目录
简单的解决方案:更大的页
混合方法:分页和分段
多级页表
详细的多级示例
超过两级
编辑地址转换过程:记住TLB
反向页表
将页表交换到磁盘
之前提到的一个问题:就是页表太大,假设一个 32 位地址空间(232 字节),4KB(212 字节)的页和一个 4 字节的页表项。一个地址空间中大约有一百万个虚拟页面(232/212)。乘以页表项的大小,你会发现页表大小为 4MB。然后如果开的进程比较多的话,那整个内存中,需要很多的空间来存放页表了。
这里上面的空间数据的计算,可以去了解。
简单的解决方案:更大的页
这里提到了一个解决方法,使用更大的页,32位地址空间为例,假设用16KB的页。所以,有18位的VPN加上14位的偏移量。假设每个页表项还是4字节,现在页表中有218项,每个页表的大小也就变成了1MB。
多种页的大小
在现在的体系结构中,都支持多种页的大小。通常使用的是一个比较小的数据。但是向数据库管理之类的,为了让TLB大概率的命中,减小TLB的压力,所以可以申请一个比较大的页表。同时也只占用一个TLB。记住这样不是为了节省页表空间。但是采用多种页的大小,是比较复杂的。所以,有时只需要想一些应用程序暴露一个接口,让他们直接请求内存页。
但是大内存页会出现每个页内存的浪费,你可以想到,有些应用程序就使用不了那么大的内存,从而导致了内部碎片。因此,在绝大数的情况下面,也就使用的是较小的页:4KB。
混合方法:分页和分段
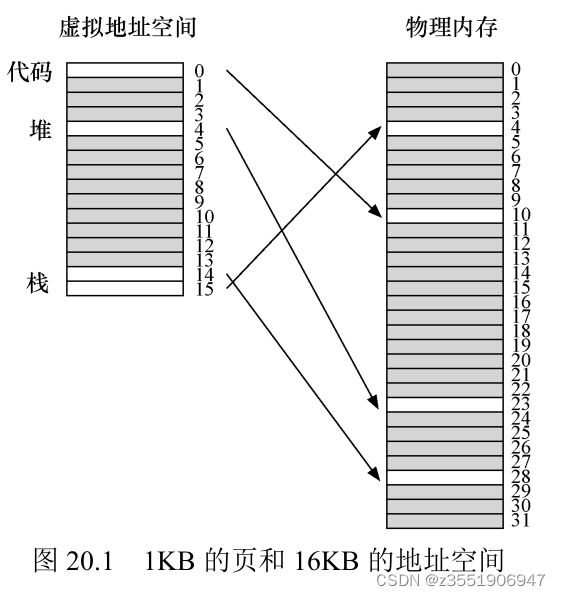 这里是一个例子,简单分析一下,是这样的,将堆栈和代码的部分,映射到物理空间上面,但是因为有很多的地方,用不到,所以也就有了很多的无效项,是比较浪费的,这个只是16KB,如果大的话,就会更浪费。
这里是一个例子,简单分析一下,是这样的,将堆栈和代码的部分,映射到物理空间上面,但是因为有很多的地方,用不到,所以也就有了很多的无效项,是比较浪费的,这个只是16KB,如果大的话,就会更浪费。
因此使用的方法不是为每个地址空间提供单个页表,而是为每个逻辑段提供一个。上面的例子中,可以会提供三个给,栈堆,还有代码。
在分段中,需要一个基址寄存器保存该段的页表的物理地址,界限寄存器指示页表的结尾(即有几个有效页)
有个简单例子,32位虚拟空间包含4KB的页面,并且地址空间分为4个段。00 是未使用的段,01 是代码段,10 是堆段,11 是栈段。
 在硬件中,所以就需要有这三对的寄存器。在进行上下文切换的时候,不许改变这些寄存器,反映新的运行进程的页表位置。
在硬件中,所以就需要有这三对的寄存器。在进行上下文切换的时候,不许改变这些寄存器,反映新的运行进程的页表位置。
当TLB没有命中的时候,硬件需要用分段位(SN)来确定哪个基址和界限对。然后硬件将其中的物理地址和VPN结合,形成页表项的地址。这种当时大大节省了空间,那边需要几个页表,也就给分配几个,不会出现内存分配过大的问题,也通过限制或者界限寄存器,可以判断出访问的时候有没有出现越界的情况,栈和堆之间没有分配的页不在占用页表中的空间。
但是上面的这个方法并不是完美的,因为分段技术,导致不是很灵活,如果有个稀疏的堆,会导致大量的页表浪费,会出现外部碎片,因为页表可以是任意大小了。寻找空间比较复杂。
多级页表
因为上面的种种问题,然后提出了一个多级页表:将页表分成页大小的单元。如果整个页的页表项无效,也就不分配,使用页目录最终页表的页是否有效。可以反映出页表的页在哪里,或者页表的整个页不包含有效页。
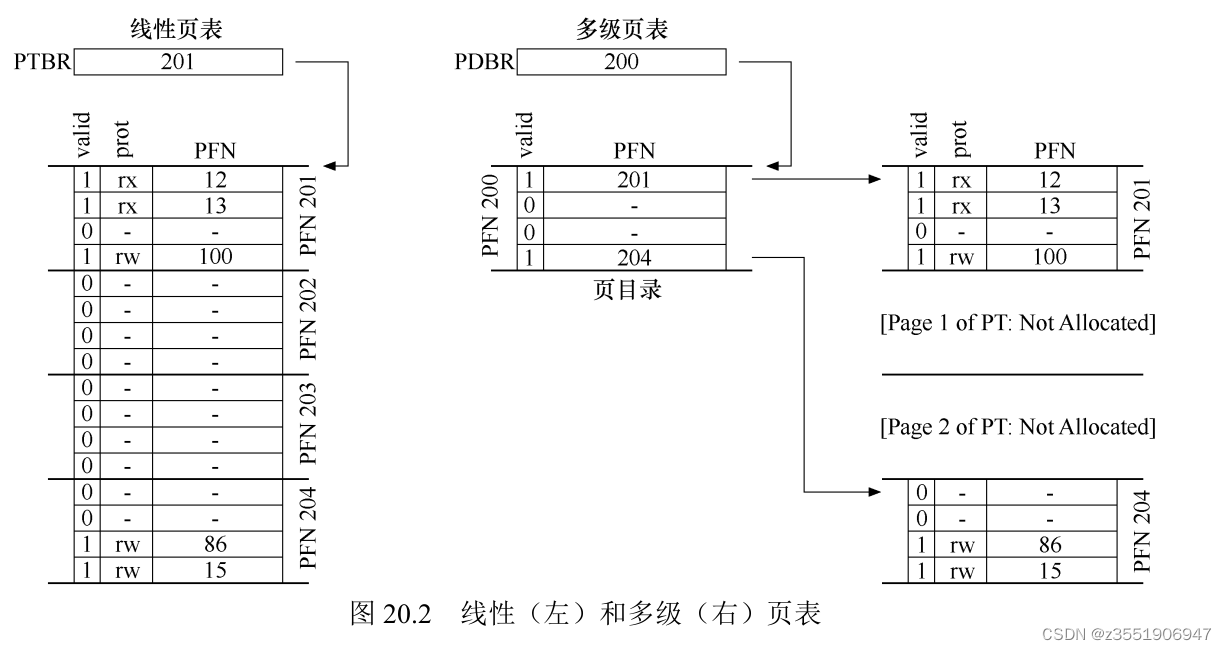 看右边的,页目录将页表的两个页标记为有效。这个就是工作过程,也就释放一些帧用于其他用途。从这里看出在多个页目录项中,有有效位和页帧号,当有效位为1的时候,表示的是该项指向的页表中,至少有一页是有效的。
看右边的,页目录将页表的两个页标记为有效。这个就是工作过程,也就释放一些帧用于其他用途。从这里看出在多个页目录项中,有有效位和页帧号,当有效位为1的时候,表示的是该项指向的页表中,至少有一页是有效的。
讲一下他的优势:首先,页表分配的页表空间和正在使用的地址空间内存量成比例,因此通常很紧凑,并且支持稀疏的地址空间。
然后,页表的每个部分可以整齐的放入一个页中,更加容易管理内存。可以在增长页表或者分配的时候获取下一个空闲页。线性的话,整个页表也就必须在连续的物理内存过中,这样的话寻找起来也就是比较困难的,但是现在的话,可以把页表页放到物理内存的任何位置。
但是这个也是有成本的,当TLB在没有命中的时候,内存需要加载两次,另一个点,就是这样做是比较复杂的。
详细的多级示例
在书中的例子讲述的是一个利用一个只有16kB的小地址空间,然后通过对这个地址空间的多级分页,然后达到需要的效果,着重总结几个点吧
-
在整个虚拟页中,不一定所有的页都是含有数据的,所以我们只需要按照页目录中页表页可以存储的页的大小去分析只需要映射几个页
-
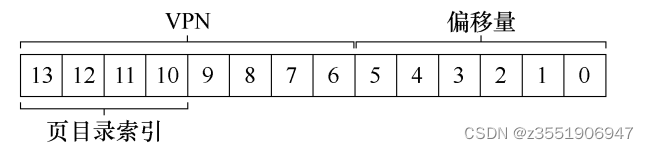 获取VPN,首先是需要通过页目录索引,拿到,这个页存在在那个页表页中,如果页目录是无效的,所以就会出错。
获取VPN,首先是需要通过页目录索引,拿到,这个页存在在那个页表页中,如果页目录是无效的,所以就会出错。 -
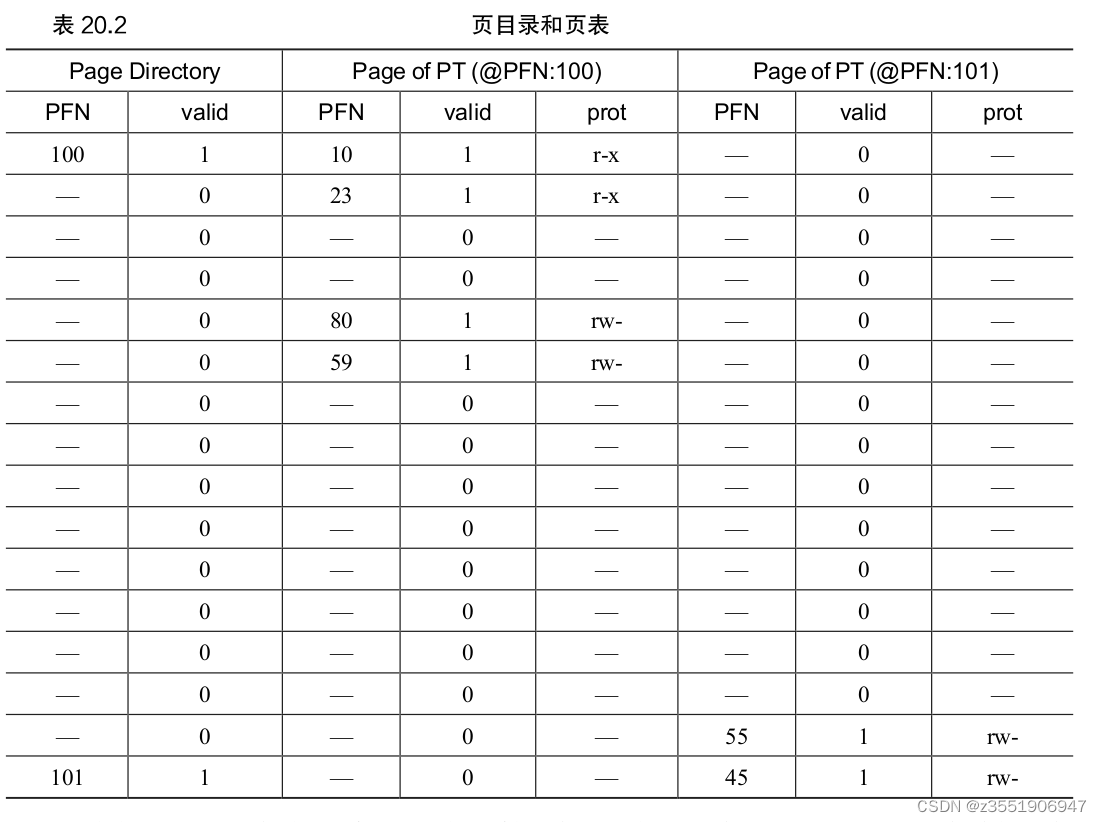
当获取到是哪个页的时候,然后在看存在于这个页表页中的那个页表中,最后获取到页表项。

超过两级
在很多的时候,可能会需要多级的页表去解决这个问题,其实里面的步骤都是一样的,也就是将页目录拆分,然后再添加页目录,就是一个层层嵌套的过程,也没有什么过多需要注意的地方。
 地址转换过程:记住TLB
地址转换过程:记住TLB
用算法的方式展现一下流程:
在任何复杂的多级页表访问发生之前,硬件首先检查TLB,在命中是,物理地址直接获取到,没有命中的时候。才需要执行完整的多级查找。可以看到传统的两级页表的成本:两次额外的内存访问来查找有效的转换映射。
反向页表
只需要一个页表来记录,其中每个项代表的是系统的每个物理页。页表项告诉我们哪个进程正在使用此页,以及该进程的哪个虚拟页映射到物理页中。这种扫描是比较昂贵的,所以采用了散列表去加速查找。
将页表交换到磁盘
如果之前接触到磁盘的时候,可以知道有个交换区,也就类似吧,在之前,都假设页表位于内核拥有的物理内存中,但是知道这样会减少行内,一些系统将页表,放入到内核虚拟内存中,从而系统在内存压力较大时候,将这些交换到磁盘。