系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
AI大模型探索之路-训练篇20:大语言模型预训练-常见微调技术对比
AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
目录
- 系列篇章💥
- 前言
- 一、经典的Transformer架构
- 二、ChatGLM3架构设计
- 1、GLM 动机
- 2、GLM的核心机制
- 3、预训练任务类型
- 1)掩码语言模型,自编码模型
- 2)因果模型,自回归模型
- 3)序列到序列模型
- 4、prompt格式
- 三、ChatGLM3微调准备
- 1、数据准备
- 2、模型选择
- 四、基于LoRA微调ChatGLM3
- 步骤1 导入相关包
- 步骤2 加载数据集
- 步骤3 数据集预处理
- 1)获取分词器
- 2)定义数据处理函数
- 3)对数据进行预处理
- 4)解码检查input_ids的格式
- 5)检查labels数据格式
- 步骤4 创建模型
- 1、创建模型实例
- 1)创建模型
- 2)精度查看确认
- 3)查看模型参数
- 2、PEFT 步骤1 配置文件
- 3、PEFT 步骤2 创建模型
- 1)创建微调模型
- 2)查看LoRA层添加情况
- 3)查看模型中可训练参数的数量
- 步骤5 配置训练参数
- 步骤6 创建训练器
- 步骤7 模型训练
- 步骤8 模型推理
- 总结
前言
在自然语言处理的浪潮中,Transformer架构以其独特的设计和卓越性能,成为了大语言模型的基石。ChatGLM3,作为其中的一员,通过微调在特定任务上展现了其强大的适应性和灵活性。本文将深入探讨ChatGLM3的架构设计,微调策略,并提供实战案例,以期为开发者提供宝贵的参考。
一、经典的Transformer架构
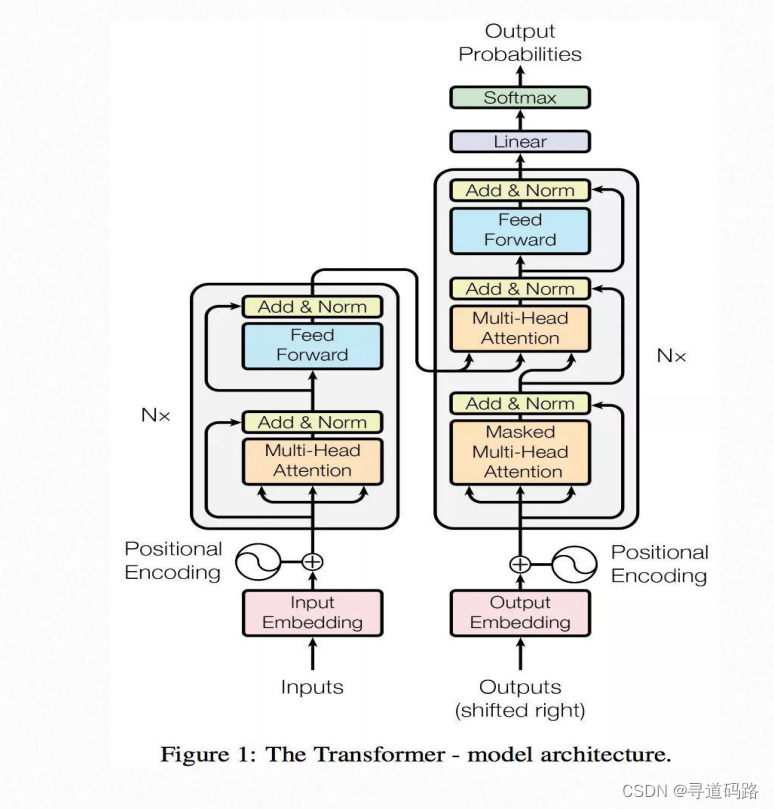
Transformer架构自问世以来,已成为NLP领域的一个里程碑。其核心思想是利用自注意力机制(Self-Attention)来捕捉文本中的长距离依赖关系,无需像循环神经网络(RNN)那样逐步处理序列。各大语言模型虽基于Transformer演变;但在结构、编码方式、激活函数、layer Norm方法上各有不同;另外掩码的设计不同,训练数据和目标的多样性等,都赋予了模型不同的特性和应用场景。
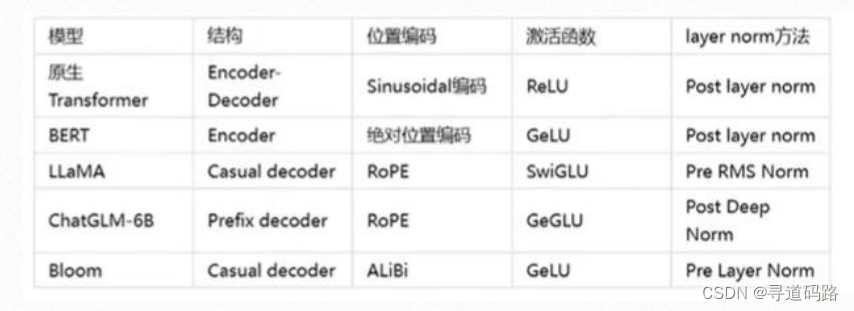
二、ChatGLM3架构设计
1、GLM 动机
大型预训练语言模型的发展可归纳为三个主要方向:
1)自编码模型 (Auto Encoding): BERT,ROBERTa,DeBERTa,ALBERT等;采用双向注意力机制,擅长处理自然语言理解任务,如情感分类、抽取式问答和自然语言推理等。
2)自回归模型 (Auto Regressive) :GPT系列,Llama,百川,等;通过单向注意力机制,专注于生成任务,包括语言建模和文本生成。
3)编码器-解码器模型 (Encoder-Decoder) : T5,BART,MASS,PALM等;结合了双向和单向注意力(encoder的attention是双向的,decoder的attention是单向的)。适用于条件生成(seq2seq)任务,比如:文本摘要,机器翻译等。
然而,现有模型在多任务性能上存在局限。GLM(General Language Model)旨在融合三者优势,实现在自然语言理解、生成和条件生成任务上的全面优化
2、GLM的核心机制

GLM的设计核心在于几个创新机制的引入:
- 自回归填空 :通过预测遮蔽(Masked)的词来训练模型,类似于BERT的Masked Language Model任务,增强模型对语言的理解和生成能力。
- 2D位置编码:采用二维位置编码,更精细地捕捉词与词之间的相对位置关系,提升模型对序列顺序的敏感度。
- 填空序列乱序:在训练过程中对填空任务的序列进行乱序处理,迫使模型学习更深层次的语言结构和转换规则。
3、预训练任务类型
1)掩码语言模型,自编码模型
将一些位置的token替换成特殊[MASK]字符,预测被替换的字符

2)因果模型,自回归模型
将完整序列输入,基于上文的token预测下文的token

3)序列到序列模型
采用编码器解码器的方式,预测放在解码器部分

在hugginface的PEFT库中,GLM归类为因果模型
4、prompt格式
ChatGLM3的prompt格式如下:
[gMASK]sop<|user|> \n Prompt<|assistant|>\n response eos_token
使用参考:
tokenizer.build_chat_input(“prompt”, history=[], role=“user”)
tokenizer.decode([xxx])

三、ChatGLM3微调准备
1、数据准备
数据集:https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh
2、模型选择
本次任务选择GLM3的基础模型。
模型地址:https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b-base/files
四、基于LoRA微调ChatGLM3
步骤1 导入相关包
开始之前,我们需要导入适用于模型训练和推理的必要库,如transformers。
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
步骤2 加载数据集
使用适当的数据加载器,例如datasets库,来加载预处理过的指令遵循性任务数据集。
ds = Dataset.load_from_disk("/root/PEFT代码/tuning/lesson01/data/alpaca_data_zh")
ds
输出:
Dataset({
features: ['output', 'input', 'instruction'],
num_rows: 26858
})
查看数据
ds[:1]
输出:
{'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。'],
'input': [''],
'instruction': ['保持健康的三个提示。']}
步骤3 数据集预处理
利用预训练模型的分词器(Tokenizer)对原始文本进行编码,并生成相应的输入ID、注意力掩码和标签。
自回归编码指令微调数据处理过程回顾:
① input输入构建:
- 在此步骤中,我们将数据集中的三个主要组成部分(指令、用户输入和预期输出)连接在一起,形成一个单一的字符串。
- 这个字符串按照以下格式组织:首先是指令(instruction),然后是用户输入(input),最后是预期输出(output)。
- 这种组织方式有助于模型理解输入和输出之间的关系,并学习如何根据指令和用户输入生成正确的输出。
② label标签创建:
- 此步骤涉及构建用于训练模型的标签(labels)。
- 用户输入部分在标签中保持不变,这意味着模型将尝试学习预测与用户输入相对应的输出。
- 对于输出部分,我们将其转化为目标标签,以便模型可以学习生成与预期输出相匹配的文本。
- 在自回归模型中,除了输出部分外,其他部分(包括指令和输入)的标签被替换为特殊的分隔符(例如:[SEP])加上-100。这样做的目的是告诉模型不需要预测这些部分,而是将注意力集中在输出部分上。
- 通过这种方式,模型将学会根据给定的指令和用户输入来生成正确的输出,同时忽略其他不相关的信息。
1)获取分词器
#加载本地模型,提前下载到本地
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/chatglm3-6b-base", trust_remote_code=True)
tokenizer
输出:
ChatGLMTokenizer(name_or_path='/root/autodl-tmp/chatglm3-6b-base', vocab_size=64798, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='left', truncation_side='right', special_tokens={}, clean_up_tokenization_spaces=False)
2)定义数据处理函数
格式处理:[gMASK]sop<|user|> \n Prompt<|assistant|>\n response eos_token
def process_func(example):
MAX_LENGTH = 256 # 设置最大长度为256
input_ids, attention_mask, labels = [], [], [] # 初始化输入ID、注意力掩码和标签列表
instruction = "\n".join([example["instruction"], example["input"]]).strip() # prompt
instruction = tokenizer.build_chat_input(instruction, history=[], role="user") # [gMASK]sop<|user|> \n prompt <|assistant|>
response = tokenizer("\n" + example["output"], add_special_tokens=False) # \n response
input_ids = instruction["input_ids"][0].numpy().tolist() + response["input_ids"] + [tokenizer.eos_token_id] #eos token
attention_mask = instruction["attention_mask"][0].numpy().tolist() + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"][0].numpy().tolist()) + response["input_ids"] + [tokenizer.eos_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
3)对数据进行预处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
输出:
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 26858
})
4)解码检查input_ids的格式
tokenizer.decode(tokenized_ds[1]["input_ids"])
输出:
'[gMASK]sop<|user|> \n 解释为什么以下分数等同于1/4\n输入:4/16<|assistant|> \n4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。'
5)检查labels数据格式
tokenizer.decode(list(filter(lambda x: x != -100, tokenized_ds[1]["labels"])))
输出:
'\n4/16等于1/4是因为我们可以约分分子分母都除以他们的最大公约数4,得到(4÷4)/ (16÷4)=1/4。分数的约分是用分子和分母除以相同的非零整数,来表示分数的一个相同的值,这因为分数实际上表示了分子除以分母,所以即使两个数同时除以同一个非零整数,分数的值也不会改变。所以4/16 和1/4是两种不同的书写形式,但它们的值相等。'
步骤4 创建模型
然后,我们实例化一个预训练模型,这个模型将作为微调的基础。对于大型模型,我们可能还需要进行一些特定的配置,以适应可用的计算资源。(为了节省资源,这里设置为半精度torch_dtype=torch.half)
1、创建模型实例
1)创建模型
import torch
model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp/modelscope/Llama-2-7b-ms",
low_cpu_mem_usage=True,
torch_dtype=torch.half,
device_map="auto")
2)精度查看确认
model.dtype
输出:
torch.float16
3)查看模型参数
检查模型有哪些参数,确认在哪一层添加LoRA微调
for name, param in model.named_parameters():
print(name)
输出:
transformer.embedding.word_embeddings.weight
transformer.encoder.layers.0.input_layernorm.weight
transformer.encoder.layers.0.self_attention.query_key_value.weight
transformer.encoder.layers.0.self_attention.query_key_value.bias
transformer.encoder.layers.0.self_attention.dense.weight
transformer.encoder.layers.0.post_attention_layernorm.weight
transformer.encoder.layers.0.mlp.dense_h_to_4h.weight
transformer.encoder.layers.0.mlp.dense_4h_to_h.weight
transformer.encoder.layers.1.input_layernorm.weight
transformer.encoder.layers.1.self_attention.query_key_value.weight
transformer.encoder.layers.1.self_attention.query_key_value.bias
transformer.encoder.layers.1.self_attention.dense.weight
transformer.encoder.layers.1.post_attention_layernorm.weight
transformer.encoder.layers.1.mlp.dense_h_to_4h.weight
transformer.encoder.layers.1.mlp.dense_4h_to_h.weight
transformer.encoder.layers.2.input_layernorm.weight
transformer.encoder.layers.2.self_attention.query_key_value.weight
transformer.encoder.layers.2.self_attention.query_key_value.bias
transformer.encoder.layers.2.self_attention.dense.weight
transformer.encoder.layers.2.post_attention_layernorm.weight
transformer.encoder.layers.2.mlp.dense_h_to_4h.weight
transformer.encoder.layers.2.mlp.dense_4h_to_h.weight
transformer.encoder.layers.3.input_layernorm.weight
transformer.encoder.layers.3.self_attention.query_key_value.weight
transformer.encoder.layers.3.self_attention.query_key_value.bias
transformer.encoder.layers.3.self_attention.dense.weight
transformer.encoder.layers.3.post_attention_layernorm.weight
transformer.encoder.layers.3.mlp.dense_h_to_4h.weight
transformer.encoder.layers.3.mlp.dense_4h_to_h.weight
transformer.encoder.layers.4.input_layernorm.weight
transformer.encoder.layers.4.self_attention.query_key_value.weight
transformer.encoder.layers.4.self_attention.query_key_value.bias
transformer.encoder.layers.4.self_attention.dense.weight
transformer.encoder.layers.4.post_attention_layernorm.weight
transformer.encoder.layers.4.mlp.dense_h_to_4h.weight
transformer.encoder.layers.4.mlp.dense_4h_to_h.weight
transformer.encoder.layers.5.input_layernorm.weight
transformer.encoder.layers.5.self_attention.query_key_value.weight
transformer.encoder.layers.5.self_attention.query_key_value.bias
transformer.encoder.layers.5.self_attention.dense.weight
transformer.encoder.layers.5.post_attention_layernorm.weight
transformer.encoder.layers.5.mlp.dense_h_to_4h.weight
transformer.encoder.layers.5.mlp.dense_4h_to_h.weight
transformer.encoder.layers.6.input_layernorm.weight
transformer.encoder.layers.6.self_attention.query_key_value.weight
transformer.encoder.layers.6.self_attention.query_key_value.bias
transformer.encoder.layers.6.self_attention.dense.weight
transformer.encoder.layers.6.post_attention_layernorm.weight
transformer.encoder.layers.6.mlp.dense_h_to_4h.weight
transformer.encoder.layers.6.mlp.dense_4h_to_h.weight
transformer.encoder.layers.7.input_layernorm.weight
transformer.encoder.layers.7.self_attention.query_key_value.weight
transformer.encoder.layers.7.self_attention.query_key_value.bias
transformer.encoder.layers.7.self_attention.dense.weight
transformer.encoder.layers.7.post_attention_layernorm.weight
transformer.encoder.layers.7.mlp.dense_h_to_4h.weight
transformer.encoder.layers.7.mlp.dense_4h_to_h.weight
transformer.encoder.layers.8.input_layernorm.weight
transformer.encoder.layers.8.self_attention.query_key_value.weight
transformer.encoder.layers.8.self_attention.query_key_value.bias
transformer.encoder.layers.8.self_attention.dense.weight
transformer.encoder.layers.8.post_attention_layernorm.weight
transformer.encoder.layers.8.mlp.dense_h_to_4h.weight
transformer.encoder.layers.8.mlp.dense_4h_to_h.weight
transformer.encoder.layers.9.input_layernorm.weight
transformer.encoder.layers.9.self_attention.query_key_value.weight
transformer.encoder.layers.9.self_attention.query_key_value.bias
transformer.encoder.layers.9.self_attention.dense.weight
transformer.encoder.layers.9.post_attention_layernorm.weight
transformer.encoder.layers.9.mlp.dense_h_to_4h.weight
transformer.encoder.layers.9.mlp.dense_4h_to_h.weight
transformer.encoder.layers.10.input_layernorm.weight
transformer.encoder.layers.10.self_attention.query_key_value.weight
transformer.encoder.layers.10.self_attention.query_key_value.bias
transformer.encoder.layers.10.self_attention.dense.weight
transformer.encoder.layers.10.post_attention_layernorm.weight
transformer.encoder.layers.10.mlp.dense_h_to_4h.weight
transformer.encoder.layers.10.mlp.dense_4h_to_h.weight
transformer.encoder.layers.11.input_layernorm.weight
transformer.encoder.layers.11.self_attention.query_key_value.weight
transformer.encoder.layers.11.self_attention.query_key_value.bias
transformer.encoder.layers.11.self_attention.dense.weight
transformer.encoder.layers.11.post_attention_layernorm.weight
transformer.encoder.layers.11.mlp.dense_h_to_4h.weight
transformer.encoder.layers.11.mlp.dense_4h_to_h.weight
transformer.encoder.layers.12.input_layernorm.weight
transformer.encoder.layers.12.self_attention.query_key_value.weight
transformer.encoder.layers.12.self_attention.query_key_value.bias
transformer.encoder.layers.12.self_attention.dense.weight
transformer.encoder.layers.12.post_attention_layernorm.weight
transformer.encoder.layers.12.mlp.dense_h_to_4h.weight
transformer.encoder.layers.12.mlp.dense_4h_to_h.weight
transformer.encoder.layers.13.input_layernorm.weight
transformer.encoder.layers.13.self_attention.query_key_value.weight
transformer.encoder.layers.13.self_attention.query_key_value.bias
transformer.encoder.layers.13.self_attention.dense.weight
transformer.encoder.layers.13.post_attention_layernorm.weight
transformer.encoder.layers.13.mlp.dense_h_to_4h.weight
transformer.encoder.layers.13.mlp.dense_4h_to_h.weight
transformer.encoder.layers.14.input_layernorm.weight
transformer.encoder.layers.14.self_attention.query_key_value.weight
transformer.encoder.layers.14.self_attention.query_key_value.bias
transformer.encoder.layers.14.self_attention.dense.weight
transformer.encoder.layers.14.post_attention_layernorm.weight
transformer.encoder.layers.14.mlp.dense_h_to_4h.weight
transformer.encoder.layers.14.mlp.dense_4h_to_h.weight
transformer.encoder.layers.15.input_layernorm.weight
transformer.encoder.layers.15.self_attention.query_key_value.weight
transformer.encoder.layers.15.self_attention.query_key_value.bias
transformer.encoder.layers.15.self_attention.dense.weight
transformer.encoder.layers.15.post_attention_layernorm.weight
transformer.encoder.layers.15.mlp.dense_h_to_4h.weight
transformer.encoder.layers.15.mlp.dense_4h_to_h.weight
transformer.encoder.layers.16.input_layernorm.weight
transformer.encoder.layers.16.self_attention.query_key_value.weight
transformer.encoder.layers.16.self_attention.query_key_value.bias
transformer.encoder.layers.16.self_attention.dense.weight
transformer.encoder.layers.16.post_attention_layernorm.weight
transformer.encoder.layers.16.mlp.dense_h_to_4h.weight
transformer.encoder.layers.16.mlp.dense_4h_to_h.weight
transformer.encoder.layers.17.input_layernorm.weight
transformer.encoder.layers.17.self_attention.query_key_value.weight
transformer.encoder.layers.17.self_attention.query_key_value.bias
transformer.encoder.layers.17.self_attention.dense.weight
transformer.encoder.layers.17.post_attention_layernorm.weight
transformer.encoder.layers.17.mlp.dense_h_to_4h.weight
transformer.encoder.layers.17.mlp.dense_4h_to_h.weight
transformer.encoder.layers.18.input_layernorm.weight
transformer.encoder.layers.18.self_attention.query_key_value.weight
transformer.encoder.layers.18.self_attention.query_key_value.bias
transformer.encoder.layers.18.self_attention.dense.weight
transformer.encoder.layers.18.post_attention_layernorm.weight
transformer.encoder.layers.18.mlp.dense_h_to_4h.weight
transformer.encoder.layers.18.mlp.dense_4h_to_h.weight
transformer.encoder.layers.19.input_layernorm.weight
transformer.encoder.layers.19.self_attention.query_key_value.weight
transformer.encoder.layers.19.self_attention.query_key_value.bias
transformer.encoder.layers.19.self_attention.dense.weight
transformer.encoder.layers.19.post_attention_layernorm.weight
transformer.encoder.layers.19.mlp.dense_h_to_4h.weight
transformer.encoder.layers.19.mlp.dense_4h_to_h.weight
transformer.encoder.layers.20.input_layernorm.weight
transformer.encoder.layers.20.self_attention.query_key_value.weight
transformer.encoder.layers.20.self_attention.query_key_value.bias
transformer.encoder.layers.20.self_attention.dense.weight
transformer.encoder.layers.20.post_attention_layernorm.weight
transformer.encoder.layers.20.mlp.dense_h_to_4h.weight
transformer.encoder.layers.20.mlp.dense_4h_to_h.weight
transformer.encoder.layers.21.input_layernorm.weight
transformer.encoder.layers.21.self_attention.query_key_value.weight
transformer.encoder.layers.21.self_attention.query_key_value.bias
transformer.encoder.layers.21.self_attention.dense.weight
transformer.encoder.layers.21.post_attention_layernorm.weight
transformer.encoder.layers.21.mlp.dense_h_to_4h.weight
transformer.encoder.layers.21.mlp.dense_4h_to_h.weight
transformer.encoder.layers.22.input_layernorm.weight
transformer.encoder.layers.22.self_attention.query_key_value.weight
transformer.encoder.layers.22.self_attention.query_key_value.bias
transformer.encoder.layers.22.self_attention.dense.weight
transformer.encoder.layers.22.post_attention_layernorm.weight
transformer.encoder.layers.22.mlp.dense_h_to_4h.weight
transformer.encoder.layers.22.mlp.dense_4h_to_h.weight
transformer.encoder.layers.23.input_layernorm.weight
transformer.encoder.layers.23.self_attention.query_key_value.weight
transformer.encoder.layers.23.self_attention.query_key_value.bias
transformer.encoder.layers.23.self_attention.dense.weight
transformer.encoder.layers.23.post_attention_layernorm.weight
transformer.encoder.layers.23.mlp.dense_h_to_4h.weight
transformer.encoder.layers.23.mlp.dense_4h_to_h.weight
transformer.encoder.layers.24.input_layernorm.weight
transformer.encoder.layers.24.self_attention.query_key_value.weight
transformer.encoder.layers.24.self_attention.query_key_value.bias
transformer.encoder.layers.24.self_attention.dense.weight
transformer.encoder.layers.24.post_attention_layernorm.weight
transformer.encoder.layers.24.mlp.dense_h_to_4h.weight
transformer.encoder.layers.24.mlp.dense_4h_to_h.weight
transformer.encoder.layers.25.input_layernorm.weight
transformer.encoder.layers.25.self_attention.query_key_value.weight
transformer.encoder.layers.25.self_attention.query_key_value.bias
transformer.encoder.layers.25.self_attention.dense.weight
transformer.encoder.layers.25.post_attention_layernorm.weight
transformer.encoder.layers.25.mlp.dense_h_to_4h.weight
transformer.encoder.layers.25.mlp.dense_4h_to_h.weight
transformer.encoder.layers.26.input_layernorm.weight
transformer.encoder.layers.26.self_attention.query_key_value.weight
transformer.encoder.layers.26.self_attention.query_key_value.bias
transformer.encoder.layers.26.self_attention.dense.weight
transformer.encoder.layers.26.post_attention_layernorm.weight
transformer.encoder.layers.26.mlp.dense_h_to_4h.weight
transformer.encoder.layers.26.mlp.dense_4h_to_h.weight
transformer.encoder.layers.27.input_layernorm.weight
transformer.encoder.layers.27.self_attention.query_key_value.weight
transformer.encoder.layers.27.self_attention.query_key_value.bias
transformer.encoder.layers.27.self_attention.dense.weight
transformer.encoder.layers.27.post_attention_layernorm.weight
transformer.encoder.layers.27.mlp.dense_h_to_4h.weight
transformer.encoder.layers.27.mlp.dense_4h_to_h.weight
transformer.encoder.final_layernorm.weight
transformer.output_layer.weight
下面2个部分是LoRA相关的配置。
2、PEFT 步骤1 配置文件
在使用PEFT进行微调时,我们首先需要创建一个配置文件,该文件定义了微调过程中的各种设置,如学习率调度、优化器选择等。
提前安装peft:pip install peft
from peft import LoraConfig, TaskType, get_peft_model, PeftModel
config = LoraConfig(target_modules=["query_key_value"])
config
输出
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=None, inference_mode=False, r=8, target_modules={'query_key_value'}, lora_alpha=8, lora_dropout=0.0, fan_in_fan_out=False, bias='none', modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={})
3、PEFT 步骤2 创建模型
接下来,我们使用PEFT和预训练模型来创建一个微调模型。这个模型将包含原始的预训练模型以及由PEFT引入的低秩参数。
1)创建微调模型
model = get_peft_model(model, config)
config
输出
LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path='/root/autodl-tmp/modelscope/Llama-2-7b-ms', revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, r=8, target_modules={'q_proj', 'v_proj'}, lora_alpha=8, lora_dropout=0.0, fan_in_fan_out=False, bias='none', modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={})
2)查看LoRA层添加情况
打印所有的模型参数,查看LoRA添加到了哪一层
for name, parameter in model.named_parameters():
print(name)
3)查看模型中可训练参数的数量
model.print_trainable_parameters()#打印出模型中可训练参数的数量
输出:
trainable params: 1,949,696 || all params: 6,245,533,696 || trainable%: 0.031217444255383614
步骤5 配置训练参数
在这一步,我们定义训练参数,这些参数包括输出目录、学习率、权重衰减、梯度累积步数、训练周期数等。这些参数将被用来配置训练过程。(设置adam_epsilon=1e-4避免精度溢出,半精度的情况下才需要设置)
args = TrainingArguments(
output_dir="/root/autodl-tmp/chatglm2output", #输出目录,用于存储模型和日志文件。
per_device_train_batch_size=2, # 每个设备的训练批次大小,即每个设备每次处理的数据量,批次越大,训练时需要资源越多
gradient_accumulation_steps=16, # 指定梯度累积步数。用于控制梯度更新的频率。在每个累积步中,模型会计算多个批次的梯度,然后一次性更新权重。这可以减少内存占用并提高训练速度。在本例子中,每16个步骤进行一次梯度更新。
logging_steps=10, #日志记录步数,用于控制每隔多少步记录一次训练日志。
num_train_epochs=1, #训练轮数,即模型在整个训练集上进行迭代的次数。正常情况会训练很多轮
learning_rate=1e-4, #学习率,控制模型参数更新的速度。较小的学习率会使模型收敛得更快,但可能需要更多的训练轮数
adam_epsilon=1e-4, #Adam优化器的epsilon值,用于防止除以零的情况。
remove_unused_columns=False #是否移除未使用的列,如果设置为False,则保留所有列,否则只保留模型所需的列。
)
步骤6 创建训练器
最后,我们创建一个训练器实例,它封装了训练循环。训练器将负责运行训练过程,并根据我们之前定义的参数进行优化。
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
步骤7 模型训练
通过调用训练器的train()方法,我们启动模型的训练过程。这将根据之前定义的参数执行模型的训练。
trainer.train()
步骤8 模型推理
训练完成后,我们可以使用训练好的模型进行推理。
model.eval()
print(model.chat(tokenizer, "如何写简历?", history=[])[0])
输出:
写简历时,您可以按照以下步骤进行:
1. 个人信息:在开头部分,写上您的姓名、联系方式和地址。
2. 教育背景:列出您所获得的所有学历,包括学校名称、学位和毕业日期。
3. 工作经历:在简历中,按照时间顺序列出您过去的工作经历,包括公司名称、职位、职责和时间。
4. 技能和证书:在您的简历中,列出您掌握的技能和证书,例如编程语言、软件、证书和证书等级。
5. 个人亮点:在您的简历中,列出您的个人亮点,例如您在团队合作、创新、解决问题和沟通方面的优势。
6. 总结:在结尾部分,简要总结您在各个领域的工作经验和技能,并表达您对未来的职业发展的期望。
请注意,简历应该简洁明了,突出您的优势和技能,同时避免使用过于复杂的语言和词汇。您可以参考模板或在线简历生成器来帮助您创建一份简历。
总结
本文深入探讨了大语言模型ChatGLM3的微调实践,从架构设计到预训练任务,再到实际的微调操作步骤。文章首先回顾了Transformer架构的重要性,接着分析了ChatGLM3融合不同预训练模型优势的独特动机和核心机制,如自回归填空和2D位置编码。此外,文中详细描述了基于LoRA技术的微调过程,包括数据准备、模型构建、训练以及推理等关键步骤。这些内容旨在为大家提供宝贵的参考,帮助大家在自然语言处理项目中有效应用大型预训练语言模型。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!