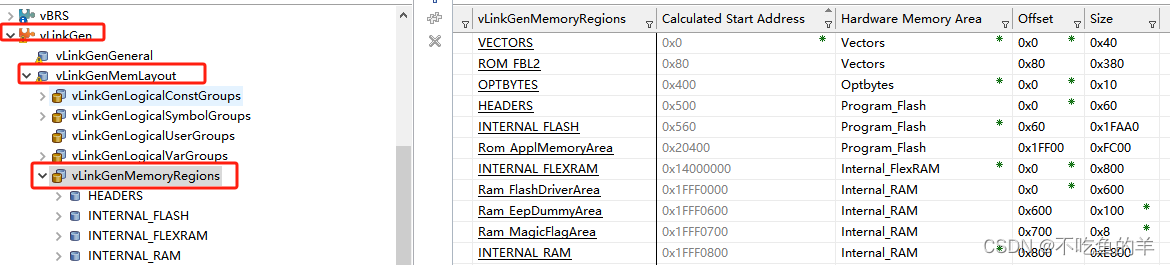
Building semantic search with SentenceTransformers on AMD — ROCm Blogs
这篇博客解释了如何在Sentence Compression数据集上训练SentenceTransformers模型来执行语义搜索。使用BERT基础模型(不区分大小写)作为基础的变换器,并应用Hugging Face的PyTorch库。
训练这个自定义模型的目标是将其用于执行语义搜索。语义搜索是一种信息检索方法,它理解搜索查询的意图和上下文,而不仅仅是匹配关键词。例如,搜索“苹果派食谱”(查询)将返回关于如何制作苹果派的结果(文档),而不仅仅是包含“苹果”和“派”这些词的页面。
可以在这个[GitHub文件夹](https://github.com/ROCm/rocm-blogs/tree/release/blogs/artificial-intelligence/sentence_transformers_amd/)中找到与这篇博客文章相关的文件。

介绍SentenceTransformers
从头开始训练一个SentenceTransformers模型包括一个过程,即教导模型理解和编码句子为有意义的、高维度的向量。在这篇博客中,专注于一个包含等价句子对的数据集。总的来说,培训过程的目标是让模型学习如何将语义上相似的句子映射在向量空间中的接近位置,同时将不相似的句子分隔开。与可能无法捕获某些领域或用例的特定性质的通用预训练模型相比,自定义训练模型确保模型能够精确调整以理解与特定领域或应用相关的上下文和语义。
感兴趣的是执行非对称语义搜索。在这种方法中,模型承认查询和文档本质上可以是不同的。例如,具有简短查询和长文档。非对称语义搜索使用编码,使搜索更加有效,即使在文本类型或长度不匹配时也是如此。这对于信息从大型文档或数据库检索的应用非常有用,其中查询通常比他们搜索的内容更短且不那么详细。这里有一个语义搜索如何工作的例子:
查询:巴黎位于法国吗?
语料库中最相似的句子:
法国的首都是巴黎(得分:0.6829)
巴黎是欧洲的一个城市,有着传统和杰出的食物,是法国的首都(得分:0.6044)
澳大利亚以其传统和杰出的食物而闻名(得分:-0.0159)
基于AMD GPU的实现
案例在Ubuntu 22.04.3 LTS系统ROCm 6.0.2和PyTorch 2.3.0版本进行。
$ python
Python 3.12.1 | packaged by Anaconda, Inc. | (main, Jan 19 2024, 15:51:05) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'2.3.0+rocm6.0'
安装以下Python包:
pip install datasets ipywidgets -U transformers sentence-transformers从HF-Mirror - Huggingface 镜像站下载Sentence Compression 数据集:
./hfd.sh embedding-data/sentence-compression --dataset --tool aria2c -x 4句子压缩(Sentence Compression)数据集包含18万对等价句子。这些句子对演示了如何把较长的句子压缩成较短的句子,同时保持相同的含义。
导入Python包
from datasets import load_dataset # 从datasets库中导入load_dataset方法
from sentence_transformers import InputExample, util # 从sentence_transformers库中导入InputExample和util模块
from torch.utils.data import DataLoader # 从torch库中导入DataLoader类
from torch import nn # 从torch库中导入神经网络相关模块
from sentence_transformers import losses # 从sentence_transformers库中导入losses模块
from sentence_transformers import SentenceTransformer, models # 从sentence_transformers库中导入SentenceTransformer和models模块准备数据集:
dataset_id = "./sentence-compression"
dataset = load_dataset(dataset_id)查看数据集中的一个样本:
# 查看一个样本
print(dataset['train']['set'][1])
['Major League Baseball Commissioner Bud Selig will be speaking at St. Norbert College next month.',
'Bud Selig to speak at St. Norbert College']SentenceTransformers库要求数据集需要有特定的格式,确保数据与模型架构兼容。
创建训练样本的列表(使用数据集的一半来进行说明)。这种方法减少了计算负载并加速了训练过程。
# 转换数据集为所需格式
train_examples = []
train_data = dataset['train']['set']
n_examples = dataset['train'].num_rows // 2 # 选择一半的数据集进行训练
for example in train_data[:n_examples]:
original_sentence = example[0]
compressed_sentence = example[1]
input_example = InputExample(texts=[original_sentence, compressed_sentence])
train_examples.append(input_example)实例化`DataLoader`类。这个类为提供了一个有效地迭代数据集的方式。
# 使用训练样本实例化DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)实现
在句子转换器模型中,目的是将不定长的输入句子映射为一个固定大小的向量。首先,将输入句子传递给一个转换模型。在这个例子中,使用了BERT基础模型(不区分大小写版本)作为基础转换模型,它会输出输入句子中每个词的上下文化嵌入向量。获取到每个词的嵌入向量后,使用汇聚层(Pooling layer)来将这些向量整合为一个单独的句子嵌入向量。最后,通过添加一个全连接层(具有双曲正切激活函数的dense层)进行额外的变换。这个层的作用是降低汇聚后的句子嵌入向量的维度,同时使用非线性激活函数让模型能够捕捉数据中更复杂的模式。
# 创建一个自定义模型
# 使用一个已存在的嵌入模型
word_embedding_model = models.Transformer('bert-base-uncased', max_seq_length=256)
# 对token嵌入向量使用汇聚函数
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
# 全连接层
dense_model = models.Dense(in_features=pooling_model.get_sentence_embedding_dimension(), out_features=256, activation_function=nn.Tanh())
# 定义整体模型
model = SentenceTransformer(modules=[word_embedding_model, pooling_model, dense_model])训练
在训练过程中,选择合适的损失函数是至关重要的,这取决于具体应用和数据集的结构。在这里,使用了`MultipleNegativesRankingLoss`函数。这个函数在句子的语义搜索应用中特别有用,因为模型需要根据句子的相关性对其进行排序。它的工作方式是将一对语义相似的句子(正例对)与多个语义不相似的句子进行对比。这个函数非常适合句子压缩数据集,因为它能够区分语义相似和不相似的句子。
# 鉴于有等效句子对的数据集,选择MultipleNegativesRankingLoss
train_loss = losses.MultipleNegativesRankingLoss(model = model)
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs = 5)推理
评估这个模型。
# 从 sentence_transformers 导入 SentenceTransformer 和 util
import torch
# 待编码的句子们(文档/语料库)
sentences = [
'Paris, which is a city in Europe with traditions and remarkable food, is the capital of France',
'The capital of France is Paris',
'Australia is known for its traditions and remarkable food',
"""
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
""",
"""
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
"""
]
# 编码句子
sentences_embeddings = model.encode(sentences, convert_to_tensor=True)
# 查询句子:
queries = ['Is Paris located in France?', 'Tell me something about Australia',
'music festival proceeding despite heavy rains',
'what is the process that some organisms use to transform light into chemical energy?']
# 使用余弦相似度为每个查询寻找语料库中最接近的句子
for query in queries:
# 编码当前查询
query_embedding = model.encode(query, convert_to_tensor=True)
# 余弦相似度及查询最接近的文档
cos_scores = util.cos_sim(query_embedding, sentences_embeddings)[0] # 计算相似度得分
top_results = torch.argsort(cos_scores, descending = True) # 得分降序排列
print("\n\n======================\n\n")
print("Query:", query)
print("\nSimilar sentences in corpus:") # 输出语料库中相似的句子
# 遍历输出与查询最相似的句子及其得分
for idx in top_results:
print(sentences[idx], "(Score: {:.4f})".format(cos_scores[idx]))通过使用几个新示例来测试模型,从而展示其有效性。
======================
Query: Is Paris located in France?
Similar sentences in corpus:
The capital of France is Paris (Score: 0.7907)
Paris, which is a city in Europe with traditions and remarkable food, is the capital of France (Score: 0.7081)
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
(Score: 0.0657)
Australia is known for its traditions and remarkable food (Score: 0.0162)
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
(Score: -0.0934)
======================
Query: Tell me something about Australia
Similar sentences in corpus:
Australia is known for its traditions and remarkable food (Score: 0.6730)
Paris, which is a city in Europe with traditions and remarkable food, is the capital of France (Score: 0.1489)
The capital of France is Paris (Score: 0.1146)
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
(Score: 0.0694)
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
(Score: -0.0241)
======================
Query: music festival proceeding despite heavy rains
Similar sentences in corpus:
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
(Score: 0.7855)
Paris, which is a city in Europe with traditions and remarkable food, is the capital of France (Score: 0.0700)
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
(Score: 0.0351)
The capital of France is Paris (Score: 0.0037)
Australia is known for its traditions and remarkable food (Score: -0.0552)
======================
Query: what is the process that some organisms use to transform light into chemical energy?
Similar sentences in corpus:
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
(Score: 0.6085)
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
(Score: 0.1370)
Paris, which is a city in Europe with traditions and remarkable food, is the capital of France (Score: 0.0141)
Australia is known for its traditions and remarkable food (Score: 0.0102)
The capital of France is Paris (Score: -0.0128)完整代码
from datasets import load_dataset
from sentence_transformers import InputExample, util
from torch.utils.data import DataLoader
from torch import nn
from sentence_transformers import losses
from sentence_transformers import SentenceTransformer, models
dataset_id = "./sentence-compression"
dataset = load_dataset(dataset_id)
# 探索一个样本
print(dataset['train']['set'][1])
#将数据集转换为所需格式
train_examples = [] # 创建训练样本列表
train_data = dataset['train']['set'] # 获取训练数据集
n_examples = dataset['train'].num_rows//2 # 选择数据集的一半进行训练
# 遍历选定的样本并创建输入示例
for example in train_data[:n_examples]:
original_sentence = example[0] # 原始句子
compressed_sentence = example[1] # 压缩后的句子
input_example = InputExample(texts = [original_sentence, compressed_sentence]) # 创建输入示例
train_examples.append(input_example) # 将输入示例添加到列表中
# 使用训练示例实例化数据加载器
train_dataloader = DataLoader(train_examples, shuffle = True, batch_size = 16) # 初始化数据加载器
# 创建自定义模型
# 使用现有的嵌入模型
word_embedding_model = models.Transformer('bert-base-uncased', max_seq_length=256) # 初始化词嵌入模型
# 对令牌嵌入应用池化函数
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension()) # 初始化池化模型
# 密集函数
dense_model = models.Dense(in_features=pooling_model.get_sentence_embedding_dimension(), out_features=256, activation_function=nn.Tanh()) # 初始化密集层模型
# 定义整体模型
model = SentenceTransformer(modules=[word_embedding_model, pooling_model, dense_model]) # 组装模型各层组件
# 给定等效句子数据集,选择MultipleNegativesRankingLoss作为训练损失
train_loss = losses.MultipleNegativesRankingLoss(model = model) # 初始化训练损失
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs = 5) # 训练模型
# from sentence_transformers import SentenceTransformer, util
import torch
# 待编码的句子们(文档/语料库)
sentences = [
'Paris, which is a city in Europe with traditions and remarkable food, is the capital of France',
'The capital of France is Paris',
'Australia is known for its traditions and remarkable food',
"""
Despite the heavy rains that lasted for most of the week, the outdoor music festival,
which featured several renowned international artists, was able to proceed as scheduled,
much to the delight of fans who had traveled from all over the country
""",
"""
Photosynthesis, a process used by plans and other organisms to convert light into
chemical energy, plays a crucial role in maintaining the balance of oxygen and carbon
dioxide in the Earth's atmosphere.
"""
]
# 编码句子
sentences_embeddings = model.encode(sentences, convert_to_tensor=True)
# 查询句子:
queries = ['Is Paris located in France?', 'Tell me something about Australia',
'music festival proceeding despite heavy rains',
'what is the process that some organisms use to transform light into chemical energy?']
# 使用余弦相似度为每个查询寻找语料库中最接近的句子
for query in queries:
# 编码当前查询
query_embedding = model.encode(query, convert_to_tensor=True)
# 余弦相似度及查询最接近的文档
cos_scores = util.cos_sim(query_embedding, sentences_embeddings)[0] # 计算相似度得分
top_results = torch.argsort(cos_scores, descending = True) # 得分降序排列
print("\n\n======================\n\n")
print("Query:", query)
print("\nSimilar sentences in corpus:") # 输出语料库中相似的句子
# 遍历输出与查询最相似的句子及其得分
for idx in top_results:
print(sentences[idx], "(Score: {:.4f})".format(cos_scores[idx]))