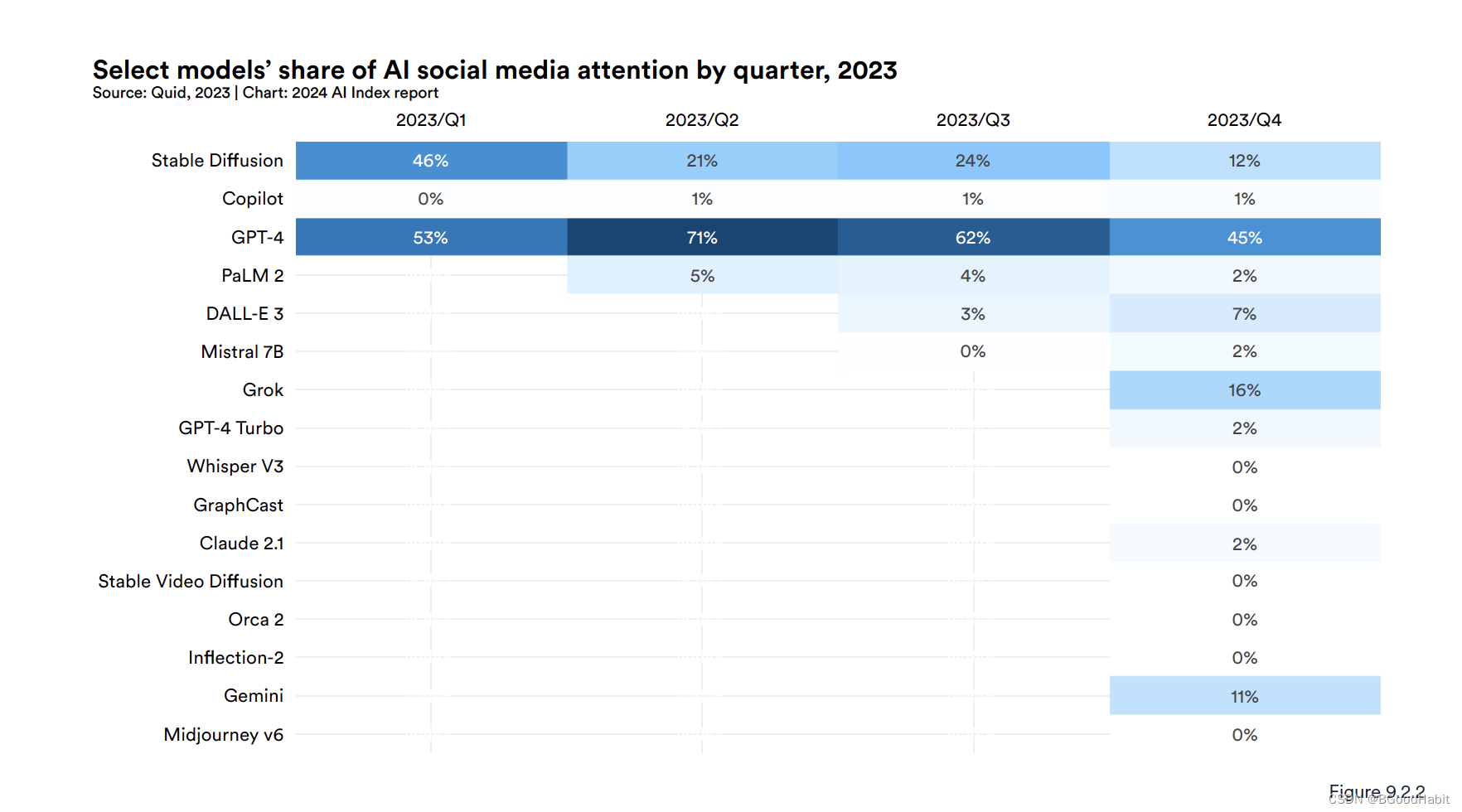
今天想跟大家聊聊,在HIVE数仓分层中,一般分为4层,在前两层中,数据贴源层(HDM)的数据是怎么加载到基础数据层(BDM)的。
A,数据加载背景
啥意思呢,我先给大家讲讲背景:我们在工作中,一般数据都是存放在HIVE中(当然,底层逻辑来讲是存放在HDFS里),但是HIVE层的数据怎么来的??
其实,在hive上游有各个不同的业务系统,它们都会把其数据同步到HIVE,然后我们会在hive里建立数仓。但大家必须知道的一个点就是,上游有各个不同的业务系统的数据都是放在oracle库,mysql,PostgreSQL,DB2,kingbase(人大金仓库)等等。表在数据库里,是不存在分区这么一个概念的,所有的数据都放在这一张表里。
贴源层(HDM)层,是由上游各个不同的业务系统的数据,同步过来的。在HDM层,我们也是直接建立一张表,把上游数据数据原封不动搬过来,比如咱们是用datax把上游表里的数据加载过来,每天同步过来的数据,我们会按照etl_date分区字段加载到表。
但是我们如何把贴源层(HDM)层的数据加载到数据基础(BDM)层呢??这是我们今天要探讨的问题。
emmmm咱们看个数仓分层图,先回忆回忆:
B,数仓分层图回忆

数仓一般分为4 层,HDM---> BDM---> CDM ---> MDM
C,HDM层到BDM层的--加载算法:
2.1,知识点:HDM层的表必然是每日分区表,分区字段为etl_date ;
BDM层的表必然是每日分区表,分区字段为prat_dt .
2.2,增量追加:HDM每日增量数据追加至BDM每日增量分区中
知识点:BDM层的表,所有的dt分区的数据加起来即历史全量的数据。比如说,银行流水表。
2.3,全量:HDM每日全量数据追加至BDM每日全量分区中
知识点:BDM层的表,每个dt分区的数据都是最新的全量的数据,可回溯数据状态情况。比如说,银行理财产品信息表。
2.4,增转全: HDM每日增量数据与BDM昨日全量分区数据比对,累积转换成BDM每日全量分区
知识点:BDM层的表,每个dt分区的数据都是最新的全量的数据。比如说,银行客户信息表。
emmmmm,前两种加载算法都很简单,但增转全还是有难度的。
接下来,咱们细细说一下增转全算法的具体实现。
D,增转全算法(重点):
0,增转全示意图
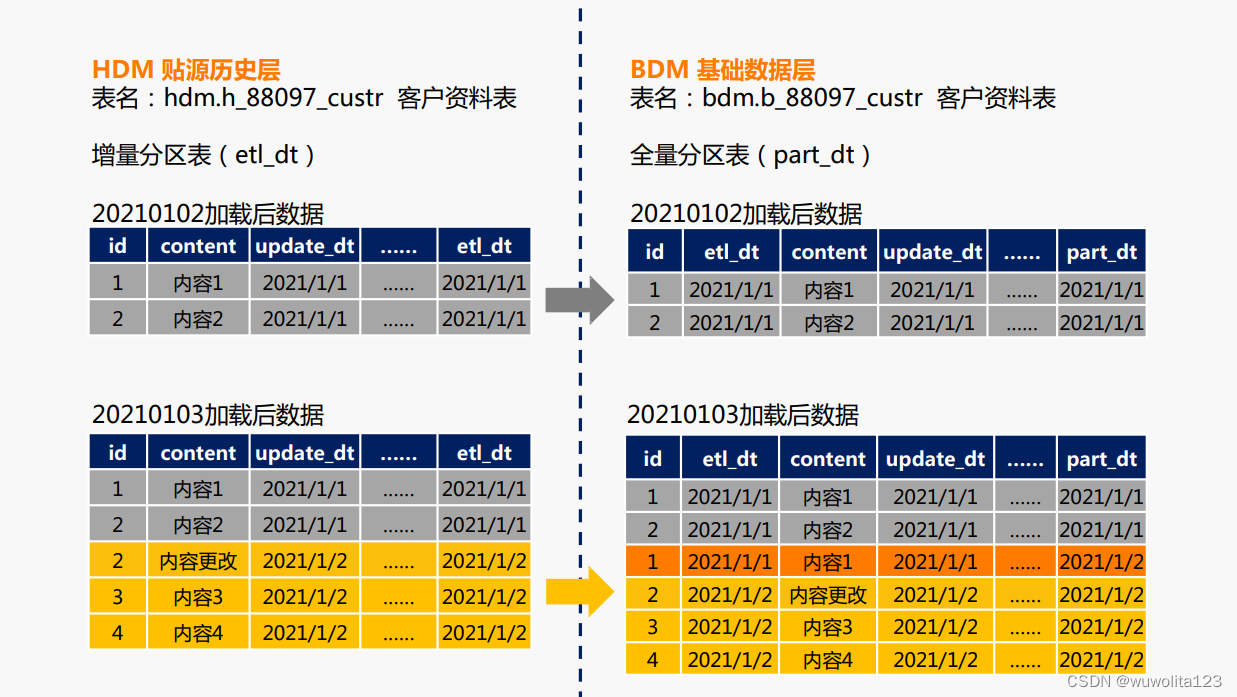
1,建立临时表01,存放上一日数据
1.1, 先建个临时表01,字段直接复制目标表字段。
drop table if exists bdm.tmp_88097_custr_01 ;
create table if not exists bdm.tmp_88097_custr_01
like bdm.b_88097_custr ;1.2,将上一日全量数据插入临时表01
insert overwrite table bdm.tmp_88097_custr_01 partition (part_dt = '${batch_date_8}')
select etl_dt --数据日期 yyyymmdd
,fund_id --产品编号
,tatistic_date ---统计日期
from bdm.b_88097_custr
where part_dt = FROM_UNIXTIME(UNIX_TIMESTAMP(date_sub('${batch_date_10}',1),'yyyy-mm-dd'),'yyyymmdd')
;2,建立临时02,存放当日比对更新后的全量数据
2.1,建立临时02,字段直接复制目标表字段。
drop table if exists bdm.tmp_88097_custr_02 ;
create table if not exists bdm.tmp_88097_custr_02
like bdm.b_88097_custr ;2.2,将上一日全量数据与当日增量数据进行比较,将上一日全量数据中无变化的数据插入到临时表02中
无变化数据etl_date保持原样
insert overwrite table bdm.tmp_88097_custr_02 partition (part_dt = '${batch_date_8}')
select t1.etl_dt --数据日期 yyyymmdd
,t1.fund_id --产品编号
,t1.tatistic_date ---统计日期
from bdm.b_88097_custr t1 上一日全量数据
where not exists (select t2.fund_id --产品编号
,t2.tatistic_date ---统计日期
from hdm.h_88097_custr --当日变化数据
where t1.fund_id = t2.fund_id
and t1.tatistic_date = t2.tatistic_date
and t2.etl_dt = '${batch_date_8}'
)
;3,将当日变化数据插入临时表02中,累积成当日的全量数据,
当日变化数据etl_date使用当日数据日期
insert overwrite table bdm.tmp_88097_custr_02 partition (part_dt = '${batch_date_8}')
select '${batch_date_8}' as etl_dt --数据日期 yyyymmdd
,fund_id --产品编号
,tatistic_date ---统计日期
from hdm.h_88097_custr --当日变化数据
where etl_dt = '${batch_date_8}'
;4,目标表数据落地
insert overwrite table bdm.b_88097_custr partition (part_dt = '${batch_date_8}')
select etl_dt --数据日期 yyyymmdd
,fund_id --产品编号
from bdm.tmp_88097_custr_02 --当日比对更新后的全量数据
where part_dt = '${batch_date_8}'
;ok,这样子经过上面4个步骤,就把HDM增量的数据加载到BDM层全量数据。
E,为什么要进行数据加载算法???
emmmm,这真的是个好问题,为什么要进行这些加载算法呢,当然是为了后面方便拿来使用啊!!
首先,HDM贴源层,咱们肯定是不能去变动的,因为它代表了业务源数据,我们业务表如果开发有问题,我们是要通过HDM层来核查数据的。
BDM层基础层的表,是经常要被CDM,MDM层,拿来使用的,在使用之前,主要是做一些基础的数据加载转换,比如某些特别的字段要经过处理获取,比如说一些字段的数据类型可能要先进行转换,比如说要增加标识字段,对数据提前打标签等。数据加载算法,当然也是非常核心的一点,就是通过处理,我们在后续的计算之时,减小数据存储,尽可能的提升计算效率。
CDM公共层数据,当然是做一些轻粒度的汇总,减少后续重复开发。
MDM层是应用层,是最终指标落地的表。
-----------------------------------------------------------------------------------------------------------------------
哈哈哈当我写完这些东西的时候,感觉有那么一些无敌,因为这些ETL的工作,以及业务需求的开发工作,咱又不是没有做过。这些对于资深大数据开发人员来说,可能不是很难,但是对每个刚踏入这一行不久,或者说没有全流程开发过的小伙伴来说,是所有的基石,也特别重要。
欢迎一键三连,您的支持是我呕心沥血创作最大的动力!!!