目录
- 前言
- 1、TextIn文档解析技术
- 1.1、文档解析技术
- 1.2、目前存在的问题
- 1.2.1、不规则的文档信息示例
- 1.3、合合信息的文档解析
- 1.3.1、合合信息的TextIn文档解析技术架构
- 1.3.2、版面分析关键技术 Layout-engine
- 1.3.3、文档树提取关键技术 Catalog-engine
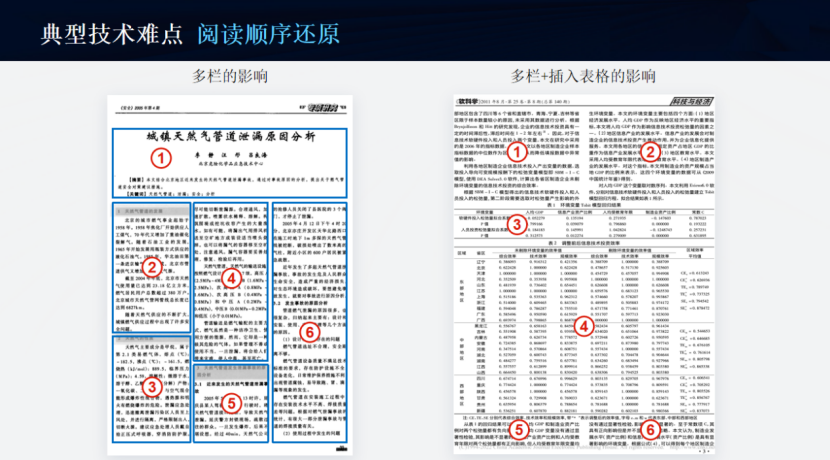
- 1.3.4、双栏
- 1.3.5、非对称双栏
- 1.3.6、双栏+表格
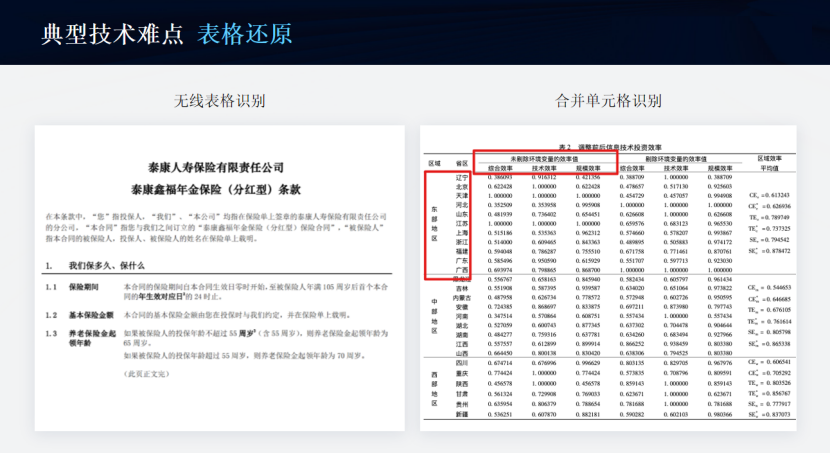
- 1.3.7、无线表格
- 1.3.8、合并单元格表格
- 1.3.9、层级目录
- 1.3.10、更高的文档问答精度
- 2、向量化技术
- 2.1、文本向量化模型
- 总结
前言

在人工智能时代,多模态大模型的发展不仅仅是技术创新的产物,它更是对人类交互和信息处理方式的一种模拟。我们的世界是多模态的:我们不仅阅读文字,还观察图像,聆听声音,感受触觉。多模态大模型试图通过模拟这种丰富的信息处理方式来增强机器的理解能力。
这些模型的核心优势在于它们的整合能力。传统的单模态系统在处理单一类型数据时可能表现出色,但它们无法捕捉跨模态的复杂关系。例如,一段视频内容不仅包含视觉元素,还可能包含重要的音频信息,甚至是文字信息(如字幕或场景中的文本)。多模态大模型能够综合这些信息,提供更为全面的分析和理解。
多模态大模型在文档处理平台的应用实现了对复杂文档内容的深层次理解和智能化处理。这些模型不仅能够执行基本的文字识别任务,还能结合上下文信息,识别和解释图表、图像中的数据和关系,甚至从视频中提取关键信息。例如,当处理一个包含图表和图像的报告时,多模态模型可以识别图表中的趋势,将其与文本中的描述相匹配,从而提供一个综合的内容概述。
1、TextIn文档解析技术
1.1、文档解析技术
文档解析技术,主要是指提取非结构化的文档内容中的关键信息,解析成结构化的数据。在多模态训练中,不仅能提取文字信息,也能对视频、音频、表格等信息进行处理,同时还能结合上下文,识别和解析文字、图片、音视频等数据中的信息和关系。
1.2、目前存在的问题
目前多模态大模型赛道上有众多著名公司在耕耘,普遍都存在一些问题。
- 速度慢,用户在Gpt里提交一个200页的文档,结果需要等3-5分钟,才能看到进度条走到底,这种体验犹如手机开机要等5分钟一样恐怖和难受。
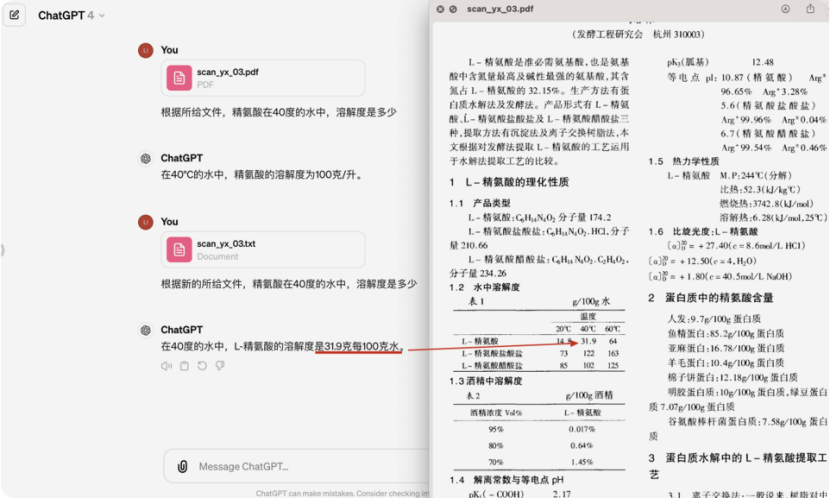
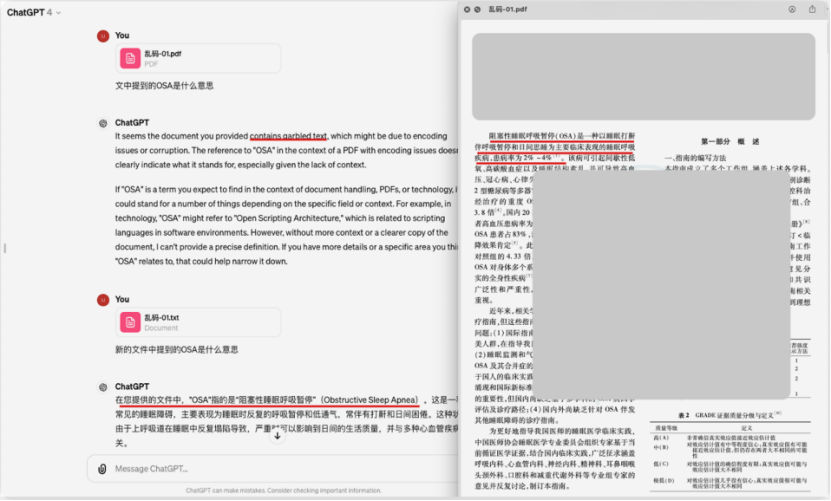
- 精度低,对于各种不规则表格、不规则排版版面、公式、图像里文字识别不佳,最终出来的结果,与预期的相差甚远。
- 兼容性差,对于繁杂的PDF编码格式识别不佳,出现乱码、丢字等情况。
1.2.1、不规则的文档信息示例
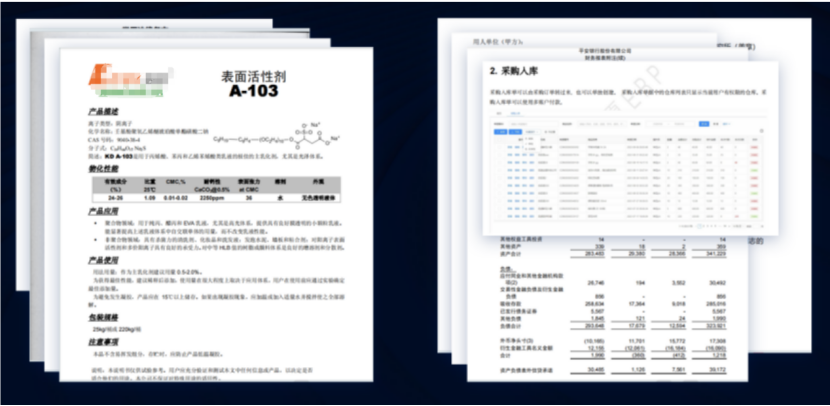


1.3、合合信息的文档解析
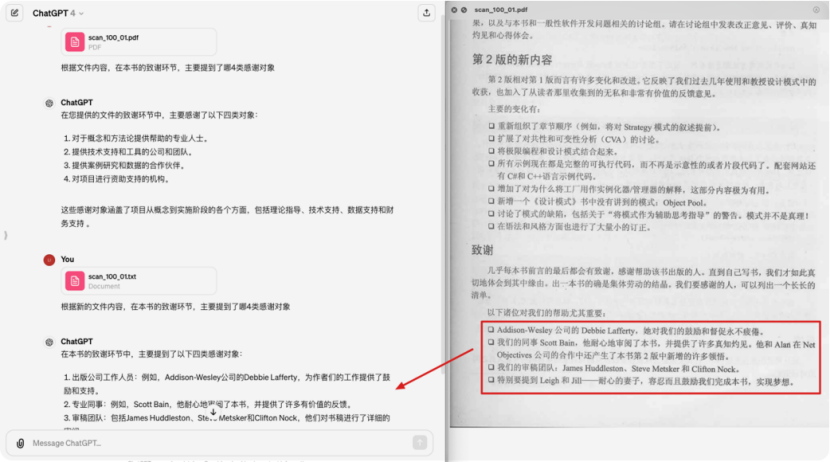
最近也使用了一些PDF解析工具,其中合合信息在PDF文档解析方面表现非常不错。合合信息在智能文字处理领域积累了十几年的经验,可以说是文档解析领域的先驱者和佼佼者。对比上述的一些问题,有了显著的提升。
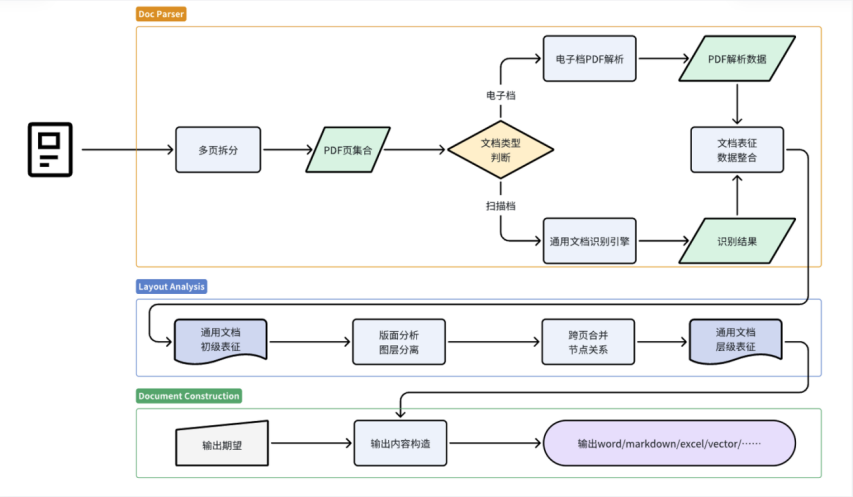
1.3.1、合合信息的TextIn文档解析技术架构
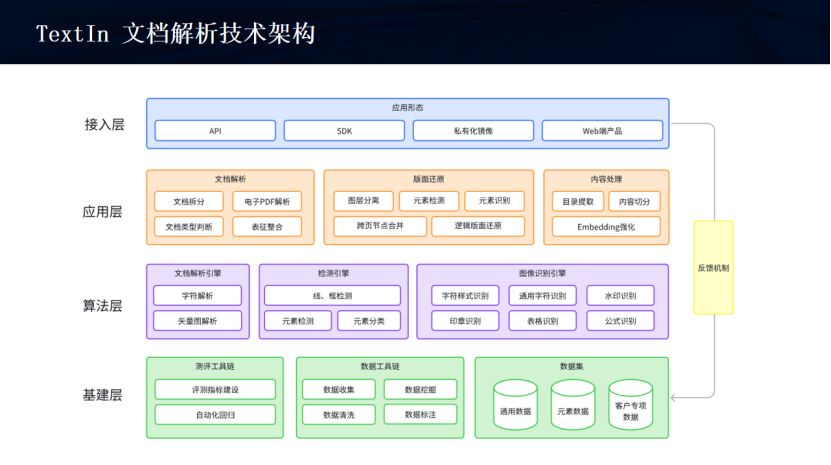
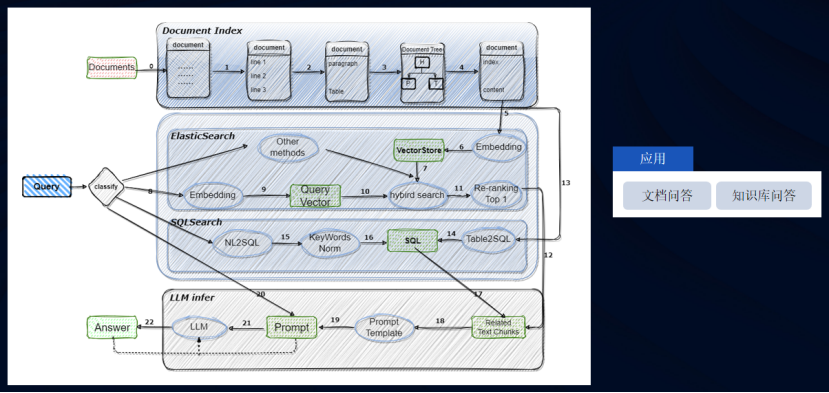
合合信息的TextIn文档解析技术架构非常清晰完整,总体分为四层:接入层、应用层、算法层、基建层。
接入层面向不同的受众,比如有技术在身的工程师通过API、SDK接入,提供HTTPS协议的API,也提供Java、go、nodejs等语言的SDK包。还有面向普通C端用户的Web端产品,用户可以在浏览器里使用合合信息的TextIn文档解析工具。
应用层可以归纳为文档解析、版面还原、内容处理三大类。
算法层可以归纳为文档解析引擎、检测引擎、图像识别引擎。
基建层是上面的基石,包括有测评工具链、数据工具链、数据集等。同时接入层也提供反馈机制,可以反馈修改意见给数据集。
下面让我们来看下合合信息的文档解析表现。
1.3.2、版面分析关键技术 Layout-engine
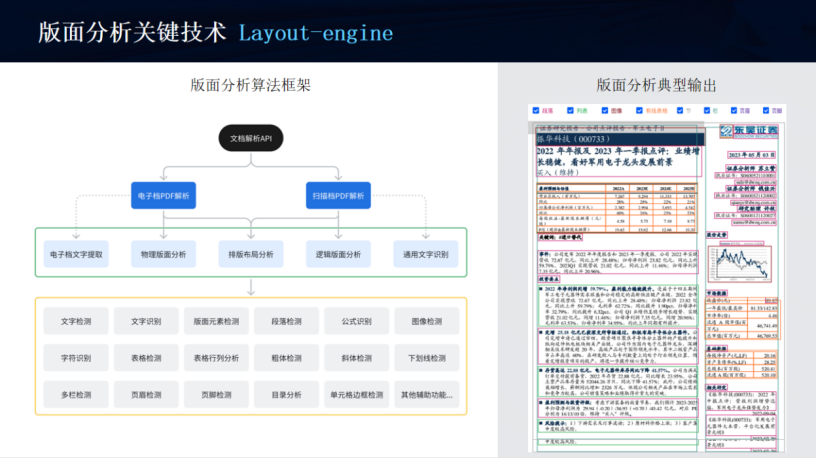
1.3.3、文档树提取关键技术 Catalog-engine

1.3.4、双栏
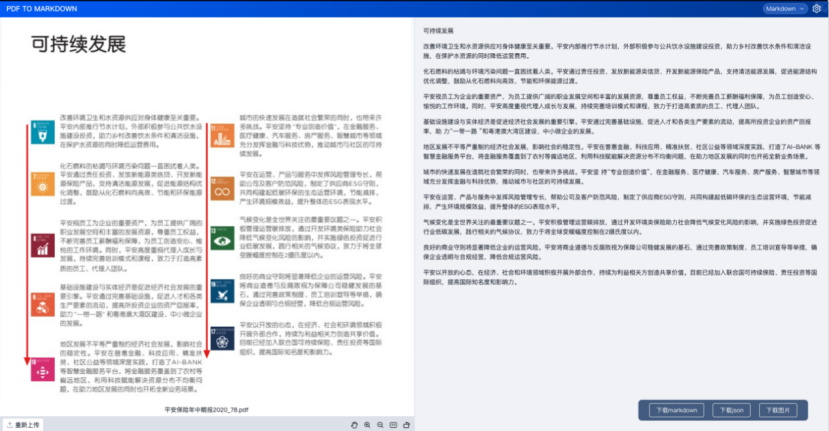
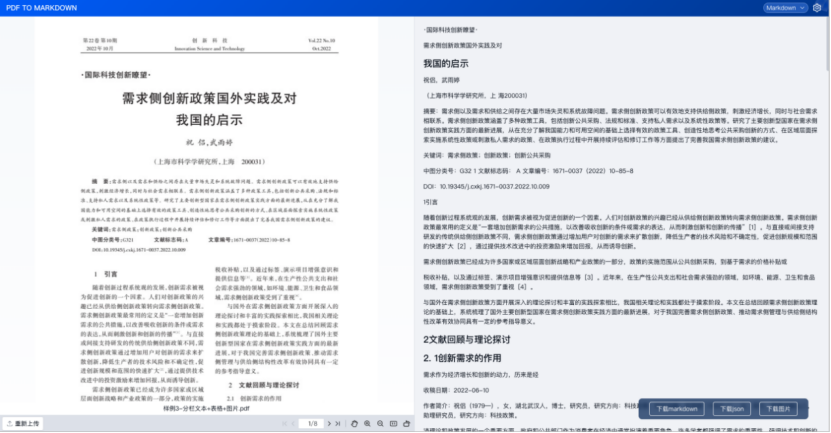
1.3.5、非对称双栏
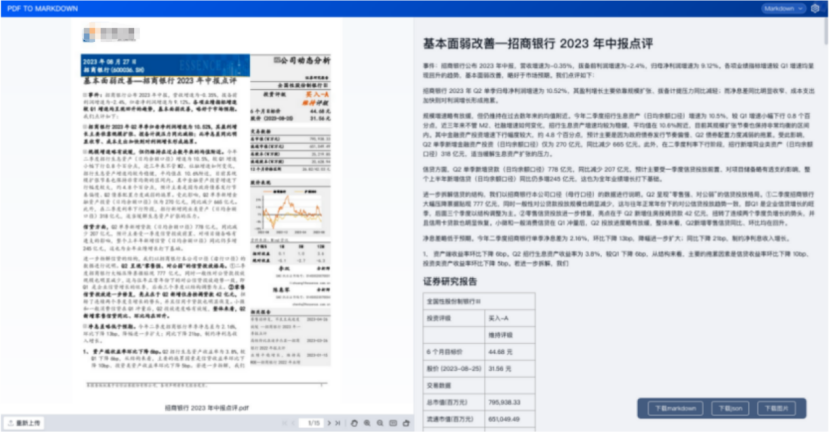
1.3.6、双栏+表格
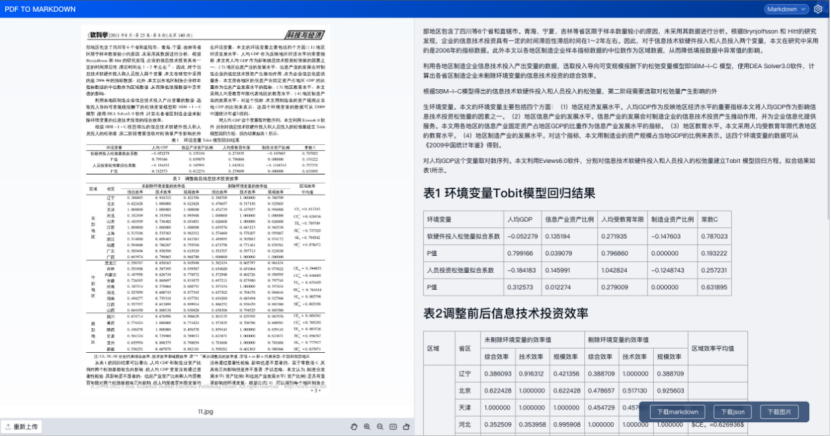
1.3.7、无线表格
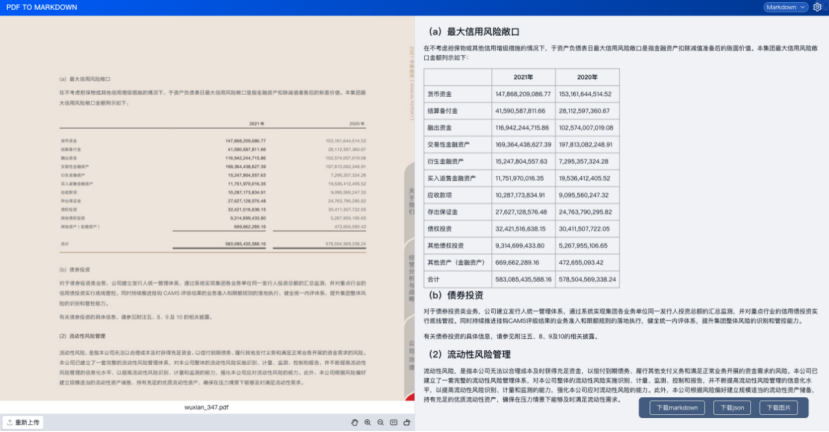
1.3.8、合并单元格表格
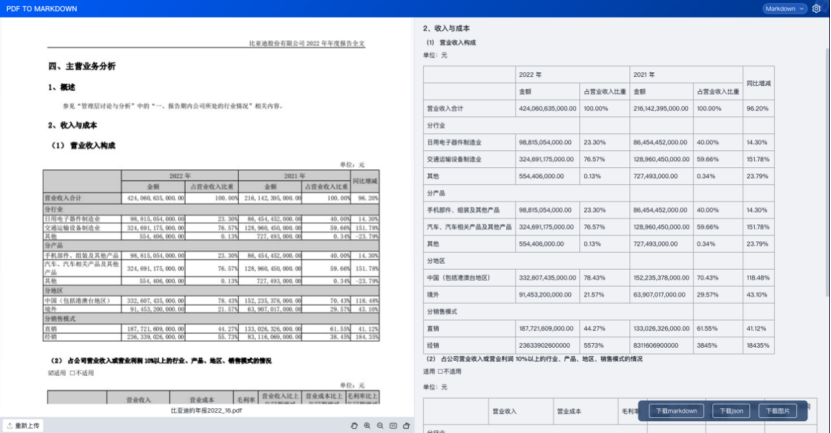
1.3.9、层级目录
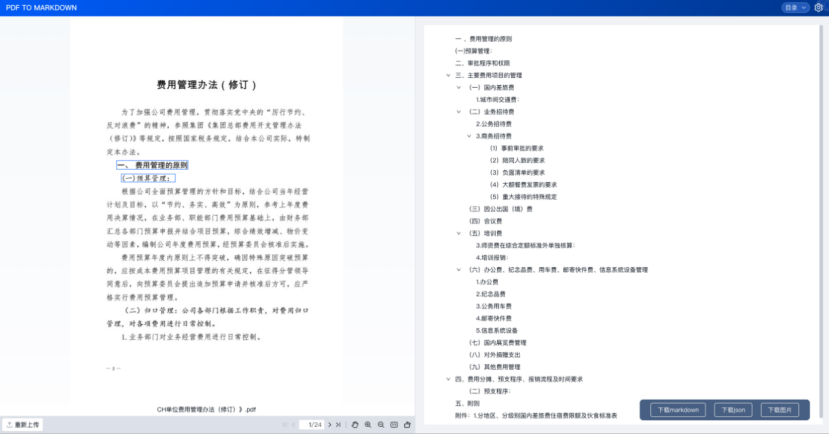
1.3.10、更高的文档问答精度
2、向量化技术
文本向量化是自然语言处理的基石,它涉及将文本数据转换为数值向量的过程,以便计算机能够处理。如词袋模型和TF-IDF、词嵌入技术如Word2Vec和GloVe、ELMo、BERT和GPT等模型,都能将文本数据转换为数值向量。
在大模型中,文本向量化变得更加复杂和强大。这些模型通常通过大规模预训练,学习丰富的语言表示,然后可以通过微调(fine-tuning)来适应特定的任务。尤其是基于Transformer的模型,它们通过自注意力机制处理文本,能够捕捉长距离的依赖关系,为文本提供动态的上下文相关表示。
2.1、文本向量化模型
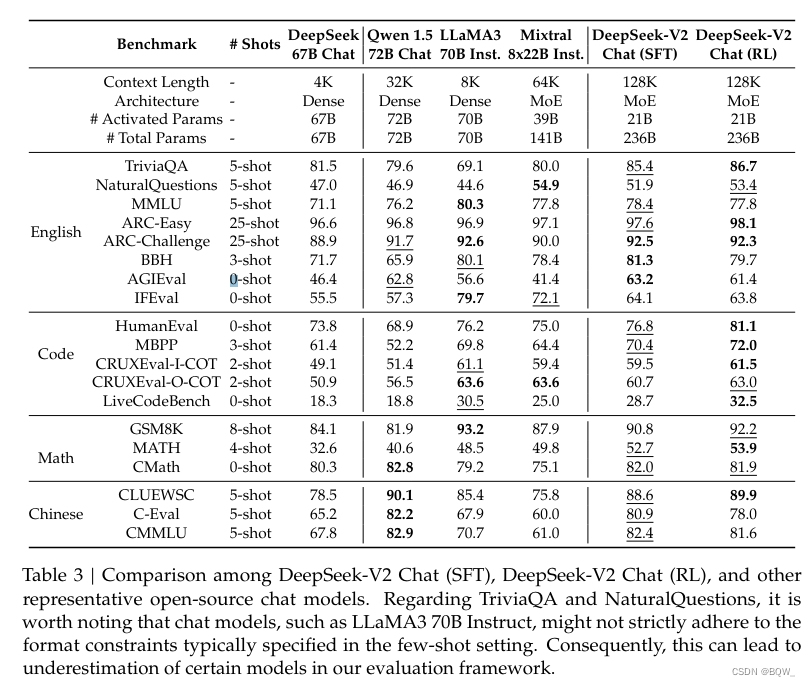
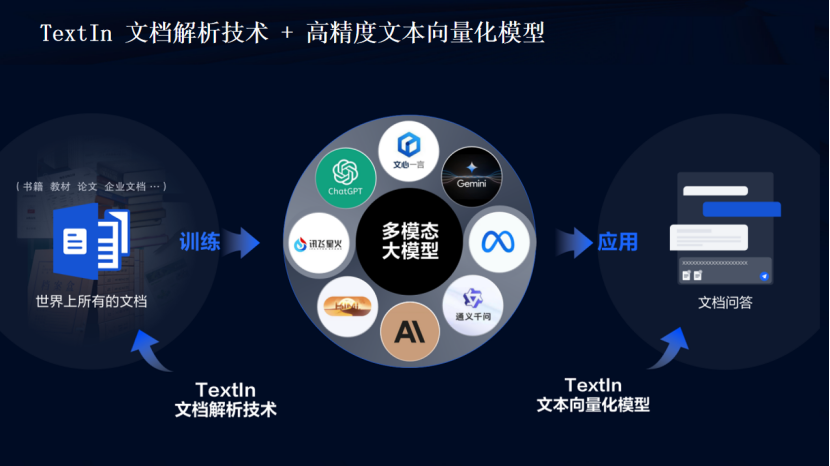
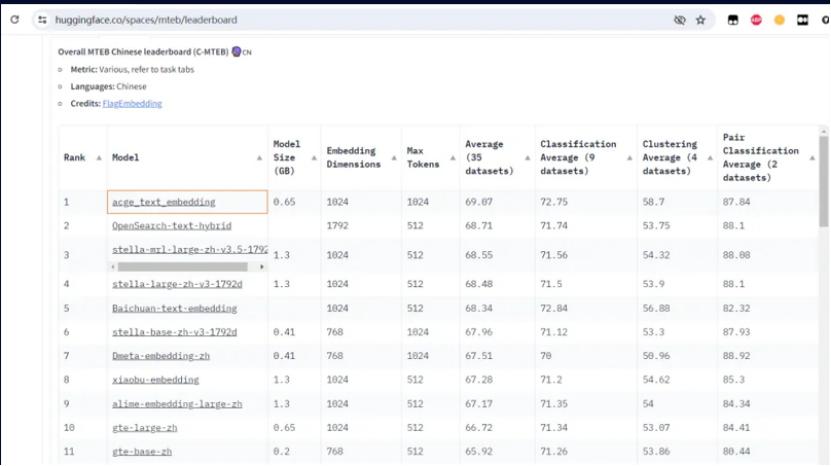
合合信息发布的文本向量化模型acge_text_embedding,简称“acge模型”,在MTEB中文榜单(C-MTEB)上取得第一的成绩,这一成就标志着在中文文本向量化领域的一个重要突破。MTEB(Multilingual Text Embedding Benchmark)是一个多语言文本嵌入基准测试,旨在评估不同模型在多项语言理解任务上的性能。ACGE模型在C-MTEB榜单上的优异表现,表明了它在理解中文语义和语用特征方面的强大能力。
总结
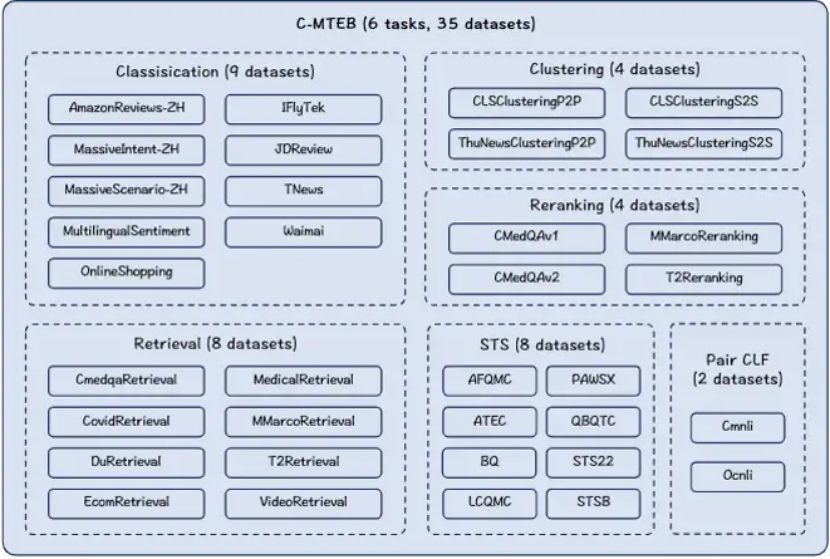
文档解析与向量化技术加速了多模态大模型训练与应用,在MTEB(C-MTEB)榜单上我们可以看到各种模型,在分类、聚类、检索、排序、文本相似度方面的表现都越来越优异。
这些技术的发展,尤其是acge模型在中文领域的优秀变现,使得合合信息在PDF文档解析方面得到了很好的结果。
- 速度快,合合信息的文档解析工具在解析一个几百页PDF文件的耗时通常都在秒级。对于C端用户而言,通常都是能够接受的。
- 【1.3】中我们对于各类版面元素都做了识别,效果还是很不错的。不管是公式、表格、还是相对复杂的排版,都能正确理解并准确还原。
- 兼容性好,我们在演示的各种繁杂文档时,都没有出现乱码、大量丢字等现象。
合合信息是一家深耕智能文字识别、商业大数据领域的老牌公司,他们有在C端深受全球用户喜爱的效率工具产品:扫描全能王、名片全能王、启信宝。在B端也有AI+大数据赋能数字化转型服务:TextIn智能文字识别产品、“启信慧眼”风控营销SaaS、“启信天元”大数据应用平台。
朋友们可以通过访问合合信息旗下的TextIn的官方网站来亲自体验一下哦。欢迎来探秘,更有惊喜【免费使用】等着你,https://www.textin.com/?from=qinghuasuo