文章目录
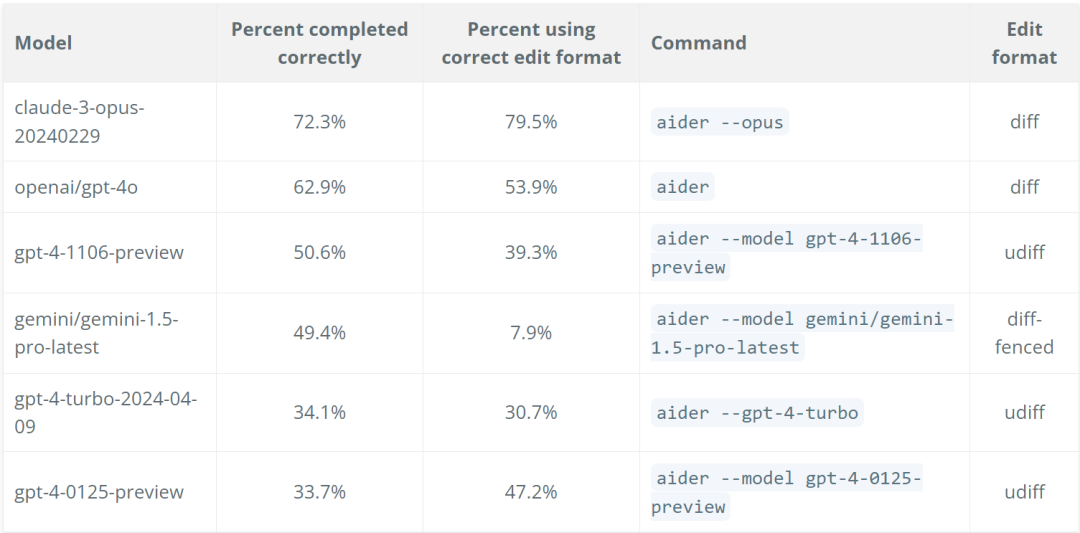
- 104. 二叉树的最大深度
- 解题思路
- c++ 实现
- 94. 二叉树的中序遍历
- 解题思路
- c++ 实现
- 101. 对称二叉树
- 解题思路
- c++ 实现
- 96. 不同的二叉搜索树
- 解题思路
- c++ 实现
- 102. 二叉树的层序遍历
- 解题思路
- c++ 实现
104. 二叉树的最大深度
题目: 给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例:
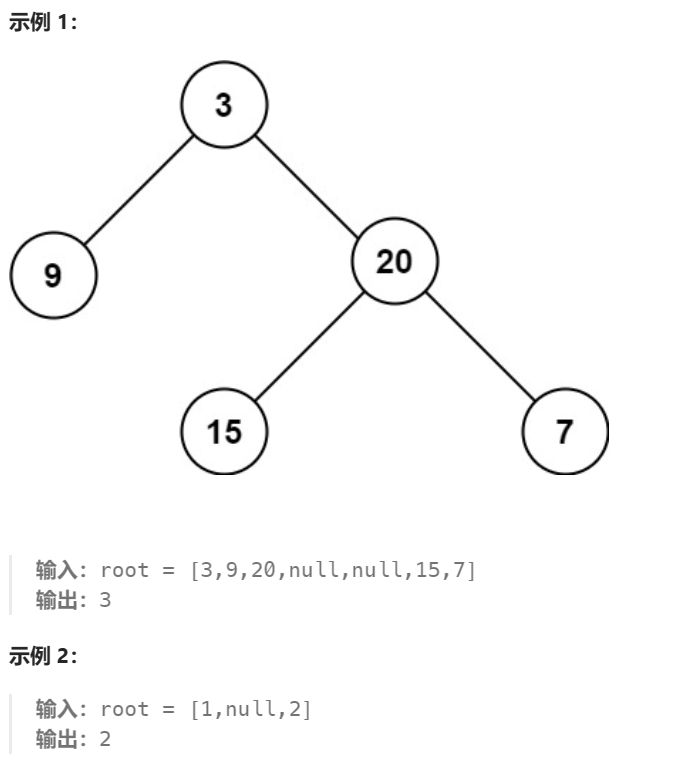
解题思路
- 没有左右子节点的节点,称为叶子节点
node->left ==nullptr && node->right ==nullptr`
- 叶子节点所在的层数,就是从跟节点到叶子节点的距离
- 统计遍历所有节点,找到叶子节点
- 如果当前节点不是叶子节点,则判断该节点左节点或右节点是否叶子节点
- 记录每个叶子节点,所在层数,找到最远距离的叶子节点
c++ 实现
class Solution {
public:
int ans =0;
void dfs(TreeNode* root, int level)
{
if (root ==nullptr) return;
if(root->left==nullptr && root->right==nullptr)
{
ans = max(ans,level);
}
dfs(root->left,level+1);
dfs(root->right,level+1);
}
int maxDepth(TreeNode* root) {
dfs(root,1);
return ans;
}
};
- 定义dfs函数,传入
节点以及所在的层level; 因为当前节点所在的层等于跟节点到该节点的距离,可以用level来表示距离 - 首先从跟节点root开始遍历,对应的level为1;
- 如果到达叶子节点,则更新最远距离ans
- 然后接着从
root->left开始,以及root->right开始寻找叶子节点,当前节点所在层为level+1 - 最终遍历完所有节点,找到最远距离ans
94. 二叉树的中序遍历
题目: 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例:
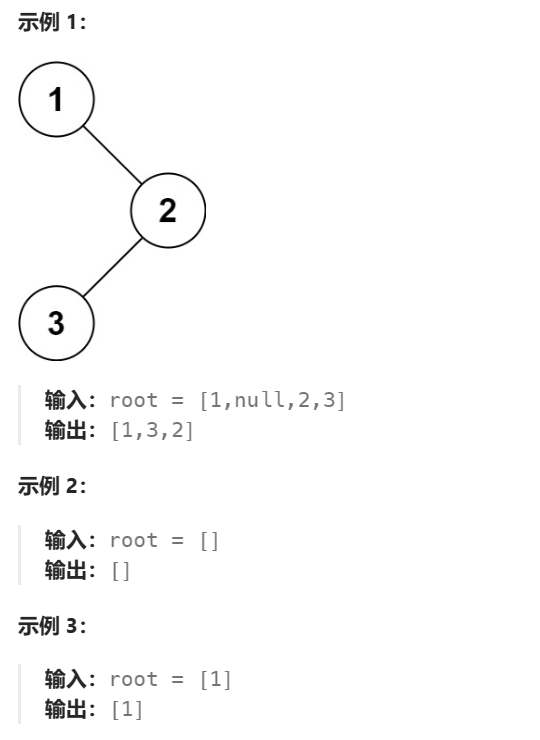
解题思路
- 中序遍历:
left -> root ->right(左中右) 递归遍历,首先考虑dfs
c++ 实现
class Solution {
public:
vector<int> ans;
void dfs(TreeNode* root)
{
if (root==nullptr) return;
dfs(root->left);
ans.push_back(root->val);
dfs(root->right);
}
vector<int> inorderTraversal(TreeNode* root) {
dfs(root);
return ans;
}
};
- 完整c++ 调试代码
#include <iostream>
#include <vector>
using namespace std;
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x):val(x),left(nullptr),right(nullptr) {};
};
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root)
{
vector<int> result;
inorder(root,result);
return result;
}
private:
void inorder(TreeNode* root, vector<int>& result)
{
if (root == nullptr) return;
inorder(root->left,result);
result.push_back(root->val);
inorder(root->right,result);
}
};
int main()
{
// 示例二叉树: 1 / \ 2 3
// 创建二叉树
TreeNode* root = new TreeNode(1);
root->left = new TreeNode(2);
root->right = new TreeNode(3);
// 使用中序遍历函数
Solution solution;
vector<int> inorderTraversalResult = solution.inorderTraversal(root);
// 打印结果
for (int val:inorderTraversalResult)
{
cout << val << " ";
}
// 清理内存
delete root->left;
delete root->right;
delete root;
return 0;
}
101. 对称二叉树
题目: 给你一个二叉树的根节点 root , 检查它是否轴对称。
示例:
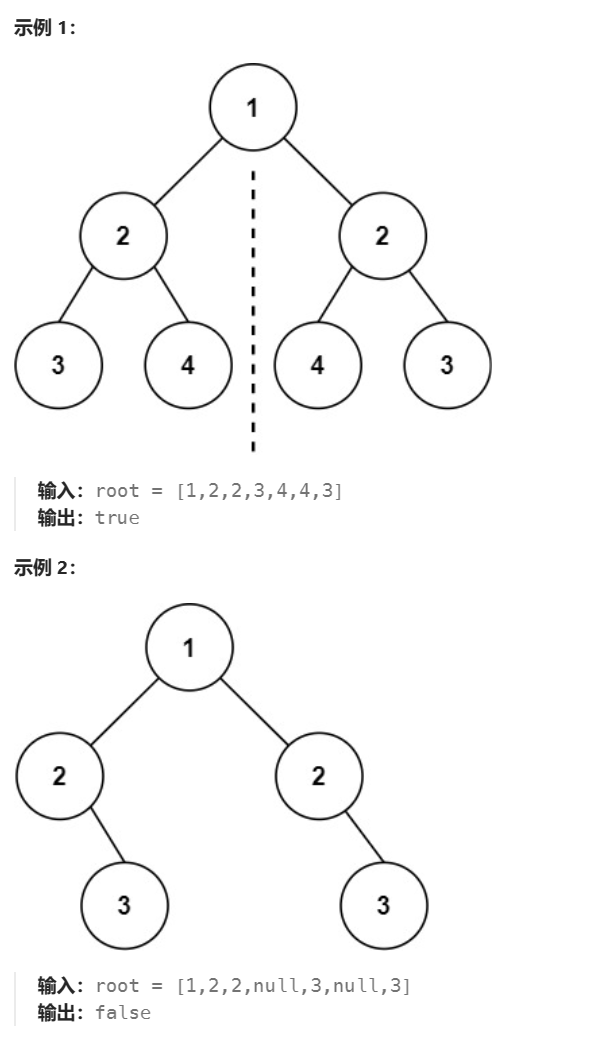
解题思路

观察对称二叉树,查找满足对称的条件,可以发现
- 对称树,它的子节左右对称,因此
子节点需相同(如图红色的2和2) - 同时,子节点的
孙子节点,左右两侧也要满足对称,即left_tree->left = right_tree->right; left_tree->right = right_tree->left; - 找到规律后,
递归遍历二叉树,判断二叉树是否对称。
参考:https://www.cnblogs.com/itdef/p/14400148.html
c++ 实现
class Solution {
public:
bool dfs(TreeNode* l,TreeNode* r)
{
//遍历到最后,都没有找到不相等的节点,那么就是对称的
if(l==nullptr && r==nullptr) return true;
if(l==nullptr && r !=nullptr) return false;
if(l!=nullptr && r==nullptr) return false;
if(l->val !=r->val) return false;
// if(l->val ==r->val) return true; // 如果加了这一句,则这棵树遍历到存在左右节点相同,就不继续向下遍历了,因此不要加
return dfs(l->left,r->right) && dfs(l->right,r->left);
}
bool isSymmetric(TreeNode* root) {
return dfs(root->left,root->right);
}
};
- 如果遍历过程中,
左右存在任意不相等的,则直接判断不是对称树 - 如果遍历到最后,都没有发现不相等。因为已经到树的最后,此时
l->left与r->right都为空,而且l->right和l->left也都是空, 根据if(l==nullptr && r==nullptr) return true;此时dfs(l->left,r->right) && dfs(l->right,r->left)返回true 注意不要加:if(l->val ==r->val) return true, 不然遍历不到树的最后,只要在中间节点存在满足这一要求的,就停止判断了,无法对整棵树进行判断。
96. 不同的二叉搜索树
题目: 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?``返回满足题意的二叉搜索树的种数。
示例:
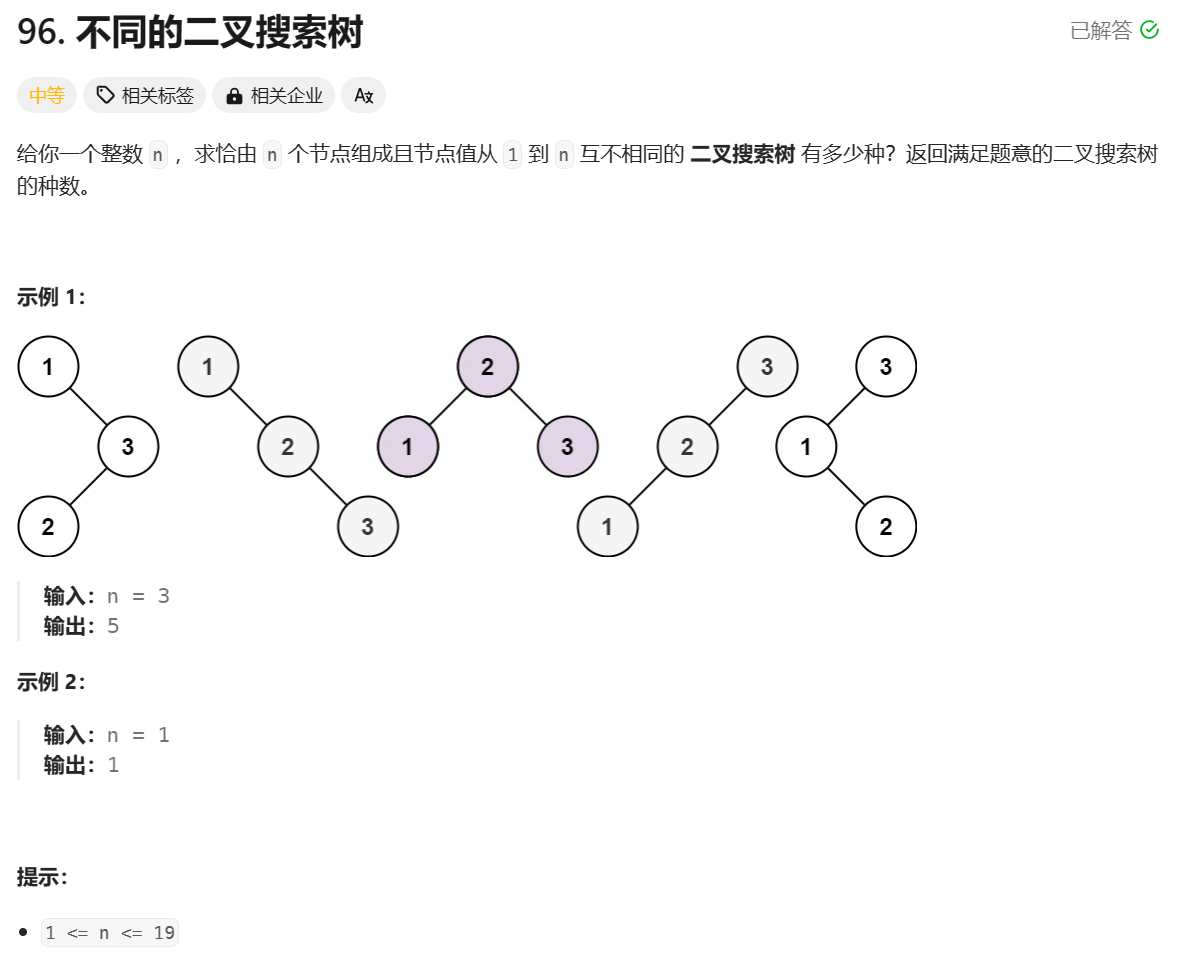
解题思路
二叉搜索树, 也称二叉排序树或二叉查找树。具有下列性质的二叉树:
- 若它的左子树不空,则
左子树上所有结点的值均小于它的根结点的值;- 若它的右子树不空,则
右子树上所有结点的值均大于它的根结点的值;- 它的左、右子树也分别为二叉排序树。
- 二叉搜索树作为一种经典的数据结构,它
既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;
- 使用
动态规划dp的方法求解, 设dp[n]记录n个连续节点(从 1 到 n 互不相同)组成的二叉搜索树的种类。 二叉搜索树,左子树上的所有节点均小于它的跟节点,右子树上的所有节点均大于它的跟节点。- 可知
dp[1]为1, 因为只有一个节点,排列的可能就只有一种;另外dp[0]也为1,因为也只有一种排列可能。dp[2]可组成两种不同的搜索二叉树,因此dp[2]=2

- 对于
3个节点,列出了所有的不同的搜索二叉树, 总共有5种。- 如果
1作为根节点,由于找不到比跟节点小的数作为左子树,因为左子树为空(dp[0]), 此时2,3两个节点在右子树上存在2种搜索二叉树的可能,也就是dp[2]:如果2在右子树上,那么3由于比2大,那么3只能是它的右子节点。如果3在右子树上,由于2比3小,2只能是它的左子节点); 此时种类数为:dp[0] * dp[2] = 2

- 如果
2作为跟节点, 因为1比跟节点2小,1只能是它的左节点,由于3比2大,3只能是根节点2的右节点, 因此只有1种可能:因此种类计算为dp[1]*dp[1] =1 - 如果
3作为跟节点,由于没有比它大的数,所以右子树为空,也就是dp[0],剩下的两个数字都在左子树上,对应为dp[2]: 如果1作为跟节点3的左节点,那么剩下的2只能是1的右节点(2比1大);如果2作为跟节点3的左子节点,那么剩下的1只能是2的左子节点(1比2小)。因此种类计算为dp[2]*dp[0] =2 - 所以对于3个节点来说,所有的二叉树为:
dp[0] * dp[2] + dp[1]*dp[1] + dp[2]*dp[0] =5
- 如果
因此得出如下规律:
- (1)
遍历每个数,作为根节点 - (2) 计算
该跟节点下,所有搜索二叉树的种类:左子树(种类)* 右字数(种类) - (3) 最后将
计算结果求和
c++ 实现
class Solution {
public:
int numTrees(int n) {
int dp[20];
memset(dp,0x0,sizeof(dp));
dp[0] =1;
dp[1] =1;
// 遍历p[i]
for(int i=2;i<=n;i++)
{ // i个节点,元素值 <=i; 遍历以每个节点作为跟节点
for (int j=1;j<=i;j++)
{
dp[i] += dp[j-1] * dp[i-j];
}
}
return dp[n];
}
};
- 首先初始化
dp[20], 并通过memset 置为0 ,因为n<=19, 初始化的大小足够了。 - 其中:dp[0] 和dp[1] 都为1
- 通过遍历
for(int i=2;i<=n;i++)来计算p[i]的值 - 对于
i个节点,元素值 <=i; 遍历以每个节点作为跟节点, 计算此时搜索二叉树的种类
dp[j-1] * dp[i-j]
- 因为左节点元素小于根节点,所以为
dp[j-1], 根据解题思路的总结,右节点对应为dp[i-j],因为j-1+i-j =i-1;
102. 二叉树的层序遍历
题目:给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例:
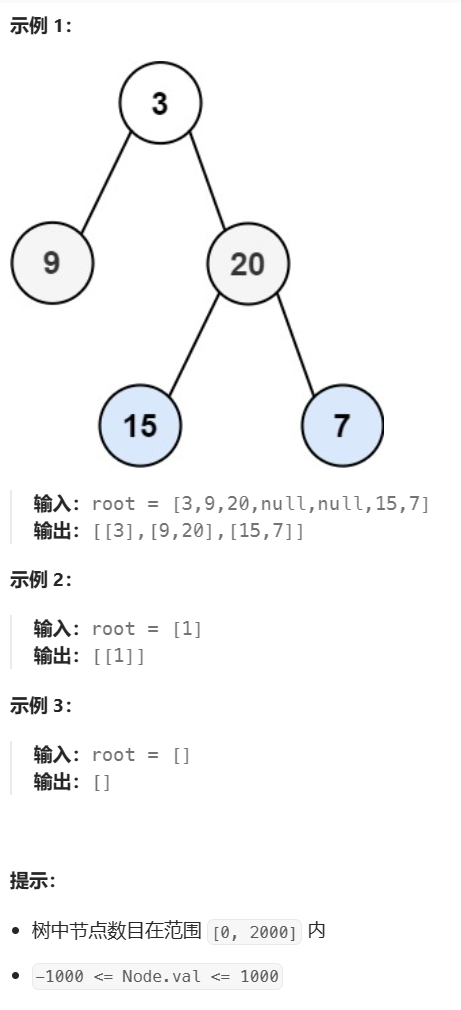
解题思路
BFS 广度优先搜索算法的介绍,看出博文: BFS和DFS优先搜索算法
BFS遍历二叉树 ,添加了遍历的树的层级level根据层级决定新开vector或者直接push

- 先将
跟节点root及层级0,加入到队列queue中,然后遍历队列。 - 首先
弹出根节点,并拿到节点值存储到ans中 - 将
根节点下一层子节点加入队列 - 然后继续弹出队列中的节点,如果节点
层级大于curr节点,增需要重新开一个vector,存储该节点的值,如果和当前层级是一样的,则直接push_back到vector中。 - 然后pop该节点,并将该节点的下一层子节点添加队
- 继续上述步骤,直到全部遍历完。。。。
c++ 实现
class Solution {
public:
vector<vector<int>> ans;
int curr =0; // current level
vector<int> v; // 单个level 保存的结果
void bfs(TreeNode* root)
{
if(root==nullptr) return;
//创建用来存储节点和level的queue
queue<pair<TreeNode*,int>> q;
// 放入第一个节点,同时记录节点的层级
q.push({root,0});
while(!q.empty())
{
// 循环弹出需要处理的节点
TreeNode* p=q.front().first;
int level = q.front().second;
// 记得从队列中pop掉
q.pop();
// 如果处理的节点层级比当前vector层级更大
// 那么说明上一层的节点数据已经处理完毕,需要重新开一个vector来记录新的层级节点
if(level>curr)
{
// 更新curr 层级
curr = level;
// 将已经处理完毕的层级数据vector, 添加到ans结果中
ans.push_back(v);
// 得到一个空的vector, 用于记录新的层级数据
v.clear();
v.push_back(p->val);
}
else
{
//如果处理节点的层级和当前curr层级一样,直接push_back即可
v.push_back(p->val);
}
// 将当前处理的节点的子节点,放入队列中,注意要加上子节点所在的层级
if (p->left !=nullptr) q.push({p->left,level+1});
if (p->right !=nullptr) q.push({p->right,level+1});
}
// 记得将最后一次的结果v,加入ans中
ans.push_back(v);
return;
}
vector<vector<int>> levelOrder(TreeNode* root) {
bfs(root);
return ans;
}
};
- 首先创建一个
队列queue来节点及所在level, 并插入根节点
//创建用来存储节点和level的queue
queue<pair<TreeNode*,int>> q;
// 放入第一个节点,同时记录节点的层级
q.push({root,0});
- 遍历队列,循环弹出需要处理的节点
// 循环弹出需要处理的节点
TreeNode* p=q.front().first;
int level = q.front().second;
// 记得从队列中pop掉
q.pop();
- 如果
处理的节点层级比当前vector层级更大,那么说明上一层的节点数据已经处理完毕,需要重新开一个vector来记录新的层级节点
if(level>curr)
{
// 更新curr 层级
curr = level;
// 将已经处理完毕的层级数据vector, 添加到ans结果中
ans.push_back(v);
// 得到一个空的vector, 用于记录新的层级数据
v.clear();
v.push_back(p->val);
}
- 如果处理节点的层级
和当前curr层级一样,直接push_back即可
else
{
//如果处理节点的层级和当前curr层级一样,直接push_back即可
v.push_back(p->val);
}
- 然后将pop掉的当前节点p的(下一层级)
子节点加入队列queue, 同时它的level+1
if (p->left !=nullptr) q.push({p->left,level+1});
if (p->right !=nullptr) q.push({p->right,level+1});
- 队列遍历完,
记得将最后一次结果v加入到ans中
// 记得将最后一次的结果,加入ans中
ans.push_back(v);





![[图解]SysML和EA建模住宅安全系统-04](https://img-blog.csdnimg.cn/direct/5f854a210e154ddabb49e6bd925b967e.png)