【YOLOv8 注意事项】
1. YOLOv8 的官方仓库和代码已上线,文档教程网址也刚刚更新。
2. YOLOv8 代码集成在 ultralytics 项目中,目前看不会再单独创建叫做 YOLOv8 的项目。
3. YOLOv8 即将有论文了!要知道 YOLOv5 自从 2020 年发布以来,一直是没有论文的。而 YOLOv8(YOLOv5团队)这次首次承认将先发布 arXiv 版本的论文(目前还在火速撰写中)。
YOLOv8 代码链接:
GitHub - ultralytics/ultralytics: YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
权重链接:
Releases · ultralytics/assets · GitHub
YOLOv8 文档教程链接:
Ultralytics YOLOv8 Docs
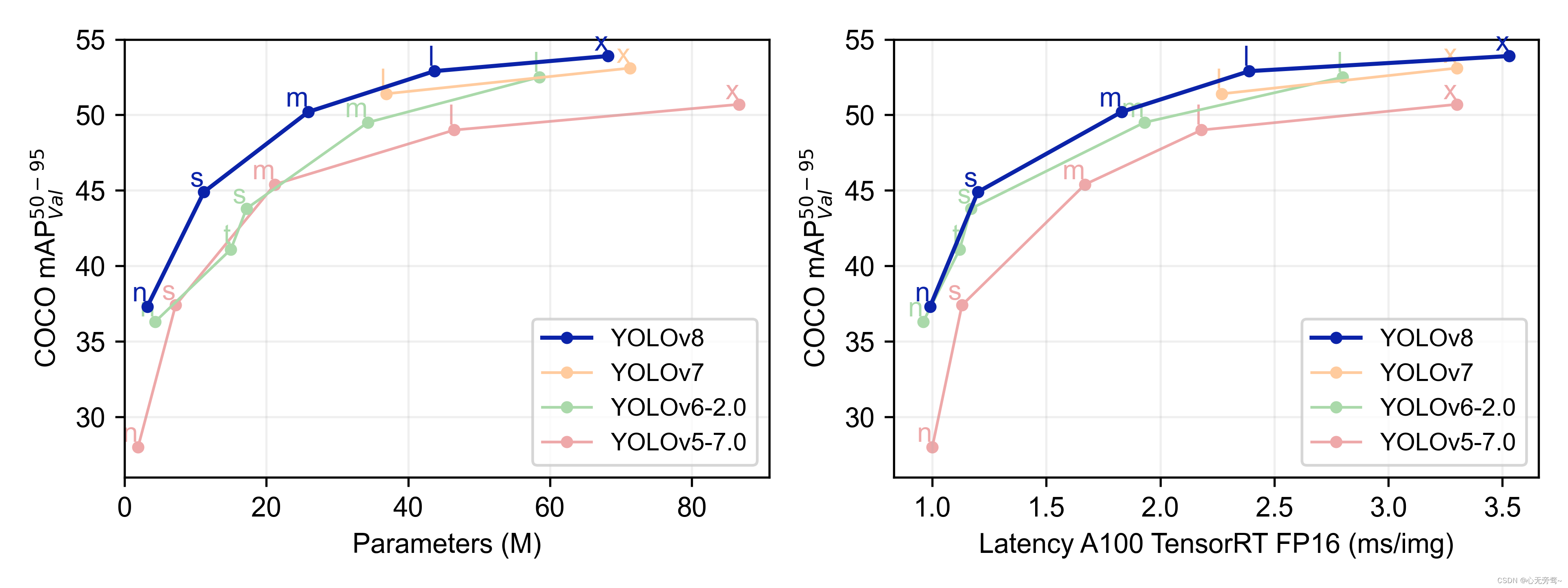
YOLOv8 官方放出了 YOLOv8 与 YOLOv7、YOLOv6 和 YOLOv5 的性能比较折线图,如下所示:
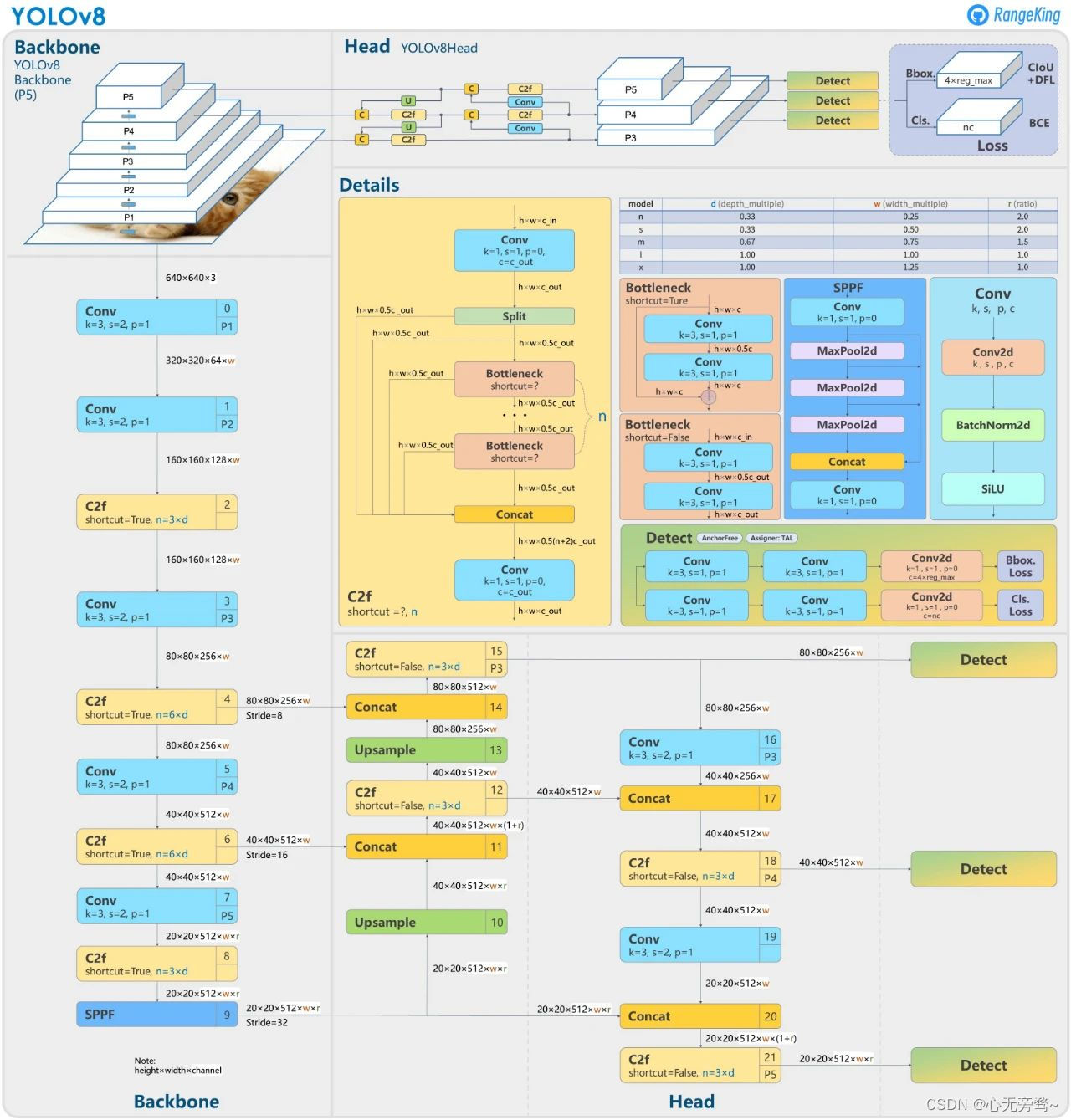
第三方(github作者:RangeKing )绘制的 YOLOv8 网络结构示意图,内容非常详细,还获得了 YOLOv8 官方的点赞认可,如下图所示:
这里分享一篇关于【YOLOv8精度速度初探和对比总结】的知乎文章,内容写的也非常好,有一些独特的见解,希望对大家有所帮助。
作者:迪迦奥特曼
YOLOv8精度速度初探和对比总结 - 知乎
前几天已经传开了 YOLOv8 即将发布,昨天 ultralytics 终于宣布开源了YOLOv8。
GitHub - ultralytics/ultralytics: YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
repo没有起名为YOLOv8,也没有合并在YOLOv5里,有网友问作者回复说要搞自己的大框架集合,不只是YOLO不只是检测。此外作者还说在写arxiv论文了,最大的那个表格估计现在一页也放不下了。YOLOv8 代码风格完善了很多,精度更是高出一大截直奔SOTA,那么是否宣告 YOLOv5 即将像YOLOv1 v2一样慢慢成为历史?YOLOv5又 是如何一步步改到YOLOv8的(仅指ultralytics的YOLOv5到YOLOv8)?
差异点总结:
前几天已经有很多解读了,这里再简单总结下YOLOv8相比YOLOv5的改动:
(1). Backbone:CSP是不变的思想,但是 v8 中选用了 C2f 模块替换 v5 的 C3 模块,每个stage的blocks数也改为了[3,6,6,3]而不是[3,6,9,3],此外x版本的depth因子仍然为1.0和L版本一样而不是常规的1.33,明显是为了轻量化。stem卷积在v8里是k=3的卷积而不是k=6的了,而最后的SPPF模块v8还是照搬沿用v5的;
(2). Neck:除了同样是 C2f 模块替换 C3 模块外,v8还将v5中 PAN-FPN 的top down上采样阶段中的卷积直接删除了;
(3). Head:Decoupled-Head,和yolov6 ppyoloe的head类似,除了cls reg两个branch外还有一个projection conv,是为 DFL 用的,不同于v6 ppyoloe的是reg_max没有加1;
(4). Label Assign:v8终于还是使用了Anchor-Free,TaskAlignedAssigner(TAL)动态匹配的方式也是和v6 ppyoloe很相似的,但topk alpha参数略有不同,v8也没有ATSS静态匹配阶段;
(5). Loss:v8的分类loss还是使用的BCE,虽然也写了VFL(varifocal_loss)但是注释了没用上,回归loss是DFL Loss+CIoU Loss,loss_weight的设置也和v6 ppyoloe略有区别;
总的来看,最大的改动就是Anchor Base换成Anchor Free了,主要就是TOOD的思想,也参考了一些v6 ppyoloe的代码。
关于精度:
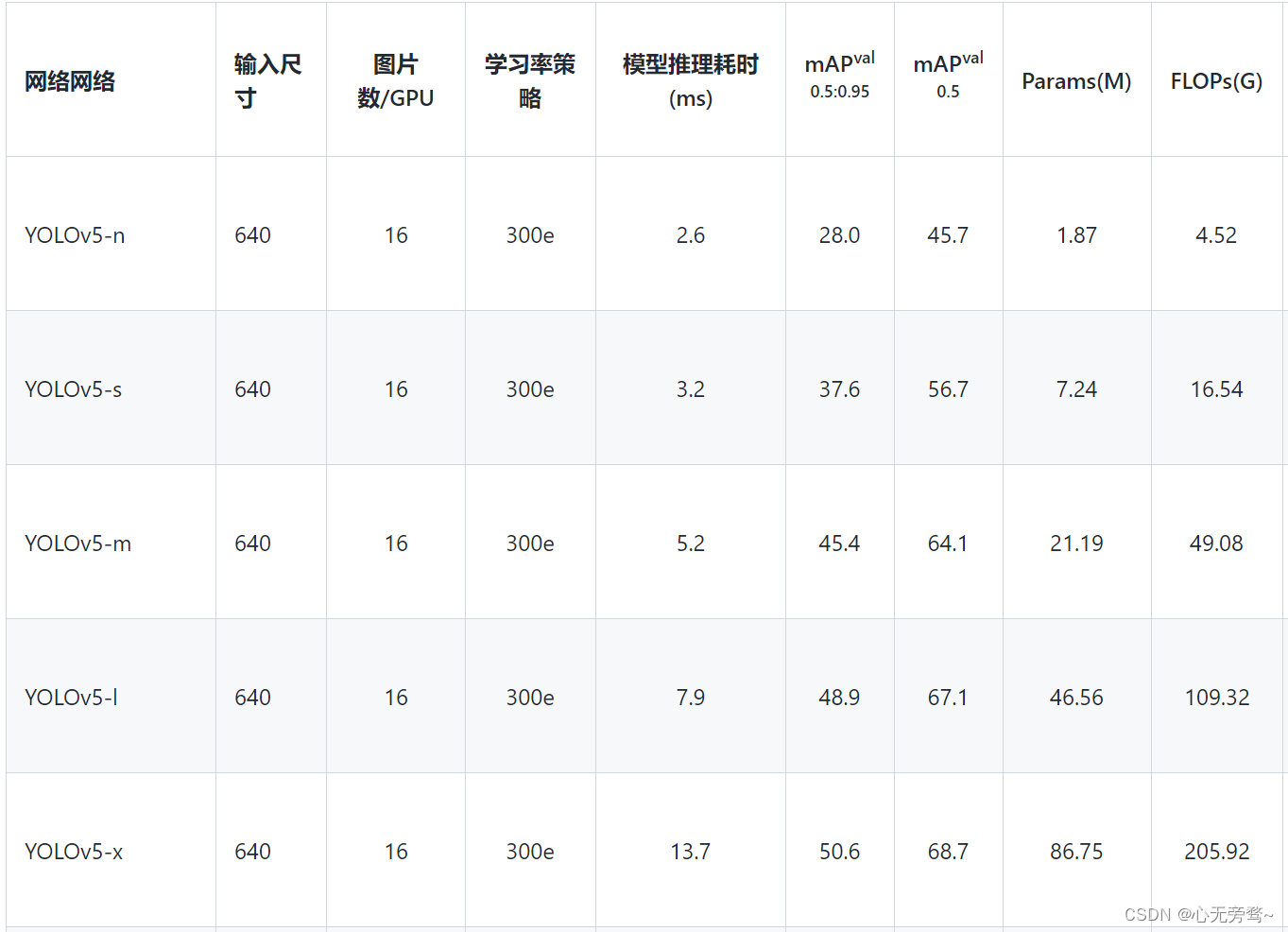
首先还是直接看下YOLOv5和YOLOv8的精度对比,可以看出同级别模型YOLOv8至少高出3个多点,nano版本更是高出9.3。参数量FLOPs上YOLOv8不可避免的增加了些,然后l x版本参数量少了点。
| Model | size (pixels) | mAPval 50-95 | mAPval 50 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
YOLOv5基本模型
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
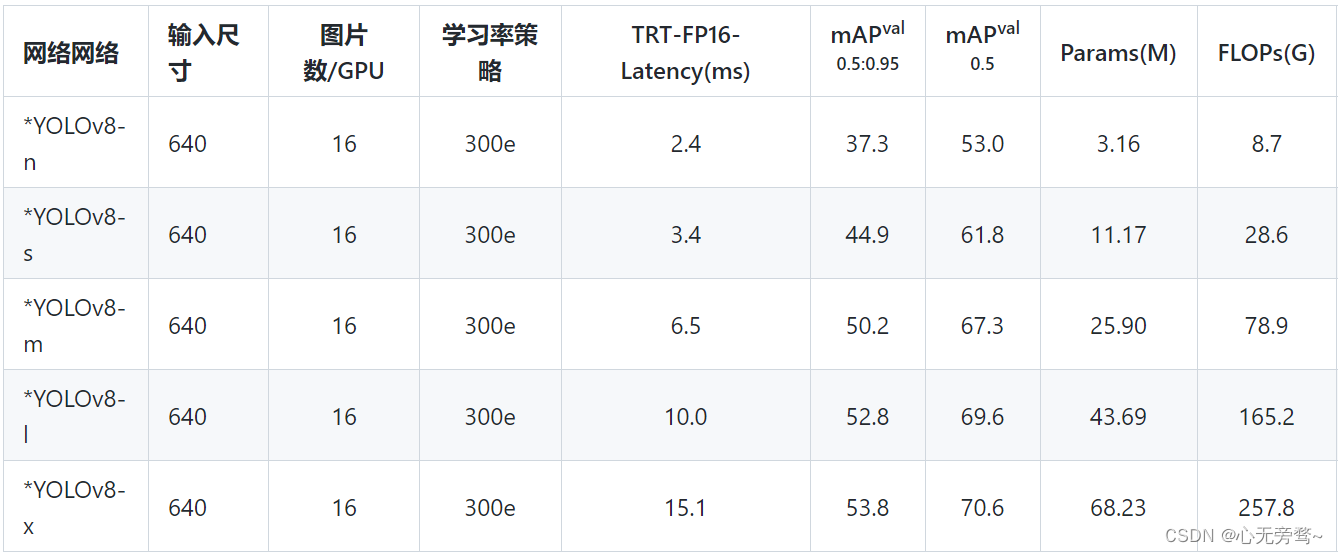
YOLOv8基本模型
关于模型结构:
参数量FLOPs不可避免增加,n s m上已经有点明显了,但l x版本参数量反而减小了很多,我觉得主要还是减少了东西导致的,比如Backbone每个stage的输出的通道数只有 n/s 和YOLOv5的n/s相同,m/l/x 最后一个stage都缩减了很多,再配合最大的stage的blocks数也减少了,以及FPN去除了top-down上采样卷积,x版本的depth因子仍然为1.0而不是常规的1.33,所以YOLOv8各个模型尤其是大模型上参数量减小了,而小模型上增加的也不太多。
同时带来的一个问题也是设计上的不统一了,包括v6 damo-yolo都是大小模型各一套backbone,v7的设计个版本就更没有章法了。一套模型X L M S T N只改depth width因子是最理想状态,但是估计这些新的YOLO的作者往往发现和竞品对比时某一个版本稍弱或优势没那么大,于是就针对它调,效果是跳上去了,但是每个版本差别也越来越大,换版本的时候不能只是改下depth width因子了,各自调优稍显刻意了点。
关于Assign和Loss:
其实主要还是TOOD的思想,这个文章介绍的比较详细了 【YOLOv6、PP-YOLOE、PicoDet为什么都选择了TOOD?】,总结下来就是分类和回归任务具有较高一致性。但是v8分类loss目前还是使用的BCE,不知道使用VFL的时候精度如何,至于IoU loss可能也已经排列组合尝试过了采用了CIoU,loss_weight也调大了iou loss的比例。v8的Assign是全程采用TAL ,没有静态匹配ATSS,其实看v6的最新代码里也逐渐去除了ATSS阶段,而PPYOLOE里还是保留着约前1/3 阶段ATSS+后期TAL的设置。本人之前训TOOD也跳过ATSS和TAL的epoch数,ATSS静态匹配确实稍显生硬,但对于较简单的数据集还是挺有用。全程TAL对于遮挡多较难的数据集更合适。
关于训练细节:
几个综合YOLO的集合代码库已经火速安排上了复现的PR,比如MMYOLO和PaddleYOLO,今早看到了PaddleYOLO 里已经率先支持了YOLOv8的inference和部署速度。
具体训练可能都还得等的官方先公布完全吧。包括训练epoch数和预训练权重,这个已经在issue中有人问到了,这是对训练精度影响最大的两个方面,现在各个YOLO也已经很难做到公平对比了,以前还默认都是300epoch下640单尺度eval精度,所以后面的YOLO纷纷使用了1280尺度、加P6层、obj365预训练、自蒸馏、大蒸小蒸馏等外挂拼命往上刷,现在则是只剩下640单尺度eval精度。
关于部署和速度:
之前我的T4机器上就测过PaddleYOLO里的ppyoloe和v5 v7的速度对比,这下正好也直接验证了下v8的几个权重onnx的速度。最基础的测速,是640*640尺度下去nms bs=1的trt测速,各家YOLO发布时这个也是必测必写的,其实换算到FPS更直观点,但是FPS波动太大,多打20都有可能,而毫秒耗时则最多差个0.2ms。
看到PaddleYOLO 里yolov8表格的TRT-FP16-Latency的数据,发现和yolov5比小模型上速度比较接近,但大模型m l x上则变慢了不少,精度的巨大提升也牺牲了速度,这也可能是之前讨论的m l x比yolov5缩减了backbone的模块和通道数有关吧。理论上看模型结构改动尤其是head加大了很多,的确可能变慢的,具体等v8公布速度数据再看看(目前已公布速度数据,如上面图所示)。
YOLOv5
YOLOv8
PaddleYOLO 的modelzoo页面可以直观的看到几乎所有YOLO的精度速度对比,虽然是paddle框架但都是同一T4 GPU环境下册的还算是可以参考的:
PaddleYOLO/MODEL_ZOO_cn.md at release/2.5 · PaddlePaddle/PaddleYOLO · GitHub
当然也期待yolov8论文中的超级大表格,那样会更直观。
star数是唯一评价标准吗
v8开源一天已经吸引了600多star数(截止2023年1月12日晚,已经1.3k star),热度非凡,最后想再稍微讨论下这个,一般来说大家首先都是看的star数去评价,但这个其实往往都是可以通过营销宣传来涨的,现在很多自媒体平台也极大的方便了传播,此外fork数基本都是被忽略的。yolov5代码普遍反应写的可读性极差不规范,但是他的star数就是一路飙升直至超过了mmdet和detectron2做到了检测领域第一,主要还是维护和生态应用做的好,此外forks数也有12.5k可见其影响力和使用范围。
我觉得还是需要看全面看待star fork等,一个代码库刚放出来的时候star肯定是暴涨的,当然也是配合着宣传营销,这个和新事物疯狂点收藏的一个道理。但是放出来一段时间后,star数的增长趋于平稳,这个时候其实可以关注下star/fork 比,一般来说在3~7的都算正常,10左右的基本上还是营销宣传PR一直在发力。起名呢也是个学问,只要起名直接叫yolov9 v10保准可以吸足流量,正如v5 v6 v7当初带动的一波又一波流量一样,但是我是觉得起名还得问问最初YOLO作者团队的同意,以示尊重经典。各大YOLO都还在继续保持着创新和更新,可以期待下yolov9 v10,不过不需要盲目就换模型,还是得大致了解下改进点和优劣势后再谨慎选择。
引用参考
[1].GitHub - ultralytics/ultralytics: YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
[2]. GitHub - PaddlePaddle/PaddleYOLO: 🚀🚀🚀 YOLO series of PaddlePaddle implementation, PPYOLOE, YOLOX, YOLOv5, YOLOv6, YOLOv7, YOLOv8, RTMDet and so on. 🚀🚀🚀
[3] YOLOv8精度速度初探和对比总结 - 知乎 (zhihu.com)






![[有人@你]请查收你的年终总结报告](https://img-blog.csdnimg.cn/04c0ab15cc474ade804e2a524c4ce92d.png)