实验4 MapReduce编程(2)
本实验的知识地图如图4-1所示( 表示重点 表示难点)。
图4-1 实验4MapReduce编程(2)知识地图
一、实验目的
1. 理解YARN体系架构。
2. 熟练掌握YARN Web UI界面的使用。
3. 掌握YARN Shell常用命令的使用。
4. 了解YARN编程之三大范式,深入理解MapReduce编程思想,掌握MR-App编写步骤,编写简单MR-App,熟练掌握在Hadoop集群上运行MR-App并查看运行结果。
二、实验环境
本实验所需的软件环境包括全分布模式Hadoop集群、Eclipse。
三、实验内容
1. 启动全分布模式Hadoop集群,守护进程包括NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager和JobHistoryServer。
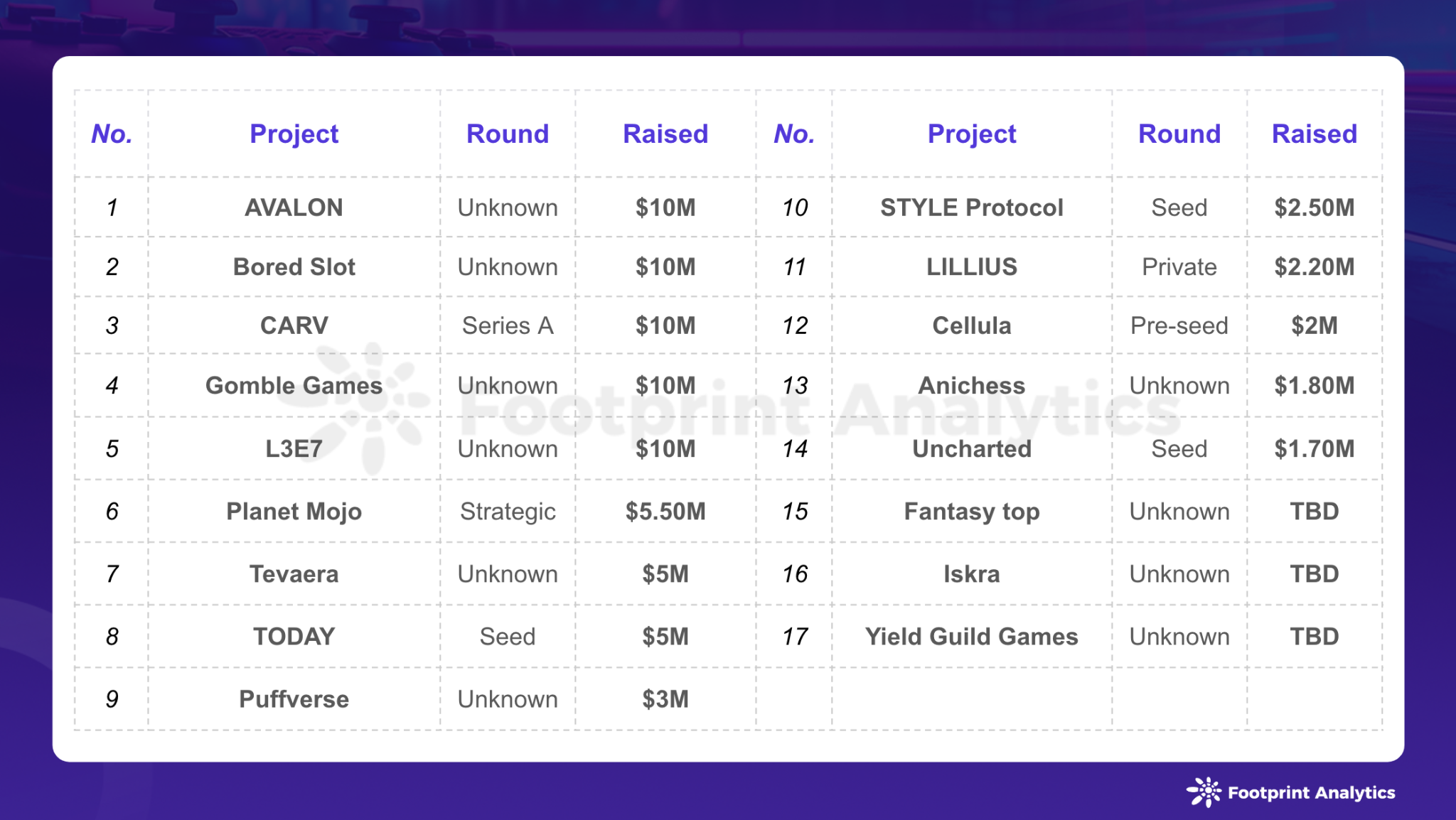
2. 在Eclipse项目MapReduceExample+姓名下建立新包com.xijing.mapreduce+姓名,编写MapReduce程序,已知某个超市的结算记录,从左往右各字段的含义依次是会员编号、结算时间、消费金额和用户身份,要求计算出会员和非会员的平均消费金额。最后打包成JAR形式并在Hadoop集群上运行该MR-App,查看运行结果。
3. 分别在自编MapReduce程序运行过程中和运行结束后查看YARN Web UI界面。
4. 分别在自编MapReduce程序运行过程中和运行结束后练习YARN Shell常用命令。
5. 关闭Hadoop集群。
四、实验原理
(一)YARN简介
在Hadoop 1.0中,MapReduce采用Master/Slave架构,有两类守护进程控制作业的执行过程,即一个JobTracker和多个TaskTracker。JobTracker负责资源管理和作业调度;TaskTracker定期向JobTracker汇报本节点的健康状况、资源使用情况、任务执行情况以及接受来自JobTracker的命令并执行。
随着集群规模负载的增加,MapReduce JobTracker在内存消耗、扩展性、可靠性、性能等方面暴露出各种缺点,具体包括以下几个方面。
(1)单点故障问题。JobTracker只有一个,它负责所有MapReduce作业的调度,若这个唯一的JobTracker出现故障就会导致整个集群不可用。
(2)可扩展性瓶颈。业内普遍总结出当节点数达到4000,任务数达到40000时,MapReduce 1.0会遇到可扩展性瓶颈,这是由于JobTracker“大包大揽”任务过重,既要负责作业的调度和失败恢复,又要负责资源的管理分配。当执行过多的任务时,需要巨大的内存开销,这也潜在增加了JobTracker失败的风险。
(3)资源划分不合理。资源(CPU、内存)被强制等量划分为多个Slot,每个TaskTracker都配置有若干固定长度的Slot,这些Slot是静态分配的,在配置的时候就被划分为Map Slot和Reduce Slot,且Map Slot仅能用于运行一个Map任务,Reduce Slot仅能用于运行一个Reduce任务,彼此之间不能使用分配给对方的Slot。这意味着,当集群中只存在单一Map任务或Reduce任务时,会造成资源的极大浪费。
(4)仅支持MapReduce一个计算框架。MapReduce是一个基于Map和Reduce、适合批处理、基于磁盘的计算框架,不能解决所有场景问题,而一个集群仅支持一个计算框架,不支持其他类型的计算框架如Spark、Storm等,造成集群多、管理复杂,且各个集群不能共享资源,造成集群间资源浪费。
为了解决MapReduce 1.0存在的问题,Hadoop 2.0以后版本对其核心子项目MapReduce的体系架构进行了重新设计,生成了MRv2和YARN。
YARN设计的基本思路就是“放权”,即不让JobTracker承担过多功能,把MapReduce 1.0中JobTracker,分别交给不同的新组件承担。重新设计后得到的YARN包括ResourceManager、ApplicationMaster和NodeManager,其中,ResourceManager负责资源管理,ApplicationMaster负责任务调度和任务监控,NodeManager负责承担原TaskTracker功能,且原资源被划分的Slot重新设计为容器Container,NodeManager能够启动和监控容器Container。另外,原JobTracker也负责存储已完成作业的作业历史,此功能也可以运行一个作业历史服务器作为一个独立守护进程来取代JobTracker,YARN中与之等价的角色是时间轴服务器Timeline Server。
总之,Hadoop 1.0中,MapReduce既是一个计算框架,又是一个资源管理和调度框架,到了Hadoop 2.0以后,MapReduce中资源管理和调度功能被单独分割出来形成YARN,YARN是一个纯粹的资源管理调度框架,而被剥离了资源管理调度功能的MapReduce变成了MRv2,MRv2是运行在YARN上的一个纯粹的计算框架。
从MapReduce 1.0发展到YARN,客户端并没有发生变化,其大部分API及接口都保持兼容,因此,原来针对Hadoop 1.0开发的代码不需做大的改动,就可以直接放在Hadoop 2.0平台上运行。
YARN的提出并非仅仅为了解决MapReduce 1.0中存在的问题,实际上YARN有着更加伟大的目标,即实现“一个集群多个框架”,也就是说在一个集群上部署一个统一的资源管理调度框架YARN,打造以YARN为核心的生态圈,如图4-2所示,在YARN之上可以部署其他各种计算框架,满足一个公司各种不同的业务需求,如离线计算框架MapReduce、DAG计算框架Tez、流式计算框架Storm、内存计算框架Spark等,由YARN为这些计算框架提供统一的资源管理调度服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。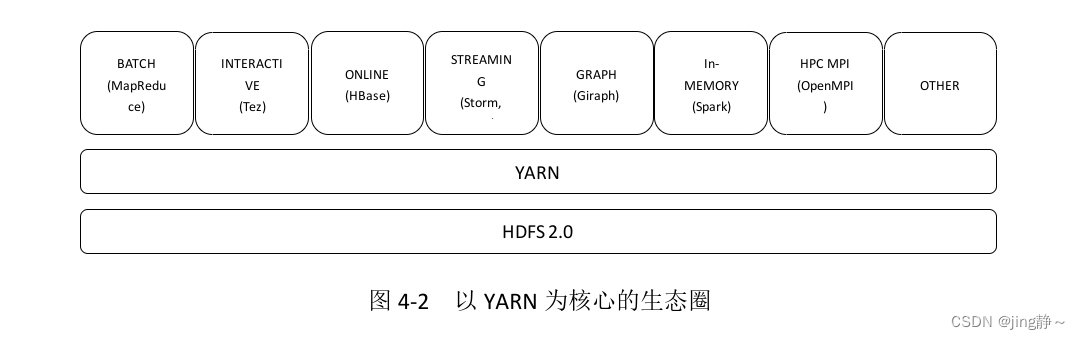
图4-2 以YARN为核心的生态圈
(二)YARN体系架构
YARN采用主从架构(Master/Slave),其核心组件包括三个:ResourceManager、NodeManager和ApplicationMaster。其中,ResourceManager是主进程,NodeManager是从进程,一个ResourceManager对应多个NodeManager,每个应用程序拥有一个ApplicationMaster。此外,YARN中引入了一个逻辑概念——容器Container,它将各类资源(如CPU、内存)抽象化,方便从节点NodeManager管理本机资源,主节点ResourceManager管理集群资源,如规定<1核,2G>为1个Container。YARN体系架构如图4-3所示。
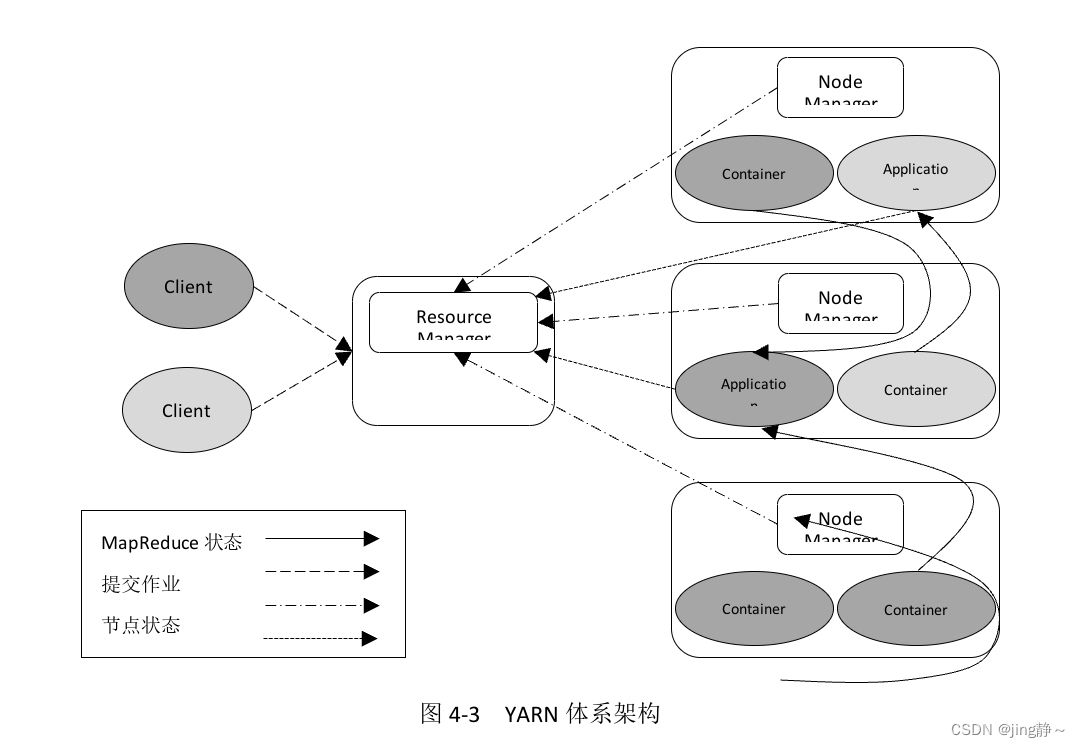
图4-3 YARN体系架构
关于YARN各组成部分的功能介绍如下。
1. Client
Client向ResourceManager提交任务、终止任务等。
2. ResourceManager
整个集群只有一个ResourceManager,负责集群资源的统一管理和调度。具体承担功能包括:
(1)处理来自客户端请求,包括启动/终止应用程序。
(2)启动/监控ApplicationMaster,一旦某个ApplicationMaster出现故障,ResourceManager将会在另一个节点上启动该ApplicationMaster。
(3)监控NodeManager,接收NodeManager汇报的心跳信息并分配任务给NodeManager去执行,一旦某个NodeManager出现故障,标记该NodeManager的任务,来告诉对应的ApplicationMaster如何处理。
3. NodeManager
整个集群有多个NodeManager,负责单节点资源的管理和使用。具体承担功能包括:
(1)周期性向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态。
(2)接收并处理来自ResourceManager的Container启动/停止的各种命令。
(3)处理来自ApplicationMaster的命令。
4. ApplicationMaster
每个应用程序拥有一个ApplicationMaster,负责管理应用程序。具体承担功能包括:
(1)数据切分。
(2)为应用程序/作业向ResourceManager申请资源(Container),并分配给内部任务。
(3)与NodeManager通信,以启动/停止任务。
(4)任务监控和容错,在任务执行失败时重新为该任务申请资源并重启任务。
(5)接收并处理ResourceManager发出的命令,如终止Container、重启NodeManager等。
5. Container
Container是YARN中新引入的一个逻辑概念,是YARN对资源的抽象,是YARN中最重要的概念之一。Container封装了某个节点上一定量的资源(CPU和内存两类资源),它与Linux Container没有任何关系,仅仅是YARN提出的一个概念。
Container由ApplicationMaster向ResourceManager申请,由ResouceManager中的资源调度器异步分配给ApplicationMaster;Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如Java、Python、C++进程启动命令等)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为以下两大类:
(1)运行ApplicationMaster的Container:这是由ResourceManager和其内部的资源调度器申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源。
(2)运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。该类Container上运行的任务类型可以是Map Task、Reduce Task或Spark Task等。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
(三)YARN Web UI
YARN Web UI接口面向管理员。从页面上,管理员能看到“集群统计信息”、“应用程序列表”、“调度器”等功能模块,此页面支持读,不支持写。YARN Web UI的默认地址为http://ResourceManagerIP:8088。YARN Web UI主界面——应用程序列表效果图如图4-4所示,从图4-4中可以看出,当前YARN上并没有任何应用程序运行。
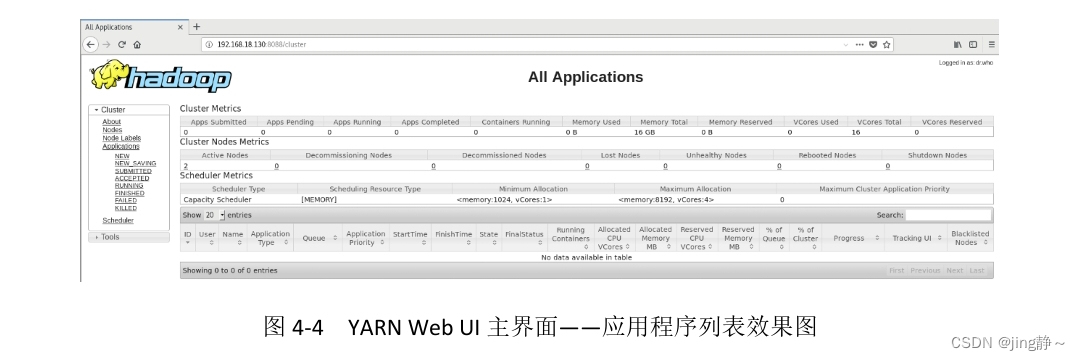
图4-4 YARN Web UI主界面——应用程序列表效果图
YARN Web调度器界面效果图如图4-5所示,从图4-5中可以看出,当前YARN上正在运行着一个应用程序“wordcount”,其Application Type为“MAPREDUCE”,采用的调度器为容量调度器Capacity Scheduler,YARN调度器的工作就是根据既定策略为应用程序分配资源,当前正在使用的Container有4个,共分配的CPU为4核,内存为5120M。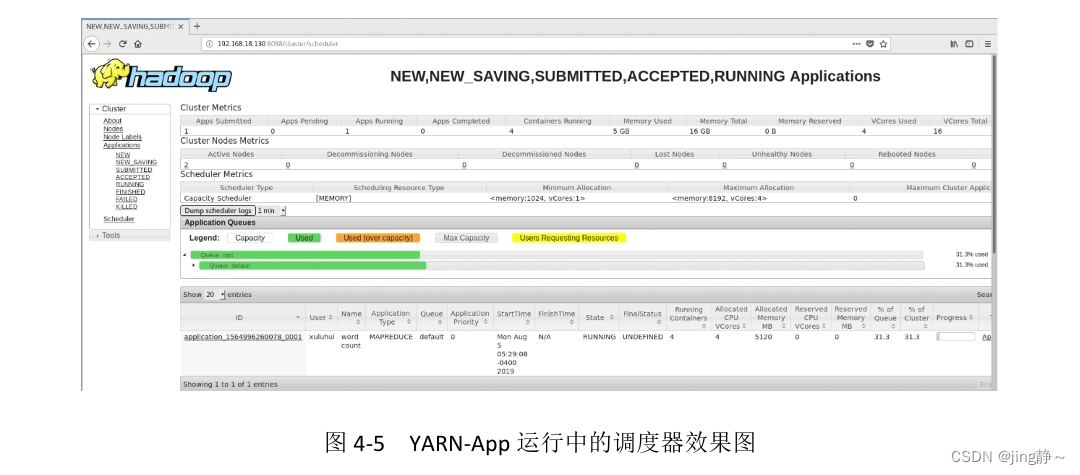
图4-5 YARN-App运行中的调度器效果图
集群资源统计信息效果图如图4-6所示,从图4-6中可以看出,按容量调度器Capacity Scheduler得出该集群的计算资源最小分配值为<memory:1024, vCores:1>,最大分配值为<memory:8192, vCores:4>。
图4-6 集群资源统计信息效果图
(四)YARN Shell
YARN Shell接口面向YARN管理员。通过Shell接口,管理员能够查看YARN系统级别统计信息,提交YARN-App等。
YARN Shell命令统一入口为:yarn,语法格式如下:
yarn [--config confdir] [COMMAND | CLASSNAME]
读者需要注意的是,若$HADOOP_HOME/bin未加入到系统环境变量PATH中,则需要切换到${HADOOP_HOME}下,输入“bin/yarn”。
读者可以使用“yarn -help”查看其帮助,命令“yarn”的具体用法和参数说明如下所示。
[xuluhui@master ~]$ yarn -help
Usage: yarn [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
resourcemanager run the ResourceManager
Use -format-state-store for deleting the RMStateStore.
Use -remove-application-from-state-store <appId> for removing application from RMStateStore.
nodemanager run a nodemanager on each slave
timelinereader run the timeline reader server
timelineserver run the timeline server
rmadmin admin tools
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
scmadmin SharedCacheManager admin tools
version print the version
jar <jar> run a jar file
application prints application(s) report/kill application
applicationattempt prints applicationattempt(s) report
container prints container(s) report
node prints node report(s)
queue prints queue information
logs dump container logs
schedulerconf updates scheduler configuration
classpath prints the class path needed to get the Hadoop jar and the required libraries
cluster prints cluster information
daemonlog get/set the log level for each daemon
top run cluster usage tool
YARN Shell命令分为系统级命令、程序级命令和其他辅助命令。本章仅介绍部分命令,关于YARN Shell命令的完整说明,读者请参考官方网站https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-site/YarnCommands.html。
1)系统级命令
YARN Shell部分系统级命令如表4-1所示。
表4-1 YARN Shell系统级命令(部分)
命令选项 功能描述
rmadmin 管理集群
node 查看集群当前节点信息
queue 查看集群当前队列运行状况
cluster 查看集群信息
2)程序级命令
YARN Shell部分程序级命令如表4-2所示。
表4-2 YARN Shell程序级命令(部分)
命令选项 功能描述
jar 向YARN集群提交YARN-App
application 查看YARN集群中正在运行的YARN-App
container 当YARN集群上正在运行YARN-App时,可以使用“container”查看该YARN-App所有Container以及各Container执行状态
3)其他辅助命令
YARN Shell部分辅助命令如表4-3所示。
表4-3 YARN Shell其他辅助命令(部分)
命令选项 功能描述
version 查看YARN版本
classpath 显示YARN环境变量
logs 显示某特定进程日志
(五)YARN Java API编程
YARN Java API接口面向Java开发工程师。程序员可以通过该接口编写YARN-App。YARN三大范式及其示例实现如表4-4所示。
表4-4 YARN三大范式及其示例实现
并行范式 示例实现
M范式 DistributedShell框架
M-S-R范式 MapReduce框架、Spark框架
BSP范式 Giraph框架
YARN-App三大模块包括:
(1)ApplicationBusinessLogic:应用程序的业务逻辑模块。
(2)ApplicationClient:应用程序客户端,负责提交和监管应用程序。
(3)ApplicationMaster:负责整个应用程序的运行,是应用程序并行化指挥地,需要指挥所有container并行执行ApplicationBusinessLogic。
YARN-App三大模块对应不同范式的类如表4-5所示。
表4-5 YARN-App三大模块对应不同范式的类
YARN应用程序标准模块 DistributedShell框架对应类 MapReduce框架对应类 Giraph框架对应类
ApplicationBussinessLogic 用户编写的Shell命令 用户自定义Mapper类、Partition类、和Reduce类 用户自定义BasicComputation类
ApplicationClient Client.java YARNRunner.java GiraphYarnClient.java
ApplicationMaster ApplicationMaster.java MRAPPMaster.java GiraphApplicationMaster.java
YARN Java API并不是本章重点,关于YARN API的详细内容,读者请参考官方网站https://hadoop.apache.org/docs/r2.9.2/api/index.html。
五、实验步骤
(一)启动Hadoop集群
在主节点上依次执行以下3条命令启动全分布模式Hadoop集群。
[xuluhui@master ~]$ start-dfs.sh
[xuluhui@master ~]$ start-yarn.sh
[xuluhui@master ~]$ mr-jobhistory-daemon.sh start historyserver
“start-dfs.sh”命令会在主节点上启动NameNode和SecondaryNameNode进程,会在从节点上启动DataNode进程。“start-yarn.sh”命令会在主节点上启动ResourceManager进程,会在从节点上启动NodeManager进程。“mr-jobhistory-daemon.sh start historyserver”命令会在主节点上启动JobHistoryServer进程。
(二)编写并运行MapReduce程序
实验3使用MapReduce统计的是单词数量,而单词本身属于字面值,是比较容易计算的。本案例将会讲解如何使用MapReduce统计对象中的某些属性。
【案例4-1】以下是某个超市的结算记录,从左往右各字段的含义依次是会员编号、结算时间、消费金额和用户身份,请计算会员和非会员的平均消费金额。
242315 2019-10-15.18:20:10 32 会员
984518 2019-10-15.18:21:02 167 会员
226335 2019-10-15.18:21:54 233 非会员
341665 2019-10-15.18:22:11 5 非会员
273367 2019-10-15.18:23:07 361 非会员
296223 2019-10-15.18:25:12 19 会员
193363 2019-10-15.18:25:55 268 会员
671512 2019-10-15.18:26:04 76 非会员
596233 2019-10-15.18:27:42 82 非会员
323444 2019-10-15.18:28:02 219 会员
345672 2019-10-15.18:28:48 482 会员
将超市结算记录命名为Customer.txt, 采用两种方法存放到本地文件系统。方法一,在windows环境中创建好,上传到linux文件系统某个目录下,例如/home/xuluhui; 方法二,在linux文件系统某个目录下新建一空白文件,例如 touch /home/xuluhui/Customer.txt,再通过vi命令编辑对应内容。
[注意]复制内容后,确保最后一行没有空格行,通过vi进入编辑模式后,使用”: set list” 可显示出所有特殊字符,确保最后一行没有空格。
最后,将该文件上传到HDFS文件系统的某个输入文件存放目录。例如/InputDataTest。
hadoop fs -put /homg/xuluhui/Customer.txt /InputDataTest。 如/InputDataTest目录不存在,需要先创建,hadoop fs -mkdir /InputDataTest。
hadoop fs -ls /
1. 在Eclipse中创建Java项目
进入/usr/local/eclipse中通过可视化桌面打开Eclipse IDE,默认的工作空间为“/home/xuluhui/eclipse-workspace”。选择菜单『File』→『New』→『Java Project』,创建Java项目“MapReduceExample+姓名”,例如“MapReduceExamplehanyue”。具体过程请参考实验3实验指导书。
2. 在项目中导入所需JAR包
为了编写关于MapReduce应用程序,需要向Java工程中添加MapReduce核心包hadoop-mapreduce-client-core-2.9.2.jar,该包中包含了可以访问MapReduce的Java API,位于$HADOOP_HOME/share/hadoop/mapreduce下。另外,由于还需要对HDFS文件进行操作,所以还需要导入JAR包hadoop-common-2.9.2.jar,该包位于$HADOOP_HOME/share/hadoop/common下。由于实验3中已导入所需JAR包,因此本步骤可以省略,具体过程请参考实验3实验指导书。
3. 在项目中新建包
右键单击项目“MapReduceExample+姓名”,从弹出的快捷菜单中选择『New』→『Package』,创建包“com.xijing.mapreduce+姓名”,例如“com.xijing.mapreducehanyue”。具体过程请参考实验3实验指导书。
4. 自编MapReduce程序
本案例的实现思路是:先计算会员和非会员的总消费金额,然后除以会员或非会员的数量。具体实现过程如下所示。
(1)编写实体类
在包“com.xijing.mapreduce+姓名”下新建类“Customer”。编写封装每个消费者记录的实体类,每个消费者至少包含了编号、消费金额和是否为会员等属性,源代码如下所示。
package com.xijing.mapreduce+姓名;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Customer implements Writable {
//会员编号
private String id;
// 消费金额
private int money;
// 0:非会员 1:会员
private int vip;
public Customer() {
}
public Customer( String id,int money, int vip) {
this.id = id;
this.money = money;
this.vip = vip;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public int getVip() {
return vip;
}
public void setVip(int vip) {
this.vip = vip;
}
//序列化
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(id);
dataOutput.writeInt(money);
dataOutput.writeInt(vip);
}
//反序列化(注意:各属性的顺序要和序列化保持一致)
public void readFields(DataInput dataInput) throws IOException {
this.id = dataInput.readUTF();
this.money = dataInput.readInt();
this.vip = dataInput.readInt() ;
}
@Override
public String toString() {
return this.id + "\t" + this.money + "\t" + this.vip;
}
}
由于本次统计的Customer对象需要在Hadoop集群中的多个节点之间传递数据,因此需要将Customer对象通过write(DataOutput dataOutput)方法进行序列化操作,并通过readFields(DataInput dataInput)进行反序列化操作。
(2)编写Mapper类
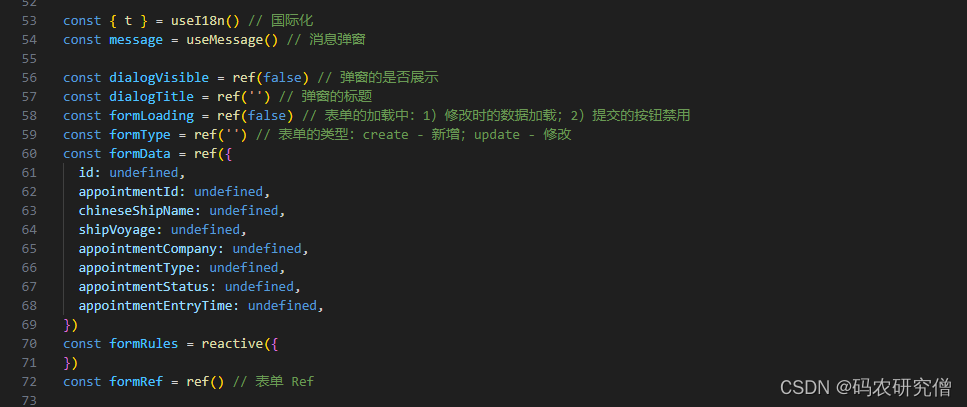
在包“com.xijing.mapreduce+姓名”下新建类“CustomerMapper”。在Map阶段读取文本中的消费者记录信息,并将消费者的各个属性字段拆分读取,然后根据会员情况,将消费者的消费金额输出到MapReduce的下一个处理阶段(即Shuffle),源代码如下所示。
package com.xijing.mapreduce+姓名;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CustomerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将一行内容转成string
String line = value.toString();
//获取各个顾客的消费数据, 请补充对应代码
String[] fields = line.split("\t");
//获取消费金额
int money = Integer.parseInt(fields[2]);
//获取会员情况, 请补充对应代码
/*
输出
Key:会员情况,value:消费金额
例如:
会员 32
会员 167
非会员 233
非会员 5
*/
context.write(); //请补充write方法对应入参
}
}
(3)编写Reducer类
在包“com.xijing.mapreduce+姓名”下新建类“CustomerReducer”。Map阶段的输出数据在经过shuffle阶段混洗以后,就会传递给Reduce阶段。Reduce拿到的数据形式是“会员(或非会员),[消费金额1,消费金额2,消费金额3,...]”。因此,与WordCount类似,只需要在Reduce阶段累加会员或非会员的总消费金额就能完成本次任务,源代码如下所示。
package com.xijing.mapreduce+姓名;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CustomerReducer extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable>values, Context context) throws IOException, InterruptedException {
//统计会员(或非会员)的个数
int vipCount = 0 ;
//总消费金额
long sumMoney = 0;
// 平均消费金额
long avgMoney = 0;
//会员(或非会员)的总消费金额,请补充对应代码
//会员(或非会员)的平均消费金额,请补充对应代码
}
}
(4)编写MapReduce程序的驱动类
在编写MapReduce程序时,程序的驱动类基本是相同的。因此,可以仿照之前的驱动类,编写本次的MapReduce驱动类,源代码如下所示。
package com.xijing.mapreduce+姓名;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CustomerDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CustomerDriver.class);
job.setMapperClass(请补充);
job.setReducerClass(请补充);
job.setMapOutputKeyClass(请补充);
job.setMapOutputValueClass(请补充);
job.setOutputKeyClass(请补充);
job.setOutputValueClass(请补充);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
最后,使用与WordCount程序相同的方法,将本程序打包成JAR包后就可以提交到Hadoop集群中运行了。执行结果就是会员与非会员的平均消费金额。
在教材中,我们介绍了一些优化MapReduce的具体方法,读者可以尝试使用一些优化策略对本案例进行优化。但在优化时一定要注意权衡利弊,认真思考每一个优化手段是否适合本题目的需求。例如在使用Combine组件前,需要先思考Combine的使用是否会影响程序的最终执行效果。
通过本实验大家可以发现,MapReduce将大数据的运算高度抽象为了Map和Reduce两个阶段,对于大部分的数据计算题目,我们只需要编写map()和reduce()方法,就能实现需要的计算功能。也正因为如此,MapReduce这款分布式计算框架对大数据计算领域有着里程碑的意义,认真学习好MapReduce对后续学习其他计算框架有着非常重要的意义和指导作用。
5. 将MapReduce程序打包成JAR包
为了运行写好的MapReduce程序,需要首先将程序打包成JAR包。可以使用Maven或者Eclipse打JAR包。由于实验3中已介绍,因此此处不再赘述,具体过程请参考实验3实验指导书。
6. 提交JAR包到Hadoop中运行
与实验3运行WordCount相同,在Hadoop集群行执行命令“hadoop jar……”,就能在集群中运行自己编写的MapReduce程序了。此处不再赘述,具体过程请参考实验3实验指导书。
格式如下:Hadoop jar jar包所在目录 com.xijing.mapreduce+姓名.CustomerDrive 输入文件存放目录 输出文件存放目录
例如:
hadoop jar /usr/local/hadoop-2.9.2/Customer.jar com.xijing.mapreduce+姓名.CustomerDriver /InputDataTest /Customer.txt /OutPutDataTest
7. 查看运行结果
与实验3相同,此处不再赘述,具体过程请参考实验3实验指导书。
(三)练习使用YARN Shell命令
分别在自编MapReduce程序运行过程中和运行结束后练习YARN Shell常用命令。
例如,通过使用命令“yarn container -list <Application Attempt ID>”来查看某YARN-App运行时分配的所有Container信息。
“Application Attempt ID”在WEB UI上可获取。点击应用程序的ID,进入具体页面。
复制对应的Attempt ID
(四)练习使用YARN Web UI界面
分别在自编MapReduce程序运行过程中和运行结束后查看YARN Web UI界面。
例如,YARN Web调度器界面效果图如图4-7所示,从图4-7中可以看出,当前YARN上正在运行着一个应用程序“wordcount”,其Application Type为“MAPREDUCE”,采用的调度器为容量调度器Capacity Scheduler,YARN调度器的工作就是根据既定策略为应用程序分配资源,当前正在使用的Container有4个,共分配的CPU为4核,内存为5120M。
图4-7 YARN-App运行中的调度器效果图
(五)关闭Hadoop集群
关闭全分布模式Hadoop集群的命令与启动命令次序相反,只需在主节点master上依次执行以下3条命令即可关闭Hadoop。
[xuluhui@master ~]$ mr-jobhistory-daemon.sh stop historyserver
[xuluhui@master ~]$ stop-yarn.sh
[xuluhui@master ~]$ stop-dfs.sh
执行mr-jobhistory-daemon.sh stop historyserver时,其*historyserver.pid文件消失;执行stop-yarn.sh时,*resourcemanager.pid和*nodemanager.pid文件依次消失;stop-dfs.sh,*namenode.pid、*datanode.pid、*secondarynamenode.pid文件依次消失。
六、实验报告要求
实验报告以电子版形式提交。
实验报告主要内容包括实验名称、实验类型、实验地点、学时、实验环境、实验原理、实验步骤、实验结果、总结与思考等。
思考与练习题
1. 查阅资料,了解如何使用IntelliJ IDEA在单机环境下,运行MapReduce程序。
2. 请思考在Windows平台和Linux平台下开发MapReduce有何差异?应该从哪些方面消除这些差异。
3. 在实际工作中,一般都会在集群环境下运行MapReduce程序。但集群的部署需要多台物理机支撑,一般情况下,我们都是使用VMWare等虚拟机软件模拟多台物理机,但这种做法对物理机的性能要求较高。为此,请查阅资料,尝试在云平台上部署Hadoop集群,并成功运行MapReduce程序。
4. MapReduce是一款分布式计算框架,可以实现分布式环境下的并行计算。请思考,如果由我们自己来设计一套小型的分布式并行计算框架,需要使用到哪些技术,各个技术的作用是什么?
参考文献
[1] 董西成. Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M]. 北京:机械工业出版社,2013.
[2] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[C]// Communications of the ACM - 50th anniversary issue: 1958 - 2008, 2008,51(1):107-113.
[3] Apache Software Foundation. Apache Hadoop 2.9.2-MapReduce Tutorial[EB/OL]. [2018-11-13]. https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html.
[4] Apache Software Foundation. Apache Hadoop 2.9.2-MapReduce Commands Guide[EB/OL]. [2018-11-13]. https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html.
[5] Apache Software Foundation. Apache Hadoop 2.9.2-Apache Hadoop Main 2.9.2 API[EB/OL]. [2018-11-13]. https://hadoop.apache.org/docs/r2.9.2/api/index.html