返回第一个出现CRLF的位置 */
// CR = '\r', LF = '\n'
const char* findCRLF() const
{
// FIXME: replace with memmem()?
const char* crlf = std::search(peek(), beginWrite(), kCRLF, kCRLF+2);
return crlf == beginWrite() ? NULL : crlf;
}
/* 在start~writable首地址 之间找CRLF, 要求start在readable地址空间中 */
// CR = '\r', LF = '\n'
const char* findCRLF(const char* start) const
{
assert(peek() <= start);
assert(start <= beginWrite());
// FIXME: replace with memmem()?
const char* crlf = std::search(start, beginWrite(), kCRLF, kCRLF+2);
return crlf == beginWrite() ? NULL : crlf;
}
/* 在readable空间中找EOL, 即LF('\n') */
// EOL = '\n'
// find end of line ('\n') from range [peek(), end)
const char* findEOL() const
{
const void* eol = memchr(peek(), '\n', readableBytes());
return static_cast<const char*>(eol);
}
/* 在start~writable首地址 之间找EOL, 要求start在readable地址空间中 */
// EOL = '\n
// find end of line ('\n') from range [start(), end)
// @require peek() < start
const char* findEOL(const char* start) const
{
assert(peek() <= start);
assert(start <= beginWrite());
const void* eol = memchr(start, '\n', beginWrite() - start);
return static_cast<const char*>(eol);
}