Python数据分析模块
- 前言
- 一、Numpy模块
- Numpy介绍
- Numpy的使用
- Numpy生成数组
- ndarray
- array生成数组
- arange生成数组
- random生成数组
- 其他
- 示例
- 关于randint
- 示例1
- 示例2
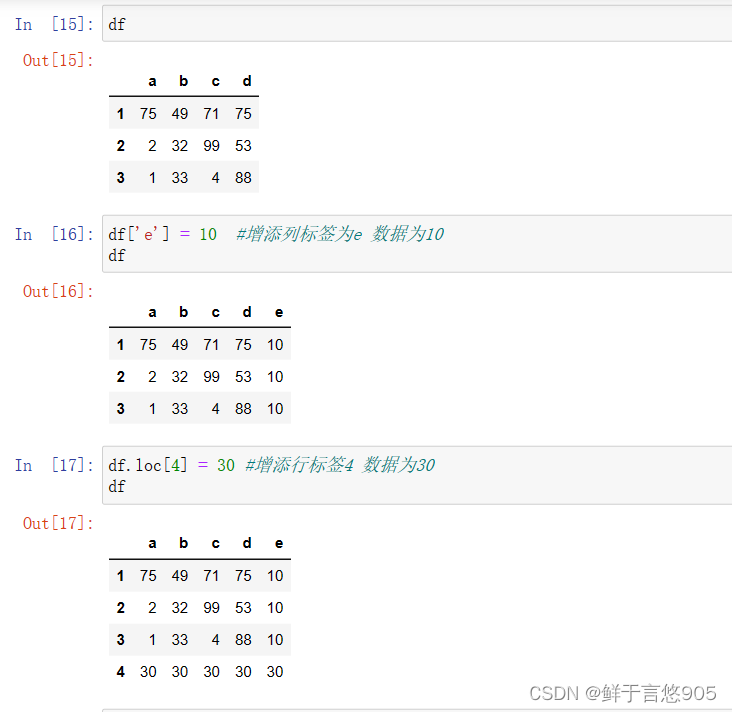
- 关于rand
- Numpy数组统计方法
- 示例
- 二、Pandas模块
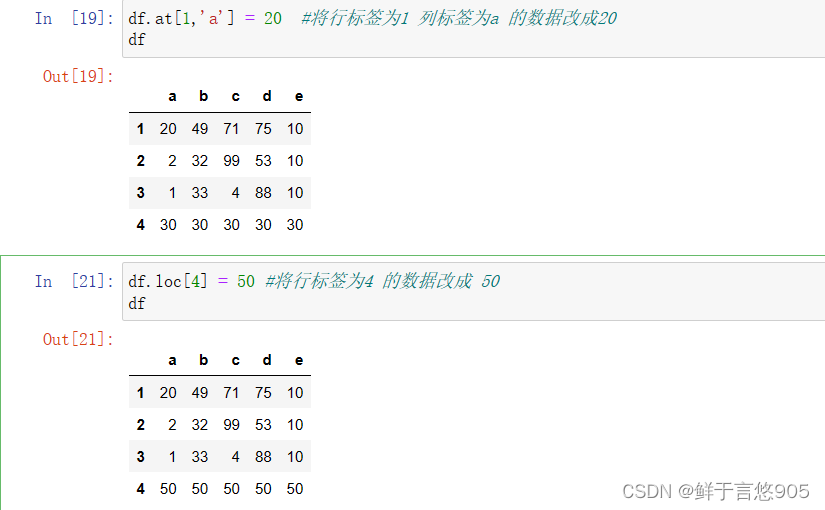
- pandas介绍
- Series
- 示例
- DataFrame
- 示例
- 三、其他模块
- Matplotlib/Seaborn模块
- Scipy模块
- Stasmodels模块
- Scikit-Learn模块
前言
在当今数字化时代,数据分析已经变得不可或缺。而Python,作为一种通用编程语言,其丰富的库和强大的功能使得它成为数据分析领域的佼佼者。Python数据分析模块,正是这一领域的核心组成部分,为数据科学家和工程师提供了强大的武器库。
Python数据分析模块的核心库主要包括NumPy、Pandas和Matplotlib。NumPy是Python中用于科学计算的基础包,提供了高性能的多维数组对象及工具。Pandas则是一个开源的、提供高性能、易于使用的数据结构和数据分析工具的Python库。它提供了数据清洗、数据转换、数据处理等一系列功能,使数据分析变得更加简单高效。而Matplotlib则是Python中最常用的绘图库,它可以帮助我们可视化数据,从而更直观地理解数据。
除了这些核心库,Python数据分析模块还包括许多其他有用的工具和库,如Seaborn、SciPy、StatsModels等。Seaborn是基于Matplotlib的数据可视化库,提供了更高级的绘图功能和更美观的图表样式。SciPy则是一个用于数学、科学和工程的库,提供了许多常用的算法和函数。StatsModels则是一个统计建模和经济学分析的Python库,可以帮助我们建立统计模型、进行假设检验等。
Python数据分析模块的应用范围非常广泛,可以用于商业分析、金融风控、医疗研究、社交媒体分析等多个领域。例如,在商业分析中,我们可以使用Python数据分析模块来分析销售数据、用户行为数据等,从而制定更有效的市场策略。在金融风控中,我们可以利用这些工具来识别风险点、预测市场走势等。在医疗研究中,Python数据分析模块可以帮助我们分析病人的医疗数据、基因数据等,从而推动医学的进步。
总之,Python数据分析模块凭借其强大的功能和广泛的应用场景,已经成为数据分析领域的重要组成部分。无论是数据科学家、工程师还是其他领域的专业人士,都可以通过学习和掌握Python数据分析模块来提高工作效率、提升数据分析能力。随着大数据时代的到来,Python数据分析模块的应用前景将更加广阔。
一、Numpy模块
Numpy的官方文档
NumPy documentation
Numpy的中文文档
NumPy 参考手册
Numpy介绍
Numpy模块是python语言的一个扩展程序库,支持大量的多维数组与矩阵计算,此外也针对数组运算提供大量的数学函数库。Numpy功能非常强大,支持广播功能函数,线性代数运算,傅里叶变换等功能。
在使用Numpy时,可以直接使用import来导入。
Numpy在导入的时候可以重命名 一般都是重命名成np
Numpy的使用
Numpy生成数组
ndarray
一个ndarray是Python中NumPy库中的一个数据结构,用于存储和操作具有相同数据类型的多维数组。它类似于常规的Python列表,但对于数值计算更高效。
一个ndarray可以有任意数量的维度,从0维(标量)到n维。每个维度被称为一个轴。例如,一个1维数组类似于一个列表,一个2维数组类似于一个矩阵,一个3维数组类似于一个立方体。
ndarray高效的原因是它将数据存储在一块连续的内存块中,并提供了针对整个数组或特定轴执行操作的优化函数。它还支持矢量化操作,可以应用于整个数组,而不需要显式循环。
array生成数组
Numpy最重要的一个特点是其N维数组对象ndarray。 ndarray与列表形式上相似,但是ndarray要求数组内部的元素必须是相同的类型。在生成ndarray时,采用Numpy的array方法。

arange生成数组
numpy.arange()函数用于生成一个具有指定范围和步长的数组。它的用法如下:
numpy.arange(start, stop, step, dtype=None)
参数说明:
start:起始值(包含在数组中)stop:终止值(不包含在数组中)step:步长,即相邻元素之间的差值,默认为1dtype:可选参数,生成的数组的数据类型,默认为None,即根据输入来推断
返回值:
- 返回一个由指定范围和步长生成的一维数组
下面是一些使用numpy.arange()函数的示例:
import numpy as np
# 生成一个从0到9的一维数组
arr1 = np.arange(10)
print(arr1)
# 生成一个从5到15的一维数组,步长为2
arr2 = np.arange(5, 15, 2)
print(arr2)
# 生成一个从0到1的一维数组,步长为0.1
arr3 = np.arange(0, 1, 0.1)
print(arr3)
输出:
[0 1 2 3 4 5 6 7 8 9]
[ 5 7 9 11 13]
[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
注意,numpy.arange()函数生成的数组不包含终止值,即生成的数组中最后一个元素不会超过或等于终止值。如果希望包含终止值,可以通过调整步长或使用numpy.linspace()函数来实现。
random生成数组
使用NumPy的random模块可以生成各种类型的随机数组,如整数数组、浮点数数组、多维数组等。下面是一些常用的随机数组生成函数:
numpy.random.random(size=None):生成一个[0, 1)范围内的浮点数数组,大小为size。如果不指定size参数,则生成一个随机数。
import numpy as np
# 生成大小为3的一维浮点数数组
arr = np.random.random(3)
print(arr)
输出结果可能为:
[0.13436424 0.84743374 0.76377462]
numpy.random.randint(low, high=None, size=None, dtype='l'):生成一个指定范围内的整数数组,大小为size。low和high参数指定元素的下界和上界。如果不指定high参数,则默认生成[0, low)范围内的整数。
import numpy as np
# 生成大小为5的一维整数数组,元素范围为[0, 9]
arr = np.random.randint(10, size=5)
print(arr)
输出结果可能为:[3 9 0 1 1]
numpy.random.randn(d0, d1, ..., dn):生成一个指定维度的标准正态分布(均值为0,标准差为1)的随机数组。
import numpy as np
# 生成大小为2x3的二维标准正态分布随机数组
arr = np.random.randn(2,3)
print(arr)
输出结果可能为:
[[-0.34551899 1.27697197 -0.05959316]
[ 0.05156384 -0.87225026 -0.40863768]]
这只是一些常用的生成随机数组的函数。NumPy的random模块还提供了很多其他函数,如生成随机排列、采样、生成随机矩阵等。你可以根据需要查阅NumPy的官方文档以了解更多函数和用法。

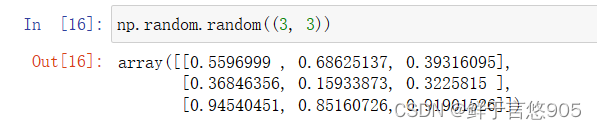
给参数传一个元组,即size=(3, 3)
np.random.random((3, 3))
返回值:是一个二维数组




其他
在numpy模块中,除了arrange方法生成数组外,还可以使用
np.zeros((m,n))方法生成m行,n列的0值数组;- 使用
np.ones((m, n))方法生成m行,n列的填充值为1的数组; - 使用
np. eyes (m, n)方法生成m行,n列的对角线位置填充为1的矩阵;
示例
使用Numpy库可以很方便地生成数组。下面是一些示例:
- 生成一个一维数组(向量):
import numpy as np
vec = np.array([1, 2, 3, 4, 5])
print(vec)
输出:
[1 2 3 4 5]
- 生成一个二维数组(矩阵):
import numpy as np
mat = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(mat)
输出:
[[1 2 3]
[4 5 6]
[7 8 9]]
- 生成一个全0或全1的数组:
import numpy as np
zeros = np.zeros((3, 3))
ones = np.ones((2, 4))
print(zeros)
print(ones)
输出:
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]]
- 生成一个指定范围和步长的数组:
import numpy as np
arr = np.arange(0, 10, 2)
print(arr)
输出:
[0 2 4 6 8]
- 生成一个随机数数组:
import numpy as np
rand_arr = np.random.rand(3, 3)
print(rand_arr)
输出:
[[0.71462283 0.16802111 0.74319442]
[0.52730748 0.24050333 0.78031217]
[0.73996269 0.71121482 0.79648372]]
这些只是使用Numpy库生成数组的一些基本方法,还有很多其他的功能和参数可以用来生成更加复杂的数组。详细的用法可以参考Numpy官方文档。
关于randint
numpy.randint函数是用于生成随机整数的函数,它可以生成指定范围内的随机整数,包括上下界。
函数签名如下:
numpy.random.randint(low, high=None, size=None, dtype='l')
参数解释:
low:生成的随机整数的下界(包含)。如果high参数没有被指定,则生成的随机整数的范围是[0, low)。high:生成的随机整数的上界(不包含)。如果指定了high参数,则生成的随机整数的范围是[low, high)。size:输出结果的维度大小。可以是整数,元组或None。如果是整数,则生成的随机整数是一维的;如果是元组,则生成的随机整数是多维的。dtype:输出结果的数据类型。默认为'l',即整数类型。
示例1
import numpy as np
# 生成一个1维数组,包含10个范围在[0, 10)的随机整数
arr = np.random.randint(10, size=10)
print(arr)
# 生成一个2维数组,包含3行4列的随机整数,整数的范围在[5, 10)
arr_2d = np.random.randint(5, 10, size=(3, 4))
print(arr_2d)
输出结果:
[4 5 9 0 3 2 9 6 3 4]
[[8 7 6 6]
[5 9 8 9]
[6 9 6 7]]
以上示例演示了如何使用numpy.randint函数生成随机整数。
示例2
np.random.randint(10)
返回值:仅仅得到一个整数,且得到的整数总是小于10

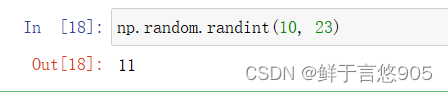
对前两个参数赋值,注意第二个参数要大于第一个参数的值
np.random.randint(10, 23)
返回值:仅仅得到一个整数,得到的整数总是在10和23之间
np.random.randint(10, 22, (3, 2))
返回值:返回的数据是在10到22之间,是3*2的元组,是元组还是列表,由最后一位参数是元组还是列表决定

关于rand
在Python的NumPy库中,rand函数用于生成指定形状的随机数数组,这些随机数是从[0, 1)的均匀分布中随机抽取得到的。
rand函数的语法如下:
numpy.random.rand(d0, d1, ..., dn)
参数说明:
d0, d1, ..., dn:生成随机数数组的维度。可以是一个整数,也可以是一个整数元组。
返回值:
- 一个具有指定形状的随机数数组。
示例用法:
import numpy as np
# 生成一个形状为(3, 3)的随机数数组
print(np.random.rand(3, 3))
输出:
[[0.18764594 0.61552877 0.50692378]
[0.10907858 0.56652417 0.27661652]
[0.01325816 0.64253746 0.12330385]]
注意:rand函数只能生成从[0, 1)的均匀分布中抽取的随机数。如果想生成其他分布的随机数,可以使用NumPy中的其他随机函数,比如randn(生成标准正态分布的随机数数组)、randint(生成指定范围内的随机整数数组)等。
np.random.rand(2)

np.random.rand(2, 3)


Numpy数组统计方法
Numpy库提供了一些常用的数组统计方法,可以对数组进行统计计算。下面是一些常用的Numpy数组统计方法的例子:
sum(): 计算数组所有元素的总和。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
total_sum = np.sum(arr)
print(total_sum) # 输出:15
mean():计算数组所有元素的平均值。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
avg = np.mean(arr)
print(avg) # 输出:3.0
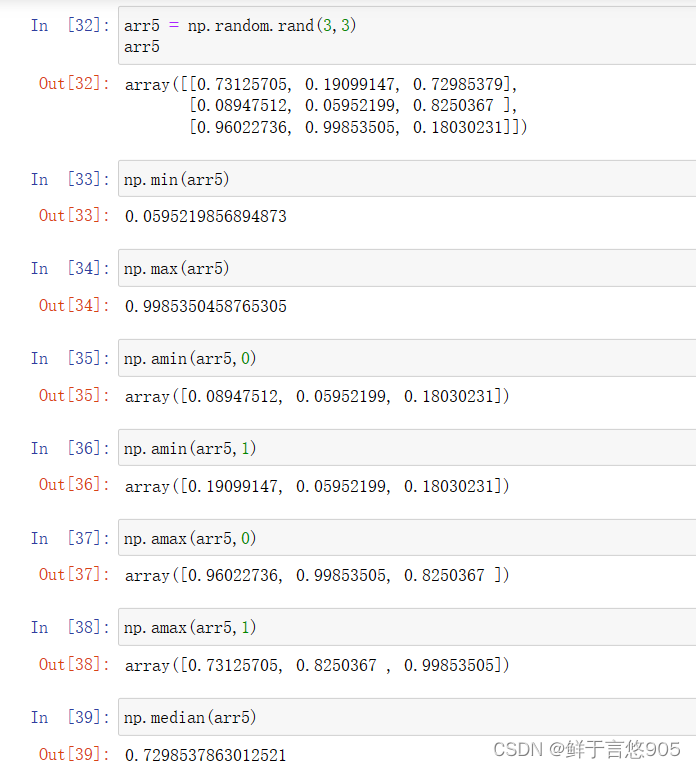
min(): 返回数组中最小的元素。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
min_val = np.min(arr)
print(min_val) # 输出:1
max(): 返回数组中最大的元素。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
max_val = np.max(arr)
print(max_val) # 输出:5
median(): 计算数组中元素的中位数。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
med = np.median(arr)
print(med) # 输出:3.0
std(): 计算数组中元素的标准差。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
std_dev = np.std(arr)
print(std_dev) # 输出:1.4142135623730951
var(): 计算数组中元素的方差。
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
variance = np.var(arr)
print(variance) # 输出:2.0
这些只是Numpy库中一些常用的数组统计方法的例子,还有其他一些方法可以用于对数组进行统计计算。你可以查看Numpy的官方文档以了解更多信息。
示例


二、Pandas模块
pandas介绍
Pandas是一个开源的Python库,主要用于数据分析和数据处理。它提供了高性能、易用且灵活的数据结构,使得数据分析任务更加简单和高效。
Pandas是基于Numpy构建的数据分析库,但它比Numpy有更高级的数据结构和分析工具,如Series类型、DataFrame类型等。将数据源重组为DataFrame数据结构后,可以利用Pandas提供的多种分析方法和工具完成数据处理和分析任务。
Pandas的主要数据结构有两种:Series和DataFrame。
-
Series:Series是一维的标记数组,类似于一维数组或者一列数据。它由一组数据和与之相关的标签(索引)构成。可以通过索引对数据进行选择和过滤。创建
Series对象:import pandas as pd data = [1, 2, 3, 4, 5] series = pd.Series(data) -
DataFrame:DataFrame是二维的表格数据结构,类似于一个关系型数据库中的表格。它由一组有序的列组成,每个列可以是不同的数据类型(数值、字符串、布尔值等)。可以通过行和列的标签进行选择和过滤。创建
DataFrame对象:import pandas as pd data = {'Name': ['John', 'Mike', 'Sarah'], 'Age': [25, 30, 28], 'City': ['New York', 'London', 'Paris']} df = pd.DataFrame(data)
Pandas提供了丰富的数据分析工具和函数,用于对数据进行选择、过滤、排序、聚合、合并、重塑、透视等操作。
Series
Series是Pandas中的一种数据结构,类似于一维的数组或列表。它由两个部分组成:索引和数据值。索引是Series中数据的标签,它可以是整数、字符串或其他数据类型。数据值是存储在Series中的实际数据。
Series可以通过多种方式创建,包括从列表、数组、字典和标量值创建。下面是一些常见的Series操作和特性:
- 访问
Series的元素:可以使用索引来访问Series中的元素,类似于访问列表的方式。例如,series[0]将返回Series中第一个元素的值。 - 标签索引:可以使用标签索引来访问
Series中的元素,类似于字典的方式。例如,series['label']将返回具有该标签的元素的值。 - 切片操作:可以使用切片操作来选择
Series中的一个子集。例如,series[2:5]将返回Series中索引为2到4的元素。 - 运算符操作:可以对
Series进行各种数学运算,如加法、减法、乘法和除法。这些运算将分别应用于Series中的每个元素。 - 缺失值处理:可以使用
Pandas提供的函数来处理Series中的缺失值,如isnull、fillna和dropna。
总而言之,Pandas的Series是一种强大的数据结构,它提供了灵活的数据访问和处理方式,适用于各种数据分析和数据处理任务。
第一列是数据的索引,第二列是数据
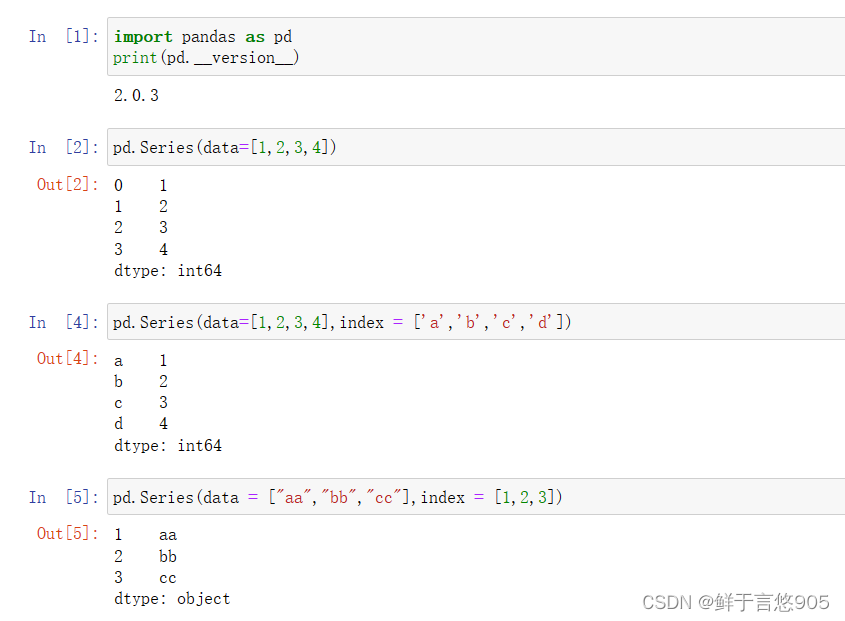
示例
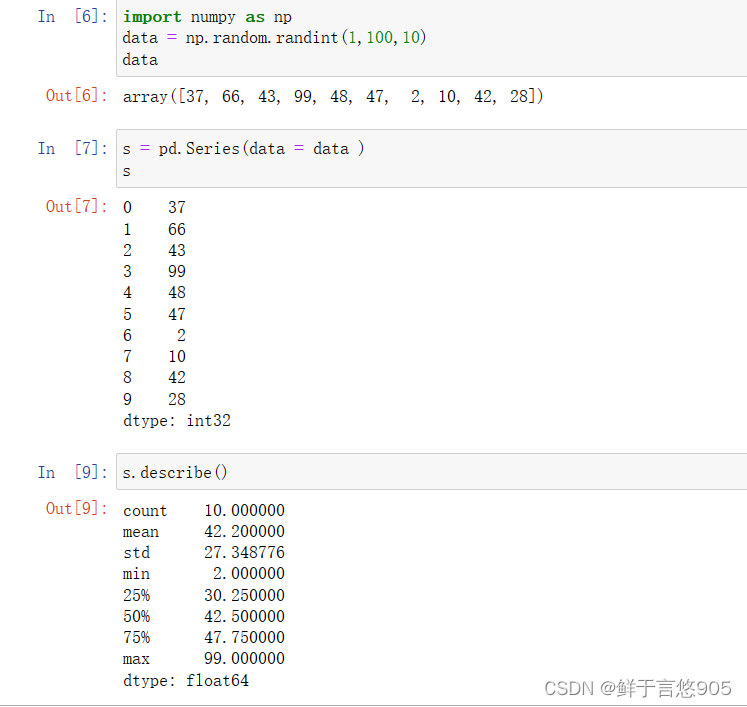
当Series数组元素为数值时,可以使用Series对象的describe方法对Series数组的数值进行分析
DataFrame
Pandas是一种开源的Python数据分析库,它提供了专门的数据结构和函数,使得数据操作更加简单和高效。其中最重要的数据结构之一是DataFrame。
DataFrame是一个二维的表格型数据结构,类似于Excel或SQL中的表。如果把Series看作Excel表中的一列,DataFrame就是Excel的一张工作表。DataFrame由多个Series组成,DataFrame可以类比为二维数组或者矩阵,但与之不同的是,DataFrame必须同时具有行索引和列索引,每列可以是不同的数据类型(整数、浮点数、字符串等)。
DataFrame可以被看作是Series对象的集合,每个Series都共享一个索引,而该索引根据行或列的名称来标识。
可以通过多种方式来创建DataFrame,包括读取外部数据源(如CSV、Excel、SQL数据库等)、从Python字典创建等。一旦创建了DataFrame,可以通过许多内置函数和方法来操作和分析数据。
DataFrame有许多常用的属性和方法,例如:
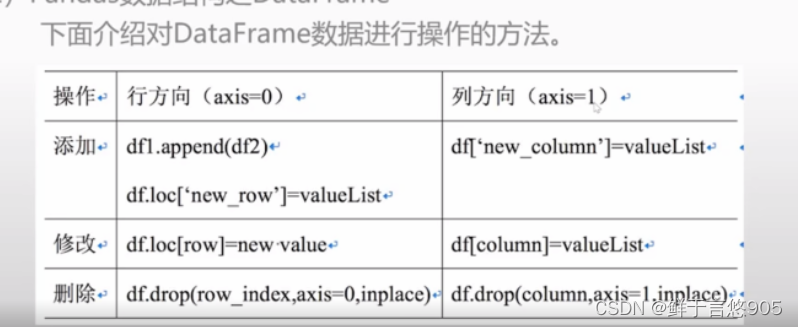
| 方法 | 功能描述 |
|---|---|
shape | 返回DataFrame的行数和列数 |
head(n)/ tail(n) | 返回数据前/后n行记录,当不给定n时,默认前/后5行 |
describe() | 返回所有数值列的统计信息,即返回DataFrame各列的统计摘要信息,如平均值、最大值、最小值等 |
max(axis=0) /min(axis = 0) | 默认列方向各列的最大/最小值,当axis的值设置为1时,获得各行的最大/最小值 |
mean(axis = 0) / median( axis = 0) | 默认获得列方向各列的平均/中位数,当axis的值设置为1时,获得各行的平均值/中位数 |
info() | 对所有数据进行简述,即返回DataFrame的信息,包括每列的数据类型和非空值的数量 |
isnull() | 检测空值,返回一个元素类型为布尔值的DataFrame,当出现空值时返回True,否则返回False |
dropna() | 删除数据集合中的空值 |
value_counts | 查看某列各值出现次数 |
count() | 对符合条件的统计次数 |
sort_values() | 对数据进行排序,默认升序 |
sort_index() | 对索引进行排序,默认升序 |
groupby() | 对符合条件的数据进行分组统计 |
sum() | 计算列的和 |
除了这些基本操作之外,Pandas还提供了丰富的功能,如数据过滤、合并、重塑、透视表、数据清洗和处理等,使得数据分析更加方便和灵活。
示例
创建DataFrame的语句如下:

index和columes参数可以指定,当不指定时,从0开始。通常情况下,列索引都会给定,这样每一列数据的属性可以由列索引描述。
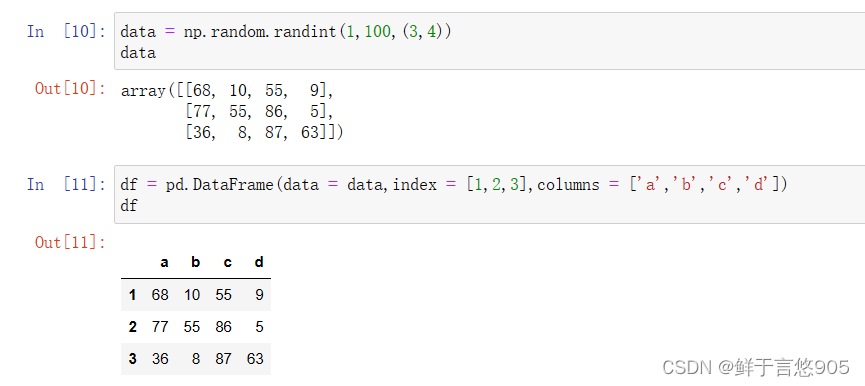
使用DataFrame类时可以调用其shape,info,index, column,values等方法返回其对应的属性。
调用DataFrame对象的info方法,可以获得其信息概述,包括行索引,列索引,非空数据个数和数据类型信息。
调用df对象的index、columns、values属性,可以返回当前df对象的行索引,列索引和数组元素。
因为DataFrame类存在索引,所以可以直接通过索引访问DataFrame里的数据。

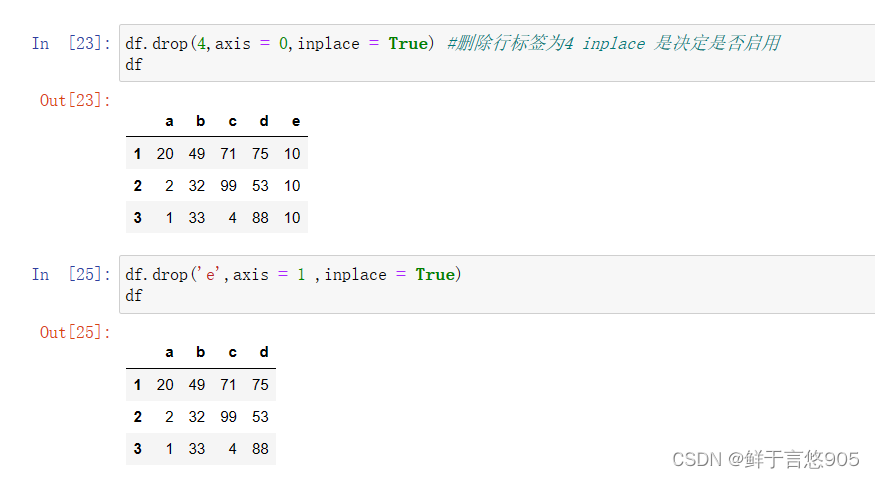
三、其他模块
Matplotlib/Seaborn模块
Matplotlib和Seaborn是Python中常用的数据可视化模块。
Matplotlib是一个绘图库,提供了各种绘图方法和工具,可以创建各种类型的图形,包括折线图、散点图、柱状图、饼图等。它可以在各种平台上运行,并且可以与NumPy、Pandas等数据分析库协同工作。Matplotlib提供了一套简洁的API,使得绘图过程变得简单和灵活。
Seaborn是基于Matplotlib的高级绘图库,提供了更高级别的绘图功能和更美观的图形风格。它针对统计分析中常见的图形进行了定制,使得绘制统计图形变得更加简单。Seaborn提供了一些内置的主题和调色板,使得图形的配色和样式更加吸引人。
使用Matplotlib和Seaborn可以进行多种类型的数据可视化,包括单变量和多变量的统计图形、时间序列图、分布图等。通过调整各种参数和选项,可以定制化图形的样式和布局,使得最终的图形能够更好地展示数据的特征和关系。
总的来说,Matplotlib和Seaborn是Python中优秀的数据可视化工具,可以帮助用户更直观地理解和分析数据,同时也提供了丰富的定制化选项和样式,使得生成美观而又有信息价值的图形变得更加容易。
Scipy模块
Scipy是一个开源的Python科学计算库,建立在NumPy之上。它提供了许多高效的和专业的数值算法和工具,用于科学和工程应用。
Scipy模块可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解决问题。目前,Scipy广泛地被数据科学、人工智能、数学、机械制造和生物工程等领域的人员应用。
Scipy模块包含了许多子模块,用于不同领域的科学计算任务,下面介绍一些常用的子模块:
-
scipy.constants:提供了常见的物理和数学常数,例如pi和e。 -
scipy.integrate:提供了数值积分的功能,可以用于求解常微分方程、积分、优化等问题。 -
scipy.optimize:提供了优化算法,可以用于最小化或最大化目标函数。 -
scipy.interpolate:提供了插值函数的功能,用于通过已知数据点的值来估计未知点的值。 -
scipy.linalg:提供了线性代数的功能,包括矩阵分解、特征值求解、线性方程组求解等。 -
scipy.signal:提供了信号处理的功能,包括滤波、谱分析、波形生成等。 -
scipy.sparse:提供了稀疏矩阵的功能,可以高效地处理大规模稀疏矩阵的计算问题。 -
scipy.spatial:提供了空间数据结构和算法的功能,包括距离计算、最近邻搜索等。 -
scipy.stats:提供了统计分析的功能,包括概率分布、假设检验、回归分析等。 -
scipy.signal:提供了信号处理的功能,包括滤波、谱分析、波形生成等。
这些只是Scipy模块中的一部分功能,它还包含了其他许多有用的子模块和函数,可以满足不同领域的科学计算需求。
Stasmodels模块
Statsmodels是一个Python库,用于拟合统计模型、进行统计测试和数据探索等任务。它提供了许多用于统计分析的功能,包括回归分析、时间序列分析、假设检验、非参数方法和描述性统计。
常用的模型包括线性模型、广义线性模型和鲁棒线性模型、线性混合效应模型、方差分析(ANOVA)方法、时间序列过程和状态空间模型、广义的矩量法等。每个估算器都有一个广泛的结果统计列表。对照现有的统计数据包对结果进行测试,以确保它们是正确的。官方网址为www.statsmodels.org。 目前,统计人员倾向安装包含大量统计功能和方法的程序库Stasmodels。
Statsmodels包含多个子模块,每个子模块都提供了特定类型的统计工具和模型。以下是一些子模块的介绍:
-
Statsmodels.api:这个子模块提供了主要的统计模型类和函数。你可以使用该模块中的方法进行回归分析、方差分析、协方差分析和非线性模型拟合等。它还提供了描述性统计和统计测试方法。 -
Statsmodels.formula.api:这个子模块基于公式语法,允许用户使用类似于R语言的模型描述。你可以使用它来构建和拟合各种统计模型,包括线性回归、广义线性模型和时间序列模型等。 -
Statsmodels.graphics:这个子模块用于可视化统计模型和结果。它提供了各种绘图函数,可以用于绘制回归诊断图、残差图、密度图等。 -
Statsmodels.tsa:这个子模块用于时间序列分析。它提供了许多方法和模型,用于处理时间序列数据,包括自回归模型、移动平均模型、ARIMA模型等。 -
Statsmodels.nonparametric:这个子模块用于非参数统计方法。它包括用于核密度估计、核回归、非参数假设检验等的函数和类。
总的来说,Statsmodels是一个非常强大的统计模型库,适用于各种统计问题和数据分析任务。它提供了丰富的功能和易于使用的接口,是Python中进行统计分析的重要工具。
Scikit-Learn模块
Scikit-learn (以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库。它提供了各种机器学习算法和工具,方便用户进行模型训练、评估和预测。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。 目前,计算机建模人员则倾向于使用包含各种人工智能方法的程序库Scikit-Learn。
以下是Scikit-Learn模块的一些重要特点和功能:
-
一致的
API:Scikit-Learn中的所有算法都有统一的API,包括fit()方法用于训练模型,predict()方法用于预测数据。这种一致的API设计使得用户可以轻松地在不同的算法之间切换。 -
丰富的算法库:
Scikit-Learn提供了包括分类、回归、聚类、降维等各种机器学习算法,涵盖了从传统的机器学习方法到最新的深度学习方法。 -
数据预处理工具:
Scikit-Learn提供了丰富的数据预处理工具,可以用来对原始数据进行特征提取、特征选择、缺失值填充、归一化等操作,以准备好用于机器学习的数据。 -
模型评估工具:
Scikit-Learn提供了多种评估指标和交叉验证方法,可以帮助用户评估训练好的模型的性能,并选择最佳的模型。 -
模型选择工具:
Scikit-Learn提供了模型选择的工具和算法,可以根据数据集的大小和复杂度自动选择适合的模型。 -
并行计算支持:
Scikit-Learn支持并行计算,可以利用多核处理器进行计算,加速模型训练和预测过程。 -
社区支持和文档丰富:
Scikit-Learn拥有庞大的用户社区和详细的文档,用户可以在社区中获取帮助,查找使用示例和教程。
总的来说,Scikit-Learn是Python中一个功能强大、易用的机器学习库,适用于各种机器学习任务,无论是初学者还是专业人士都可以使用它进行模型训练和预测。