1.文件读写



1.1 读取csv文件 —— read.csv()
- read.csv()部分参数的解释如下:
| 参数名称 | 作用 | 备注 |
| filepath_or_buffer | 要读取的文件路径或对象 | |
| sep | 字段分隔符,默认为逗号 | |
| delimiter | 字段分隔符 | 与 sep 功能相似 |
| header | 用作列名的行号,默认为0(第一行),如果没有列名则设为None | |
| names | 列名列表,用于结果DataFrame | names适用于没有表头的情况 |
| index_col | 用作索引的列编号或列名 | |
| usecols | 返回的列,可以是列名的列表或由列索引组成的列表 | |
| dtype | 字典或列表,指定某些列的数据类型 | |
| skiprows | 需要忽略的行数 | 从文件开头算起 |
| nrows | 需要读取的行数 | 从文件开头算起 |
| encoding | 文件编码 | 如’utf-8’等 |
# 1.导入panda库,然后命名为pd
import pandas as pd
# 2.读取csv文件,注意路径的问题
iris = pd.read_csv(r"C:/XXX/xxx/Documents/mycrawlers/数据分析与可视化/实验二——Pandas的基本使用方法/iris.csv")
# 3.读取iris文件的前5行数据
print(iris.head(5))
# 得到的结果为
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
0 1 5.1 3.5 1.4 0.2 setosa
1 2 4.9 3.0 1.4 0.2 setosa
2 3 4.7 3.2 1.3 0.2 setosa
3 4 4.6 3.1 1.5 0.2 setosa
4 5 5.0 3.6 1.4 0.2 setosa
# 4.读取iris文件的行
print(iris.columns)
# 得到的结果为
Index(['Unnamed: 0', 'Sepal.Length', 'Sepal.Width', 'Petal.Length',
'Petal.Width', 'Species'],dtype='object')
# 5.读取iris文件的索引值
print (iris.index)
# 得到的结果为
RangeIndex(start=0, stop=150, step=1)
# 6.查看iris文件的值的类型
print (type(iris.values))
# 得到的结果为
<class 'numpy.ndarray'>
1.1.1 head()方法
- 在head()方法中里面没有给定数字,默认的是前5行,可以通过输入具体的数字来调整读取文件的多少
# 1.利用head()方法读取iris文件的前100行数据(包括100行)
iris.head(100)
# 2.得到的结果为
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
0 1 5.1 3.5 1.4 0.2 setosa
1 2 4.9 3.0 1.4 0.2 setosa
2 3 4.7 3.2 1.3 0.2 setosa
3 4 4.6 3.1 1.5 0.2 setosa
4 5 5.0 3.6 1.4 0.2 setosa
... ... ... ... ... ... ...
95 96 5.7 3.0 4.2 1.2 versicolor
96 97 5.7 2.9 4.2 1.3 versicolor
97 98 6.2 2.9 4.3 1.3 versicolor
98 99 5.1 2.5 3.0 1.1 versicolor
99 100 5.7 2.8 4.1 1.3 versicolor
100 rows × 6 columns- 读取iris文件的Species列的前5行数据以及"Petal.Length","Species"两列全部数据
# 1.读取iris文件的Species列的前5行数据
iris.Species.head()
# 2.得到的结果为
0 setosa
1 setosa
2 setosa
3 setosa
4 setosa
Name: Species, dtype: object
# 3.读取iris文件的中Petal.Length、Species列的全部数据
iris[["Petal.Length","Species"]]
# 4.得到的结果为
Petal.Length Species
0 1.4 setosa
1 1.4 setosa
2 1.3 setosa
3 1.5 setosa
4 1.4 setosa
... ... ...
145 5.2 virginica
146 5.0 virginica
147 5.2 virginica
148 5.4 virginica
149 5.1 virginica
150 rows × 2 columns1.2 读取xlsx文件—— read.excel()
- pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
(1)io:要读取的Excel文件的路径(字符串)或者可迭代对象,例如文件对象、Excel表格URL、Excel文件中的表名等。
(2)sheet_name:要读取的Sheet的名称或索引(默认为0)
(3)header:指定列名所在的行数,默认为0,表示第一行
(4)names:自定义列名(列表形式),如果不指定,则默认使用Excel文件中的列名
(5)index_col:指定作为行索引的列,默认为None,表示不使用任何列作为索引
(6)usecols:指定要读取的列(列表形式),可以是列名或列索引
1.3 读取csv或txt文件——read_tabl()
-
read_table(filepath_or_buffer , sep='\t' , header='infer' ,names=None , index _col=None , usecols=None , dtype=None , converters=None , skiprows=None , skipfooter=None , nrows=None ,na_values=None , skip_blank_lines=True , parse_dates=False ,thousands= None , comment=None , encoding=None)
(1)filepath_or_buffer:文件路径、指定存储数据的URL或者文件型对象
(2)sep:指定原数据集中分割每行字段的分隔符,默认为tab制表符
(3)header:是否将原数据集中的第一行作为表头,默认是0,将第一行作为变量名称;如果原始数据中没有表头,该参数需要设置成None
(4)names:如果原数据集中没有列名,这个可以用来给数据添加列名。和header=None一起使用
(5)index _col:指定数据集中的某些列(字段)作为数据的行索引(标签)
(6)usecols:指定要读取哪些列(字段)的数据
(7)dtype:为数据集中的每列设置不同的数据类型
(8)converters:通过字典格式,为数据集中的某些列(字段)设置转换函数
# 1.使用read_table()方法读取文件
tips = pd.read_table(r"C:/Users/86135/Documents/mycrawlers/数据分析与可视化/实验二——Pandas的基本使用方法/tips1.csv",sep=",")
# 2.查看文件前5行数据
tips.head()
# 3.得到的结果为
total_bill,tip,sex,smoker,day,time,size
0 16.99,1.01,Female,No,Sun,Dinner,2
1 10.34,1.66,Male,No,Sun,Dinner,3
2 21.01,3.5,Male,No,Sun,Dinner,3
3 23.68,3.31,Male,No,Sun,Dinner,2
4 24.59,3.61,Female,No,Sun,Dinner,4# 1.导入panda库,然后命名为pd
import pandas as pd
# 2.导入文件注意这里的文件是xlsx类型的文件,不是csv文件
data = pd.read_excel(r"C:/XXX/xxx/Documents/mycrawlers/数据分析与可视化/实验二——Pandas的基本使用方法/tips.xlsx")
# 3.读取tips文件的前5行
data.head()
# 4.得到的结果为
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 41.4 pandas.get_dummies()——将分类变量转换为虚拟/指标变量
- get_dummies (数据, prefix = None , prefix_sep = '_' , dummy_na = False , columns = None , sparse = False , drop_first = False , dtype = None )
(1) data:数组、Series 或 DataFrame 获取输入的数据
(2)prefix(前缀):str、str 列表或 str 字典,默认无 附加 DataFrame 列名的字符串。在 DataFrame 上调用 get_dummies 时传递一个长度等于列数的列表。 或者,前缀 可以是将列名映射到前缀的字典
(3)prefix_sep:str,默认 '_' 如果附加前缀,则使用分隔符/定界符。或者通过prefix传递一个列表或字典
(4)dummy_na:布尔值,默认为 False 如果忽略 False NaN,则添加一列以指示 NaN
(5)columns :列表,默认无 要编码的 DataFrame 中的列名。 如果columns是 None 那么所有具有 object或category dtype 的列都将被转换
(6)sparse :布尔值,默认为 False 虚拟编码列应该由SparseArray(True) 还是常规 NumPy 数组 (False) 支持
(7)drop_first:布尔值,默认为 False 是否通过删除第一级从 k 个分类级别中取出 k-1 个虚拟变量
(8)dtype :默认 np.uint8 新列的数据类型。只允许使用一个 dtype
# 1.读取tips文件的前5行
data.head()
# 2.使用get_dummies的方法,读取tips文件的名称为'dy'的列,根据原数据进行转换,添加原数据中缺省的变量
day_df = pd.get_dummies(data["day"])
# 3.读取使用get_dummies方法后,读取tips文件的前10行数据
day_df.head(10)
#4. 得到的数据为
Fri Sat Sun Thur
0 0 0 1 0
1 0 0 1 0
2 0 0 1 0
3 0 0 1 0
4 0 0 1 0
5 0 0 1 0
6 0 0 1 0
7 0 0 1 0
8 0 0 1 0
9 0 0 1 01.5 matplotlib.pyplot绘图函数
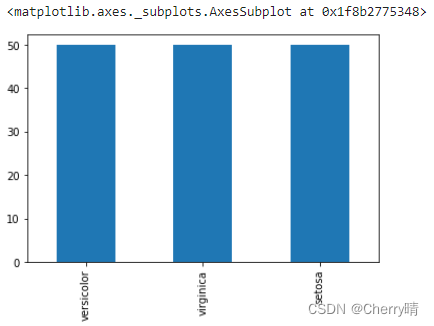
# 1.导入库
import matplotlib.pyplot as plt
# 2.# %matplotlib具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像
%matplotlib inline
# 3.导入数据
species = iris["Species"]
# 4.指定绘制的图形为柱状图(bar)
species.value_counts().plot(kind="bar")得到的结果如下图1-4所示:
1.6 info()—— 查看数据的摘要信息
- info(verbose=True, buf=None, max_cols=None)
(1)verbose:布尔值,默认值为 True,如果为 False,则不打印列计数摘要
(2)buf :可写缓冲区,默认:sys.stdout
(3)max_cols:int,默认值:无,确定是打印完整摘要还是简短摘要
# 1.查看iris文件数据帧的摘要信息
iris.info()
# 2.得到的结果为
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
Unnamed: 0 150 non-null int64
Sepal.Length 150 non-null float64
Sepal.Width 150 non-null float64
Petal.Length 150 non-null float64
Petal.Width 150 non-null float64
Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB1.7 describe方法——观察数据的范围、大小、波动趋势等等,便于判断后续对数据采取哪类模型更合适
- dataframe.describe(percentiles=None, include=None, exclude=None)
(1)percentiles:此参数可以设定数值型特征的统计量,默认是[.25, .5, .75],也就是返回25%,50%,75%数据量时的数字,但是这个可以修改的,可以修改成[.2,.75,.8],它是默认有[.5]的
(2)include:此参数默认是只计算数值型特征的统计量,当输入include=['O'],会计算离散型变量的统计特征 像上面的代码,传参数是"all"的时候会把数值型和离散型特征的统计都进行显示
(3)exclude:此参数可以指定不选哪些,默认不丢弃任何列,相当于无影响
# 1.使用describe方法观察iris数据
iris.describe(include = "all")
# 2. 得到的结果为
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
count 150.000000 150.000000 150.000000 150.000000 150.000000 150
unique NaN NaN NaN NaN NaN 3
top NaN NaN NaN NaN NaN versicolor
freq NaN NaN NaN NaN NaN 50
mean 75.500000 5.843333 3.057333 3.758000 1.199333 NaN
std 43.445368 0.828066 0.435866 1.765298 0.762238 NaN
min 1.000000 4.300000 2.000000 1.000000 0.100000 NaN
25% 38.250000 5.100000 2.800000 1.600000 0.300000 NaN
50% 75.500000 5.800000 3.000000 4.350000 1.300000 NaN
75% 112.750000 6.400000 3.300000 5.100000 1.800000 NaN
max 150.000000 7.900000 4.400000 6.900000 2.500000 NaN- percentiles:此参数可以设定数值型特征的统计量,默认是[.25, .5, .75],也就是返回25%,50%,75%数据量时的数字,但是这个可以修改的,可以修改成[.2,.75,.8],它是默认有[.5]的
# 1.添加percentiles参数
iris.describe(percentiles=[.35,.65,.85],include = "all")
# 2.得到的结果为
Unnamed: 0 Sepal.Length Sepal.Width Petal.Length Petal.Width Species
count 150.000000 150.000000 150.000000 150.000000 150.000000 150
unique NaN NaN NaN NaN NaN 3
top NaN NaN NaN NaN NaN versicolor
freq NaN NaN NaN NaN NaN 50
mean 75.500000 5.843333 3.057333 3.758000 1.199333 NaN
std 43.445368 0.828066 0.435866 1.765298 0.762238 NaN
min 1.000000 4.300000 2.000000 1.000000 0.100000 NaN
35% 53.150000 5.500000 2.900000 3.330000 1.000000 NaN
50% 75.500000 5.800000 3.000000 4.350000 1.300000 NaN
65% 97.850000 6.200000 3.200000 4.800000 1.500000 NaN
85% 127.650000 6.700000 3.500000 5.600000 2.065000 NaN
max 150.000000 7.900000 4.400000 6.900000 2.500000 NaN- include参数默认是只计算数值型特征的统计量,当输入include=['O'],会计算离散型变量的统计特征
# 1.include参数默认是只计算数值型特征的统计量,当输入include=['O'],会计算离散型变量的统计特征
iris.describe(percentiles=[.35,.65,.85],include = ["O"])
# 2.得到的结果为
Species
count 150
unique 3
top versicolor
freq 501.2 Series
- pd.Series(data, index)
(1)data:数据,可以是NumPy的ndarray对象、字典、字典
(2)index:索引
1.2.1 通过列表创建Series
- 不指定index的情况下
# 1.这里并没有指定index,所以python会采用整型数据作为该Series的index
ts = pd.Series(np.random.randn(4))
# 2.查看数据
ts
# 3.得到的结果为
0 -0.239289
1 0.595429
2 -0.237222
3 -0.061077
dtype: float64- 指定index的情况下:
# 1.导入numpy库
import numpy as np
# 2.随机在(0-4)(不包括4)的数字中生成一个一维数组,并设定其index
ts = pd.Series(np.random.randn(4),index=["a","a","c","d"])
# 3.查看列表
ts
# 4.得到的结果为
a -0.113357
a -0.003608
c 0.165057
d -0.061333
dtype: float641.2.2通过字典创建Series
- 通过使用字典来创建Series,且只传入一个字典,则结果中的Series中的索引就是原字典的键(有序排列)
# 1.这里是通过使用字典来创建Series,且只传入一个字典,则结果中的Series中的索引就是原字典的键(有序排列)
d = {"a":0.12,"b":0.33,"c":-0.17}
# 2.创建Series
ts = pd.Series(d)
# 3.查看结果
ts
# 4.最终得到的结果为
a 0.12
b 0.33
c -0.17
dtype: float64- 指定Series的index,这里只有一个值,但是并没有指定它对应的索引
# 1.指定Series的index,这里只有一个值,但是并没有指定它对应的索引
ts = pd.Series(2, index=["a","b","c"])
# 2. 查看结果
ts
# 3.得到的结果为
a 2
b 2
c 2
dtype: int64- 特别注意:Series是一个一维数组,它的值是一个或者是对应index索引的个数(有指定索引的),否则会报错
1.2.3数据索引与筛选
- 读取iris.csv文件中的Petal.Length列的前5行数据
# 1.读取iris.csv文件中的Petal.Length列的前5行数据
ts = data["Petal.Length"].head(5)
# 2.查看数据
ts
# 3.得到的结果为
0 1.4
1 1.4
2 1.3
3 1.5
4 1.4
Name: Petal.Length, dtype: float64- 通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的第三个值
# 1.通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的第三个值
ts[2]
# 2.得到的结果为
1.3- 通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的前四个值,不包括第四个
# 1.通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的前四个值,不包括第四个
ts[:3]
# 2.得到的结果为
0 1.4
1 1.4
2 1.3
Name: Petal.Length, dtype: float64- 通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的第一个和第三个数据值
# 1.通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的第一个和第三个数据值
ts[[1,3]]
# 2.得到的结果为
1 1.4
3 1.5
Name: Petal.Length, dtype: float64- 通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的值,并从中选取小于前5个数据的平均值的值
# 1.通过切片操作来读取iris.csv文件中的Petal.Length列的前5行数据的值,并从中选取小于前5个数据的平均值的值
ts[ts < ts.mean()]
# 2.得到的结果为
2 1.3
Name: Petal.Length, dtype: float641.2.4 唯一值和数量统计
- unique(iterable)——计算Index中唯一值的数组
(1)iterable 参数是一个可迭代对象,可以是列表、元组、集合等
注意事项:
(1)unique() 函数只能用于可迭代对象,如列表、元组、集合等
(2)unique() 函数返回的是一个新的列表,不会修改原有可迭代对象中的元素
(3)unique() 函数是以元素的值作为唯一性的判断标准,而不是以元素的内存地址判断是否相同
(4)unique() 函数对于不可哈希的对象(如列表、集合等)会报错,所以在使用时需要确保可迭代对象中的元素是可哈希的
# 1.选择数据
species = data["Species"]
# 2.使用unique()方法统计一共有几种鸢尾花
species.unique()
# 3.得到的结果为
array(['setosa', 'versicolor', 'virginica'], dtype=object)- value_counts(values,sort=True,ascending=False,normalize=False,bins=None,dropna=True)
(1)sort:是否要进行排序;默认进行排序
(2)ascending:默认降序排列
(3)normalize=False:是否要对计算结果进行标准化并显示标准化后的结果,默认是False
(4)bins:可以自定义分组区间,默认是否
(5)dropna:是否删除缺失值nan,默认删除
# 1.统计每种每种鸢尾花的数量
species.value_counts()
# 2.得到的结果为
versicolor 50
virginica 50
setosa 50
Name: Species, dtype: int64注意:本文中数据以及内容若有侵权,请第一时间联系删除。
本文是作者个人学习后的总结,未经作者授权,禁止转载,谢谢配合。




![[图解]SysML和EA建模住宅安全系统-04](https://img-blog.csdnimg.cn/direct/5f854a210e154ddabb49e6bd925b967e.png)