前言
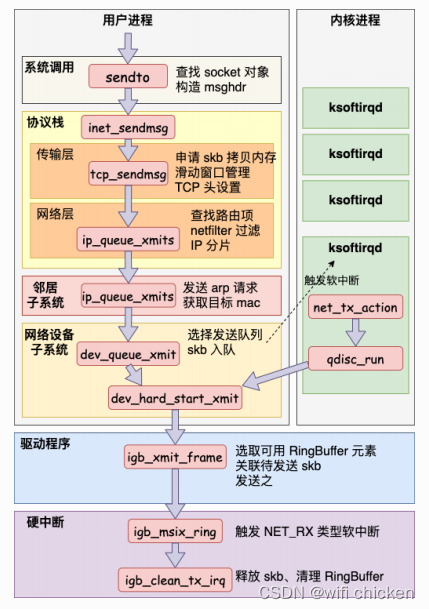
我们开始今天对 Linux 内核⽹络发送过程的深度剖析。还是按照我们之前的传统,先从⼀段代码作为切⼊。
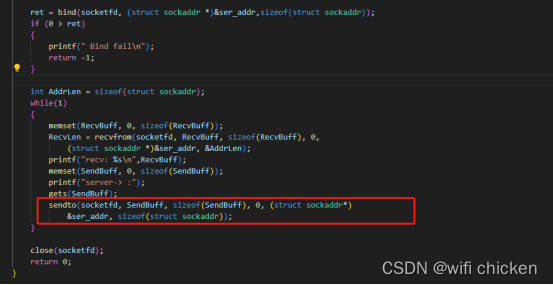
上述代码中,调⽤ send 之后内核是怎么样把数据包发送出去的。本⽂基于Linux 3.10,⽹卡驱动采⽤Intel的igb举例。
基础框架
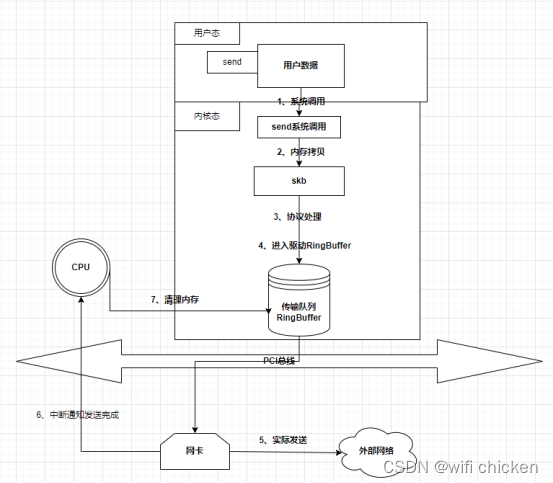
- 我们看到⽤户数据被拷⻉到内核态,然后经过协议栈处理后进⼊到了RingBuffer中。随后⽹卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。
源码流程跟踪(梳理的是从上到下的调用流程)
应用层
1. while(1)
{
sendto(socketfd, SendBuff, sizeof(SendBuff), 0, (struct sockaddr*)
&ser_addr, sizeof(struct sockaddr));
}
系统调用
2. SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t,
len,unsigned, flags, struct sockaddr __user *, addr,int, addr_len) {
err = sock_sendmsg(sock, &msg, len); }
int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
ret = __sock_sendmsg(&iocb, sock, msg, size);
}
static inline int __sock_sendmsg(struct kiocb *iocb, struct socket *sock,struct msghdr *msg, size_t size)
{
int err = security_socket_sendmsg(sock, msg, size);
return err ?: __sock_sendmsg_nosec(iocb, sock, msg, size);
}
static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
si->msg = msg;
si->size = size;
return sock->ops->sendmsg(iocb, sock, msg, size);
}
协议栈
3. int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct
msghdr *msg, size_t size) { return sk->sk_prot->sendmsg(iocb,
sk, msg, size); }
传输层
4. int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr
*msg, size_t size) { if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now); continue; }
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,int nonagle)
{
if (tcp_write_xmit(sk, cur_mss, nonagle, 0, GFP_ATOMIC))
tcp_check_probe_timer(sk);
}
static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
}
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask)
{
//调用网络层发送接口
err = icsk->icsk_af_ops->queue_xmit(skb, &inet->cork.fl);
if (likely(err <= 0))
return err;
}
网络层
5. int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl) { res =
ip_local_out(skb); rcu_read_unlock(); return res; }
int ip_local_out(struct sk_buff *skb)
{
err = __ip_local_out(skb);
if (likely(err == 1))
err = dst_output(skb);
}
/* Output packet to network from transport. */
static inline int dst_output(struct sk_buff *skb)
{
return skb_dst(skb)->output(skb);
}
static int ip_finish_output(struct sk_buff *skb)
{
return ip_finish_output2(skb);
}
static inline int ip_finish_output2(struct sk_buff *skb)
{
if (dst->hh) {
int res = neigh_hh_output(dst->hh, skb);
}
}
链路层
5. static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb)
{
unsigned int seq;
int hh_len;
skb_push(skb, hh_len);
return dev_queue_xmit(skb);
}
Linux 内核网络子系统
6. int dev_queue_xmit(struct sk_buff *skb) { if (q->enqueue) { rc =
__dev_xmit_skb(skb, q, dev, txq); goto out; } }
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
if (sch_direct_xmit(skb, q, dev, txq, root_lock))
}
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock)
{
HARD_TX_LOCK(dev, txq, smp_processor_id());
if (!netif_tx_queue_frozen_or_stopped(txq))
ret = dev_hard_start_xmit(skb, dev, txq);
}
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{//调用驱动里的回调发送函数ndo_start_xmit,将数据包传给网卡设备
skb_len = skb->len;
rc = ops->ndo_start_xmit(skb, dev);
}
驱动程序
7. static netdev_tx_t igb_xmit_frame(struct sk_buff *skb,
struct net_device *netdev) { return igb_xmit_frame_ring(skb, igb_tx_queue_mapping(adapter, skb)); }
netdev_tx_t igb_xmit_frame_ring(struct sk_buff *skb,
struct igb_ring *tx_ring)
{//igb_tx_map函数准备给设备发送的数据
igb_tx_map(tx_ring, first, hdr_len);
}
- 虽然数据这时已经发送完毕,但是其实还有⼀件重要的事情没有做,那就是释放缓存队列等内存。
- 那内核是如何知道什么时候才能释放内存的呢,当然是等⽹络发送完毕之后。⽹卡在发送完毕的时候,会给 CPU 发送⼀个硬中断来通知 CPU。
我们现在来看一下硬中断触发后的流程图:
硬中断
static irqreturn_t igb_msix_ring(int irq, void *data)
{
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
static inline void napi_schedule(struct napi_struct *n)
{
if (napi_schedule_prep(n))
__napi_schedule(n);
}
void __napi_schedule(struct napi_struct *n)
{
____napi_schedule(&__get_cpu_var(softnet_data), n);
local_irq_restore(flags);
}
/* Called with irq disabled */
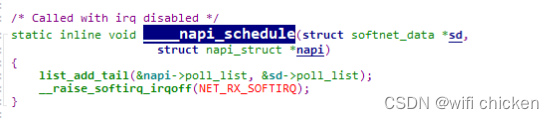
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
软中断
static void net_rx_action(struct softirq_action *h)
{
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
}
static bool igb_clean_tx_irq(struct igb_q_vector *q_vector)
{
do {
/* free the skb */
dev_kfree_skb_any(tx_buffer->skb);
/* unmap skb header data */
dma_unmap_single(tx_ring->dev,
dma_unmap_addr(tx_buffer, dma),
dma_unmap_len(tx_buffer, len),
DMA_TO_DEVICE);
/* clear tx_buffer data */
tx_buffer->skb = NULL;
dma_unmap_len_set(tx_buffer, len, 0);
/* clear last DMA location and unmap remaining buffers */
while (tx_desc != eop_desc) {
}
}
注意,虽然是发送数据,但是硬中断最终触发的软中断却是NET_RX_SOFTIRQ,⽽并不是 NET_TX_SOFTIRQ
在服务器上查看 /proc/softirqs,为什么 NET_RX 要⽐ NET_TX ⼤的多?
- 在服务器上查看 /proc/softirqs,为什么 NET_RX 要⽐ NET_TX ⼤的多的多传输完成最终会触发 NET_RX,⽽不是
NET_TX。 所以⾃然你观测 /proc/softirqs 也就能看到NET_RX 更多了。
网卡启动准备
- 现在的服务器上的⽹卡⼀般都是⽀持多队列的。每⼀个队列上都是由⼀个 RingBuffer 表示的,开启了多队列以后的的⽹卡就会对应有多个RingBuffer。
- ⽹卡在启动时最重要的任务之⼀就是分配和初始化 RingBuffer,理解了 RingBuffer 将会⾮常有助于后⾯我们掌握发送。因为今天的主题是发送,所以就以传输队列为例,我们来看下⽹卡启动时分配 RingBuffer 的实际过程。
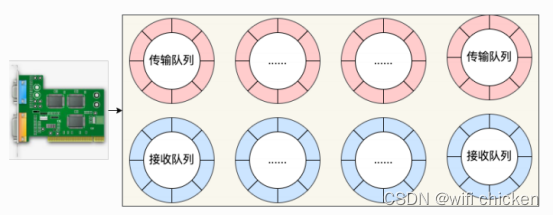
- 在⽹卡启动的时候,会调⽤到 __igb_open 函数,RingBuffer 就是在这⾥分配的。
static int igb_open(struct net_device *netdev)
{
//分配传输描述符数组
/* allocate transmit descriptors */
err = igb_setup_all_tx_resources(adapter);
//分配接收描述符数组
/* allocate receive descriptors */
err = igb_setup_all_rx_resources(adapter);
//开启全部队列
netif_tx_start_all_queues(netdev);
}
- 在上⾯ __igb_open 函数调⽤ igb_setup_all_tx_resources 分配所有的传输 RingBuffer, 调⽤
igb_setup_all_rx_resources 创建所有的接收 RingBuffer。
static int igb_setup_all_tx_resources(struct igb_adapter *adapter)
{//有⼏个队列就构造⼏个 RingBuffer
for (i = 0; i < adapter->num_tx_queues; i++) {
err = igb_setup_tx_resources(adapter->tx_ring[i]);
}
}
真正的 RingBuffer 构造过程是在 igb_setup_tx_resources 中完成的。
int igb_setup_tx_resources(struct igb_ring *tx_ring)
{
struct device *dev = tx_ring->dev;
int size;
//1.申请 igb_tx_buffer 数组内存
size = sizeof(struct igb_buffer) * tx_ring->count;
tx_ring->buffer_info = vzalloc(size);
if (!tx_ring->buffer_info)
goto err;
//2.申请 e1000_adv_tx_desc DMA 数组内存
/* round up to nearest 4K */
tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc);
tx_ring->size = ALIGN(tx_ring->size, 4096);
tx_ring->desc = dma_alloc_coherent(dev,
tx_ring->size,
&tx_ring->dma,
GFP_KERNEL);
if (!tx_ring->desc)
goto err;
//初始化队列成员
tx_ring->next_to_use = 0;
tx_ring->next_to_clean = 0;
return 0;
}
从上述源码可以看到,实际上⼀个 RingBuffer 的内部不仅仅是⼀个环形队列数组,⽽是有两个
- igb_tx_buffer 数组:这个数组是内核使⽤的,通过 vzalloc 申请的。
- e1000_adv_tx_desc 数组:这个数组是⽹卡硬件使⽤的,硬件是可以通过 DMA 直接访问这块内存,通过 dma_alloc_coherent 分配。
这个时候它们之间还没有啥联系。将来在发送的时候,这两个环形数组中相同位置的指针将都将指向同⼀个 skb。这样,内核和硬件就能共同访问同样的数据了,内核往 skb ⾥写数据,⽹卡硬件负责发送。

最后调⽤ netif_tx_start_all_queues 开启队列,对于硬中断的处理函数 igb_msix_ring其实也是在 __igb_open 中注册的。
ACCEPT 创建新 SOCKET
- 在发送数据之前,我们往往还需要⼀个已经建⽴好连接的 socket。
- 当 accept 之后,进程会创建⼀个新的 socket 出来,然后把它放到当前进程的打开⽂件列表中,专⻔⽤于和对应的客户端通信。
假设服务器进程通过 accept 和客户端建⽴了两条连接,我们来简单看⼀下这两条连接和进程的关联关系。
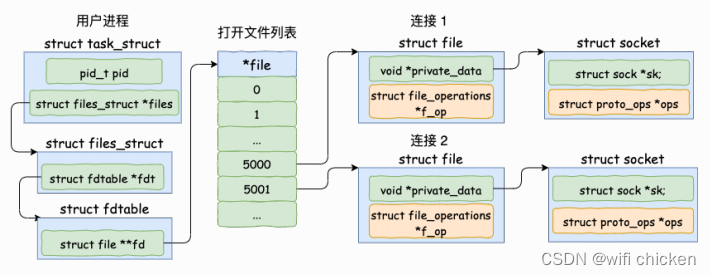
其中代表⼀条连接的 socket 内核对象更为具体⼀点的结构图如下。

发送数据真正开始
send 系统调⽤实现
send 系统调⽤的源码位于⽂件 net/socket.c 中。在这个系统调⽤⾥,内部其实真正使⽤的是 sendto 系统调⽤。整个调⽤链条虽然不短,但其实主要只⼲了两件简单的事情:
- 第⼀是在内核中把真正的 socket 找出来,在这个对象⾥记录着各种协议栈的函数地址。
- 第⼆是构造⼀个 struct msghdr 对象,把⽤户传⼊的数据,⽐如 buffer地址、数据⻓度,统统都装进去.剩下的事情就交给下⼀层协议栈⾥的函数 inet_sendmsg 了,其中 inet_sendmsg 函数的地址是通过 socket 内核对象⾥的 ops 成员找到的。
⼤致流程:
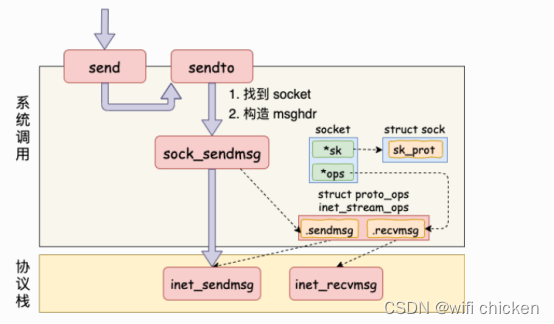

- 从源码可以看到,我们在⽤户态使⽤的 send 函数和 sendto 函数其实都是 sendto 系统调⽤实现的。send
只是为了⽅便,封装出来的⼀个更易于调⽤的⽅式⽽已。 - 在 sendto 系统调⽤⾥,⾸先根据⽤户传进来的 socket 句柄号来查找真正的 socket 内核对象。接着把⽤户请求的
buff、len、flag 等参数都统统打包到⼀个 struct msghdr 对象中。接着调⽤了 sock_sendmsg => __sock_sendmsg ==> __sock_sendmsg_nosec。在__sock_sendmsg_nosec 中,调⽤将会由系统调⽤进⼊到协议栈,我们来看它的源码。

- 通过前面的 socket 内核对象结构图,我们可以看到,这⾥调⽤的是 sock->ops->sendmsg 实际执⾏的是
inet_sendmsg。这个函数是 AF_INET 协议族提供的通⽤发送函数。
传输层处理
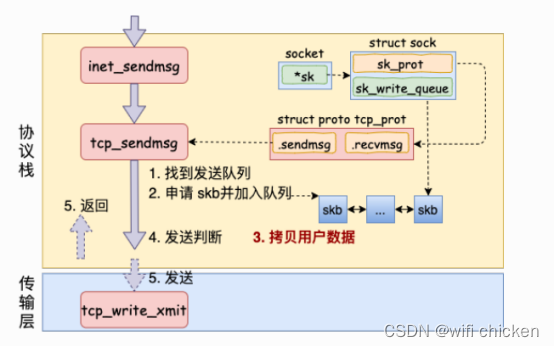
- 在进⼊到协议栈 inet_sendmsg 以后,内核接着会找到 socket 上的具体协议发送函数。对于TCP 协议来说,那就是tcp_sendmsg(同样也是通过 socket 内核对象找到的)。
- 在这个函数中,内核会申请⼀个内核态的 skb 内存,将⽤户待发送的数据拷⻉进去。注意这个时候不⼀定会真正开始发送,如果没有达到发送条件的话很可能这次调⽤直接就返回了。
⼤概过程如图:
-
inet_sendmsg 函数的源码

-
在这个函数中会调⽤到具体协议的发送函数。同样前面的 socket 内核对象结构图,我们看到对于 TCP 协议下的 socket 来说,来说sk->sk_prot->sendmsg 指向的是tcp_sendmsg(对于 UPD 来说是 udp_sendmsg)。

-
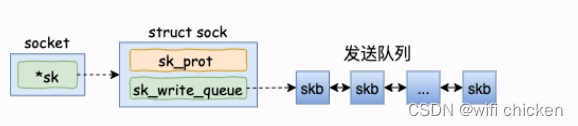
理解对 socket 调⽤ tcp_write_queue_tail 是理解发送的前提。如上所示,这个函数是在获取 socket
发送队列中的最后⼀个 skb。 skb 是 struct sk_buff 对象的简称,⽤户的发送队列就是该对象组成的⼀个链表。
-
再接着看 tcp_sendmsg 的其它部分
tcp_sendmsg(struct kiocb *iocb,struct sock *sk, struct msghdr *msg, size_t size){
//获取用户传递过来的数据和标志
iov = msg->msg_iov;
//用户数据地址
iovlen =msg->msg_iovlen;
//数据块数为1
flags = msg->msg_flags;
//各种标志
//遍历用户层的数据块
while (--iovlen >= 0) {
//待发送数据块的地址
unsigned char __user *from = iov->iov_base; while (seglen >0) {
//需要申请新的
skb if (copy <= 0) {
//申请skb,并添加到发送队列的尾部
skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);
//把 skb 挂到socket的发送队列上
skb_entail(sk, skb); }
// skb 中有足够的空间
if (skb_availroom(skb) > 0) {
//拷贝用户空间的数据到内核空间,同时计算校验和
//from是用户空间的数据地址
skb_add_data_nocache(sk, skb, from, copy); }
- 这个函数⽐较⻓,不过其实逻辑并不复杂。其中 msg->msg_iov 存储的是⽤户态内存的要发送的数据的buffer。接下来在内核态申请内核内存,⽐如skb,并把⽤户内存⾥的数据拷⻉到内核态内存中。这就会涉及到⼀次或者⼏次内存拷⻉的开销。

- ⾄于内核什么时候真正把 skb 发送出去。在 tcp_sendmsg 中会进⾏⼀些判断。
int tcp_sendmsg(){
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
}
- 只有满⾜ forced_push(tp) 或者 skb ==tcp_send_head(sk)成⽴的时候,内核才会真正启动发送数据包。其中forced_push(tp) 判断的是未发送的数据数据是否已经超过最⼤窗⼝的⼀半了。
条件都不满⾜的话,这次的⽤户要发送的数据只是拷⻉到内核就算完事了!
传输层发送
- 假设现在内核发送条件已经满⾜了,我们再来跟踪⼀下实际的发送过程。对于上节函数中,当满⾜真正发送条件的时候,⽆论调⽤的是__tcp_push_pending_frames 还是tcp_push_one最终都实际会执⾏到 tcp_write_xmit。所以我们直接从 tcp_write_xmit 看起,这个函数处理了传输层的拥塞控制、滑动窗⼝相关的⼯作。满⾜窗⼝要求的时候,设置⼀下 TCP 头然后将 skb 传到更低的⽹络层进⾏处理。
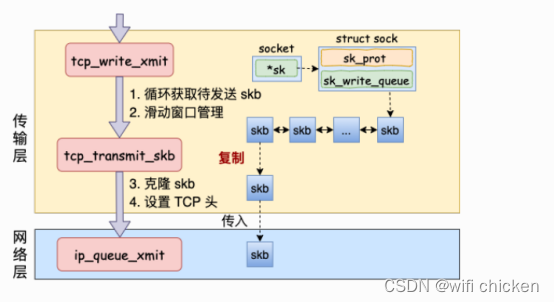
- 来看下 tcp_write_xmit 的源码


- 可以看到我们之前在⽹络协议⾥学的滑动窗⼝、拥塞控制就是在这个函数中完成的,这部分就不过多展开了,感兴趣同学⾃⼰找这段源码来读。我们今天只看发送主过程,那就⾛到了tcp_transmit_skb。
有删减函数:

此函数说明:
先克隆⼀个新的 skb,这⾥重点说下为什么要复制⼀个 skb 出来呢?
- 是因为 skb 后续在调⽤⽹络层,最后到达⽹卡发送完成的时候,这个 skb 会被释放掉。⽽我们知道 TCP协议是⽀持丢失重传的,在收到对⽅的 ACK 之前,这个 skb 不能被删除。所以内核的做法就是每次调⽤⽹卡发送的时候,实际上传递出去的是skb 的⼀个拷⻉。等收到ACK 再真正删除。
- 修改 skb 中的 TCP header,根据实际情况把 TCP 头设置好。这⾥要介绍⼀个⼩技巧,skb内部其实包含了⽹络协议中所有的 header。在设置 TCP 头的时候,只是把指针指向 skb 的合适位置。后⾯再设置 IP头的时候,在把指针挪⼀挪就⾏,避免频繁的内存申请和拷⻉,效率很⾼。
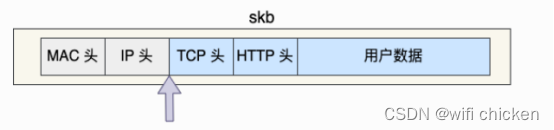
- tcp_transmit_skb是发送数据位于传输层的最后⼀步,接下来就可以进⼊到⽹络层进⾏下⼀层的操作了。调⽤了⽹络层提供的发送接⼝icsk->icsk_af_ops->queue_xmit()。
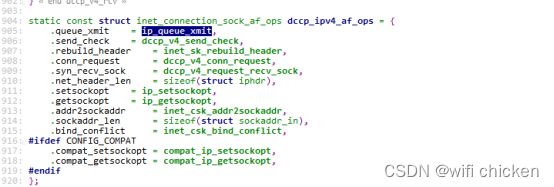
在下⾯的这个源码中,我们的知道了 queue_xmit 其实指向的是 ip_queue_xmit 函数。
⾃此,传输层的⼯作也就都完成了。 数据离开了传输层,接下来将会进⼊到内核在⽹络层的实现⾥。
⽹络层发送处理
- Linux 内核⽹络层的发送的实现位于 net/ipv4/ip_output.c 这个⽂件。传输层调⽤到的ip_queue_xmit也在这⾥。(从⽂件名上也能看出来进⼊到 IP 层了,源⽂件名已经从tcp_xxx 变成了 ip_xxx。)
- 在⽹络层⾥主要处理路由项查找、IP 头设置、netfilter 过滤、skb 切分(⼤于 MTU 的话)⼏项⼯作,处理完这些⼯作后会交给更下层的邻居⼦系统来处理。
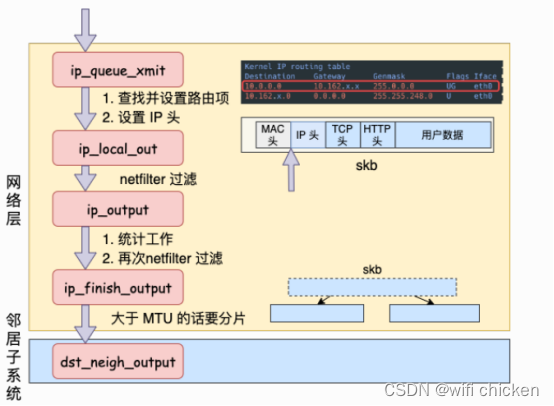

- ip_queue_xmit 已经到了⽹络层,在这个函数⾥我们看到了⽹络层相关的功能路由项查找,如果找到了则设置到 skb上(没有路由的话就直接报错返回了)。
- 在 Linux 上通过 route 命令可以看到你本机的路由配置。

- 在路由表中,可以查到某个⽬的⽹络应该通过哪个 Iface(⽹卡),哪个 Gateway(⽹卡)发送出去。查找出来以后缓存到 socket上,下次再发送数据就不⽤查了。
- 接着把路由表地址也放到 skb ⾥去。

- 接下来就是定位到 skb ⾥的 IP 头的位置上,然后开始按照协议规范设置 IP header

- 在 ip_local_out => __ip_local_out => nf_hook 会执⾏ netfilter 过滤。如果你使⽤iptables配置了⼀些规则,那么这⾥将检测是否命中规则。
- 如果你设置了⾮常复杂的 netfilter 规则,在这个函数这⾥将会导致你的进程 CPU 开销会极⼤增加。

- 此函数找到这个 skb 的路由表(dst 条⽬) ,然后调⽤路由表的 output ⽅法。这⼜是⼀个函数指针,指向的是 ip_output
⽅法。

- 在 ip_output 中进⾏⼀些简单的,统计⼯作,再次执⾏ netfilter 过滤。过滤通过之后回调ip_finish_output。
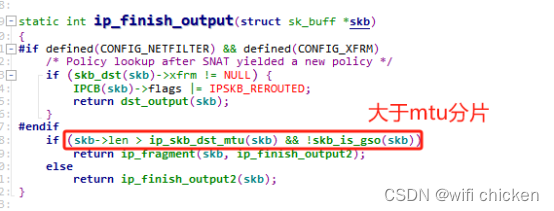
- 在 ip_finish_output 中我们看到,如果数据⼤于 MTU 的话,是会执⾏分⽚的。
- 在 ip_finish_output2 中,终于发送过程会进⼊到下⼀层,邻居⼦系统中。
在早期的时候,软件开发者会尽量控制⾃⼰数据包尺⼨⼩于 MTU,通过这种⽅式来优化⽹络性能。因为分⽚会带来两个问题:
- 需要进⾏额外的切分处理,有额外性能开销。
- 只要⼀个分⽚丢失,整个包都得重传。所以避免分⽚既杜绝了分⽚开销,也⼤⼤降低了重传率。
邻居⼦系统
- 邻居⼦系统是位于⽹络层和数据链路层中间的⼀个系统,其作⽤是对⽹络层提供⼀个封装,让⽹络层不必关⼼下层的地址信息,让下层来决定发送到哪个MAC 地址。⽽且这个邻居⼦系统并不位于协议栈 net/ipv4/ ⽬录内,⽽是位于
net/core/neighbour.c。因为⽆论是对于 IPv4 还是 IPv6 ,都需要使⽤该模块。

- 在邻居⼦系统⾥主要是查找或者创建邻居项,在创造邻居项的时候,有可能会发出实际的arp 请求。然后封装⼀下 MAC
头,将发送过程再传递到更下层的⽹络设备⼦系统。⼤致流程如图。
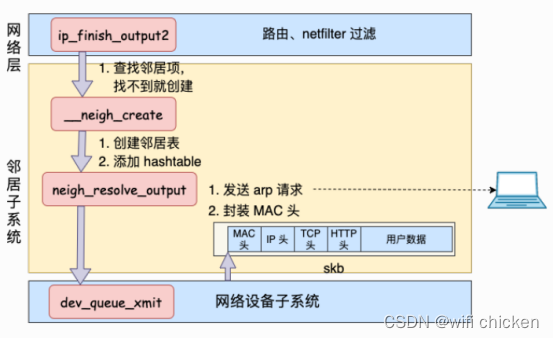
- 理解了⼤致流程,我们再回头看源码。在上⾯⼩节 ip_finish_output2源码中调⽤了__ipv4_neigh_lookup_noref。它是在 arp 缓存中进⾏查找,其第⼆个参数传⼊的是路由下⼀跳 IP信息。
如果查找不到,则调⽤ __neigh_create 创建⼀个邻居。
- 有了邻居项以后,此时仍然还不具备发送 IP 报⽂的能⼒,因为⽬的 MAC 地址还未获取。调⽤ dst_neigh_output 继续传递
skb。

- 调⽤ output,实际指向的是 neigh_resolve_output。在这个函数内部有可能会发出 arp ⽹络请求。

- 当获取到硬件 MAC 地址以后,就可以封装 skb 的 MAC 头了。最后调⽤ dev_queue_xmit将 skb 传递给 Linux
⽹络设备⼦系统。
⽹络设备⼦系统

- 邻居⼦系统通过 dev_queue_xmit 进⼊到⽹络设备⼦系统中来。

- ⽹卡启动准备⾥,⽹卡是有多个发送队列的。上⾯对 netdev_pick_tx 函数的调⽤就是选择⼀个队列进⾏发送。netdev_pick_tx 发送队列的选择受 XPS等配置的影响,⽽且还有缓存,也是⼀套⼩复杂的逻辑。这⾥我们只关注两个逻辑,⾸先会获取⽤户的 XPS配置,否则就⾃动计算了。代码⻅netdev_pick_tx => __netdev_pick_tx。

- 然后获取与此队列关联的 qdisc。在 linux 上通过 tc 命令可以看到 qdisc 类型
$ tc qdisc
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev ens33 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
-
⼤部分的设备都有队列(回环设备和隧道设备除外),所以现在我们进⼊到__dev_xmit_skb。
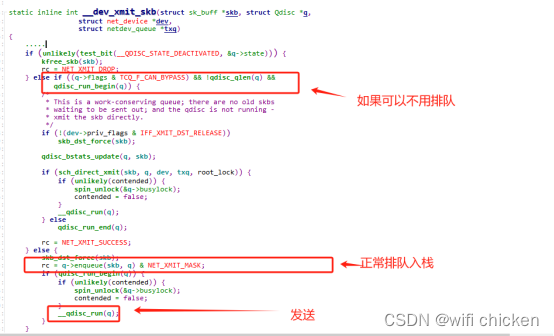
上述代码中分两种情况,1 是可以 bypass(绕过)排队系统的,另外⼀种是正常排队。我们只看第⼆种情况。 -
先调⽤ q->enqueue 把 skb 添加到队列⾥。然后调⽤ __qdisc_run 开始发送。

-
在上述代码中,我们看到 while 循环不断地从队列中取出 skb 并进⾏发送。注意,这个时候其实都占⽤的是⽤户进程的系统态时间(sy)。只有当 quota ⽤尽或者其它进程需要 CPU 的时候才触发软中断进⾏发送。
-
所以这就是为什么⼀般服务器上查看 /proc/softirqs,⼀般 NET_RX 都要⽐ NET_TX ⼤的多的第⼆个原因。对于读来说,都是要经过 NET_RX 软中断,⽽对于发送来说,只有系统态配额⽤尽才让软中断上。
继续看发送过程

- qdisc_restart 从队列中取出⼀个 skb,并调⽤sch_direct_xmit 继续发送。

软中断调度
- 在 4.5 咱们看到了如果系统态 CPU 发送⽹络包不够⽤的时候,会调⽤ __netif_schedule触发⼀个软中断。该函数会进⼊到 __netif_reschedule,由它来实际发出NET_TX_SOFTIRQ 类型软中断。
- 软中断是由内核线程来运⾏的,该线程会进⼊到net_tx_action 函数,在该函数中能获取到发送队列,并也最终调⽤到驱动程序⾥的⼊⼝函数 dev_hard_start_xmit
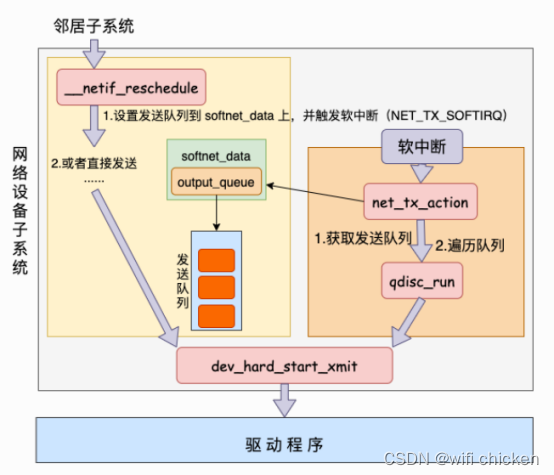
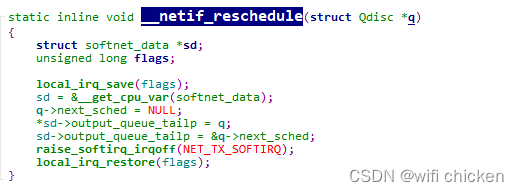
- 函数⾥在软中断能访问到的 softnet_data ⾥设置了要发送的数据队列,添加到了output_queue ⾥了。紧接着触发了NET_TX_SOFTIRQ 类型的软中断。(T 代表 transmit 传输)
- 我们直接从 NET_TX_SOFTIRQ softirq 注册的回调函数 net_tx_action讲起。⽤户态进程触发完软中断之后,会有⼀个软中断内核线程会执⾏到net_tx_action。
牢记,这以后发送数据消耗的 CPU 就都显示在 si (SoftIRQ)这⾥了,不会消耗⽤户进程的系统时间了

- 软中断这⾥会获取 softnet_data。前⾯我们看到进程内核态在调⽤ __netif_reschedule的时候把发送队列写到softnet_data的output_queue ⾥了。 软中断循环遍历 sd->output_queue发送数据帧。
来看 qdisc_run,它和进程⽤户态⼀样,也会调⽤到 __qdisc_run。
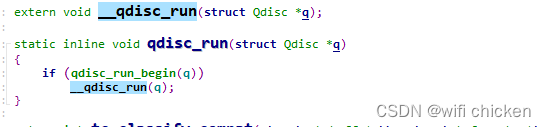
- 然后⼀样就是进⼊ qdisc_restart =>sch_direct_xmit,直到驱动程序函数dev_hard_start_xmit。
⽹卡驱动发送
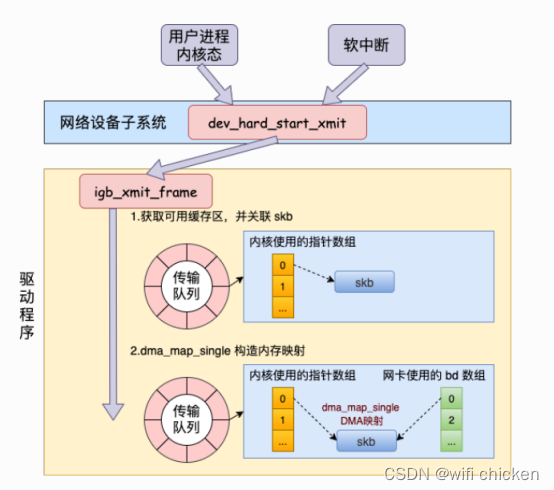
- ⽆论是对于⽤户进程的内核态,还是对于软中断上下⽂,都会调⽤到⽹络设备⼦系统中的dev_hard_start_xmit函数。在这个函数中,会调⽤到驱动⾥的发送函数igb_xmit_frame。
- 在驱动函数⾥,将 skb 会挂到 RingBuffer上,驱动调⽤完毕后,数据包将真正从⽹卡发送出去。
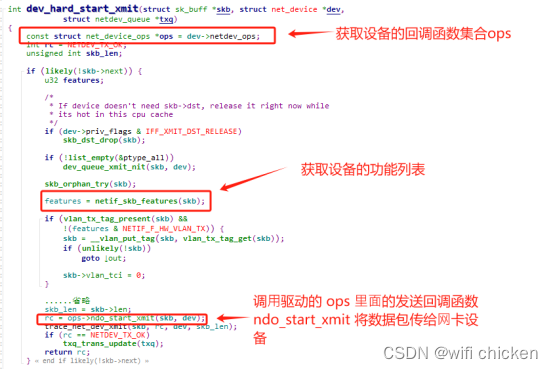
- 其中 ndo_start_xmit 是⽹卡驱动要实现的⼀个函数,是在 net_device_ops 中定义的
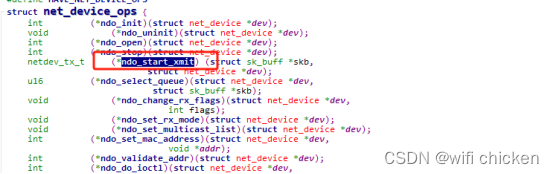
- 在 igb ⽹卡驱动源码中,我们找到了
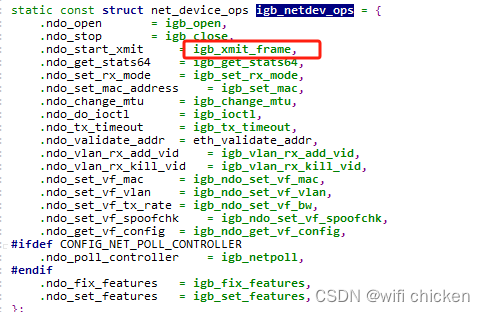
- 也就是说,对于⽹络设备层定义的 ndo_start_xmit, igb 的实现函数是 igb_xmit_frame。这个函数是在⽹卡驱动初始化的时候被赋值的。
- 所以在上⾯⽹络设备层调⽤ ops->ndo_start_xmit 的时候,会实际上进⼊ igb_xmit_frame这个函数中。我们进⼊这个函数来看看驱动程序是如何⼯作的


在这⾥从⽹卡的发送队列的 RingBuffer 中取下来⼀个元素,并将 skb 挂到元素上。

igb_tx_map 函数处理将 skb 数据映射到⽹卡可访问的内存 DMA 区域。
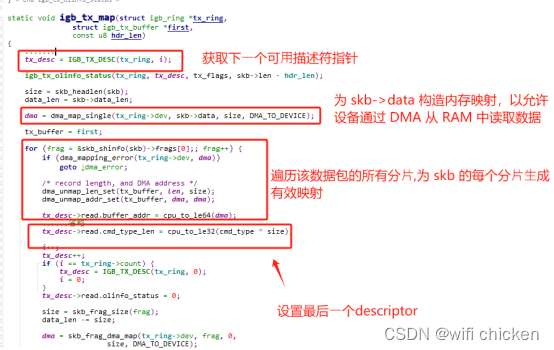
- 当所有需要的描述符都已建好,且 skb 的所有数据都映射到 DMA 地址后,驱动就会进⼊到它的最后⼀步,触发真实的发送。
发送完成硬中断
- 当数据发送完成以后,其实⼯作并没有结束。因为内存还没有清理。当发送完成的时候,⽹卡设备会触发⼀个硬中断来释放内存。
- 在发送硬中断⾥,会执⾏ RingBuffer 内存的清理⼯作
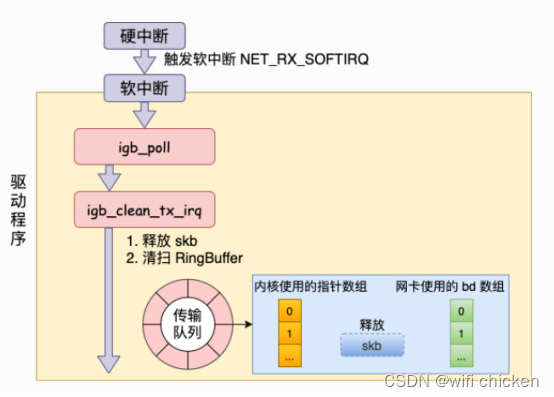
回头看⼀下硬中断触发软中断的源码
- 这⾥有个很有意思的细节,⽆论硬中断是因为是有数据要接收,还是说发送完成通知,从硬中断触发的软中断都是 NET_RX_SOFTIRQ。这个我们在第⼀节说过了,这是软中断统计中RX 要⾼于 TX 的⼀个原因。
- 我们接着进⼊软中断的回调函数 igb_poll。在这个函数⾥,我们注意到有⼀⾏igb_clean_tx_irq
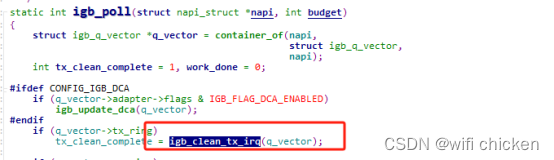
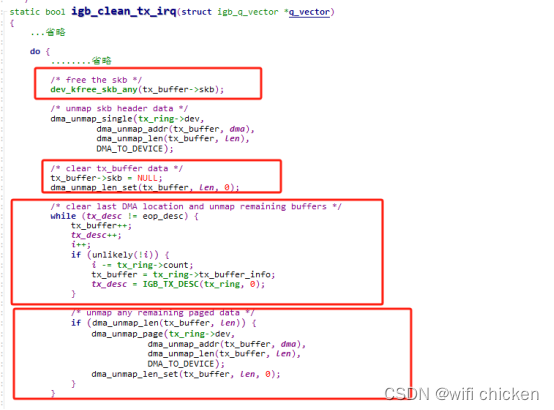
- 清理skb,解除了 DMA 映射等等。 到了这⼀步,传输才算是基本完成了。
- 为啥我说是基本完成,⽽不是全部完成了呢?因为传输层需要保证可靠性,所以 skb 其实还没有删除。它得等收到对⽅的 ACK 之后才会真正删除,那个时候才算是彻底的发送完毕。
疑问
我们在监控内核发送数据消耗的 CPU 时,是应该看 sy 还是 si ?
- 在⽹络包的发送过程中,⽤户进程(在内核态)完成了绝⼤部分的⼯作,甚⾄连调⽤驱动的事情都⼲了。 只有当内核态进程被切⾛前才会发起软中断。发送过程中,绝⼤部分(90%)以上的开销都是在⽤户进程内核态消耗掉的。只有⼀少部分情况下才会触发软中断(NET_TX 类型),由软中断ksoftirqd 内核进程来发送。
- 所以,在监控⽹络 IO 对服务器造成的 CPU 开销的时候,不能仅仅只看 si,⽽是应该把 si、sy都考虑进来
查看 /proc/softirqs,为什么 NET_RX 要⽐ NET_TX ⼤的多的多?
- 第⼀个原因是当数据发送完成以后,通过硬中断的⽅式来通知驱动发送完毕。但是硬中断⽆论是有数据接收,还是对于发送完毕,触发的软中断都是NET_RX_SOFTIRQ,⽽并不是NET_TX_SOFTIRQ。
- 第⼆个原因是对于读来说,都是要经过 NET_RX 软中断的,都⾛ ksoftirqd 内核进程。⽽对于发送来说,绝⼤部分⼯作都是在⽤户进程内核态处理了,只有系统态配额⽤尽才会发出NET_TX,让软中断上。综上两个原因,那么在机器上查看 NET_RX ⽐ NET_TX
发送⽹络数据的时候都涉及到哪些内存拷⻉?(这⾥内存拷⻉,我们特指待发送数据的内存拷⻉)
- 第⼀次拷⻉操作是内核申请完 skb 之后,这时候会将⽤户传递进来的 buffer ⾥的数据内容都拷⻉到 skb中。如果要发送的数据量⽐较⼤的话,这个拷⻉操作开销还是不⼩的。
- 第⼆次拷⻉操作是从传输层进⼊⽹络层的时候,每⼀个 skb 都会被克隆⼀个新的副本出来。⽹络层以及下⾯的驱动、软中断等组件在发送完成的时候会将这个副本删除。传输层保存着原始的 skb,在当⽹络对⽅没有 ack 的时候,还可以重新发送,以实现 TCP 中要求的可靠传输。
- 第三次拷⻉不是必须的,只有当 IP 层发现 skb ⼤于 MTU 时才需要进⾏。会再申请额外的skb,并将原来的 skb 拷⻉为多个⼩的 skb。
注意:在⽹络性能优化中经常听到的零拷⻉,有夸张的成分。TCP 为了保证可靠性,第⼆次的拷⻉根本就没法省。如果包再⼤于 MTU 的话,分⽚时的拷⻉同样也避免不了。