🎇个人主页:Ice_Sugar_7
🎇所属专栏:JavaEE
🎇欢迎点赞收藏加关注哦!
线程池
- 🍉简介
- 🍉标准库中的线程池
- 🍉Executors
- 🍉实现一个简单的线程池
🍉简介
“池”是一个非常重要的概念,我们之前学的字符串常量池就是一种常量池

除了常量池,还有数据库连接池、线程池、进程池、内存池……
池有两个作用:
- 提前把要用的对象准备好
- 对象用完后也不要立即释放,而是先留着,以备下次使用
我们主要来分析线程池
它是存放线程的池,会把要使用的线程提前创建好,用完之后也不会立即释放,而是放回线程池里。这样就可以节省创建及销毁线程的开销
那为什么从线程池里取线程就比向系统申请更高效呢?
因为从池里取,这部分是通过代码实现的,代码是我们自己写的,是纯用户态的(可控的);而向系统申请创建线程是需要内核来完成的,这个过程是不太可控的
就是说你不知道系统在创建线程之前会不会去做别的事儿,它如果有搞别的,那肯定会耽误时间
🍉标准库中的线程池
标准库提供了 ThreadPoolExecutor 这个类,它的构造方法有很多参数

我们分别来解释一下每个参数的含义
-
corePoolSize —— 核心线程数
标准库提供的线程池,它所持有的线程数并非是一成不变的,而是会根据当前任务量,自适应调节线程个数。即如果任务非常多,那就会多搞几个线程;反之则会缩减线程数
核心线程数就是一个线程池里最少有多少个线程 -
maximumPoolSize —— 最大线程数
顾名思义,就是最多能有多少个线程 -
keepAliveTime —— 保持存活时间
就是某个线程,它的空闲时间如果超过这个时间阈值,那就会被销毁掉(或者说空闲状态下能存活多久) -
unit —— 保持存活时间的时间单位(h、min、s、ms……)
-
workQueue —— 一个阻塞队列
和定时器类似,线程池中也可以持有多个任务,所以用一个阻塞队列来存放任务,如果任务有优先级的话,可以用 PriorityBlockingQueue。Runnable 是用来描述任务的主体 -
threadFactory —— 线程工厂
首先要解释一下什么是工厂模式
工厂模式是一种常见的设计模式,通过专门的“工厂类”/“工厂对象”来创建指定的对象
它本质上是给 Java 语法填坑的。这里的“坑”指的是,方法重载没办法在返回值相同的前提下,重载参数个数相同、类型一样的方法
而有时候要重载的方法,它们参数列表中的参数个数和类型虽然一样,但是意思不一样
举个例子,现在有一个类 Point,要用它来表示平面直角坐标系中的点,在数学中有两种表达形式:常规的坐标和极坐标
public class Point {
double x,y;
double r,a;
Point(double x,double y) { //用坐标的形式表示
this.x = x;
this.y = y;
}
Point(double r,double a) { //用极坐标的形式表示
this.r = r;
this.a = a;
}
}
这样写编译器会报错
我们可以把原先两个方法改成静态方法,直接在方法内部创建一个对象并初始化,然后再返回这个对象
这种把创建对象和初始化封装起来,在静态方法内部完成这些操作的过程,想得到对象,就调用这个方法,它就会“加工”出一个对象,这就是工厂模式。代码如下:
public class Point {
public double x,y;
public double r,a;
public static Point pointByXY(double x,double y) { //用坐标的形式表示
Point p = new Point();
p.x = x;
p.y = y;
return p;
}
public static Point pointByRA(double r,double a) { //用极坐标的形式表示
Point p = new Point();
p.r = r;
p.a = a;
return p;
}
public static void main(String[] args) {
Point p1 = Point.pointByXY(1,2);
Point p2 = Point.pointByRA(3,4);
}
}
pointByXY 和 pointByRA 就称为工厂方法
这两个工厂方法是放在 Point 里面,所以 Point 就叫作工厂类
- handler —— 拒绝策略
这个参数是最重要的一个参数
线程池中的阻塞队列能够容纳的元素是有上限的,如果往队列中添加任务时,任务队列已经满了,那线程池会怎么做呢?
这就涉及到拒绝策略了
有四种策略
①AbortPolicy:直接抛出异常。此时原先任务和新任务都不执行
②CallerRunsPolicy:新的任务由添加任务的线程去执行,就是“谁揽的活谁去干”。此时新任务就不由线程池执行了
③DiscardOldestPolicy:丢弃最老的任务
④DiscardPolicy:丢弃最新的任务
🍉Executors
由于 ThreadPoolExecutor 参数比较多,用起来比较复杂,所以标准库还提供了另一个版本 —— 工厂类 Executors,它是由 ThreadPoolExecutor 封装后得到的,通过 Executors 创建出来的线程池对象,它内部已经把 ThreadPoolExecutor 创建好了并设置了参数
可以看到已经提供了多种现成的线程池
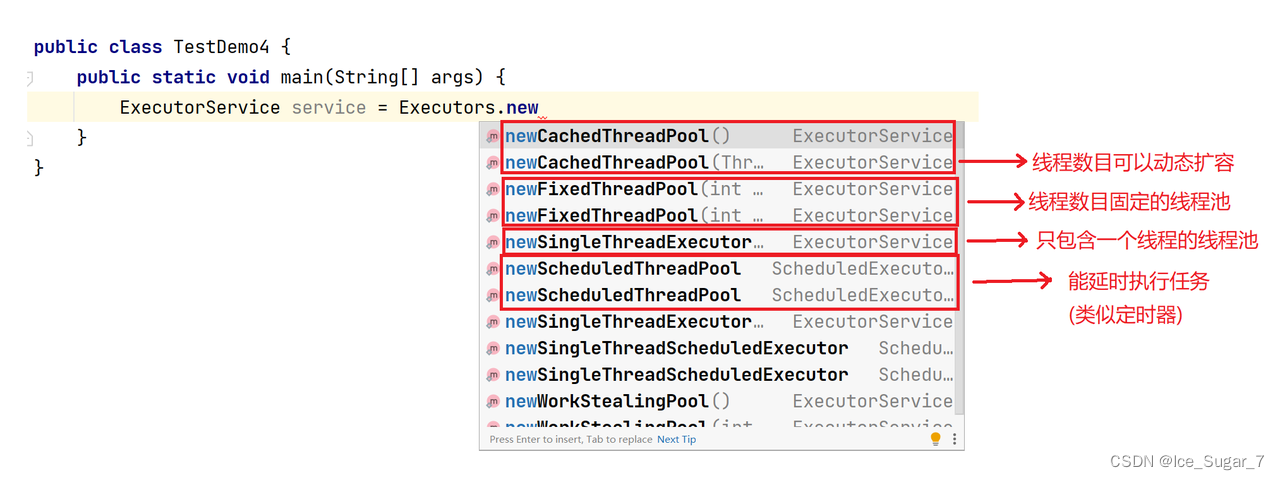
Q:Executors 和 ThreadPoolExecutor 分别在什么时候使用?
A:如果没什么要求,只是简单使用一下,那就用 Executors;而如果想要高度定制化(diy),那就使用 ThreadPoolExecutor,参数都由自己设置,掌控权在我们手上,这样可以避免一些不可控因素
🍉实现一个简单的线程池
方便起见,我们写一个线程数目固定的线程池
构造方法指定创建多少个线程,并把这些线程创建好。然后要有一个阻塞队列,持有要执行的任务。还要提供一个方法 —— submit,它用来添加新任务
public class MyThreadPool {
private List<Thread> list = new ArrayList<>();
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1000);
public MyThreadPool(int n) {
for(int i = 0;i < n;i++) {
Thread t = new Thread(()-> {
try {
while (true) {
Runnable runnable = queue.take(); //取出任务并执行
runnable.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
list.add(t);
}
}
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
}
测试一下:
public class TestDemo5 {
public static void main(String[] args) throws InterruptedException {
MyThreadPool executor = new MyThreadPool(4); //4个线程
for (int i = 0; i < 1000; i++) {
int n = i;
executor.submit(new Runnable() {
@Override
public void run() {
System.out.println("执行任务:" + n + " 当前线程为:" + Thread.currentThread());
}
});
}
}
}
因为这里每次循环都会改变 i 的值,所以不能直接打印语句中不能写 i,而要重新定义一个变量 n,这个 n 在这里就是“事实 final”,可以放到打印语句中
补充:run 是回调函数,它访问外部作用域的变量就是变量捕获,而变量捕获要求变量是常量 or “事实 final”
结果如下:

因为线程是随机调度的,所以任务序号是无序的