目录
前言
进程间通信的基本概念
管道
匿名管道
pipe函数
cfc
管道的四种情况
管道的五种特征
进程池
ProcessPool.cpp:
Task.cpp:
前言
ubuntu系统的默认用户名不为root的解决方案(但是不建议):轻量应用服务器 常见问题-文档中心-腾讯云 (tencent.com)
进程间通信的基本概念
进程间通信目的:进程间也是需要协同的,比如数据传输、资源共享、通知事件、进程控制
进程间通信的前提:让不同进程看到同一份OS中的资源(一段内存)
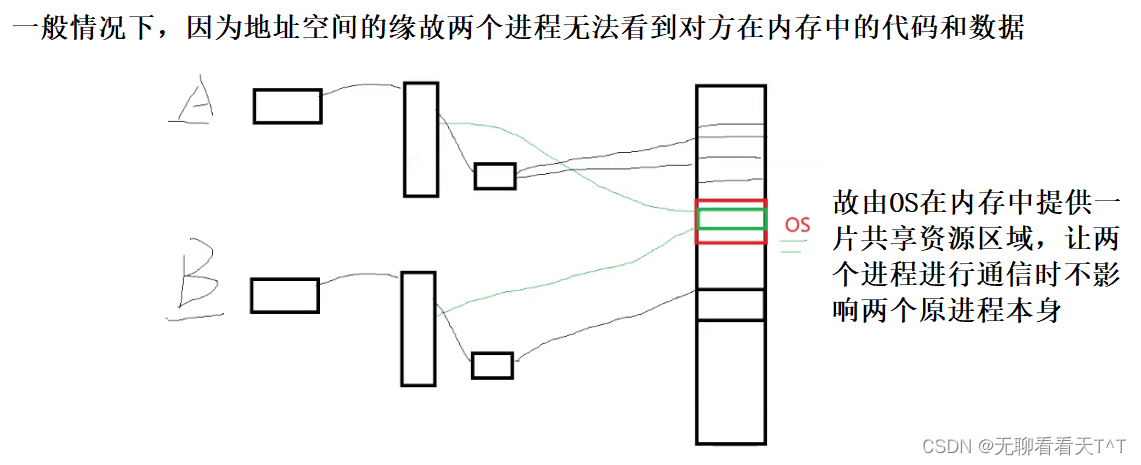
- 一定是某个进程提出了进程间通信的请求,OS才会创建一个共享资源
- 为了防止进程在通信时直接访问OS,OS会提供很多系统调用接口
- OS创建的共享资源的不同 + OS提供的系统调用接口的不同 = 进程间通信会有不同的种类
注意事项:
1、进程间能通信不等于能一直通信,fork函数子进程继承父进程不属于进程间通信
2、进程间通信的成本可能会稍微高一点
进程间通信依赖的标准:system V标准(主要用于本地通信) 和posix标准
system V标准规定的三种进程间通信的方案:消息队列、共享内存、信号量
管道
基本概念:System V 标准中提供了多种 IPC 机制,如消息队列、共享内存和信号量,但是使用这些 IPC 机制需要考虑很多细节问题(例如缓冲区大小、同步与互斥等),并且需要编写复杂的代码来实现,而管道只需一条简单命令即可创建,并且它们支持两个相关联地运行在同一系统上地程序之间互相传输信息(管道是最初人们实现进程间通信的一种方式)

问题:为什么父子进程会向同一个显示器终端打印数据?
解释:进行写操作时,父子进程都会向同一个内核级文件缓冲区中写入(内核级文件缓冲区不属于任何文件)当操作系统定期刷新时会将该缓冲区中的内容刷新到指定的文件中(在这里就是显示器文件)
问题:进程怎么做到默认打开三个标准流0、1、2?
解释:因为所有的进程都是bash的子进程,当bash打开(指向这三个流的文件,具体细节不再描述)了,bash的子进程也就打开了
问题:为什么子进程主动close(0或1或2)不影响父进程继续使用显示器文件呢?
解释:struct file中存在一个内存级的引用计数,父子进程同时指向一个struct file则该引用计数为2,close子进程的某个标准流文件时,只会将该引用计数减一,父进程依然可以访问(file - > ref_count--; if(ref_count == 0)才会释放文件资源)
问题:什么是管道文件?
解释:内核级文件缓冲区(重新设计后的) + struct file,父子进程一个负责向内核级文件缓冲区中写,另一个读取内核级文件缓冲区中的内容就形成了进程间通信的定义(让不同的进程看到同一份OS中的资源,文件系统也属于OS),此外为了保证父子进程间通信的合理性,管道文件只允许单向通信,同时读取会发生数据紊乱

补充:为了提高进程间通信的效率,避免写入文件缓冲区后还要向磁盘文件中刷新,所以OS设计者基于原来内核级文件缓冲区的代码,在OS中重新设计了一个不需要向磁盘中定时刷新的内核级文件缓冲区
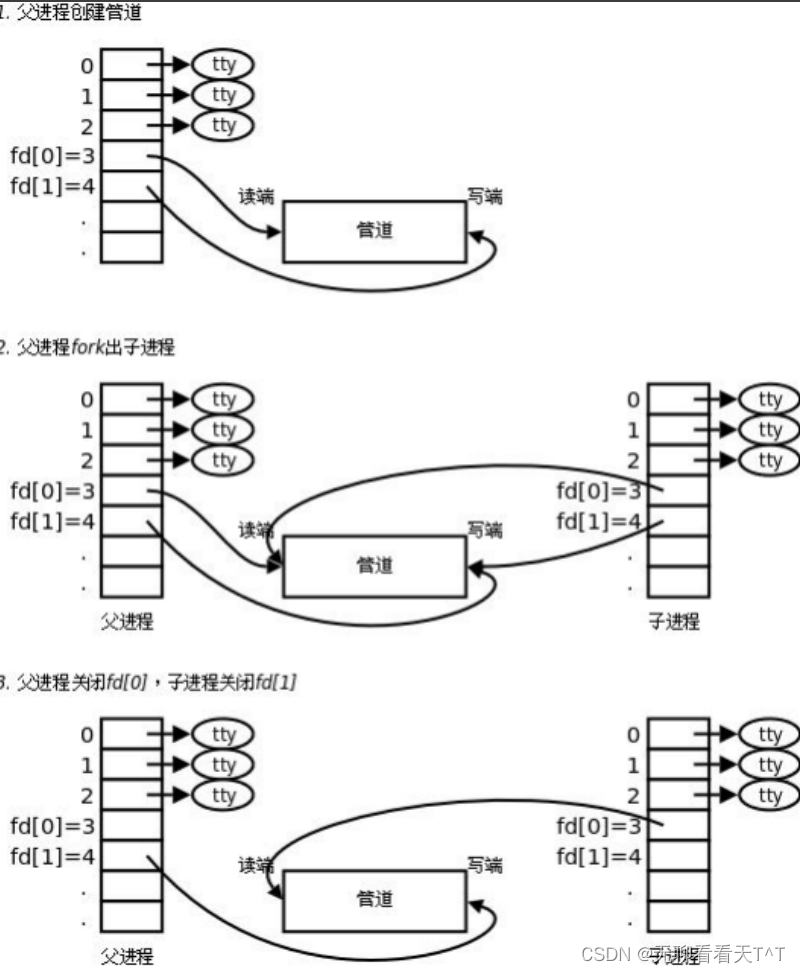
问题:如何实现父进程读文件,子进程写文件?
解释:父进程仍然打开3号文件描述符close(4),子进程仍然打开4号文件描述符close(3)

问题:父子既然要关闭不需要的fd,为何之前还要打开?可以不关闭吗?
解释:①为了让子进程继承,通过继承后不用了再关闭的这种方式形成的进程间通信是由设计者深思熟虑后的结果(父进程只打开一个3后续子进程还要再关闭3再打开4,还不如父子进程都打开3和4按照实际情况再进行关闭,前者也可以但是后者更简单)②可以不关闭但是可能会造成父子进程同时写入,所以建议关闭,同时由于存放文件描述符的是一个数组,数组是有大小范围的,所以如果为了保证通信的单向性子进程让某个文件描述符空闲,如果还有其它情况造成的文件描述符在数组中处于空闲状态,就会造成文件描述符泄漏
匿名管道
pipe函数
函数原型:int pipe(int pipefd[2]);
包含头文件:<unistd.h>
参数:输出型参数,是一个由两个整数构成的数组,第一个元素表示读端的文件描述符,第二个元素表示写端的文件描述符,写端和读端的文件描述符由OS自行填写
返回值:调用成功返回0,否则返回-1
功能:在OS中创建一个用于进程间通信的没有名字的内核级文件缓冲区,即匿名管道
注意事项:
1、pipe函数的底层是open函数,只不过这里不需要提供文件路径、文件名以及初始权限
2、如果想要双向通信可以使用两个管道
3、将pipe创建的内核级文件缓冲区叫做管道,是因为它在本质上还是一个内核级文件缓冲区,只不过正常情况下一个进程对文件进行写的时候就是写入内核级文件缓冲区然后由OS负责定时刷新到管道,而新建的缓冲区不会向磁盘中刷新而是刷新给进程,刷新的目的地改变了,只需将原来内核级文件缓冲区的代码稍加更改就可以实现这一功能,并且“一进一出”还符合我们日常生活中对管道的理解
cfc
1、进程进程间通信是有成本的,需要做准备工作:
//2、创建子进程
pid_t id = fork();
if(id == 0)
{
//子进程---写端
//3、关闭不需要的fd
close(pipefd[0]);
close(pipefd[1]);//完成通信后也将子进程的写端关闭
exit(0);
}
//父进程---读端
close(pipefd[1]);
close(pipefd[0]); // 完成通信后也将子进程的读端关闭2、进程间通信:
#include <iostream>
#include <unistd.h>
#include <cerrno> //c++版本的errno.h
#include <cstring> //c++版本的string.h
#include <sys/wait.h>
#include <sys/types.h>
#include <string>
// 携带发送的信息
std::string getOtherMessage()
{
// 获取要返回的信息
static int cnt = 0; // 计数器
std::string messageid = std::to_string(cnt);
cnt++; // 每使用一次计数器就++
pid_t self_id = getpid(); // 获取当前进程的pid
std::string stringpid = std::to_string(self_id);
std::string message = " my messageid is : ";
message += messageid;
message += " my pid is : ";
message += stringpid; // 逐渐向要传回的string字符串中追加要返回的信息
return message;
}
// 子进程进行写入
void ChildProcessWrite(int wfd)
{
std::string message = "father, I am your child process!";
while (true)
{
std::string info = message + getOtherMessage(); // 子进程尝试向父进程传递的所有信息
write(wfd, info.c_str(), info.size()); // write函数传入的字符串需要是c语言格式的,c_str将string字符串变为c语言格式的字符串
sleep(1); // 让子进程写慢一点,这样父进程就不会一直读并打印在显示器上
} // write是由操作系统提供的接口,而操作系统又是C语言编写的,所以后续学习中可能会碰到c语言的接口和c++的接口混合使用的情况
} // info最后有/0但是文件不需要
const int size = 1024; // 定义父进程可以读取的数组大小
// 父进程进行读取
void FatherProcessRead(int rfd)
{
char inbuffer[size]; // 普通的c99标准不支持变长数组,但是这里使用的是gnb的c99标准,gun的c99标准支持变长数组
while (true)
{
ssize_t n = read(rfd, inbuffer, sizeof(inbuffer)); // 因为文件不需要\0,所以读取管道中内容到缓冲区时可以少读取一个并将/0变为0
if (n > 0)
{
inbuffer[n] = 0;
std::cout << "父进程获取的消息: " << inbuffer << std::endl;
}
}
}
int main()
{
// 1、创建管道
int pipefd[2];
int n = pipe(pipefd); // 输出型参数,rfd,wfd
if (n != 0)
{
std::cerr << "errno" << errno << ":" << "errstring" << strerror(errno) << std::endl;
return 1;
}
// pipefd[0]即读端fd,pipefd[1]即写端fd
std::cout << "pipefd[0] = " << pipefd[0] << ", pipefd[1] = " << pipefd[1] << std::endl;
sleep(1); // 便于看到管道创建成功
// 2、创建子进程
pid_t id = fork();
if (id == 0)
{
std::cout << "子进程关闭不需要的fd,准备发消息了" << std::endl;
sleep(1); // 便于感受到发消息的过程
// 子进程---写端
// 3、关闭不需要的fd
close(pipefd[0]);
ChildProcessWrite(pipefd[1]); // 子进程的写函数
close(pipefd[1]); // 完成通信后也将子进程的写端关闭
exit(0);
}
std::cout << "发进程关闭不需要的fd,准备收消息了" << std::endl;
sleep(1); // 便于感受到收消息的过程
// 父进程---读端
close(pipefd[1]);
FatherProcessRead(pipefd[0]); // 父进程的读函数
close(pipefd[0]); // 完成通信后也将子进程的读端关闭
pid_t rid = waitpid(id, nullptr, 0);
if (rid > 0)
{
std::cout << "wait child process done" << std::endl;
}
return 0;
}
结论:因为可以用write和read读取管道,所以管道也是文件
管道的四种情况
1、如果管道内部为空,不具备读取条件,读进程会被阻塞(wait)等到管道不为空时才会读取
2、管道被写满 && rfd不关闭也不读取:此时管道会被写满,写进程会被阻塞,等到管道不为满时才会继续写入
3、管道一直在读 && wfd关闭:读端read函数的返回值最后为0,表示读取到了文件结尾
4、rfd直接关闭 && 写端一直入:写端进程会被OS直接用13号信号杀掉(OS判断出进程异常)
管道的五种特征
1、对于匿名管道:只能用来进行具有“血缘关系”的进程间的通信,但常用于父子进程间通信
2、管道内部自带进程之间的同步机制(子进程写一条写父进程读一条(但也不绝对),管道在实现时内部做了保护,不会出现多进程同时访问共享资源导致的共享区数据不一致问题)
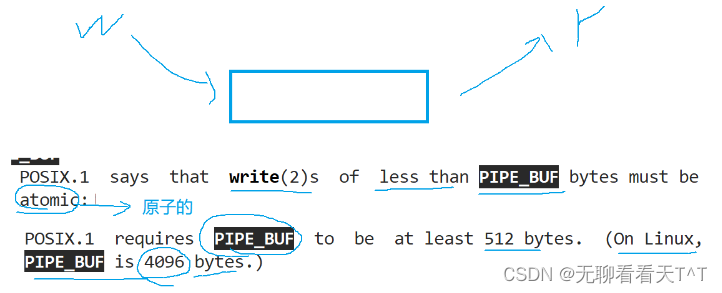
3、管道文件按的生命周期是随进程的
4、管道文件在通信的时候,是面向字节流的,读写次数不一定是一一匹配的(写十次一次一条,读一次一次读十条,水管一直流,但是可以选用不同的容器去接水)
5、管道的通信模式,是一种特殊的半双工模式(正常的半双工是双方都写入和接收,但同时只能有一个人写入另一个人负责接收,管道是永远只能有一个人进行写入另一个人进行接收)
进程池
产生原因:OS处理任务过多时,频繁的创建和销毁新的进程去执行这些任务会造成极大的资源浪费,OS不会做浪费资源的事情
基本概念:提前创建多个用于执行任务的子进程,当父进程派发任务时子进程去处理父进程的任务,处理完成后继续阻塞等待(这些进程组成了一个类似于“池子”的空间)
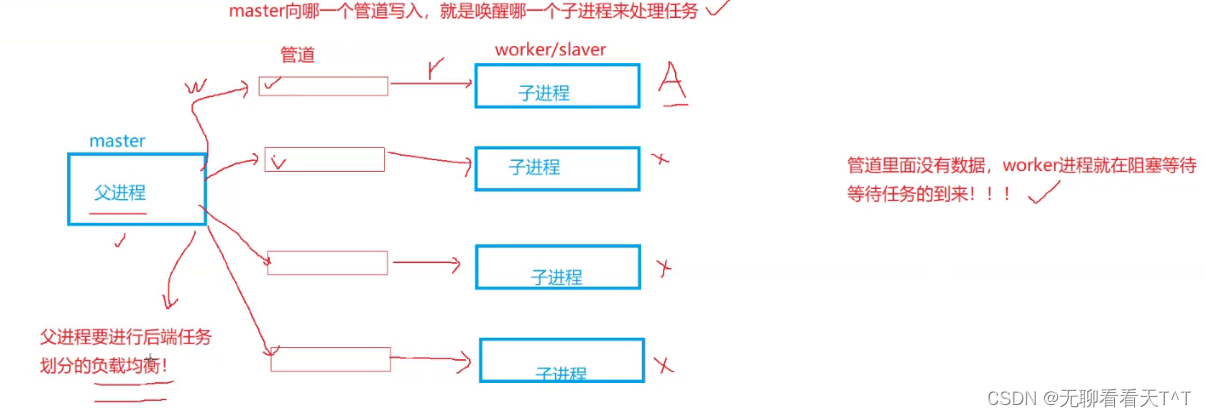
ProcessPool.cpp:
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "Task.hpp"
// 管道
class Channel
{
public:
Channel(int wfd, pid_t id, const std::string &name)
: _wfd(wfd), _subprocessid(id), _name(name)
{
}
~Channel()
{
}
// 获取写端的wfd、目标子进程的pid,当前管道名
int GetWfd() { return _wfd; }
pid_t GetProcessID() { return _subprocessid; }
std::string GetName() { return _name; }
void CloseChannel() // 关闭连接当前管道的wfd
{
std::cout << "关闭当前进程连接到管道的wfd: " << _wfd << std::endl;
close(_wfd);
}
void wait() // 子进程阻塞等待
{
pid_t rid = waitpid(_subprocessid, nullptr, 0); // (阻塞等待的子进程pid,指向子进程的退出信息(因为没有写就直接设置为空指针),选择阻塞等待的方式)返回值是阻塞成功的子进程的pid
if (rid > 0)
{
std::cout << "pid = " << rid << " 的子进程变为阻塞等待 " << std::endl; // 打印阻塞成功的子进程的pid
std::cout << std::endl;
}
}
private:
int _wfd;
pid_t _subprocessid;
std::string _name;
};
// 形参命名规范
// const & 修饰的应该是一个输入型参数
//& 修饰的应该是一个输入输出型参数
//* 修饰的应该是一个输出型参数
// 创建管道和进程池
void CreatChannelAndSub(int num, std::vector<Channel> *channels, task_t task) // task_t task是回调函数,当子进程执行fork时会去回调指定好的任务文件中的work函数,实现了任务文件和进程文件间的解耦
{
for (int i = 0; i < num; i++) // 循环创建子进程和对应的管道
{
// 1、创建管道
int pipefd[2] = {0}; // 存放读写端文件描述符的数组(该数组在每次循环时都重置)
int n = pipe(pipefd); // 每次循环时都由OS向数组中写入分配给新建管道的读端和写端的文件描述符(OS依据会fd的占用情况分配不同的fd给新的管道)
if (n < 0)
exit(1); // 创建管道失败进程退出
// 2、创建子进程
pid_t id = fork();
if (id == 0)
{
// 处理第二次创建管道时的子进程中还有指向第一个管道的rfd
if (!channels->empty()) // 管道数组不为空,即到了第二次创建管道时才会执行该判断语句
{
for (auto &channel : *channels) // 循环遍历之前的管道并拿到这些管道的rfd,然后关闭当前进程的这些rfd
{
channel.CloseChannel();
}
}
std::cout << std::endl;
sleep(5);
// 子进程
close(pipefd[1]); // 关闭子进程的wfd
// work(pipefd[0]); // 子进程等待并处理父进程派发的任务
// dup2(pipefd[0],0);//子进程不仅可以从管道中,还可以从标准输入中获取任务码
// work();//我们不给work传rfd就可以断绝子进程从管道中获取任务码,这样就进一步完成了管道和子进程间逻辑的解耦
dup2(pipefd[0], 0); // 子进程不仅可以从管道中,还可以从标准输入中获取任务码,这种方法使得子进程可以像处理标准输入一样处理来自管道的数据,从而提高了代码的通用性和可移植性。
task(); // 将work也视为一个任务
close(pipefd[0]); // 关闭子进程的rfd
exit(0); // 子进程退出
}
// 3、父进程构建管道名
std::string Channel_name = std::to_string(i) + "号 Channel"; // 每次循环i+1,管道名即为i号 Channel
close(pipefd[0]); // 关闭父进程的rfd
// 向数组中尾插管道
channels->push_back(Channel(pipefd[1], id, Channel_name)); // 会向当前管道写入父进程的wfd,当前管道对应的子进程pid,当前管道
}
}
// 检测进程池和管道是否创建成功
void TestForProcessPoolAndSub(std::vector<Channel> &channels)
{
std::cout << "=========================================================" << std::endl;
std::cout << " 管道名 " << " 管道对应的子进程pid " << " 会向当前管道写入的wfd " << std::endl;
for (auto &Channel : channels)
{
std::cout << " " << Channel.GetName() << " " << Channel.GetProcessID() << " " << Channel.GetWfd() << std::endl;
}
std::cout << "=========================================================" << std::endl;
}
// 获取一个管道下标(利用取模 + static变量 在0~channelnum间循环)(使得每个管道都会被使用到的轮询方案)
int NextChannel(int channelnum)
{
static int next = 0;
int index = next;
next++;
next %= channelnum;
return index;
}
// 发送任务
void SendTaskCommand(Channel &channels, int taskcommand) // 此时是向数组中的一个管道派发任务,所以形参应该是一个管道类类型的对象
{
write(channels.GetWfd(), &taskcommand, sizeof(taskcommand)); // 像指定的wfd中写入(OS会通过该wfd找到对应的管道,这里本质上就是向管道中写入),要写入的任务码,任务码的大小
} // 这里不是要截取任务码所存放地址的前四个字节,而是获取任务码本身,别搞错了
// 向子进程派发一次任务(也叫通过管道控制子进程,因为只要向某一个管道中派发任务后该管道对应的子进程就可以接收到该任务,二者的连接关系提前已经建立好了)
void CtrlProcessOnce(std::vector<Channel> &Channels)
{
sleep(1);
// 1、选择一个任务(获取一个任务码,本质是获取一个函数指针)
int taskcommand = SelectTask();
// 2、选择一个管道进行任务的派发
int channel_index = NextChannel(Channels.size());
// 3、发送任务
SendTaskCommand(Channels[channel_index], taskcommand); // 向指管道发送任务码,因为管道和子进程建立了关联,向管道中输入内容时子进程在自己的work函数中就会读取到管道中的任务码,然后子进程就会依据该任务码去执行相应的任务
std::cout << "分配的随机任务码为:" << taskcommand << " 派发给的管道名为: "
<< Channels[channel_index].GetName() << " 处理任务的子进程pid为: " << Channels[channel_index].GetProcessID() << std::endl;
}
// 向子进程派发任务
void CtrlProcess(std::vector<Channel> &Channels, int time = -1) // 默认一直向子进程派发任务
{
if (time > 0)
{
while (time--)
{
CtrlProcessOnce(Channels);
}
}
else
{
while (true)
{
CtrlProcessOnce(Channels);
}
}
}
// 回收管道和子进程(释放而不是等待)
void CleanUpChannelAndSubProcess(std::vector<Channel> &Channels)
{
for (auto &i : Channels)
{
i.CloseChannel(); // 先关闭写端wfd
i.wait(); // 然后让子进程阻塞等待
}
}
// 创建进有五个进程的进程池,在命令行中的命令行字符串是./processpool 5,一共有命令行字符串的数量应该为2时才能进行创建进程池
int main(int agrc, char *argv[])
{
if (agrc != 2) // 命令行参数不为2那么就报错并返回
{
std::cerr << "Usage: " << argv[0] << " processnum" << std::endl;
return 1;
}
int num = std::stoi(argv[1]); // 将argv数组中获取到的命令行字符串经stoi函数转为整型并赋值给num,num表示要进程池中子进程的个数
LoadTask(); // 加载任务
std::cout << "加载任务成功..." << std::endl;
std::vector<Channel> Channels; // 对管道的处理变成了对数组中Channels对象的增删查改
// 1、创建管道和进程池
CreatChannelAndSub(num, &Channels, work); // 规定子进程创价后会回调work函数
TestForProcessPoolAndSub(Channels); // 检测进程池和管道是否创建成功(到这里所有管道和子进程的连接关系已经建立完成)
std::cout << "创建并关联子进程与管道成功..." << std::endl;
std::cout << std::endl;
// 2、向子进程派发任务
CtrlProcess(Channels, 4);
sleep(2);
std::cout << "子进程处理任务成功..." << std::endl;
std::cout << std::endl;
// 3、回收管道和子进程
CleanUpChannelAndSubProcess(Channels);
std::cout << "回收管道和子进程成功.." << std::endl;
std::cout << std::endl;
return 0;
}Task.cpp:
/*
* @Author: error: error: git config user.name & please set dead value or install git && error: git config user.email & please set dead value or install git & please set dead value or install git
* @Date: 2024-05-10 21:01:58
* @LastEditors: error: error: git config user.name & please set dead value or install git && error: git config user.email & please set dead value or install git & please set dead value or install git
* @LastEditTime: 2024-05-12 10:20:05
* @FilePath: /2024.5.10/Task.hpp
* @Description: 这是默认设置,请设置`customMade`, 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
*/
#pragma once
#include <iostream>
#include <ctime>
#include <cstdlib> //c++风格的c语言的stdlib.h头文件
#include <sys/types.h>
#include <unistd.h>
#define TaskNum 3 // 定义要处理的任务类型个数
typedef void (*task_t)(); // task_t 函数指针类型(task_t是一个类型不是一个指针)
task_t tasks[TaskNum]; // 创建一个task_t函数指针类型的数组tasks,数组中存放的都是函数指针
// 打印任务
void Print()
{
std::cout << "I am a print task" << std::endl;
}
// 下载任务
void DownLoad()
{
std::cout << "I am a DownLoad task" << std::endl;
}
// 刷新任务
void Flush()
{
std::cout << "I am a Flush task" << std::endl;
}
// 加载任务(将任务放入函数指针数组中)
void LoadTask()
{
srand(time(nullptr) ^ getpid() ^ 17777); // 依据时间戳 与 当前进程的pid亦或的结果使得“种子”更加的随机,当然也可以再亦或上其它内容
tasks[0] = Print; // 第一个函数指针指向打印任务
tasks[1] = DownLoad; // 第二个函数指针指向下载任务
tasks[2] = Flush; // 第三个函数指针指向刷新任务
}
// 执行任务
void ExcuteTask(int number)
{
if (number < 0 || number > 2)
return;
tasks[number](); // 根据传入的任务码确定要调用的函数
}
// 选择任务码
int SelectTask()
{
return rand() % TaskNum; // 返回随机的任务码
}
// // 版本一:
// // 子进程处理派发的任务(子进程会从依据rfd从管道中拿到任务码)
// void work(int rfd)
// {
// // 子进程循环等待
// int i = 1;
// while (1)
// {
// int command = 0;
// int n = read(rfd, &command, sizeof(command)); // OS会依据rfd帮助子进程获取与它关联的管道中的内容
// if (n == sizeof(int))
// {
// std::cout << "pid = " << getpid() << " 的子进程正在执行任务" << std::endl;
// ExcuteTask(command); // 依据任务码执行任务
// std::cout << std::endl;
// }
// else if (n == 0) // 读端读取不到内容时结束子进程的work
// {
// std::cout << "pid = " << getpid() << " 的子进程读取不到内容了" << std::endl;
// break;
// }
// }
// }
// 版本二:
// 子进程的任务
void work()
{
// 子进程循环处理任务
int i = 1;
while (1)
{
int command = 0;
int n = read(0, &command, sizeof(command)); // OS会依据rfd帮助子进程获取与它关联的管道中的内容
std::cout << std::endl;
if (n == sizeof(int))
{
std::cout << "pid = " << getpid() << " 的子进程正在执行任务" << std::endl;
ExcuteTask(command); // 依据任务码执行任务
std::cout << std::endl;
sleep(1);
}
else if (n == 0) // 读端读取不到内容时结束子进程的work
{
std::cout << "pid = " << getpid() << " 的子进程读取不到内容了" << std::endl;
break;
}
}
}- 最后每次运行的示意图都会因使用的sellp或者进程的执行顺序等因素产生差异,可以自行尝试修改,作者懒得修改了
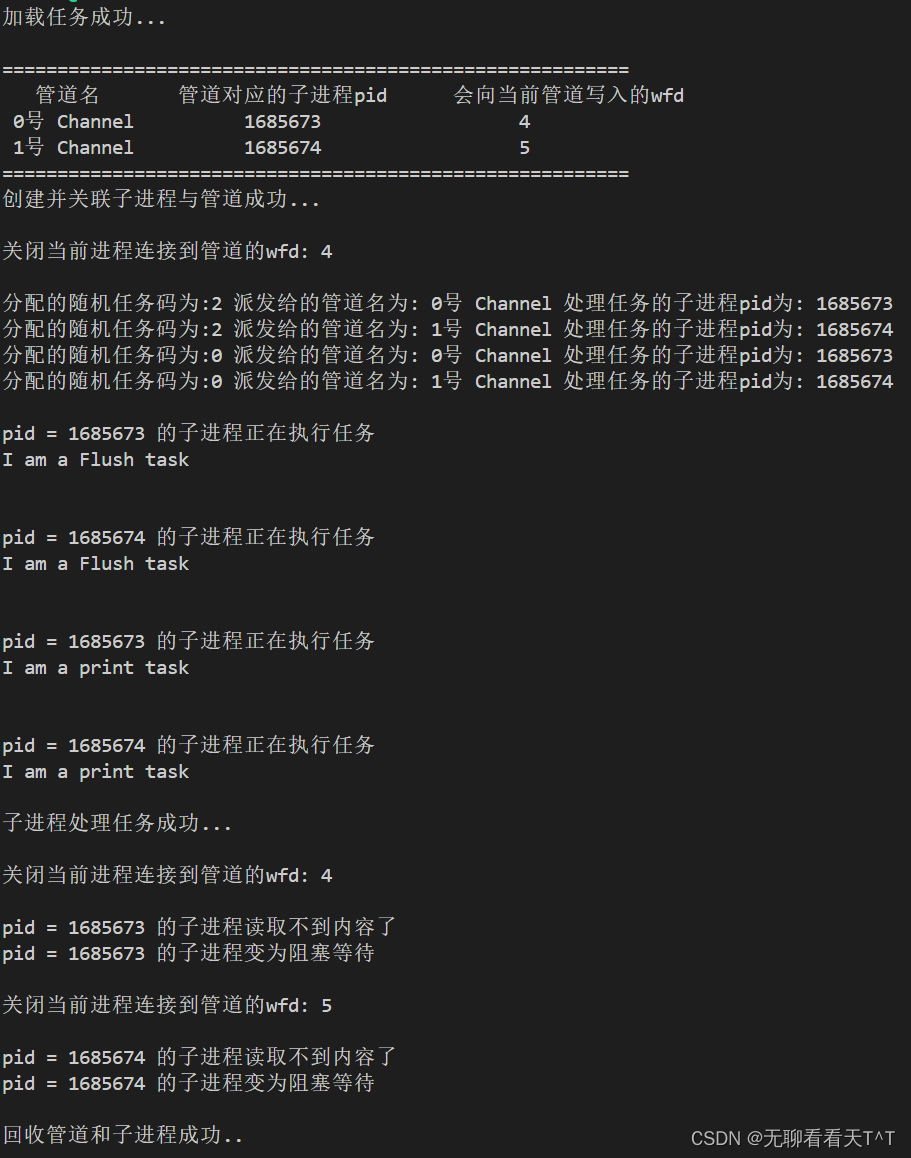
注意事项:子进程从管道中拿到的是一个任务码,后根据该任务码去寻找具体任务
这篇文章也很好可惜是Python的:http://t.csdnimg.cn/yerqf
rand、time和srand函数:http://t.csdnimg.cn/BK9g7
write、dup2和read函数:http://t.csdnimg.cn/a5xdS
waitpid函数:http://t.csdnimg.cn/pXPTb
~over~