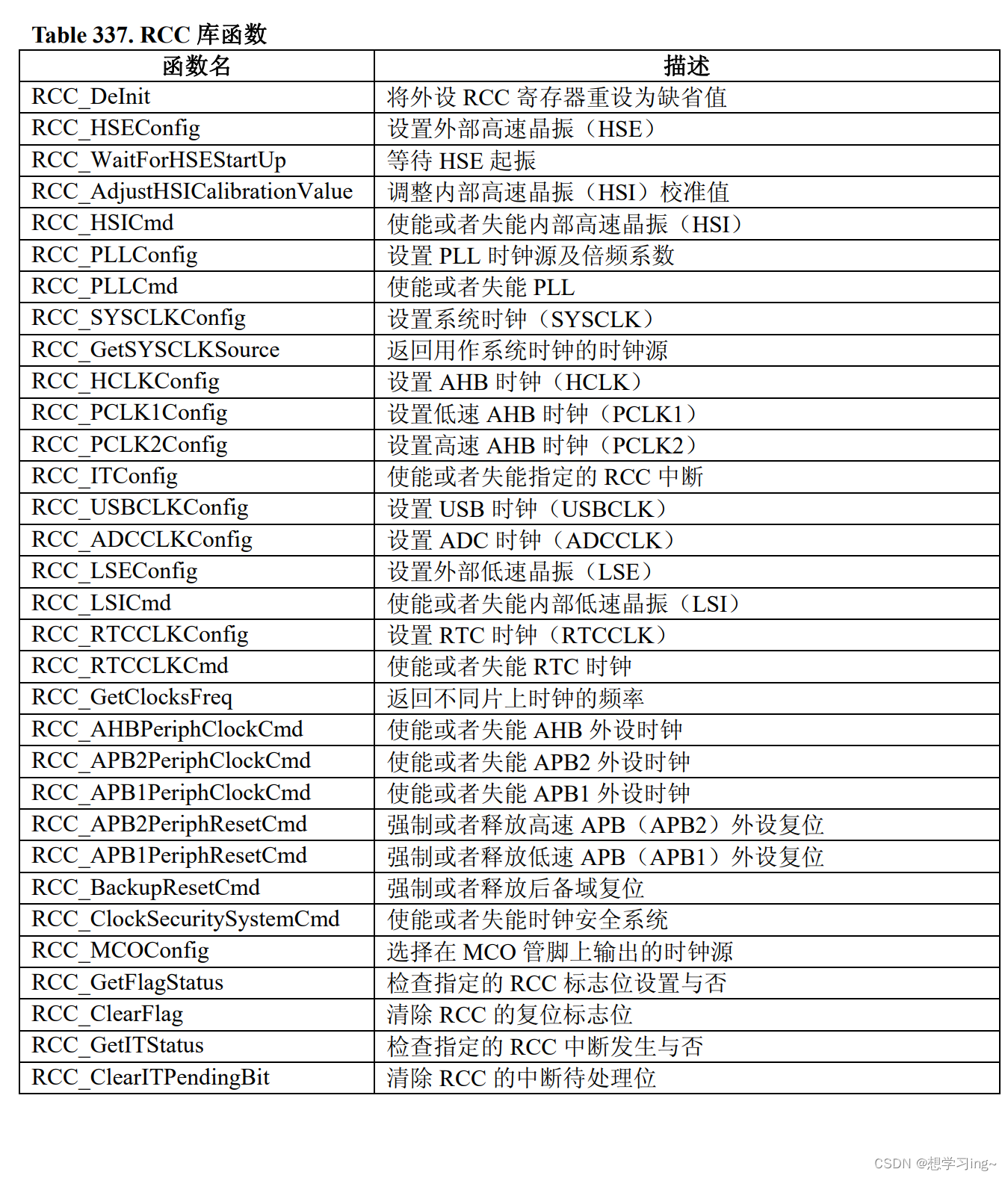
ABSTRACT
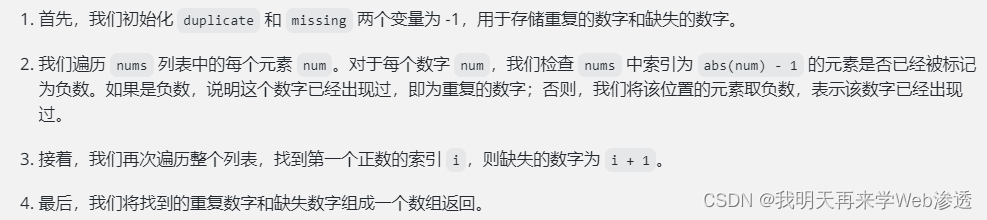
谣言被定义为广泛传播且没有可靠来源支持的言论。现代社会,谣言在社交网络上广泛传播。谣言的传播给社会带来了巨大的挑战。 “假新闻”故事可能会激怒您的情绪并改变您的情绪。有些谣言甚至会造成社会恐慌和经济损失。因此,谣言的影响可能是深远而持久的。遏制谣言的传播需要高效、智能的谣言控制策略。现有的谣言控制策略是为控制单个谣言而设计的。然而,社交网络上通常存在大量谣言,由于检测能力和CPU性能有限,一次只能删除有限的谣言。因此,在处理多个谣言时,我们应该按照一定的顺序消除谣言。我们认为,删除谣言的顺序很重要,因为不同的谣言具有不同的属性,例如接受率、传播速度等。不幸的是,据我们所知,之前没有关于删除多个谣言和删除谣言的顺序的工作。为此,本文提出了两种新颖的谣言控制策略来消除多重谣言。我们还扩展了经典的易感感染者恢复(SIR)模型,以更实际的方式模拟谣言传播的动态。我们评估策略的绩效。实验表明,我们提出的谣言控制策略明显优于基准策略。
关键词 多重谣言约束、谣言控制策略、谣言删除令、社交网络、易感感染者康复 (SIR) 模型
1 INTRODUCTION
人们使用 Facebook 和 Twitter 等社交网络来交换信息并与在线朋友保持密切联系。然而,社交网络也为谣言传播提供了机会。谣言内容惊人、虚假、信息量巨大、引人注目、耸人听闻、传播速度快。谣言的快速传播威胁社会安全,引发公众恐慌。 “奥巴马因白宫爆炸受伤”的谣言直接造成世界金融市场不稳定,短时间内损失1300亿美元[10]。有些谣言会造成社会不稳定和秩序混乱。周五晚上的一场高中橄榄球比赛中,一名枪手在社交媒体上发出威胁,引发了校园恐慌。当这些球员、学校官员和人群纷纷寻求安全时,但当局证实这种威胁并不可信[13]。
如何抑制谣言的传播引起了许多研究者的关注。目前的研究主要集中在限制单一谣言的传播。压制谣言的方法有两种。一是直接删除社交网络上受感染用户的谣言。二是通过网络传播真相,澄清谣言。前一种方法从所有帖子中辨别谣言,并确定所有谣言的范围和影响力。消除有影响力的用户的谣言可以限制谣言的传播。后一种方法将少数用户识别为真相传播者。他们负责传播真相、打击谣言,比如屏蔽谣言、限制受感染的用户。在[8]中,Kundan 等人。提出了一种以 Maki Thompson 谣言为模型的流行病最优控制方法,该方法采用了庞特里亚金最小原理和改进版本的前向后向扫描技术来进行数值计算计算以满足预算约束。谭等人。 [16]基于主题分类和多尺度特征融合成功检测到多个谣言。在[28]中,赵等人。提出了社交网络上的 SIHR 谣言传播模型。在他们的论文中,他们通过添加冬眠者的遗忘和记忆机制来推迟谣言终止时间(消除谣言的时间)并减少最大谣言影响。
尽管在有效遏制单一谣言的传播方面已经取得了很大进展,但对于压制多个谣言的研究仍然不足。现实生活中,社交网络上可能同时存在很多谣言。由于网络管理员的数量有限以及所消耗的时间和系统资源,因此存在与谣言控制相关的成本。为了有效地控制多个谣言,我们可以分析每个谣言的传播率,并根据传播率形成移除顺序。这将最有可能减缓谣言的传播,最大限度地减少受影响的用户数量并降低成本。
在异构社交网络中,用户通常与其他用户具有不同数量的连接(程度)。不同异构社交网络的拓扑也可以彼此不同。异质性的另一个来源是某些谣言比其他谣言更可信。换句话说,谣言的接受率不同。
程度、可信度的差异称为网络异质性。我们使用Runge-Kutta方法进行数值模拟并分析谣言传播趋势。
本文的重点是通过按适当的顺序删除谣言来控制多个谣言,从而最大程度地减少受影响的用户数量。据我们所知,我们是第一个研究多重谣言控制策略的人。我们提出了两种基于扩展的易感感染恢复(SIR)模型的新颖策略。在现有的使用SIR模型描述谣言传播过程的作品中[18],所有被感染的用户都被视为传播者。我们通过将受感染的用户分类为扼杀者和传播者来扩展模型。我们的主要贡献如下:
• 我们通过将受感染的用户分类为抑制者和传播者来扩展经典的SIR 模型。这使得该模型对于描述谣言传播过程更加实用。在模型中,我们还考虑了社交网络的异质性、用户程度(与其他用户的联系数量)以及谣言的诉求水平。
• 采用Runge-Kutta方法,分析不同网络异质性下谣言的传播趋势。根据数值结果,我们确定多个谣言的删除顺序。
• 我们提出了两种控制多种谣言的新颖策略,即 OSLA 和 MSLA,其目标是最大限度地减少受感染用户的数量。这两种策略用于确定不同时间尺度的移除顺序。
• 我们进行实验来评估谣言消除策略的有效性。我们提出的谣言消除策略优于基准算法。
本文的其余部分安排如下。第 2 节描述了谣言传播和问题定义的动态模型。我们在第3节中提出了谣言消除顺序策略。在第4节中,我们使用Runge-Kutta方法来模拟谣言的传播并分析影响传播的参数。我们在第 5 节中进行了实验来评估谣言删除订单策略的性能。
2 PRELIMINARIES
2.1 The Rumor Propagation Model
我们开发了一个扩展的易感-感染-恢复 (SIR) 模型来描述谣言传播。 SIR模型及其变体是研究传染病爆发的基础模型[12]。基本的SIR模型在社交网络的文献中被广泛采用[7][27][4]。在SIR模型下,分为三类用户:易感者(S)、感染者(I)和康复者(R)。为了更加实用,我们通过将受感染的用户分类为抑制者和传播者来扩展基本的 SIR 模型。这个想法是基于这样一个事实:一些受感染的用户选择传播谣言,而另一些则不选择。
考虑一个拥有 n 个用户的社交网络,并且有一个谣言在网络中传播。用户分为以下几类。易受影响的用户是那些没有收到谣言的用户。被感染的用户是那些收到谣言并相信它的人。受感染的用户要么是抑制者,要么是传播者。前者相信谣言,但不传播谣言。后者相信谣言并积极传播。系统可以阻止受感染的用户转发谣言。在这种情况下,我们说她/他成为恢复用户。当我们删除社交网络上所有被感染用户的谣言后,剩下的易感用户将不再接触谣言。在任何特定时间,社交网络上通常都会传播多个谣言。因此,每个谣言都有自己的易感用户、扼杀者、传播者和康复用户。
对于任何谣言 i,令 Si (t) 为在时间 t 时易受谣言影响的人口比例。令 Ii (t)、Ii0(t) 和 Ii1(t) 分别为在时间 t 时被感染、窒息者或传播者的人口比例,其中 Ii (t) = Ii0(t) + Ii1 (t)。令 Ri (t) 为在时间 t 相对于谣言 i 已恢复的人口比例。我们必须有
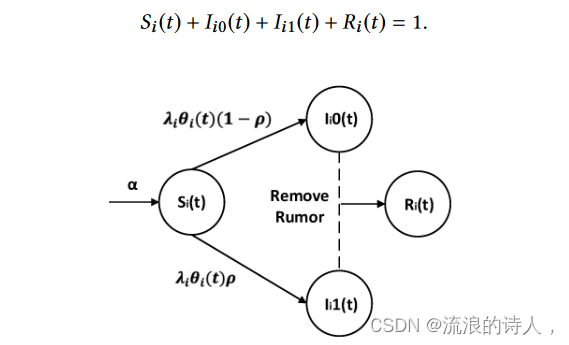
图 1:与谣言 i 相关的状态转换
图1展示了不同类别用户之间的关系。符号的含义可以在表1中找到。接下来我们讨论不同类型用户之间的关系。
• 总是有新用户在社交网络上注册帐户。我们假设易受影响的用户以速率 α 加入社交网络。
• 随着谣言的传播,其影响力不断增大。更易受影响的用户会关注谣言。假设谣言 i 的谣言接受率为 λi ,其中 0 < λi < 1。换句话说,如果易受影响的用户与单个感染者连接,则其可以以 λi 的速率转变为感染者。对于任何时间 t,令 θi (t) 表示一个用户相对于谣言 i 连接的受感染用户的平均数量。那么,对于谣言 i,易感用户被感染的比率等于 λiθi (t)。当易感用户被感染时,她/他将以概率 ρ 传播它,或者以 1 − ρ 的概率不传播它。因此,易受影响的用户以 λiθi (t)Si (t)(1 − ρ) 的速率成为抑制者(即图 1 中的 Si (t) → Ii0(t)),并且她/他以速率成为传播者λiθi (t)Si (t)ρ (即图 1 中的 Si (t) → Ii1(t))。
• 如果谣言 i 被删除,则受感染的用户将恢复关于谣言 i 的状态(图 1)。当删除谣言 i 时,我们假设单位时间内最多可以将其从 K 个感染用户中删除。这受到计算资源、网络管理器数量或其他成本考虑因素的限制。
2.2 Problem Definition
我们提出了针对多种谣言的谣言控制策略。由于谣言清除涉及非零成本,因此我们可以同时处理的谣言数量有限。我们会优先删除传播最快的谣言。这样的策略对于减缓谣言的传播是最有效的。为此,我们需要形成一个最优的谣言消除顺序。
在这个谣言消除策略中,我们根据传播因子 Fi 对谣言进行排序,定义为:
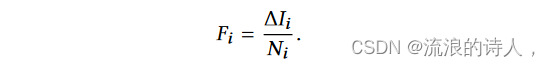
谣言 i 的传播因子 Fi 是谣言实时传播率的度量。我们将时间离散为大小为 τ 的间隔。在一段时间内,我们可以删除最多 K 个受感染用户的谣言。为了彻底消除一个谣言,我们可能需要几个间隔,这个间隔的数量用 Ni 表示。完全消除谣言所需的时间为Ni·τ。在此期间,受感染用户的数量可能会增加 ΔIi 。传播因子可以帮助评估多个谣言的传播率。我们需要限制谣言传播最快的速度,因此我们应该设计一种算法来计算传播因子。假设我们在社交网络中总共有 N 个谣言。
假设我们在时间 t 有 Ii (t) 个因谣言 i 感染的用户。我们需要 Ni (t) 个时间间隔才能在时间 t 完全消除谣言 i。完全消除谣言 i 所需的时间表示为 Ti (t) = Ni (t)τ 。 Ti(t)取决于时间t。假设我们考虑从时间 t 删除谣言 i。我们可以计算出消除谣言 i 所需的时间 Ti(t)。根据公式(3)和(4),受感染用户的增长率为:
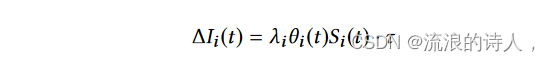
大多数情况下,易受影响用户的比例Si(t)和θi(t)在Ti(t)时间内变化不大。然后我们近似地得到以下方程。

由上式,我们可以计算出Ti(t):

消除所有谣言的总时间为 T (T = N Í i = 1 Ti (ti )),其中 ti 表示谣言 i 被消除的时间。初始易感、感染和康复用户应满足:Si(0) = 1 − i0, Ii(0) = i0, Ri(0) = 0
i0 → 0 是社交网络上谣言传播之初的少数受感染用户。
我们可以通过网络观察来检测社交网络上用户的不同状态。快照观察已用于提供社交网络中受感染节点的详细信息[31][19][29]。我们使用快照观察来检测社交网络上所有受感染的用户。恢复的用户只有在我们开始删除谣言后才会出现。在消除对受感染用户的谣言后,我们还治愈了该用户,她/他再次康复。除了受感染的用户和恢复的用户外,其余用户均易受影响。根据这种方法,我们可以确定社交网络上所有用户的状态。
随着时间的推移,越来越多的易感用户被感染。在时间 t,假设 ψ 代表我们为所有 N 个谣言形成的任何谣言删除顺序。在删除顺序 ψ 中,我们按照从 1 到 N 的顺序删除谣言。我们将按顺序删除谣言。令 t1 = t。我们可以递归地定义 tj:tj = tj−1 + Tj−1(tj−1)。每个tj是开始消除谣言j的时间。也可表示为 tj = t1 + j −1 Í l =1 Tl (tl )。
最大感染用户数(Imax)等于每个谣言的感染用户分数之和。设 I * i (t) 表示从时间 0 到时间 t 期间被谣言 i 感染的用户数量。假设我们从时间 0 开始执行谣言消除系统。那么,I ∗ i( i Í j =1 Tj (tj )) 表示谣言 i 能够到达的最终受感染用户数量。最优谣言控制策略的目标是:最小化 I ∗ max = N Í i =1 I* i( i Í j =1 Tj (tj ))。
ψ 表示 N 个谣言的任意一个约束顺序[谣言 1,谣言 2,...,谣言 N ]。 A是N个谣言的所有约束阶的集合。在本文中,我们的谣言约束策略是形成最优约束阶ψ*以最小化Imax。
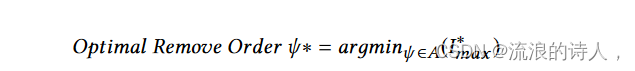
在第3节中,我们需要设计一个算法来实现它。
3 RUMOR REMOVE ORDER STRATEGY
基于上述数学分析,我们形成了谣言消除策略,以最大限度地减少受感染用户的总数。我们使用 Runge-Kutta [23] 方法来估计每个谣言的传播率。 Runge-Kutta 方法为 SIR 模型中的常微分方程提供了近似解。为了消除 N 个谣言,我们的算法使用迭代结构。当谣言去除系统空闲时,我们执行Runge-Kutta方法来计算谣言的传播率,并去除选定的谣言。谣言移除顺序策略是一种启发式算法。

我们提出了具有最优约束顺序的谣言删除顺序策略,算法如下所示。假设辟谣系统在时间t=0时启动,我们将通过网络观察不断更新每个谣言的易感用户和感染用户,并在每一轮中选择一个谣言进行辟谣。我们提出了两种算法来选择谣言:算法 1 是一种一步前瞻算法(OSLA)。它选择在一个时间间隔内传播最快的谣言。算法 2 是多步前瞻算法 (MSLA)。它着眼于较长一段时间内的谣言传播,而不仅仅是一个时间间隔。周期为Ti(t),根据式(1)计算。稍后,我们将使用随机选择作为基准算法来评估我们提出的算法的性能。随机选择,随机选择一条谣言进行剔除;删除谣言的K个感染用户也是随机选择的。

在OSLA第4行和MSLA第5行中,我们使用Runge-Kutta方法估计所有谣言的传播因子,并选择传播因子最大的谣言进行移除。稍后我们将展示如何使用 Runge-Kutta 方法来计算铺展率。
在我们提出的算法的下表中,i是谣言的索引,V表示N个谣言的集合,i*表示每轮中选定的谣言的索引,Seti*(t)表示受感染用户的集合在时间t。

删除谣言函数如算法 3 所示。我们在每轮中删除最多 K 个用户。 VR是所有要删除的受感染用户的集合。 u 是被感染的用户,他有可能感染最易受影响的用户。我们应该把时间还给彻底消除谣言i*。
Set1 = Seti*(t+1),Seti*(t)表示在t+1时刻被感染的用户集合,并且在t时刻没有移除和治愈任何被感染的用户。 Set2 = Seti*(t+1),Seti*(t)\u表示在t时刻去除感染用户u后在t+1时刻感染用户的集合。在谣言删除系统中,我们确定 u 与社交网络上的最大邻居。
在Remove-Rumor函数中,我们使用贪心算法来删除谣言。我们可以在每个时间间隔删除 K 个用户。如图所示在算法中,我们选择影响最易受影响的K个用户进行删除。我们首先删除吊具,然后删除抑制器。
4 RUMOR SPREADING SIMULATION WITH RUNGE-KUTTA METHOD
4.1 The Extended SIR Model
在本节中,我们使用微分方程描述谣言传播的动力学。
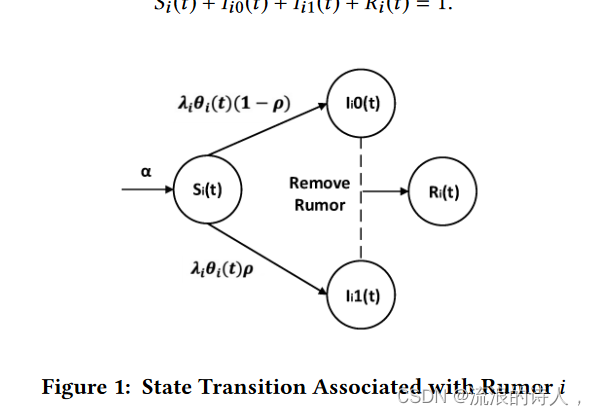
图 1:与谣言 i 相关的状态转换
如图1所示,对于每个谣言i,我们将用户分为四类:易受影响的用户、压制者、传播者和康复用户。它们的数量分别用 Si 、 I0i 、 I1i 和 Ri 表示。每个谣言都有自己的接受率。根据2.1节的描述,我们有以下方程,形成扩展的SIR模型。注意,在这部分中,时间t是实数。
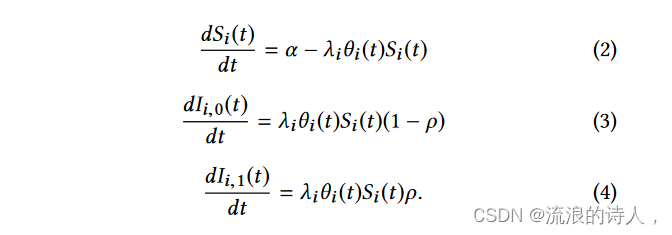
4.2 Runge-Kutta Method
为了执行谣言消除算法,我们需要估计受感染用户的数量如何变化,这由微分方程(2)-(4)描述。
我们将使用龙格-库塔方法来近似计算变化。在 OSLA 算法中,我们计算一个时间间隔内的变化。在 MSLA 算法中,我们计算几个时间间隔内的变化。 Runge-Kutta 方法是一种迭代方法,利用时间离散来逼近常微分方程的解[23]。
在龙格-库塔方法的实现中,我们使用的步长为h,它应该远小于一个时间间隔。 Runge-Kutta 方法的迭代次数等于 τ h ,其中 τ 是时间间隔的长度。我们选择使用四阶龙格-库塔方法。基于微分方程 (2) - (4),我们对 RungeKutta 方法进行以下迭代,其中 j ∈ {0, 1, . 。 。 τ h − 1},是迭代索引。初始值为S0 i (t) = Si (t)。数量 S j i (t) 近似于 Si (t + jh)。
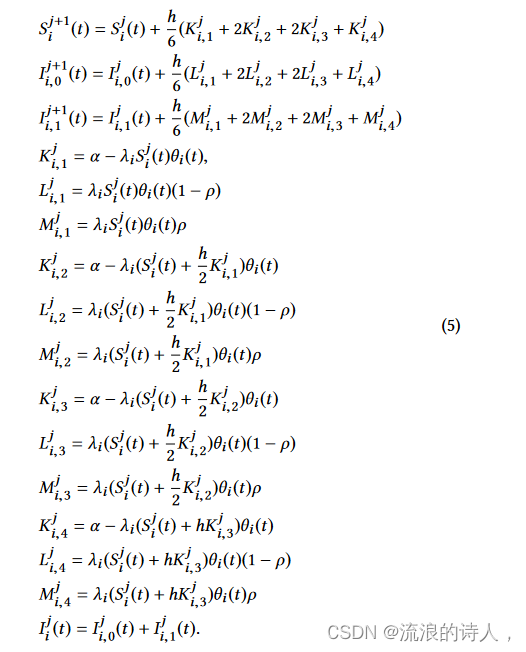
θi (t) 表示一个人所连接的受感染用户的平均数量。直观上,θi(t)与被感染用户的数量成正比,并且与用户在社交网络上的程度有关。我们可以将 θi(t) 表示为:

n 是互联网用户总数。 kj 是节点的度。 Ikj(t)表示受感染程度为kj的互联网用户数量。
假设在我们删除谣言的短时间内,用户在社交网络上的程度基本保持不变。如果我们考虑一个用户与其他用户的连接是随机的,则 θi (t) 的值与第 i 个谣言的受感染用户数量成正比。那是,

其中系数 ψi 称为影响因子,由社交网络的连通性决定
4.3 The Influence of Rumor Acceptance Rate λi
为了模拟谣言的传播,我们假设最初有10000个易受影响的互联网用户,10个谣言传播者和10个传播者。当然,最初并没有恢复的互联网用户。我们将影响因子ψi设置为0.005。 α默认设置为0。在这样的封闭环境下,我们改变谣言接受率λi的变量,并分析它将如何影响谣言的传播。
谣言接受率表示易受影响的用户接受谣言的概率。它代表了谣言的可信度。假设我们有三个谣言,接受率为:0.1、0.2、0.5。

图2:谣言接受率的影响
从图2中我们可以看出,谣言接受率可以加速从易感者到感染者的转变。因此,在其他参数都相同的情况下,我们应该首先删除谣言接受率较高的谣言。
4.4 The Influence of Impact Factor ψi
接下来我们讨论影响因子ψi的影响。它是θi(t)和Ii(t)之间的系数。实际上,ψi代表了社交网络的平均度。如果一个社交网络是强连接的,它应该有一个高的 ψi 。对于弱连接网络则相反。 ψi 的值由社交网络的拓扑结构决定。
为了分析影响因子的影响,我们将接受率λi设置为0.1。其他参数与4.3节相同。假设同一个谣言在三个不同的社交网络中传播,其影响因子分别为:0.002、0.005 和 0.01。
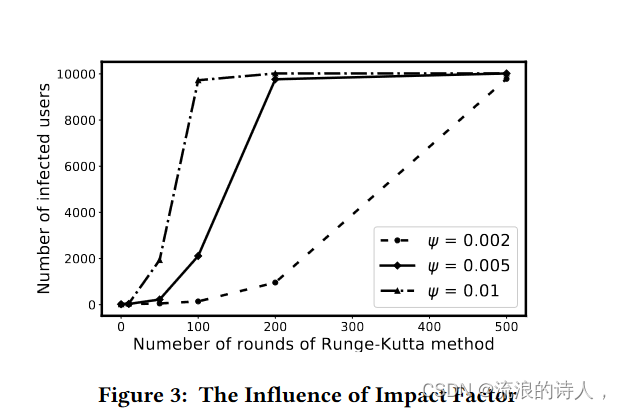
图3:影响因子的影响
图3展示了三种谣言的传播趋势。我们可以观察到,较高的影响因子也能加速从易感用户向感染用户的转化。直观上,谣言在社交网络中传播得越快,程度越高。因此,我们应该首先在强大的社交网络中消除谣言。
5 EXPERIMENT AND EVALUATION
社交网络有自己的拓扑。在第 4 节中,我们明确解释了谣言的不同属性将如何影响其传播。在本节中,我们的目标是利用数学分析结果来确定多个谣言的约束顺序。
为了验证我们的数学分析结果,我们在幂律分布式社交网络上执行实验。我们假设所有谣言都存在于同一个社交网络中。在我们的实验中,我们首先生成每个谣言的初始感染用户。我们在这些实验中依次删除谣言。然后我们进行实验,将最终结果与三种不同的谣言约束策略进行比较。
5.1 Experimental Setting
我们已经生成了社交网络,社交网络的连接应该遵守幂律分布[5]。幂律分布可以表示为:

其中: - k 是互联网用户的社交联系度(度); - Pr(k)是互联网用户有k个邻居的概率; - γ 是幂律指数; - ζ (γ ) 是黎曼 zeta 函数:n Í k =1 k−γ ,n 是社交网络上的互联网用户总数
我们进行模拟来评估谣言约束算法的性能。由于幂律指数应满足:2 < γ < 3,因此我们选择γ为2.5。我们假设社交网络总共有 10000 个互联网用户并生成社交网络。根据幂律分布的性质,我们可以计算出影响因子为:

在模拟过程中,我们将谣言分为三个区间:[0.001, 0.01]、[0.01, 0, 1]、[0.1, 0.2]。我们设计了三个区间,因为谣言通常有不同的接受率。对于每个谣言,最初感染的用户应遵守最小限制(500)的线性分布。之所以会出现这种情况,是因为只有谣言有影响力,感染了足够多的人,才值得关注,应该被删除[22]。
我们使用 OSLA、MSLA 和随机选择算法来形成谣言删除命令。这些实验用于评估这三种算法的效率。
5.2 Evaluation
在这个实验中,我们选择了十个谣言。在OLA和SLA中,我们使用Runge-Kutta方法来估计谣言的传播率。我们设计约束顺序来消除传播的谣言最快的。随机选择算法是选择一个随机的谣言来删除,我们在每一轮中随机删除被感染的用户,而不是使用贪心算法。我们可以分析这三种算法的性能。
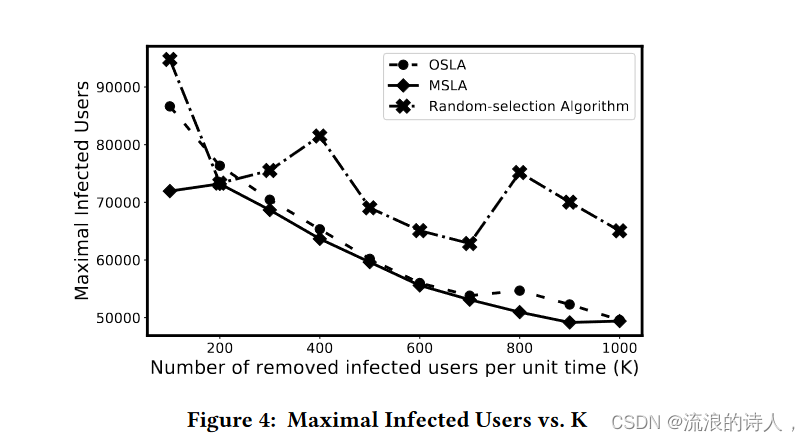
图 4:最大受感染用户数与 K 数
如图4所示,我们将单位时间(K)删除用户的范围从100个改为1000个。MSLA算法总是能得到最好的结果。 OSLA 是一种稳定的算法,但性能不如 MSLA。发生这种情况是因为多重谣言约束问题没有最优子结构。 OSLA 是一种贪婪算法,在这种情况下效果不佳。法律援助办仅展望一个单位时间,这是不够的。有些谣言在下一个单位时间内传播得最快,但在接下来的时间内可能会减慢,因为它已经几乎到达了整个社交网络。 MSLA 会预测几个时间单位并消除传播率最高的谣言。它更全面、更有效。随机选择算法不稳定。它没有数学估计步骤,而且大多数时候表现比法律援助办差。这三种方法的执行时间非常相似。
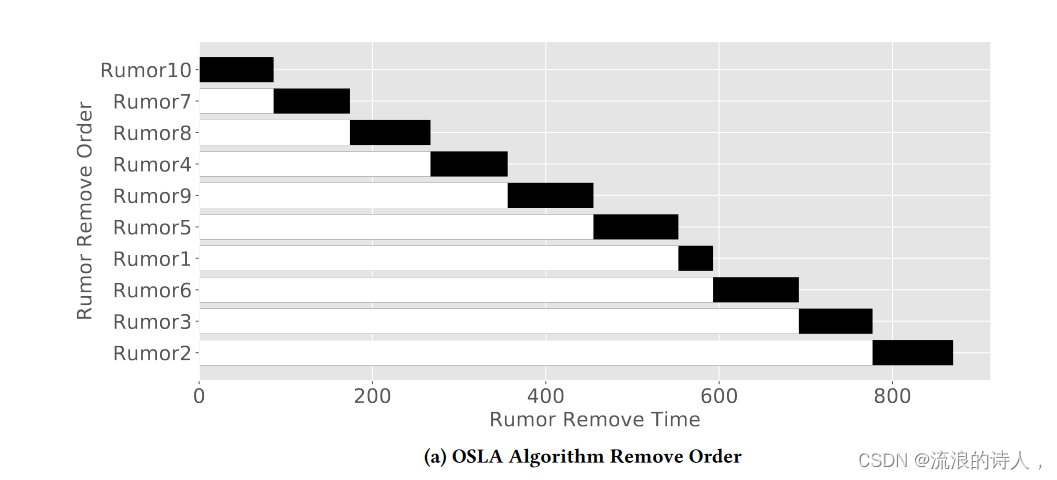

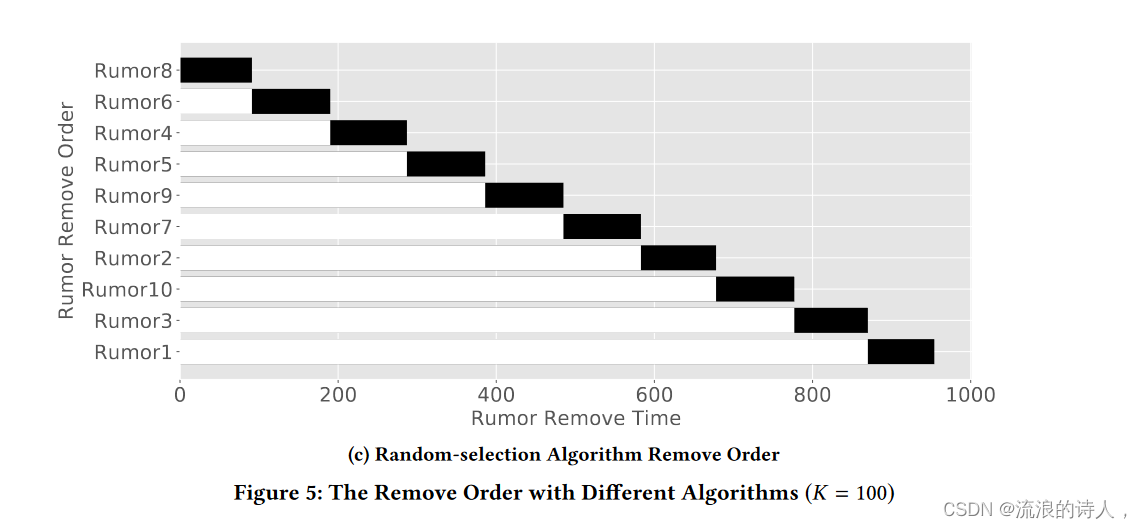 图 5:不同算法的删除顺序 (K = 100)
图 5:不同算法的删除顺序 (K = 100)
在图5中,我们观察了这三种算法的具体约束顺序。 OSLA 首先删除 Rumor 10,MSLA 首先删除 Rumor 7。谣言 10 已有 3189 名受感染用户。删除如此多的受感染用户非常耗时。首先删除谣言10,其他谣言传播得很快。最重要的是,一个拥有三分之一受感染用户的社交网络可以很快感染整个网络。尽管法律援助办先删除了谣言10个,但法律援助办的总数仍然可以达到8553个,仍然增加了168.2%。 MSLA 首先选择谣言 7 和谣言 8 进行删除,因为它们的初始感染用户很少且接受率较高。它几乎在最后删除了谣言9和谣言10,因为这两个谣言已经感染了整个社交网络。随机选择算法删除了第二位的谣言 6,该谣言 6 具有许多初始感染的谣言。在其清除过程中,其他谣言的感染用户数量明显增加。
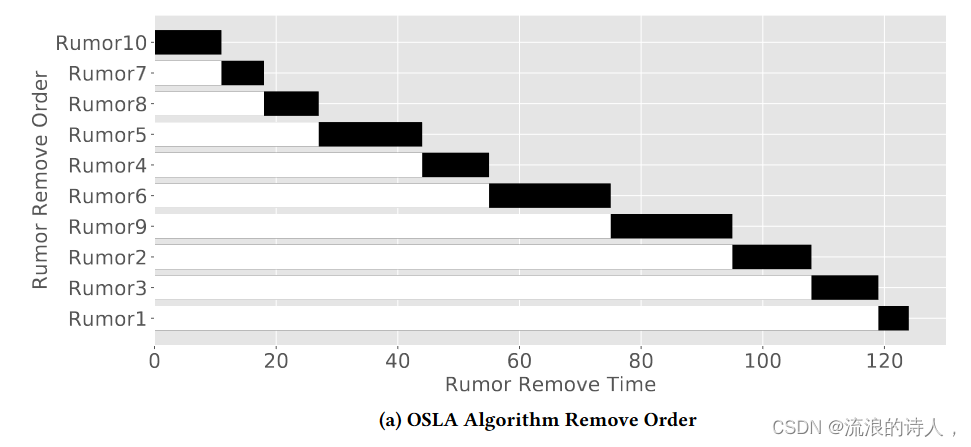

 图 6:不同算法的删除顺序 (K = 500)
图 6:不同算法的删除顺序 (K = 500)
如图6所示,OSLA的性能非常接近MSLA。发生这种情况是因为,如果我们增加 K 的值,我们也会减少消除谣言所需的时间。消除一个谣言所消耗的时间(Ti(t))也接近一个单位时间。因此,OSLA 和 MSLA 具有相似的性能。
6 RELATED WORK
谣言约束多年来一直是一个热门研究课题,引起了学术界和工业界的关注[25]。我们介绍了有关谣言约束的现有研究工作。
谣言源检测是谣言约束的一个重要问题。谣言源检测可分为:单谣言源检测和多谣言源检测。 Shah 和 Zaman 是第一个系统研究网络中计算机病毒检测问题的人。他们使用 SIR 模型对网络中的病毒传播进行建模,并构建一个估计器来检测单个病毒源 [14]。王等人。解决了通过多个观察来检测单个谣言源的问题。他们设计了一种检测算法来组合单个实例的多个连续观察结果[20]。郑等人。 [30]提出了一种概率表征算法来估计谣言源的谣言边界。谣言来源检测是区分谣言和有价值新闻的一项重要工作。目前的研究工作还可以检测多个谣言来源。赵等人。 [26]提出了一种通过部分观察来检测网络中多个谣言源的方法。王等人。 [21]通过将情感信息编码为时间序列划分和单词表示来检测谣言事件。桑索什库马尔等人。 [15]使用神经模糊方法来检测在线社交网络中的谣言。
谣言拦截是谣言遏制的另一个重要问题。目前大多数谣言约束方法都是引入与谣言竞争的正级联。布达克等人。 [2]是最早研究谣言拦截问题的人之一。他们基于多活动独立级联模型来约束谣言。他们还选择社交网络中的一部分个人来采取“好的”活动。他等人。展示了竞争线性阈值模型和 OPOAO 模型的 (1 − 1/e) 近似算法[6]。李等人。 [9]随后制定了 γ - k 谣言限制问题并显示了 (1 − 1/e) 近似。 γ 代表将受污染节点变成好节点所花费的努力。 k是保护器的数量。如上所述,这些现有方法在处理大量社交网络信息时耗时且薄弱。最近,一些研究人员提出了一些启发式方法。阿穆萨等人。[1] 使用半监督聚类算法在社交网络中实现了谣言最小化和分类。童等人。 [17]提出了一种有效的随机算法来阻止社交网络上的谣言。吴等人。 [24]提出根据社区结构最小化动态谣言的影响。
综上所述,目前针对多重谣言阻断的研究工作还很少[3]。我们是第一个研究多重谣言约束顺序以最小化多重谣言传播的影响的人。我们的研究成果被证明是有效且高效的[11]。
7 CONCLUSION
在本文中,我们提出了改进的SIR模型,并基于幂律分布生成相关的社交网络。我们分析参数设置如何影响谣言传播。然后我们使用龙格-库塔方法来分析谣言的传播。我们提出了 OSLA 和 MSLA 算法,并与基准随机选择算法相比评估了它们的性能。我们的实验表明,所提出的算法优于随机选择算法。